python爬虫实战——自动下载百度图片(文末附源码)
用Python制作一个下载图片神器
前言
这个想法是怎么来的?
很简单,就是不想一张一张的下载图片,嫌太慢。
在很久很久以前,我比较喜欢收集各种动漫的壁纸,作为一个漫迷,自然是能收集多少就收集多少。小孩子才做选择,我全都要。但是用鼠标一个个点击下载,这也太low啦!于是最终放弃啦。
现在,这个想法在我脑中不停地出现,如果不解决它,我会茶不思饭不想,难受至极!
于是,我竭尽全力的挤出时间(上班摸鱼的时候),终于完成了这一”举世瞩目“的工程。现在仅需输入需要下载的图片内容、图片数量,就可以快速的拥有数不尽的”荣华富贵“。
接下来,看一看这是如何实现的(让一让,我要开始装B啦),授人鱼不如授人以渔。
分析百度图片网站
为什么是百度图片,而不是其他网站?
我不想回答,咱直接开始分析,好吧。
怎么检查网站的构造?
以谷歌浏览器为例,右击选择“检查”,就可以看到网站的源码,以及整个结构。
那百度图片网站是如何工作的,或者如何加载图片的?
当我在搜索框中输入《秦时明月》后,点击百度一下,图片并不会全部展示完,而是先加载一部分数据,当页面滑动到最后一张图片后,页面会继续加载图片。这种加载数据的方式,被称为“异步加载”。
对于这种异步加载得到的数据,选择“Network”选项卡,在选中“XHR”,这里面加载的内容就是异步加载的内容。如下图:

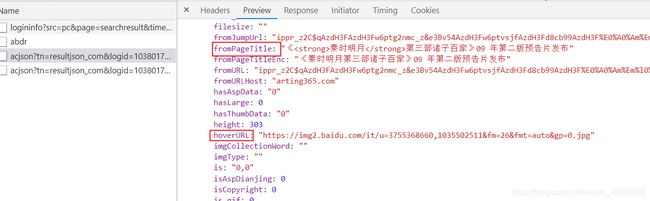
点击左侧的接口地址,在右侧选择“Preview”选项,就可以看到该接口返回的json数据。在这个接口中发现:fromPageTitleEnc为图片的标题,hoverURL为图片的真正地址。如下图:
知道图片的加载方式,然后呢?
现在接口的地址如下:
url = "https://image.baidu.com/search/acjson"
接下来就是要”伪造“请求头(header)以及请求参数(param),模拟浏览器去访问接口。
刚开始可以将浏览器中所有的数据复制下来,去请求接口,经过我的一番测试,发现请求头只需要以下参数即可:
header = {
'Accept': 'text/plain, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Host': 'image.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
请求参数如下:
其中,重要的参数为:
- queryWord:word,查询词
- rn:代表接口返回的图片数量为30张
- pn:以30为基础,60表示第二个接口,90表示第三个接口,120表示第四个接口
其他参数,我也不知道有啥用!放着不要动就行。
param = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'fp': 'result',
'queryWord': '秦时明月',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'st': '-1',
'ic': '0',
'word': '秦时明月',
'face': '0',
'istype': '2',
'nc': '1',
'pn': '60',
'rn': '30',
'gsm': '1e',
}
所以,只需修改queryWord,word,pn即可获取不同类型图片,不同数量的图片。
爬虫
能否谈一下你的爬虫代码思路?
talk is cheap,show me the code!(话不多说,都在代码里!)
1、获取json数据
def get_json(query_word=None, page_num=None):
# 修改参数中的查询关键词
param["queryWord"] = query_word
param["word"] = query_word
# 修改获取图片的数量
param["pn"] = f'{30 * page_num}'
# 模拟浏览器获取json数据
res = requests.get(url=url, headers=header, params=param)
res_dict = dict(res.json())
return res_dict
2、解析数据
def get_pic_info(res=None):
# 将图片信息都放到 pic_info 列表中
pic_info = []
for data in res["data"]:
# 从 json 数据中解析出数据
pic_name = data.get("fromPageTitleEnc", None)
pic_url = data.get("hoverURL", None)
# 以 pic_name 为名命名图片
if pic_name and pic_url:
pic_name = pic_name.replace(" ", '')
for p in string.punctuation:
pic_name = pic_name.replace(p, '')
if "png" in pic_url:
pic_name += ".png"
if "jpg" in pic_url:
pic_name += ".jpg"
if "gif" in pic_url:
pic_name += ".gif"
if "jpeg" in pic_url:
pic_name += ".jpeg"
if "bmp" in pic_url:
pic_name += ".bmp"
pic_info.append({"pic_name": pic_name, "pic_url": pic_url})
return pic_info
3、保存图片
def save_picture(query_word=None, pic_name=None, pic_url=None):
# 在同级目录下创建 image 文件夹,将图片保存在以 query_word 为名创建新的文件夹
cwd = os.getcwd()
images_path = os.path.join(cwd, "images")
query_word_path = os.path.join(images_path, query_word)
# images 文件夹
if "images" not in os.listdir(cwd):
os.mkdir(images_path)
# os.chdir(images_path)
# query_word 文件夹
if query_word not in os.listdir(images_path):
os.mkdir(query_word_path)
# 读取图片
pic = requests.get(pic_url, stream=True)
pic_path = os.path.join(query_word_path, pic_name)
# 保存图片
with open(pic_path, "wb") as f:
for c in pic.iter_content(chunk_size=10240):
f.write(c)
4、主运行代码
def run():
while True:
# 多次下载,直到输入 q 退出
query_word = str(input("输入要下载的图片名(q退出):"))
if query_word == "q":
break
while True:
# 当输入的数量不为整数,循环输入
pic_num = input("输入需要下载的数量(q退出):")
if pic_num == "q":
break
try:
pic_num = int(pic_num)
except:
continue
page_num = 1 if int(pic_num / 30) == 0 else int(pic_num / 30)
for i in range(1, page_num + 1):
# 获取 json 数据
res = get_json(query_word=query_word, page_num=i)
# 获取图片名和图片地址
pic_info = get_pic_info(res=res)
# 保存图片
for pic in pic_info:
print(pic["pic_name"], "下载完成")
save_picture(query_word=query_word, pic_name=pic["pic_name"], pic_url=pic["pic_url"])
break
if __name__ == '__main__':
run()
这么多代码,没有基础的我,不想看,咋办?
不要方,少年,接下来有更加神奇的操作,如何将这些代码封装为exe文件,这样就算你没有python环境,也可以使用。
生成exe文件
请问,将python文件打包成exe文件总共分几步?
第一步:将用到的第三方库requests与该py文件同级目录下,如下图:
第二步:安装pyinstaller
pip installer pyinstaller
第三步:打包
pyinstaller -F py文件的绝对地址
更改图标,图标只能是ico文件
pyinstaller -i -F ico图片地址 py文件的绝对地址
好了,这里就介绍这么多,感兴趣的同学给个关注呗!