【机器学习】案例一:随机森林预测泰坦尼克号生还概率
目录
前言:
【一】数据清洗及可视化
介绍
知识点
环境准备
数据特征介绍
检查数据
相关系数
缺失值
偏态分布
数值化和标准化
离群点
实验总结一
【二】分类模型训练及评价
介绍
环境准备
模型评估
模型选择
性能度量
实验总结二
【三】随机森林分类器及其参数调节
介绍
知识点
实验原理
决策树
集成学习
随机森林
Python sklearn 参数调节
交叉验证法调参
scikit-learn 自动调参函数 GridSearchCV
实验总结三
前言:
杰克和露丝的爱情,生命的不可预料,使得泰坦尼克号的沉没即悲伤又美好。本实验将通过数据来预测船员和乘客的生还状况,包括数据清洗及可视化、模型训练及评估,以及随机森林分类器调参等内容。
【一】数据清洗及可视化
介绍
数据清洗是数据分析中非常重要的一部分,也最繁琐,做好这一步需要大量的经验和耐心。这门课程中,我将和大家一起,一步步完成这项工作。大家可以从这门课程中学习数据清洗的基本思路以及具体操作,同时,练习使用 Pandas 数据分析工具、Seaborn 统计分析可视化工具。
知识点
- 离群点分析
- 缺失值处理
- 偏态分布数据处理
环境准备
下载数据
!wget -nc "http://labfile.oss.aliyuncs.com/courses/1001/train.csv" # 数据来源www.kaggle.com
接下来,导入所需模块
import pandas as pd
import numpy as np
import matplotlib as plt
import seaborn as sns
%matplotlib inline
data = pd.read_csv('train.csv') #读取数据,命名为 data
data.head(5) #查看 data 前5行
示例结果:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
数据特征介绍
data.columns #查看特征向量
示例结果:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
我们导入的数据集 data,每行是一个训练样例(即游客),每列是该样例的特征。 其中 Suivived 代表游客是否存活(0 或 1),这是一个二分类问题(死亡 或 生存)。下面是各特征的详细说明:
- PassengerId: 编号
- Survived: 0 = 死亡,1 = 生存
- Pclass: 船票级别 1 = 高级, 2 = 中等, 3 = 低等
- Name: 名称
- Sex: male = 男性,female = 女性
- Age: 年龄
- SibSp: 在 Titanic 上的兄弟姐妹以及配偶的人数
- Parch: 在 Titanic 上的父母以及子女的人数
- Ticket: 船票编号
- Fare: 工资
- Cabin: 所在的船舱
- Embarked: 登船的港口 C = Cherbourg, Q = Queenstown, S = Southampton
检查数据
检查数据的第一步是完整性。
len(data) #数据集长度
示例结果:
891
data.isnull().sum() #查看 null 值,查看非空使用 notnull()
示例结果:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
总共有 891 个游客的数据,177 个 Age 缺失,687 个 Cabin 缺失,2 个 Embarked 缺失。在后面我们需要用不同的方法补充这些数据。
然后,我们查看特征类别分布是否平衡。类别平衡指分类样例不同类别的训练样例数目差别不大。当差别很大时,为类别不平衡。当类别不平衡的时候,例如正反比为 9:1,学习器将所有样本判别为正例的正确率都能达到 0.9。这时候,我们就需要使用 “再缩放”、“欠采样”、“过采样”、“阈值移动” 等方法。
sns.countplot(x='Survived',data=data) #对不同值的 'Survived' 进行计数并绘图
示例结果:

图的纵坐标表示在不同类别下的人数。相差不是特别大,我们认为属于类别平衡问题。
接下来,我们查看特征值分布和格式。在这里,我们观察每个特征特征值是什么格式,怎么分布,维度如何。
data.head(5)
示例结果:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
- Cabin, Embarked 等特征值数值化
- Ticket 等高维数据降维处理并将特征值数值化
- Fare,Age 等为连续数据,之后需要检查是否是偏态数据
接下来,删除无用的特征 PassengerId, Name。
data.drop(['PassengerId','Name'],axis=1,inplace=True) #删除 data['PassengerId','Name'] 两列数据,axis=1 表示删除列,axis=0 表示删除行,inplace=True 原位删除
data.columns
示例结果:
Index(['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Ticket', 'Fare',
'Cabin', 'Embarked'],
dtype='object')
相关系数
参考 知乎关于相关系数、协方差的讨论
g=sns.heatmap(data[['Survived','SibSp','Parch','Age','Fare','Pclass']].corr(),cmap='RdYlGn',annot=True)
#corr() 计算相关系数,cmap 选择 color map,annot=True 显示相关系数
示例结果:

数值越大,相关性越大。Fare 和 Survived 有较大的正相关性。但这并不能说明其它的特征与 Survived 无关。
缺失值
根据不同的情况,可以使用中位数、平均值、众数填充,删除等方法处理缺失数据,更复杂的还有建模预测。
Age
作图 Age ~ Survived。年龄较小的孩子生存的几率大。补充缺失值后,我们必须检查是否对 Age ~ Survived 的性质产生影响。
Age0=data[(data['Survived']==0)&(data['Age'].notnull())]['Age'] #死亡乘客的 Age 数据
Age1=data[(data['Survived']==1)&(data['Age'].notnull())]['Age'] #生存乘客的 Age 数据
g=sns.kdeplot(Age0,legend=True,shade=True,color='r',label='NotSurvived') #死亡乘客年龄概率分布图, shade=True 设置阴影
g=sns.kdeplot(Age1,legend=True,shade=True,color='b',label='Survived') #生存乘客概率分布图
示例结果:

根据 heatmap(热力图), Age 和 SibSp, Parch, Pclass 相关性高,我们再用箱型图直观感受下,以图形 Sex ~ Age, Pclass ~ Age 为例。
g=sns.factorplot(x='Sex',y='Age',data=data,kind='box')
g=sns.factorplot(x='Pclass',y='Age',data=data,kind='box')
示例结果:

上面两图说明男性和女性的年龄分布(指箱型图中的五条线,从上到下依次是最大值、四分位数、中位数、四分位数、最小值)基本一致,而购买不同等级票的人的年龄分布是不同的。所以,我们根据票的等级将数据分为不同的集合,再用缺失数据所在集合的平均值来进行填充,并检查填充后 Age ~ Survived 是否受到影响。
index = list(data[data['Age'].isnull()].index) #Age 缺失样例的 index
Age_mean = np.mean(data[data['Age'].notnull()]['Age']) #求平均值
copy_data = data.copy()
for i in index:
filling_age = np.mean(copy_data[(copy_data['Pclass'] == copy_data.iloc[i]['Pclass'])
& (copy_data['SibSp'] == copy_data.iloc[i]['SibSp'])
& (copy_data['Parch'] == copy_data.iloc[i]['Parch'])
]['Age'])
if not np.isnan(filling_age): # filling_age 非空为真
data['Age'].iloc[i] = filling_age #填充 null 值
else: # filling_age 空为真
data['Age'].iloc[i] = Age_mean
g = sns.kdeplot(Age0, legend=True, shade=True, color='r', label='NotSurvived')
g = sns.kdeplot(Age1, legend=True, shade=True, color='b', label='Survived')
示例结果:
Embarked
对于只有极少数缺失值的特征,我们可以选择删除该样例,使用众数、均值、中位数填充。
Cabin
对于这种复杂,高维的数据,我们需要挖掘它的规律。例如 Cabin 特征值由字母开头,判断船舱按字母分为 A,B,C...
于是我们仅提取字母编号,降低维度。然后使用新的字母‘U’填充缺失数据。
data[data['Cabin'].notnull()]['Cabin'].head(10)
示例结果:
1 C85
3 C123
6 E46
10 G6
11 C103
21 D56
23 A6
27 C23 C25 C27
31 B78
52 D33
Name: Cabin, dtype: object
# fillna() 填充 null 值
data['Cabin'].fillna('U',inplace=True)
# 使用 lambda 表达式定义匿名函数对 i 执行 list(i)[0]。map() 指对指定序列 data ['Cabin'] 进行映射,对每个元素执行 lambda
data['Cabin']=data['Cabin'].map(lambda i: list(i)[0])
# kind='bar' 绘制条形图,ci=False 不绘制概率曲线,order 设置横坐标次序
g = sns.factorplot(x='Cabin',y='Survived',data=data,ci=False,kind='bar',order=['A','B','C','D','E','F','T','U'])
示例结果:

g = sns.countplot(x='Cabin',hue='Pclass',data=data,order=['A','B','C','D','E','F','T','U']) # hue='Pclass' 表示根据 'Pclass' 进行分类
示例结果:

从上面的图中看得出,缺失数据的游客主要是三等舱的,并且这部分游客的生存率相对较低。
偏态分布
偏态分布的数据有时不利于模型发现数据中的规律,我们可以使用 Log Transformation 来处理数据,参考 Skewed Distribution and Log Transformation
Fare
g=sns.kdeplot(data[data['Survived']==0]['Fare'],shade='True',label='NotSurvived',color='r') # 死亡乘客 'Fare' 分布
g=sns.kdeplot(data[data['Survived']==1]['Fare'],shade='True',label='Survived',color='b') # 生存乘客 'Fare' 分布
示例结果:

Fare 属于右偏态分布,Python 提供了计算数据偏态系数的函数 skew(), 计算值越大,数据偏态越明显。使用 Log Transformation 后,我们看到计算值从 4.79 降到 0.44。
data['Fare']=data['Fare'].map(lambda i:np.log(i) if i>0 else 0) # 匿名函数为对非零数据进行 Log Transformation,否则保持零值
g=sns.distplot(data['Fare'])
print('Skew Coefficient:%.2f' %(data['Fare'].skew())) # skew() 计算偏态系数
示例结果:

数值化和标准化
Ticket
Ticket 特征值中的一串数字编号对我们没有意义,忽略。下面代码中,我们用正则表达式过滤掉这串数字,并使用 pandas get_dummies 函数进行数值化(以 Ticket 特征值 作为新的特征,0,1 作为新的特征值)。参考正则表达式
Ticket=[]
import re
r=re.compile(r'\w*')#正则表达式,查找所有单词字符[a-z/A-Z/0-9]
for i in data['Ticket']:
sp=i.split(' ')#拆分空格前后字符串,返回列表
if len(sp)==1:
Ticket.append('U')#对于只有一串数字的 Ticket,Ticket 增加字符 'U'
else:
t=r.findall(sp[0])#查找所有单词字符,忽略符号,返回列表
Ticket.append(''.join(t))#将 t 中所有字符串合并
data['Ticket']=Ticket
data=pd.get_dummies(data,columns=['Ticket'],prefix='T')#get_dummies:如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)
data.columns
示例结果:
Index(['Survived', 'Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Cabin',
'Embarked', 'T_A4', 'T_A5', 'T_AS', 'T_C', 'T_CA', 'T_CASOTON', 'T_FC',
'T_FCC', 'T_Fa', 'T_PC', 'T_PP', 'T_PPP', 'T_SC', 'T_SCA4', 'T_SCAH',
'T_SCOW', 'T_SCPARIS', 'T_SCParis', 'T_SOC', 'T_SOP', 'T_SOPP',
'T_SOTONO2', 'T_SOTONOQ', 'T_SP', 'T_STONO', 'T_STONO2', 'T_SWPP',
'T_U', 'T_WC', 'T_WEP'],
dtype='object')
Sex
Sex 只有 male, female 两个特征值,用 0 替代 male, 1 替代 female。
data['Sex'].replace('male',0,inplace=True)#inplace=True 原位替换
data['Sex'].replace('female',1,inplace=True)
离群点
离群点是显著偏离数据集中其余对象的点。离群点来源于操作失误,数据本身的可变性等。在不同的环境中,离群点扮演不同角色。例如一个人的年龄 300 岁,应予以删除,而某些环境中,我们却需要探测、研究离群点,例如欺诈检测。
我们这里采用箱线法, 检测特征 ['Age', 'Parch', 'SibSp', 'Fare'] 的离群点。参考离群点和箱线法
from collections import Counter
def outlier_detect(n, df, features):#定义函数 outlier_detect 探测离群点,输入变量 n, df, features,返回 outlier
outlier_index = []
for feature in features:
Q1 = np.percentile(df[feature], 25)#计算上四分位数(1/4)
Q3 = np.percentile(df[feature], 75)#计算下四分位数(3/4)
IQR = Q3 - Q1
outlier_span = 1.5 * IQR
col = ((data[data[feature] > Q3 + outlier_span]).index |
(data[data[feature] < Q1 - outlier_span]).index)
outlier_index.extend(col)
print('%s: %f (Q3+1.5*IQR) , %f (Q1-1.5*QIR) )' %
(feature, Q3 + outlier_span, Q1 - outlier_span))
outlier_index = Counter(outlier_index)#计数
outlier = list(i for i, j in outlier_index.items() if j >= n)
print('number of outliers: %d' % len(outlier))
print(df[['Age', 'Parch', 'SibSp', 'Fare']].loc[outlier])
return outlier
outlier = outlier_detect(3, data, ['Age', 'Parch', 'SibSp', 'Fare'])#调用函数 outlier_detect
示例结果:
Age: 59.500000 (Q3+1.5*IQR) , -0.500000 (Q1-1.5*QIR) )
Parch: 0.000000 (Q3+1.5*IQR) , 0.000000 (Q1-1.5*QIR) )
SibSp: 2.500000 (Q3+1.5*IQR) , -1.500000 (Q1-1.5*QIR) )
Fare: 5.482703 (Q3+1.5*IQR) , 0.019461 (Q1-1.5*QIR) )
number of outliers: 4
Age Parch SibSp Fare
438 64.0 4 1 5.572154
27 19.0 2 3 5.572154
88 23.0 2 3 5.572154
341 24.0 2 3 5.572154
这里我们检测出 4 个离群点,使用 drop 函数删除即可。
实验总结一
本实验我们介绍了数据清洗的基本思路,大家不仅需要掌握数据清洗的基础知识,还要善于利用数据分析工具。同时,不同环境,数据清洗的方法不同,这就要求我们多做练习。
【二】分类模型训练及评价
介绍
实验将评估不同模型的测试精度以及过拟合问题。学习器没有最好,只有适不适合,模型评估和性能度量的重要性可想而知。比起上节课,这节课将会轻松愉快很多。我们重点在模型评估的实现过程,对分类算法不了解的不用担心,实验 三中,我们将对算法以及进行深入学习。
知识点
- 交叉验证法
- 过拟合
- 学习曲线
环境准备
下载数据
!wget http://labfile.oss.aliyuncs.com/courses/1001/data.csv #经过完整数据清洗后的数据
模型评估
模型选择
学习器在训练集上的误差称为 “训练误差” 或者 “经验误差”,在新的样本上的误差称为“泛化误差”。我们希望得到的是泛化误差小的学习器。通常,我们利用“测试集” 来测试学习器对新样本的判别能力,以得到的 “测试误差” 来近似泛化误差。基于这种思想的学习器的评估方法,有留出法、k 折交叉验证法、留一法、自助法:
- 留出法 (hold-out):将数据集 D 划分为训练集 S 和测试集 T。通常 S 与 T 比例为 2/3 ~ 4/5。
- k 折交叉验证(k-fold cross validation):将 D 划分 k 个大小相似的子集(每份子集尽可能保持数据分布的一致性:子集中不同类别的样本数量比例与 D 基本一致),其中一份作为测试集,剩下 k-1 份为训练集 T,操作 k 次。 例如 D 划分为 D1,D2,... ,D10,第一次使用 D1 作为测试集,第二次使用 D2,第三次使用 D3, ... , 第十次使用 D10 作为测试集。最后计算 k 次测试误差的平均值近似泛化误差。
- 留一法(Leave-One-out):k 折交叉验证法的特例,即每次测试集 T 只留一个数据,剩下的作为训练集 S
- 自助法(bootstrapping):每次从数据集 D 中有放回地采一个样本,并将这个样本放入训练集 S 中,重复 m 次。则训练集中有 m 个训练样本,将未在训练集中的样本放入测试集 T。
留出法和 k 折交叉验证法需要划分一部分样本作为测试集,就引入由于训练样本规模不同而产生的偏差。留一法改善了这一问题,但计算复杂度高。自助法也改善了这一个问题,但改变了数据集分布,同样会引入偏差,该方法适合数据集较小的情况。所以,留出法和 k 折交叉验证法是最常用的。这里选择 k 折交叉验证法进行模型评估。
Python sklearn.model_selection 提供了 Stratified k-fold。参考 Stratified k-fold
我推荐使用 sklearn cross_val_score。这个函数输入我们选择的算法、数据集 D,k 的值,输出训练精度(误差是错误率,精度是正确率)。对于分类问题,默认采用 stratified k-fold 方法。参考 sklearn cross_val_score
下面我们用 10 折交叉验证法(k=10)对两种常用的集成学习算法 AdaBoost 以及 Random Forest 进行评估。最后我们看到 Random Forest 比 Adaboost 效果更好。
import pandas as pd
import numpy as np
import matplotlib as plt
%matplotlib inline
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
data = pd.read_csv('data.csv')
data.head(5)
示例结果:
| Unnamed: 0 | Survived | Sex | Age | SibSp | Parch | Fare | Pc_1 | Pc_2 | Pc_3 | ... | T_SOPP | T_SOTONO2 | T_SOTONOQ | T_SP | T_STONO | T_STONO2 | T_SWPP | T_WC | T_WEP | T_X | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 22.0 | 1 | 0 | 1.981001 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 38.0 | 1 | 0 | 4.266662 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 2 | 1 | 1 | 26.0 | 0 | 0 | 2.070022 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 3 | 1 | 1 | 35.0 | 1 | 0 | 3.972177 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 4 | 0 | 0 | 35.0 | 0 | 0 | 2.085672 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
y = data['Survived']
X = data.drop(['Survived'], axis=1).values
classifiers = [AdaBoostClassifier(
random_state=2), RandomForestClassifier(random_state=2)]
for clf in classifiers:
score = cross_val_score(clf, X, y, cv=10, scoring='accuracy')#cv=10:10 折交叉验证法,scoring='accuracy':返回测试精度
print([np.mean(score)])#显示测试精度平均值
示例结果:
[0.7353336738168198]
[0.8047636477130858]
性能度量
过拟合是学习器性能过好,把样本的一些特性当做了数据的一般性质,从而导致训练误差低但泛化误差高。学习曲线是判断过拟合的一种方式,同时可以判断学习器的表现。学习曲线包括训练误差(或精度)随样例数目的变化曲线与测试误差(或精度)随样例数目的变化曲线。
下面我将以训练样例数目为横坐标,训练精度和测试精度为纵坐标绘制学习曲线,并分析 Random Forest 算法的性能。大家可以参考这篇博客进行深入学习 学习曲线
from sklearn.model_selection import learning_curve
import matplotlib.pyplot as plt
# 定义函数 plot_learning_curve 绘制学习曲线。train_sizes 初始化为 array([ 0.1 , 0.325, 0.55 , 0.775, 1\. ]),cv 初始化为 10,以后调用函数时不再输入这两个变量
def plot_learning_curve(estimator, title, X, y, cv=10,
train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title) # 设置图的 title
plt.xlabel('Training examples') # 横坐标
plt.ylabel('Score') # 纵坐标
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv,
train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1) # 计算平均值
train_scores_std = np.std(train_scores, axis=1) # 计算标准差
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid() # 设置背景的网格
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha=0.1, color='g') # 设置颜色
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha=0.1, color='r')
plt.plot(train_sizes, train_scores_mean, 'o-', color='g',
label='traning score') # 绘制训练精度曲线
plt.plot(train_sizes, test_scores_mean, 'o-', color='r',
label='testing score') # 绘制测试精度曲线
plt.legend(loc='best')
return plt
g = plot_learning_curve(RandomForestClassifier(), 'RFC', X, y) # 调用函数 plot_learning_curve 绘制随机森林学习器学习曲线
示例结果:

Random Forest 的学习曲线我们得到了,训练误差始终接近 0,而测试误差始终偏高,说明存在过拟合的问题。这个问题的产生是因为 Random Forest 算法使用决策树作为基学习器,而决策树的一些特性将造成较严重的过拟合。这个问题的具体原因以及解决方法将在下一节课讲解。
实验总结二
本实验我们使用交叉验证法以及学习曲线对模型选择和性能评估进行了实例讲解,并练习使用 sklearn 机器学习工具。下节课我们将深入学习如何真的随机森林分类器调参。
【三】随机森林分类器及其参数调节
介绍
本实验我们将学习集成学习的随机森林算法,参数调节,并解决上一节实验当中遇到的过拟合问题。我们将继续使用 Python sklean 机器学习工具。
知识点
- 决策树
- 集成学习
- 随机森林算法
- 参数调节
本实验衔接着上一个实验,我们需要导入先前的模块和载入数据
教学代码:
!wget -nc http://labfile.oss.aliyuncs.com/courses/1001/data.csvimport pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score data = pd.read_csv('data.csv') data.head(5) y = data['Survived'] X = data.drop(['Survived'], axis=1).values
实验原理
决策树
学习随机森林算法,首先需要了解决策树。这里可以参考 通俗易懂之决策树。以下知识点需要大家提前理解:
- 决策树的属性选择:划分属性时,在当前节点下,在属性集合中,选择最优的属性。
- 决策树的深度 n 对学习器性能的影响: n 太小有欠拟合风险,太大有过拟合风险。
- 划分选择算法: gini(基尼) 以及 entropy(熵)。
集成学习
集成学习就是构建并结合多个个体学习器(称为基学习器)来完成学习任务。举一个例子。下表中 √ 表示分类正确,× 表示分类错误。
| - | 学习器 1 | 学习器 2 | 学习器 3 |
|---|---|---|---|
| h1 | √ | √ | × |
| h2 | × | √ | √ |
| h3 | √ | × | √ |
| 集成(提升性能) | √ | √ | √ |
| - | 学习器 1 | 学习器 2 | 学习器 3 |
|---|---|---|---|
| h1 | √ | √ | × |
| h2 | √ | √ | × |
| h3 | √ | √ | × |
| 集成(不起作用) | √ | √ | × |
| - | 学习器 1 | 学习器 2 | 学习器 3 |
|---|---|---|---|
| h1 | × | × | √ |
| h2 | × | √ | × |
| h3 | √ | × | × |
| 集成(起负作用) | × | × | × |
由上面三个表,我们看到集成学习器是通过少数服从多数的原则来进行分类结果的最终选择,这就要求我们的基学习器具有第一个表的特性:性能好,并且不一样(即好而不同)。随着基学习器数目的增加,集成的错误率剧烈下降直至为 0。
随机森林
随机森林以决策树为基学习器。但是属性选择与决策树不同。随机森林中,基决策树学习器在每个节点上,从该节点的属性集合中随机选择包含 K 个属性的子集,再从子集中选择最优属性用于划分。这就满足 “好而不同” 的条件。随机森林计算开销小,是现在机器学习算法当中水平较高的算法。
Python sklearn 参数调节

| 参数 | 特点 | |
|---|---|---|
| n_estimators | 基学习器数目(默认值 10) | 基本趋势是值越大精度越高 ,直到达到一个上限 |
| criterion(标准) | 选择算法 gini 或者 entropy (默认 gini) | 视具体情况定 |
| max_features | 2.2.3 节中子集的大小,即 k 值(默认 sqrt(n_features)) | |
| max_depth | 决策树深度 | 过小基学习器欠拟合,过大基学习器过拟合。粗调节 |
| max_leaf_nodes | 最大叶节点数(默认无限制) | 粗调节 |
| min_samples_split | 分裂时最小样本数,默认 2 | 细调节, 越小模型越复杂 |
| min_samples_leaf | 叶节点最小样本数,默认 2 | 细调节,越小模型越复杂 |
| bootstrap | 是否采用自助法进行样本抽样(默认使用) | 决定基学习器样本是否一致 |
在以上参数中,只有 n_estimators 对精度的影响是单调的。粗调节表示参数选择跨度大,以 10、100 等为单位。细调节参数选择跨度小,以 1、2 等为单位。
交叉验证法调参
我们首先调节:n_estimators,max_depth。首先观察特征数目,这决定了 max_depth 等参数的范围。然后使用交叉验证法调参。
len(X[0])
示例结果:
51
def para_tune(para, X, y): #
clf = RandomForestClassifier(n_estimators=para) # n_estimators 设置为 para
score = np.mean(cross_val_score(clf, X, y, scoring='accuracy'))
return score
def accurate_curve(para_range, X, y, title):
score = []
for para in para_range:
score.append(para_tune(para, X, y))
plt.figure()
plt.title(title)
plt.xlabel('Paramters')
plt.ylabel('Score')
plt.grid()
plt.plot(para_range, score, 'o-')
return plt
g = accurate_curve([2, 10, 50, 100, 150], X, y, 'n_estimator tuning')
示例结果:

def para_tune(para, X, y):
clf = RandomForestClassifier(n_estimators=300, max_depth=para)
score = np.mean(cross_val_score(clf, X, y, scoring='accuracy'))
return score
def accurate_curve(para_range, X, y, title):
score = []
for para in para_range:
score.append(para_tune(para, X, y))
plt.figure()
plt.title(title)
plt.xlabel('Paramters')
plt.ylabel('Score')
plt.grid()
plt.plot(para_range, score, 'o-')
return plt
g = accurate_curve([2, 10, 20, 30, 40], X, y, 'max_depth tuning')
示例结果:
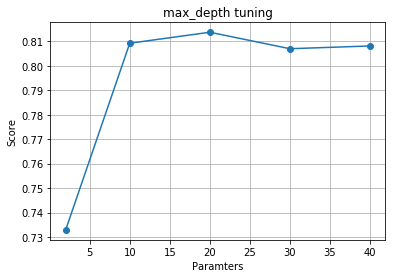
得到最优参数 n_estimators=100,max_depth=10。
scikit-learn 自动调参函数 GridSearchCV
接下来我们使用这个函数来选择最优的学习器,并绘制上一节实验学到的学习曲线。
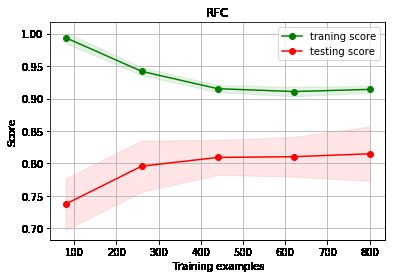
观察学习曲线,训练精度随样例数目增加而减小,测试精度则增加,过拟合程度降低。并且从学习曲线的变化趋势看,测试精度将随着训练样例的数目的增加而进一步增加。实际上,决策树的深度以及基学习器的数目起主要的作用。
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import learning_curve
def plot_learning_curve(estimator, title, X, y, cv=10,
train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure()
plt.title(title) # 设置图的 title
plt.xlabel('Training examples') # 横坐标
plt.ylabel('Score') # 纵坐标
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y, cv=cv,
train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1) # 计算平均值
train_scores_std = np.std(train_scores, axis=1) # 计算标准差
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid() # 设置背景的网格
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std,
alpha=0.1, color='g') # 设置颜色
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std,
alpha=0.1, color='r')
plt.plot(train_sizes, train_scores_mean, 'o-', color='g',
label='traning score') # 绘制训练精度曲线
plt.plot(train_sizes, test_scores_mean, 'o-', color='r',
label='testing score') # 绘制测试精度曲线
plt.legend(loc='best')
return plt
clf = RandomForestClassifier()
para_grid = {'max_depth': [10], 'n_estimators': [100], 'max_features': [1, 5, 10], 'criterion': ['gini', 'entropy'],
'min_samples_split': [2, 5, 10], 'min_samples_leaf': [1, 5, 10]}#对以上参数进行网格搜索
gs = GridSearchCV(clf, param_grid=para_grid, cv=3, scoring='accuracy')
gs.fit(X, y)
gs_best = gs.best_estimator_ #选择出最优的学习器
gs.best_score_ #最优学习器的精度
g = plot_learning_curve(gs_best, 'RFC', X, y)#调用实验2中定义的 plot_learning_curve 绘制学习曲线示例结果:
实验总结三
本小节学习了随机森林算法以及 sklearn 工具的使用。并且通过参数调节,缓解了过拟合现象。