Elasticsearch学习系列一(部署和配置IK分词器)
优质资源分享
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| Python实战微信订餐小程序 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| Python量化交易实战 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
Elasticsearch简介
Elasticsearch是什么?
Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数据。本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。ES使用Java开发并使用Lucene作为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI和javaAPI来隐藏Lucene的复杂性,从而让全文搜索变得简单。
起源:Shay Banon。2004年失业,陪老婆去伦敦学习厨师。失业在家帮老婆写一个菜谱搜索引擎。封装了lucene,做出了开源项目compass。找到工作后,做分布式高性能项目,再封装compass,写出了elasticsearch,使得lucene支持分布式。现在是Elasticsearch创始人兼Elastic首席执行官
Elasticsearch的功能
- 分布式的搜索引擎
分布式:Elasticsearch自动将海量数据分散到多台服务器上去存储和检索
- 全文检索
提供模糊搜索等自动度很高的查询方式,并进行相关性排名,高亮等功能
- 数据分析引擎(分组聚合)
电商网站,最近一周笔记本电脑这种商品销量排名top10的商家有哪些?新闻网站,最近1个月访问量排名top3的新闻板块是哪些
- 对海量数据进行近实时的处理
海量数据的处理:因为是分布式架构,Elasticsearch可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理。近实时指的是Elasticsearch可以实现秒级别的数据搜索和分析
Elasticsearch的特点
- 安装方便:没有其他依赖,下载后安装非常方便;只用修改几个参数就可以搭建起来一个集群
- JSON:输入/输出格式为 JSON,意味着不需要定义 Schema,快捷方便
- RESTful:基本所有操作 ( 索引、查询、甚至是配置 ) 都可以通过 HTTP 接口进行
- 分布式:节点对外表现对等(每个节点都可以用来做入口)加入节点自动负载均衡
- 多租户:可根据不同的用途分索引,可以同时操作多个索引
- 支持超大数据:可以扩展到PB级的结构化和非结构化数据海量数据的近实时处理
使用场景
- 搜索类场景
如电商网站、招聘网站、新闻资讯类网站、各种app内的搜索。
- 日志分析类场景
经典的ELK组合(Elasticsearch/Logstash/Kibana),可以完成日志收集,日志存储,日志分析查询界面基本功能,目前该方案的实现很普及,大部分企业日志分析系统使用了该方案。
- 数据预警平台及数据分析场景
例如电商价格预警,在支持的电商平台设置价格预警,当优惠的价格低于某个值时,触发通知消息,通知用户购买。数据分析常见的比如分析电商平台销售量top 10的品牌,分析博客系统、头条网站top10关注度、评论数、访问量的内容等等。
- 商业BI(Business Intelligence)系统
比如大型零售超市,需要分析上一季度用户消费金额,年龄段,每天各时间段到店人数分布等信息,输出相应的报表数据,并预测下一季度的热卖商品,根据年龄段定向推荐适宜产品。Elasticsearch执行数据分析和挖掘,Kibana做数据可视化。
常见案例
- 维基百科、百度百科:有全文检索、高亮、搜索推荐功能
- stack overflow:有全文检索,可以根据报错关键信息,去搜索解决方法。
- github:从上千亿行代码中搜索你想要的关键代码和项目。
- 日志分析系统:各企业内部搭建的ELK平台
Elasticsearch VS Solr
- Lucene
Lucene是Apache基金会维护的一套完全使用Java编写的信息搜索工具包(Jar包),它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此在使用Lucene时仍需要我们自己进一步开发搜索引擎系统,例如数据获取、解析、分词等方面的东西。
注意:Lucene只是一个框架,我们需要在Java程序中集成它再使用。而且需要很多的学习才能明白它是如何运行的,熟练运用Lucene非常复杂。
- Solr
Solr是一个有HTTP接口的基于Lucene的查询服务器,是一个搜索引擎系统,封装了很多Lucene细节,Solr可以直接利用HTTP GET/POST请求去查询,维护修改索引
- Elasticsearch
Elasticsearch也是一个建立在全文搜索引擎 Apache Lucene基础上的搜索引擎。采用的策略是分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
总结:
- Solr和Es都是基于Lucene实现的
- Solr利用Zookeeper进行分布式管理,而Es自身带有分布式协调管理功能
- Solr比Es实现更全面,功能更多,而Es本身更注重于核心功能,高级功能多由第三方插件提供
- Solr在传统的搜索应用中表现比Es好,而Es在实时搜索应用方面比Solr好
- Solr查询快,但更新索引时慢,可用于电商等查询多的应用;而Es建立索引快,更实时
- 随着数据量的增加,Solr的搜索效率会变得更低,而Es却没有明显变化
安装部署ES
- 下载es,并解压
https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-3-0
- 编辑vim config/elasticsearch.yml,修改下面的4个地方。network.host对应自己机器的ip
node.name: node-1
network.host: 192.168.211.136
#
# Set a custom port for HTTP:
#
http.port: 9200
cluster.initial\_master\_nodes: ["node-1"]
- ++按需++修改vim config/jvm.options内存设置
可以调整里面的Xms和Xmx
3. 添加es用户(es默认root用户无法启动)
useradd estest
#修改密码
passwd estest
- 赋予estest用户一个目录权限
chown -R estest /usr/elasticsearch/
- 修改/etc/sysctl.conf
#末尾添加
vm.max\_map\_count=655360
修改完执行sysctl -p,让其生效
sysctl -p
- 修改/etc/security/limits.conf
#末尾添加
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
- 修改/etc/security/limits.d/20-nproc.conf
#末尾添加
* hard nproc 4096
重新登录或重启服务器使配置生效。
- 启动es
#切换用户
su estest
#启动
bin/elasticsearch
- 测试
http://192.168.56.115:9200/
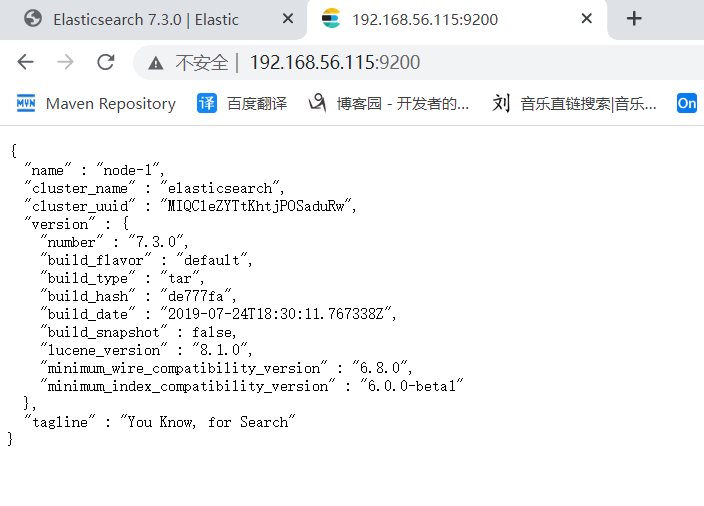
测试ok,安装成功!!!
安装配置Kibana
什么是Kibana?
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱状图、线状图、饼图等。而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
安装Kibana
- 下载Kibana
https://www.elastic.co/cn/downloads/kibana
root账户下操作:
- 解压
- 改变kibana目录权限、设置访问权限
chown -R estest /usr/local/kibana-7.3.0-linux-x86_64
chmod -R 777 /usr/local/kibana-7.3.0-linux-x86_64
- 修改配置文件
server.port: 5601
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://192.168.211.136:9200"]
- 启动
su estest
bin/kibana
访问地址: http://192.168.56.115:5601

后续的操作我们可以使用kibana来访问es:
Es集成IK分词器
KAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于
Lucene项目,同时提供了对Lucene的默认优化实现。
插件安装方式
- 在es的bin目录下执行以下命令,es插件管理器会自动帮我们安装,然后等待安装完成。
bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip
安装包安装方式
- 下载 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.3.0/elasticsearch-analysis-ik-7.3.0.zip
- 在es安装目录下的plugins目录下新建analysis-ik目录
#新建analysis-ik文件夹
mkdir analysis-ik
#切换至 analysis-ik文件夹下
cd analysis-ik
#上传资料中的 elasticsearch-analysis-ik-7.3.0.zip
#解压
unzip elasticsearch-analysis-ik-7.3.3.zip
#解压完成后删除zip
rm -rf elasticsearch-analysis-ik-7.3.0.zip
- 重启es
测试分词器
IK分词器有两种分词模式:ik_max_word和ik_smart模式
- ik_max_word:将文本做最细粒度的拆分
- ik_smart:将文本做最粗力度的拆分
示例:
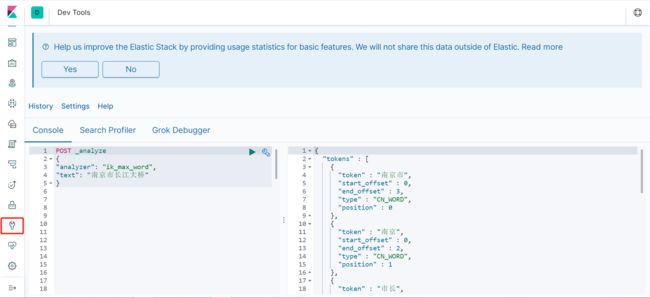
POST \_analyze
{
"analyzer": "ik\_max\_word",
"text": "南京市长江大桥"
}
得到结果如下:
{
"tokens" : [
{
"token" : "南京市",
"start\_offset" : 0,
"end\_offset" : 3,
"type" : "CN\_WORD",
"position" : 0
},
{
"token" : "南京",
"start\_offset" : 0,
"end\_offset" : 2,
"type" : "CN\_WORD",
"position" : 1
},
{
"token" : "市长",
"start\_offset" : 2,
"end\_offset" : 4,
"type" : "CN\_WORD",
"position" : 2
},
{
"token" : "长江大桥",
"start\_offset" : 3,
"end\_offset" : 7,
"type" : "CN\_WORD",
"position" : 3
},
{
"token" : "长江",
"start\_offset" : 3,
"end\_offset" : 5,
"type" : "CN\_WORD",
"position" : 4
},
{
"token" : "大桥",
"start\_offset" : 5,
"end\_offset" : 7,
"type" : "CN\_WORD",
"position" : 5
}
]
}
扩展词典
分词结果没有我们想要的时候,可以自己扩展。如:南京市长江大桥,它的语义是南京市市长叫“江大桥”。
- 进入到 config/analysis-ik/(插件命令安装方式)或plugins/analysis-ik/config(安装包安装方式) 目录下, 新增自定义词典(文件名随意)
vim my_ext_dict.dic
内容输入:江大桥
2. 将我们的自定义扩展文件配置上
vim IKAnalyzer.cfg.xml
xml version="1.0" encoding="UTF-8"?
properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
IK Analyzer 扩展配置comment>
my_ext_dict.dicentry>
entry>
properties>
- 配置完后重启es
停用词配置同理。
同义词典使用
同一个东西有不同的词语来表示。我们搜索的时候期望输入"土豆",能搜出"洋芋",输入"西红柿"能搜出"番茄"等等。
Elasticsearch 自带一个名为 synonym 的同义词 filter。为了能让 IK 和 synonym 同时工作,我们需要定义新的analyzer,用IK做tokenizer,synonym做filter。
- config/analysis-ik目录下创建synonym.txt文件,输入一些同义词
西红柿,番茄
- 创建索引时使用同义词配置
{
"settings":{
"analysis":{
"filter":{
"word_sync":{
"type":"synonym",
"synonyms\_path":"analysis-ik/synonym.txt"
}
},
"analyzer":{
"ik_sync_max_word":{
"filter":[
"word\_sync"
],
"type":"custom",
"tokenizer":"ik\_max\_word"
},
"ik_sync_smart":{
"filter":[
"word\_sync"
],
"type":"custom",
"tokenizer":"ik\_smart"
}
}
}
},
"mappings":{
"properties":{
"字段名":{
"type":"字段类型",
"analyzer":"ik\_sync\_smart",
"search\_analyzer":"ik\_sync\_smart"
}
}
}
}
以上配置定义了ik_sync_max_word和ik_sync_smart这两个新的analyzer,对应IK的ik_max_word和ik_smart两种分词策略。
- 搜索时指定分词器ik_sync_max_word或ik_sync_smart即可拥有同义词功能。
示例如下:
- 建索引
PUT /test-synonym
{
"settings":{
"analysis":{
"filter":{
"word_sync":{
"type":"synonym",
"synonyms\_path":"analysis-ik/synonym.txt"
}
},
"analyzer":{
"ik_sync_max_word":{
"filter":[
"word\_sync"
],
"type":"custom",
"tokenizer":"ik\_max\_word"
},
"ik_sync_smart":{
"filter":[
"word\_sync"
],
"type":"custom",
"tokenizer":"ik\_smart"
}
}
}
},
"mappings":{
"properties":{
"name":{
"type":"text",
"analyzer":"ik\_sync\_smart",
"search\_analyzer":"ik\_sync\_smart"
}
}
}
}
- 插入数据
POST /test-synonym/_doc/1
{
"name":"我喜欢吃番茄"
}
- 搜索
POST /test-synonym/_search
{
"query":{
"match":{
"name":"西红柿"
}
}
}