目标检测——Yolov4
文章目录
-
- Bag of freebies(BOF)
-
- 数据增强
- 网络正则化的方法
- 类别不平衡,损失函数设计
- Bag of specials(BOS)
-
- SPPNet(Spatial Pyramid Pooling)
- CSPNet(Cross Stage Partial Network)
- CBAM(Convolutional Block Attention Module)
- PAN(Path Aggregation Network)
- 激活函数Mish
- eliminate grid sensitivity
- 整体网络架构
Bag of freebies(BOF)
数据增强
- 只增加训练成本,但是能显著提高精度,并不影响推理速度
- 数据增强:调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转
Mosaic data augmentation

Random Erase:用随机值或训练集的平均像素值替换图像的区域
Hide and Seek:根据概率设置随机隐藏一些补丁

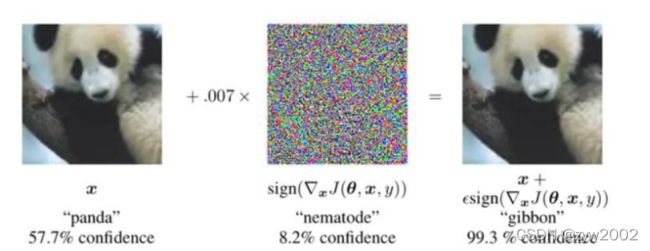
Self-adversarial-training(SAT): 通过引入噪音点来增加游戏难度
网络正则化的方法
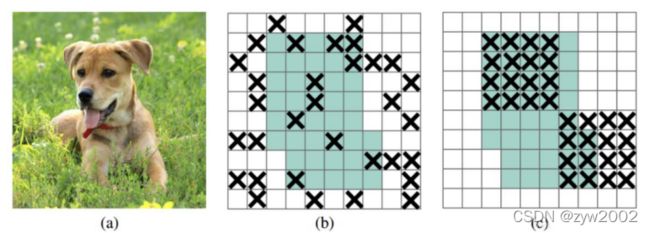
- 网络正则化的方法:Dropout、Dropblock等
DropBlock 之前的dropout是随机选择点(b),现在去掉一个区域。
类别不平衡,损失函数设计
Label Smoothing
神经网络最大的缺点:自觉不错(过拟合),让它别太自信。
例如原来标签为 ( 0 , 1 ) : [ 0 , 1 ] × ( 1 − 0.1 ) + 0.1 / 2 = [ 0.05 , 0.95 ] (0,1):[0,1] \times(1-0.1)+0.1 / 2=[0.05,0.95] (0,1):[0,1]×(1−0.1)+0.1/2=[0.05,0.95]

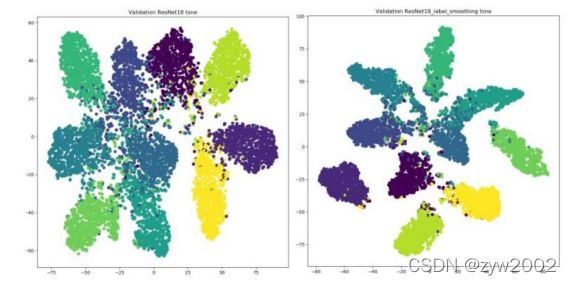
使用之后效果分析(右图):簇内更紧密,簇间更分离
IOU损失
IOU损失:1-IOU
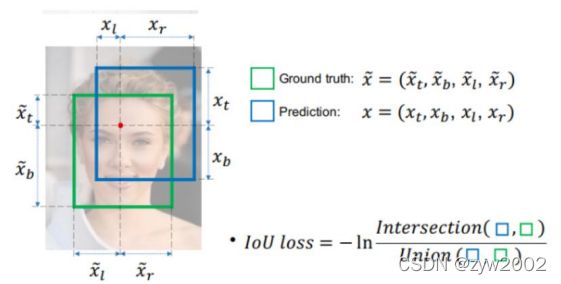
有哪些问题呢?
没有相交则IOU=0无法梯度计算,相同的IOU却反映不出实际情况到底是什么样子。
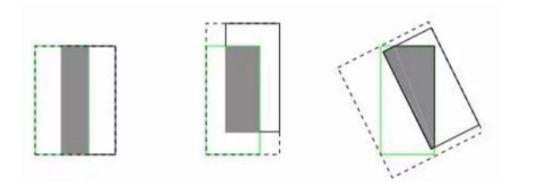
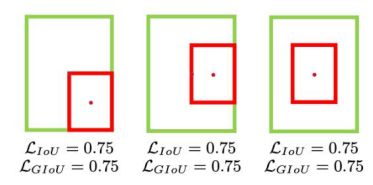
GIOU损失
公式: L G I o U = 1 − I o U + ∣ C − B ∪ B g t ∣ ∣ C ∣ \mathcal{L}_{G I o U}=1-I o U+\frac{\left|C-B \cup B^{g t}\right|}{|C|} LGIoU=1−IoU+∣C∣∣C−B∪Bgt∣
引入了最小封闭形状C(C可以把A,B包含在内)

在不重叠情况下能让预测框尽可能朝着真实框前进,但是如果两个框重叠,则失效。
DIOU损失
公式: L D I o U = 1 − I o U + ρ 2 ( b , b g t ) c 2 \mathcal{L}_{D I o U}=1-I o U+\frac{\rho^{2}\left(\mathbf{b}, \mathbf{b}^{g t}\right)}{c^{2}} LDIoU=1−IoU+c2ρ2(b,bgt)
其中分子计算预测框与真实框的中心点欧式距离d
分母是能覆盖预测框与真实框的最小BOX的对角线长度c
直接优化距离,速度更快,并解决GIOU问题

CIOU损失
公式: L C I o U = 1 − I o U + ρ 2 ( b , b g t ) c 2 + α v \mathcal{L}_{C I o U}=1-I o U+\frac{\rho^{2}\left(\mathbf{b}, \mathbf{b}^{g t}\right)}{c^{2}}+\alpha v LCIoU=1−IoU+c2ρ2(b,bgt)+αv v = 4 π 2 ( arctan w g t h g t − arctan w h ) 2 v=\frac{4}{\pi^{2}}\left(\arctan \frac{w^{g t}}{h^{g t}}-\arctan \frac{w}{h}\right)^{2} v=π24(arctanhgtwgt−arctanhw)2
α = v ( 1 − I o U ) + v \alpha=\frac{v}{(1-I o U)+v} α=(1−IoU)+vv
损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比
其中 α \alpha α 可以当做权重参数
DIOU-NMS
之前使用NMS来决定是否删除一个框,现在改用DIOU-NMS
公式: s i = { s i , IoU − R D I o U ( M , B i ) < ε , 0 , IoU − R D I o U ( M , B i ) ≥ ε , R D I o U = ρ 2 ( b , b g t ) c 2 s_{i}=\left\{\begin{array}{l}s_{i}, \operatorname{IoU}-\mathcal{R}_{D I o U}\left(\mathcal{M}, B_{i}\right)<\varepsilon, \\ 0, \operatorname{IoU}-\mathcal{R}_{D I o U}\left(\mathcal{M}, B_{i}\right) \geq \varepsilon,\end{array} \quad \mathcal{R}_{D I o U}=\frac{\rho^{2}\left(\mathbf{b}, \mathbf{b}^{g t}\right)}{c^{2}}\right. si={si,IoU−RDIoU(M,Bi)<ε,0,IoU−RDIoU(M,Bi)≥ε,RDIoU=c2ρ2(b,bgt)
不仅考虑了loU的值,还考虑了两个Box中心点之间的距离
其中M表示高置信度候选框,Bi就是遍历各个框跟置信度高的重合情况。
SOFT-NMS
更改分数而且直接剔除

Bag of specials(BOS)
增加稍许推断代价,但可以提高模型精度的方法
网络细节部分加入了很多改进,引入了各种能让特征提取更好的方法
注意力机制,网络细节设计,特征金字塔等
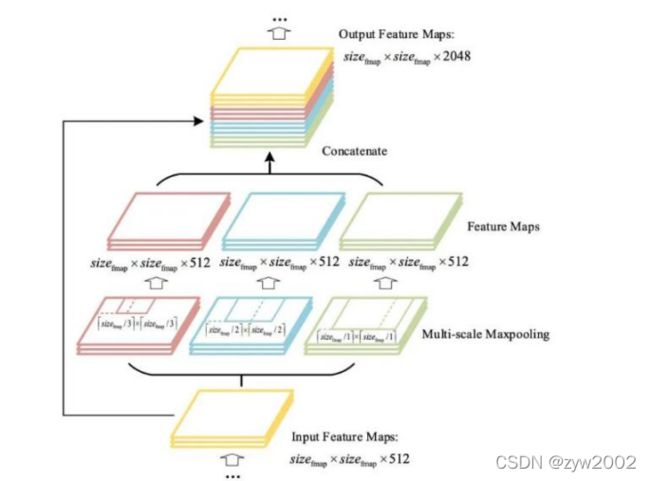
SPPNet(Spatial Pyramid Pooling)
V3中为了更好满足不同输入大小,训练的时候要改变输入数据的大小
SPP其实就是用最大池化来满足最终输入特征一致即可
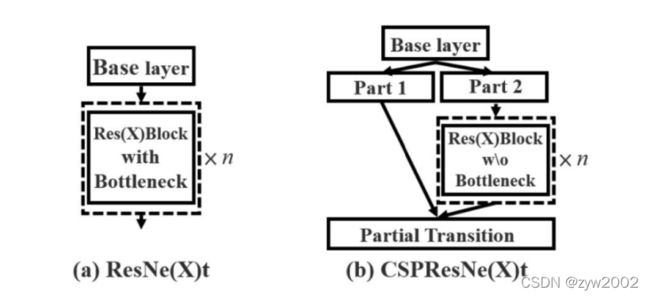
CSPNet(Cross Stage Partial Network)
每一个block按照特征图的channel维度拆分成两部分
一份正常走网络,另一份直接concat到这个block的输
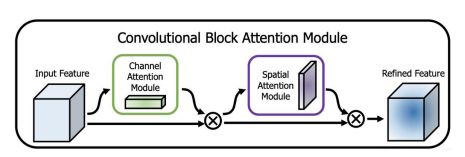
CBAM(Convolutional Block Attention Module)
注意力机制:包括通道注意力机制(Channel Attention Module)和空间的注意力机制(Spatial Attention Module)。
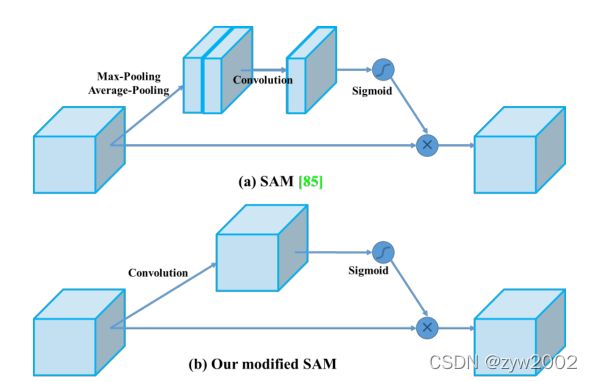
优点是更简单了,速度相对能更快一点。
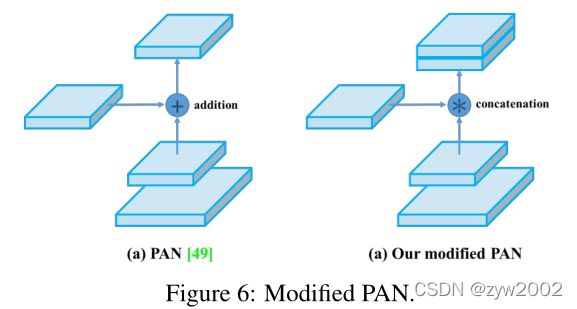
PAN(Path Aggregation Network)
得先从FPN说起,FPN自顶向下的模式,将高层特征传下来(不是双向的,我们希望增加一个自下向上的传递路径)
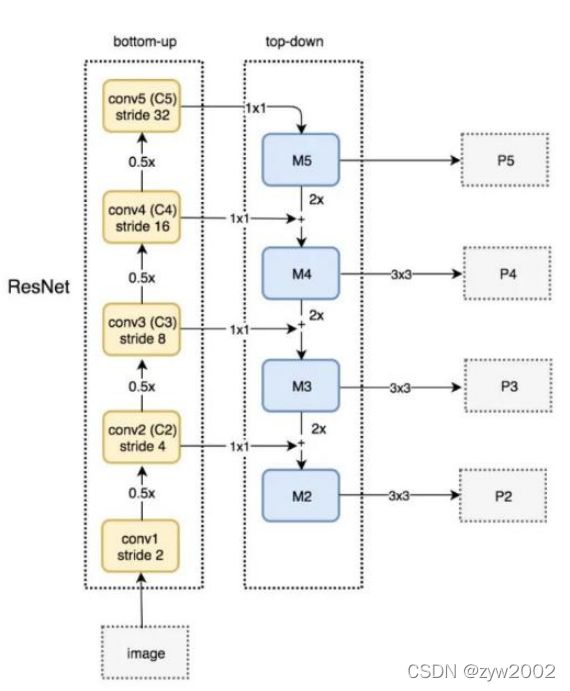
PAN 引入了自底向上的路径,使得底层信息更容易传到顶部,并且还是一个捷径

不同之处在于,YOLOV4中并不是加法,而是拼接
激活函数Mish
Mish 函数
Relu有点太绝对了,Mish更符合实际
公式: f ( x ) = x ⋅ tanh ( ln ( 1 + e x ) ) f(x)=x \cdot \tanh \left(\ln \left(1+e^{x}\right)\right) f(x)=x⋅tanh(ln(1+ex))
但是计算量确实增加了,效果会提升一点

eliminate grid sensitivity
比较好理解,坐标回归预测值都在0-1之间,如果在grid边界怎么表示?
此时就需要非常大的数值才可以达到边界,为了缓解这种情况可以在激活函数前加上一个系数(大于1的): b y = σ ( t y ) + c y b_{y}=\sigma\left(t_{y}\right)+c_{y} by=σ(ty)+cy

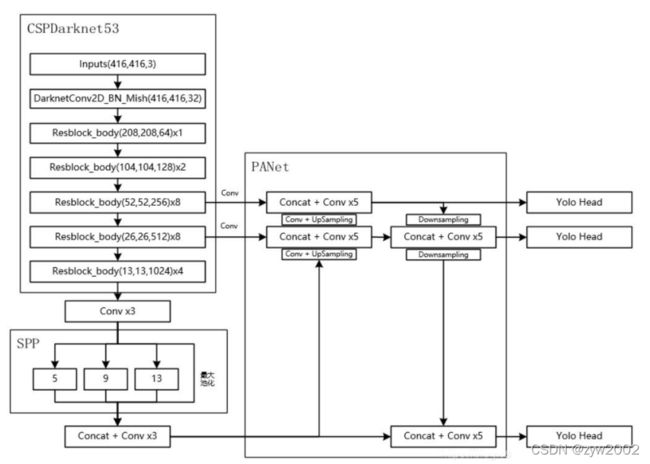
整体网络架构