AI人工智能(调包侠)速成之路十一(AlphaZero代码实战3:神经网络实现)
AlphaZero巧妙了使用MCTS搜索树和神经网络一起,通过MCTS搜索树优化神经网络参数,反过来又通过优化的神经网络指导MCTS搜索。两者一主一辅,非常优雅的解决了这类状态完全可见,信息充分的棋类问题。前面结合一个五子棋AI的案例代码实现了蒙特卡洛树搜索,这次我们使用Tensorflow2来实现神经网络的部分。
AI人工智能(调包侠)速成之路十(AlphaZero代码实战2:蒙特卡洛树搜索)
神经网络输入特征的设计
神经网络的输入特征设计等同于传统程序设计里面的“数据结构”设计,在Tensorflow2中使用Numpy多维数组作为输入,然后转换为tensor变量再经过不同的网络层逐层变换,最后按我们设计的分类问题或者数值回归问题输出结果。
输入特征基本上按照解决问题所需要的充分必要信息来设计,如果硬件条件允许也可以多增加输入信息,增加的信息要能帮助到解决问题,否则只是浪费资源和增加消耗的时间。比如我们前面介绍(mnist手写数字识别)输入信息是28*28*1,我们也可以输入彩色图片信息28*28*3,输入信息增加了三倍但是对于识别数字这个问题来说是没有必要的,但是如果我们的问题不但要识别数字还要分辨颜色的话就必须输入彩色图片信息28*28*3,否则分辨颜色的功能就无法实现。
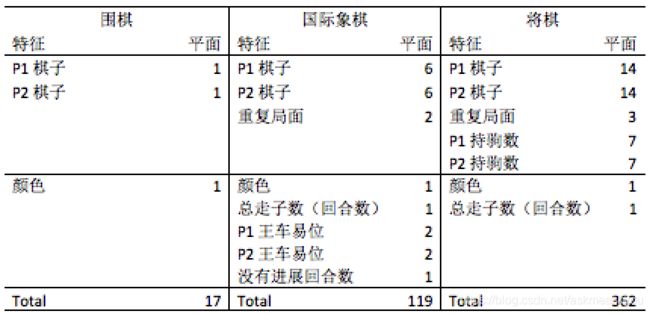
AlphaZero围棋输入的是19×19×17维度的图像栈 ,我们这个五子棋的网络用15×15×4维度已经够用了。
# 定义网络结构
# 1. 输入
self.input_states = tf.keras.layers.Input([4, board_width, board_width], dtype='float32', name='input_states') # TODO C plain x 2
self.input_state = tf.transpose(self.input_states, [0, 2, 3, 1], name="input_state")
# 2. 中间层
# 2.1 卷积层
X = tf.keras.layers.Conv2D(filters=64, kernel_size=[3, 3], padding="same", data_format="channels_last")(self.input_state)
X = tf.keras.layers.BatchNormalization(epsilon=1e-5, fused=True)(X)
X = tf.nn.relu(X)为了程序代码方便我们输入用4*15*15的格式,输入后用tf.transpose将格式转换为15*15*4格式。接着使用一个卷积层变换输入信息(mnist手写数字识别3:cnn卷积神经网络实现 卷积层忘记的看这里)。
Batch Normalization
Batch Normalization,简称BN,来源于《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》,中文叫批量归一化/批量标准化?好像没有很好的翻译。用一个Batch的均值和方差作为对整个数据集均值和方差的估计。随着网络的深度增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,这样继续下去就会导致梯度消失。BN就是通过方法将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。
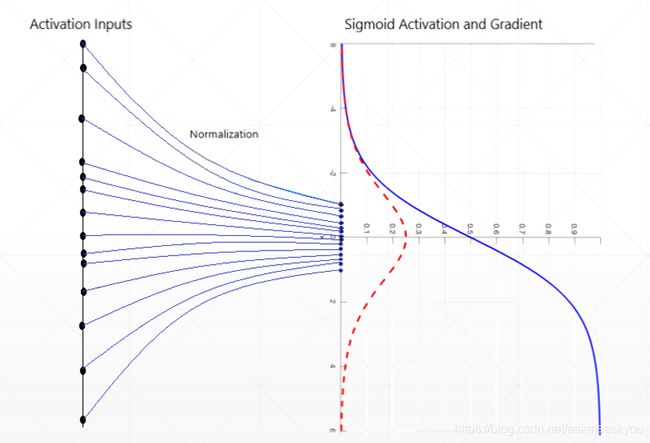
深度神经网络中每一个中间层都是下一层的输入,在输入下一层之前用tf.keras.layers.BatchNormalization做一下变换。
深度残差网络ResNet
深度残差网络ResNet是2015年何凯明博士(广东省高考状元,进入清华,2011年香港中文大学博士毕业后正式加入微软亚洲研究院MSRA)在MSRA提出的。之前的神经网络超过20层以后就变得很难训练成功,ResNet出来以后网络深度可以达到上千层,深度神经网络取得了质的飞跃。

深度学习目前进展取决于技巧:初始权值选择,局部感受野,权值共享等等,但使用更深层的网络时,依然要面对反向传播时梯度消失这类传统困难,层数越多,训练错误率与测试错误率反而升高。ResNet相当于将学习目标改变了,不再学习如何完整的输出结果,而是学习输入和输出的差别,即残差。数学上可以证明加入“短接”是对训练参数最好的选择。
# 2.2 残差层
def residual_block(input):
X = tf.keras.layers.Conv2D(filters=64, kernel_size=[3, 3], padding="same", data_format="channels_last")(input)
X = tf.keras.layers.BatchNormalization(epsilon=1e-5, fused=True)(X)
X = tf.nn.relu(X)
X = tf.keras.layers.Conv2D(filters=64, kernel_size=[3, 3], padding="same", data_format="channels_last")(X)
X = tf.keras.layers.BatchNormalization(epsilon=1e-5, fused=True)(X)
add = tf.add(X, input)
return tf.nn.relu(add)
for i in range(7):
X = residual_block(X)目前残差层还需要自己实现,实现代码如上。短接操作使用 tf.add,要注意两个相加的内容维度要保持一致。定义完残差层就可以用一个循环堆叠多层使用,上面代码使用7个残差层串联起来。
网络输出 概率向量P数组输出:
# 3. P数组输出
Y = tf.keras.layers.Conv2D(filters=2, kernel_size=[1, 1], padding="same", data_format="channels_last")(X)
Y = tf.keras.layers.BatchNormalization(epsilon=1e-5, fused=True)(Y)
Y = tf.nn.relu(Y)
self.action_conv_flat = tf.reshape(Y, [-1, 2 * board_width * board_width], name="action_conv_flat")
self.action_fc = tf.keras.layers.Dense(board_width * board_width,activation=tf.nn.log_softmax)(self.action_conv_flat)网络输出 胜率v值输出
# 4. v值输出
Y = tf.keras.layers.Conv2D(filters=1, kernel_size=[1, 1], padding="same", data_format="channels_last")(X)
Y = tf.keras.layers.BatchNormalization(epsilon=1e-5, fused=True)(Y)
Y = tf.nn.relu(Y)
self.evaluation_conv_flat = tf.reshape(Y, [-1, 1 * board_width * board_width], name="evaluation_conv_flat")
self.evaluation_fc1 = tf.keras.layers.Dense(64, activation='relu', name="evaluation_fc1")(self.evaluation_conv_flat)
self.evaluation_fc2 = tf.keras.layers.Dense(1, activation='tanh', name="evaluation_fc2")(self.evaluation_fc1)打印出网络结构
self.model = tf.keras.Model(
inputs=[self.input_states],
outputs=[self.action_fc, self.evaluation_fc2])
self.model.summary()
损失函数计算和优化器
# 定义损失函数
# 1. P数组损失函数
#self.policy_loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
# 2. v值损失函数
#self.value_loss = tf.keras.losses.MeanSquaredError()
# 3. L2正则项
#self.l2_penalty = tf.keras.metrics.MeanAbsoluteError()
# 4. 所有加起来成为损失函数
#self.loss = self.value_loss + self.policy_loss + self.l2_penalty
# 训练用的优化器
self.optimizer = tf.compat.v1.train.AdamOptimizer(learning_rate=self.learning_rate_fn, name="optimizer")
神经网络的输入是局面s,输出是预测的action概率向量p和胜率v,胜率是回归问题,优化自然用MSE损失,概率向量的优化要用softmax交叉熵损失,L2正则项是为了防止过拟合,目标就是最小化这个联合损失。就是让神经网络的预测跟MCTS的搜索结果尽量接近。
训练网络
def train_step(self, positions, pi, z, learning_rate=0.001):
with tf.GradientTape() as tape:
policy_head, value_head = self.model(positions, training=True)
loss = self.compute_loss(pi, z, policy_head, value_head)
metrics = self.compute_metrics(pi, policy_head)
grads = tape.gradient(loss, self.model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, self.model.trainable_variables),global_step=self.global_step, name='train_step')
return loss, metrics
使用神经网络预测
def policy_value(self, state_batch):
state_batch=np.array(state_batch)
state_batch = state_batch.astype(np.float32)
if len(state_batch.shape) == 3:
sp = state_batch.shape
state_batch=np.reshape(state_batch, [1, sp[0], sp[1], sp[2]])
log_act_probs, value = self.model(state_batch, training=False)
act_probs = np.exp(log_act_probs) #OverflowError: Python int too large to convert to C long
return act_probs, value现在神经网络部分全部完成。我们在下一篇实现一个人机对战的游戏界面,然后结合蒙特卡洛树搜索和神经网络估值实现AI交互。当然没有训练之前(他/她/它)的表现只能像个幼儿,后面就需要花费大量时间精力来刻意培养你的“小孩”了,训练好了就是人工智能,训练不好就变成人工智障了......。
AlphaZero代码实战系列 源代码打包
下载地址:https://download.csdn.net/download/askmeaskyou/12931806