数据库设计三范式详细介绍--数据库设计规范之数据库设计三范式
为什么需要数据库设计
1. 我们在设计数据表的时候要考虑很多问题问题,比如:
- 用户都需要什么数据?需要在数据表中保存哪些数据?
- 如果保证数据表中数据的正确性,当插入、删除、更新的时候该进行怎么样的约束检查?
- 如何降低数据表的数据冗余,保证数据表不会因为用户量的增长而迅速扩张?
- 如何让负责数据库维护的人员更方便使用数据库?
- 使用数据库的应用场景各不相同,可以说针对不同的情况设计出来的数据表可能千差万别。
2. 现实情况中面临的场景
当数据库运行一段时间之后我们才发现数据表设计有问题。重新调整数据表结构就需要做数据的迁移,还有可能影响程序的业务逻辑,以及网站的正常访问。
3. 如果是糟糕的数据库设计可能会造成以下问题
- 数据冗余、信息重复、存储空间浪费
- 数据更新、插入、删除异常
- 无法正确表示信息
- 丢失有效信息
- 程序性能差
4. 良好的数据库设计则有以下优点:
- 节省数据的存储空间
- 能够保证数据的完整性
- 方便进行数据库应用系统的开发
总之,开始设置数据库的时候我们需要重视数据表的设计。为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。
范式
范式简介
在关系型数据库中,关于数据表设计的基本原则、规范就成为范式。可以理解为,一张数据表的设计结构需要满足的某种设计标准的级别。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
范式的英文名称是Normal Form,简称NF。它是英国人在上个世纪70年代提出关系数据库模型后总结出来的。范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。
范式包含哪些
目前关系型数据库优六种常见范式,按照范式级别,从低到高分别是第一范式、第二范式、第三范式、巴斯-科德范式、第四范式和第五范式(又称完美范式)。
数据库的范式设计越高阶,冗余度就越低,同时高阶的范式一定符合低阶范式的要求,满足最低要求的范式是第一范式。在第一范式的基础上进一步满足更多规范要求的称为第二范式,其余以此类推。
一般来说,在关系型数据库设计中,最高也就遵循到巴斯范式,普遍是第三范式。但也不是绝对的,有时候为了提高某些查询性能,我们还需要破坏范式规则,也就是反范式化。
键和属性的概念
范式的定义会使用到主键和候选键,数据库中的键(key)由一个或多个属性组成。数据表中常用的几种键和属性的定义:
- 超键:能唯一标识元组(记录)的属性集叫做超键。
- 候选键:如果超键不包括多余的属性,那么这个超键就是候选键。
- 主键:用户可以从候选键中选择一个作为主键。
- 外键:如果数据表R1中的某属性集不是R1的主键,而是另一个表R2的主键,那么这个属性集就是数据表R1的外键。
- 主属性:包含在任一候选键中的属性称为主属性。
- 非主属性:与主属性相对,指的是不包含在任何一个候选键中的属性。
通常,我们可将候选键称之为“码”,把主键称为“主码”。因为键可能是有多个属性组成,针对单个属性我们还可以用主属性和非主属性来进行区分。
举例
这里有两个表:
球员表(player):球员编号 | 姓名 | 身份证号 |年龄 |球队编号
球队表:(team):球队编号|主教练|球队所在地
- 超键:对于球员表来说,超键就是包括球员编号或身份证号的任意组合,比如球员编号,球员编号和姓名,身份证号和年龄等。
- 候选键:就是最小的超键,对于球员表来说,候选键就是球员编号或者身份证号
- 主键:我们自己选定,也就是从候选键中选择一个,比如球员编号。
- 外键:球员表中的球队编号。
- 主属性、非主属性:在球员表中,主属性就是球员编号 身份证号,其他属性姓名 年龄 球队编号都是非主属性。
第一范式(1NF)
第一范式主要是确保数据表中每个字段的值必须具有原子性,也就是说数据表中每个字段的值为不可再拆分的最小数据单元。
我们在设计某个字段的时候,对于字段x来说,不能把字段x拆分成字段x1和字段x2.事实上,任何dbms都会满足第一范式的要求,不会将字段进行拆分。
举例1
假设一家公司要存储员工的姓名和练习方式,它创建一个如下的表
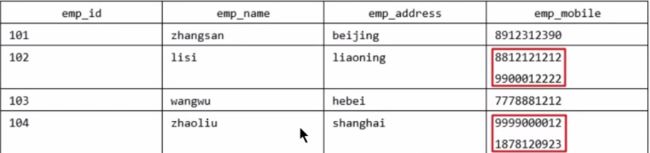
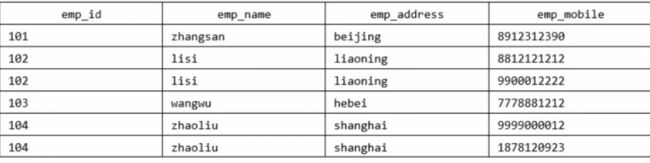
改变就不符合1NF,因为规则说表的每个属性必须是原子值,lisi和zhaoliu员工的emp_mobile值违反了改规则。为了使表符合1NF,我们应该用如下表:
举例2
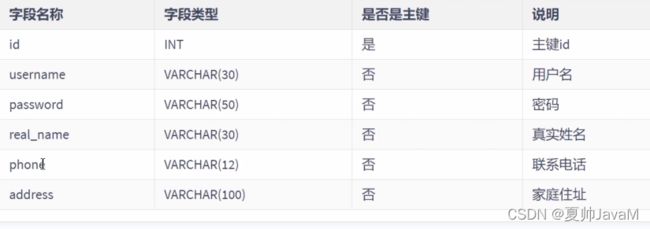
有一个user表

其不符合第一范式。其中user_info字段为用户信息,可以进一步拆分成更小粒度字段。将user_info拆分后如下
举例3
属性的原子性是主管的。* 例如employees*表中雇员姓名应当使用1个(fullname)、2个(firstname,lastname)还是3个(fistname,middlename,和lastname)属性表示呢?答案取决于应用程序。如果程序需要分别处理雇员的姓名部分(如:用于搜索目的),则有必要把它们分开。否则,不需要。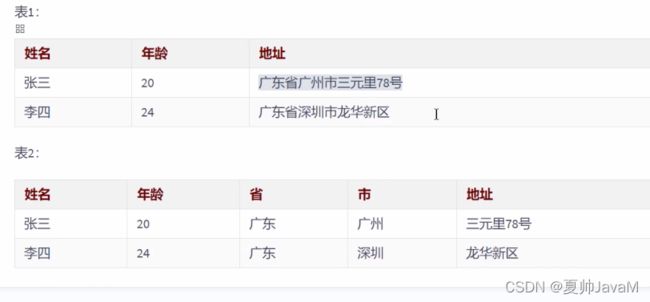
第二范式(2NF)
第二范式要求在满足第一范式的基础上,还要满足数据表里的每一条记录都是可唯一标识的。而且所有非主键字段,都必须完全依赖于主键,不能之依赖主键部分。如果知道主键的所有属性的值,就可以检索到任何行的任何属性的任何值。(要求中的主键,可以拓展替换为候选键)。
举例1
成绩表(学号、课程号、成绩)关系中,(学号,课程号)可以决定成绩,但是学号不能决定成绩,课程号也不能决定成绩。所以(学号,课程号)–》成绩就是完全依赖关系。
举例2
比赛表player_game里包含球员编号、姓名、年龄、比赛编号、比赛时间和比赛场地等属性。这里候选键和主键都为(球员编号,比赛编号),我们可以通过主键来决定如下的关系:
(球员编号,比赛编号)-----》(姓名,年龄,比赛时间,场地,得分)
但是这个表不满足第二范式,因为表中字段还存在如下关系:
(球员编号)—》(姓名,年龄)
(比赛编号)—》(比赛时间,比赛场地)
对于非主属性来说,并非完全依赖候主键。这样会产生怎么样的问题呢?
- 数据冗余,如果一个球员可以参加m场比赛,那么球员的姓名和年龄就要重复m-1次。一个比赛可能会有n个球员参加,比赛时间和场地就重复了n-1次。
- 插入异常,如果我们想要添加一场新的比赛,但是这时还没有确定参加的球员有谁,那么就无法插入。
- 删除异常,如果我要删除某个球员编号,如果没有单独保存比赛表的话,就会同时把比赛信息删除。
- 更新异常,如果我们调整了某个比赛时间,那么表中所有这个比赛时间都需要调整,否则就会出现一场比赛时间不同的情况。
为了避免出现上述的情况,我们可以把球员比赛表设计为下面三张表
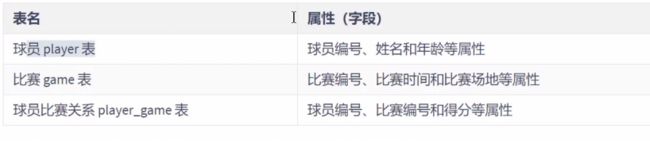
这样的话,每张数据表都符合第二范式,也就避免了异常情况的发生。
1NF告诉我们字段属性需要是原子性,而2NF告诉我们一张表就是一个独立的对象,一张表只表达一个意思
举例3
定义了一个名为Orders的关系,表示订单和订单行的信息
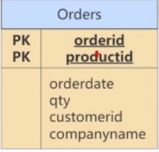
违反了第二范式,因为有非主属性依赖于候选键(或主键)的一部分。例如,可以通过orderid找到订单的orderdate,以及customerid和companyname而没有必要再去使用productid
修改:
Orders表和OrderDetails表如下,此时符合第二范式。
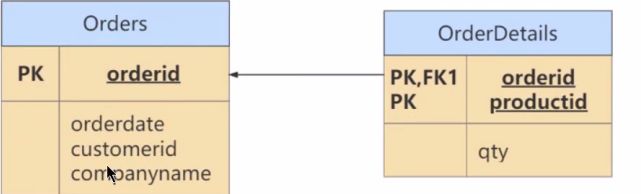
小结:第二范式要求实体的属性完全依赖于主键字段。如果存在不完全依赖,那么这个属性和主键字段的一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多关系
第三范式(3NF)
第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都和主键字段直接相关,也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。即为不存在非主属性A依赖于非主属性B,非主属性B依赖于主键C的情况。通俗说,改规则的意思是所有非主属性之间不能有依赖关系,必须相互独立。
这里的主键可以拓展为候选键。
举例1
部门信息表:每个部门有部门编号、部门名称、部门简介等信息。
员工信息表:每个员工有员工编号、姓名、部门编号。列出部门编号就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。
如果不存在部门信息表,则根据3NF也应该构建它,否则就会又大量的数据冗余。
举例2
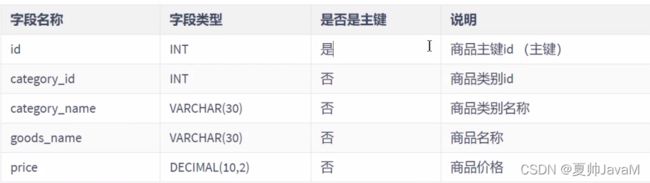
商品类别名称依赖于商品类别id不符合3NF
修改:
表1 符合3NF的商品类别表的设计

表2 符合3NF的商品表的设计

商品表goods通过商品类别id字段与商品类别表进行关联。
2NF和3NF通常以这句话概括“每个非键属性依赖于键,依赖于整个键,并且除了键别无他物”
小结
关于数据表的设计,有三个范式要遵循。
- 第一范式,确保每列保持原子性
数据库每一列都是不可分割的原子数据项,不可再分的最小数据单元,而不能是集合、数组、记录等非原子数据项 - 第二范式,确保每列和主键完全依赖 。尤其是在复合主键的情况下,非主键部分不应该依赖于部分主键。
- 第三范式,确保每列都和主键列直接相关,而不是间接相关。
**范式的优点:**数据的标准化有助于消除数据库中的数据冗余,3NF通常被认为在性能、扩展性和数据完整性方面达到了最好的平衡。
**范式的缺点:**范式的使用,可能降低查询效率。因为范式等级越高,设计出来的数据表越多,越精细,数据的冗余度就越低,进行数据查询的时候就可能需要关联多张表,这不但代价昂贵,也可能使一些索引策略无效。
范式知识提出了设计的标准,实际上设计数据表时未必一定要符合这些标准。开发中我们会出现为了性能和读取效率违反范式化的原则,通过增加少量的冗余或重复的数据来提高数据库的读性能,减少关联查询,join表的次,实现空间换取时间的目的。因此在实际的设计过程中要理论结合实际,灵活运用。
范式本身没有优劣之分,只有适用场景不同。没有完美的设计,只有合适的设计,我们在数据表的设计中,还需要根据需求将范式和反范式混合使用。