英文评论机器学习_第72集 python机器学习:停用词和tf-idf缩放数据用于电影评论...
停用词是一种删除没有信息量的单词的一种方法,该方法就是舍弃那些出现次数太多以至于没有信息量的次。主要有两种方法:使用特定语言的停用词(stopword)列表或舍弃那些出现过于频繁的单词
在scikit-learn的feature-extraction模块中提供了英语停用词的内置列表,代码示例如下:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
print("Number of stop word: {}".format(len(ENGLISH_STOP_WORDS)))
print("Every 10th stopword:{}".format(list(ENGLISH_STOP_WORDS)[::10]))
运行上述代码其结果为:
Number of stop word: 318
Every 10th stopword:
['mine', 'meanwhile', 'again', 'across', 'off', 'though', 'such', 'something', 'myself', 'if', 'noone', 'call', 'been', 'interest', 'whose', 'behind', 'fifteen', 'even', 'often', 'found', 'sometime', 'done', 'alone', 'they', 'forty', 'last', 'co', 'part', 'whenever', 'somewhere', 'anything', 'anyhow']
由上述运行结果可知,删除上述列表中的停用词只能使得特征数量少了318个(即上述列表的长度),下面我们来看一下是否对性能产生影响。代码如下:
#指定stop_words=“English”将使用内置列表
#也可以扩展这个列表并传入自己的列表
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
param_grid = {'C':[0.001,0.01,0.1,1,10,100]}
vect = CountVectorizer(min_df=10, stop_words="english").fit(text_train)
x_train = vect.transform(text_train)
print("x_train with stop words:{}".format(repr(x_train)))
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(x_train, y_train)
print("Best coss validation score is: {:.3f}".format(grid.best_score_))
运行后其对应的结果如下:
x_train with stop words:
<75000x31610 sparse matrix of type ''
with 6538340 stored elements in Compressed Sparse Row format>
Best coss validation score is: 0.713
使用停用词偶网格搜索性能有所下降,但是鉴于3万多个数据减少300多个数据不太可能对性能或解释造成很大影响,所以这个列表似乎是不值得的,固定的列表主要对小型数据很有帮助,这些数据集可能没有包含足够的信息,模型从数据本身无法判断哪些单词是停用词。
下面我们通过设置CountVectorizer的max_df选项来舍弃出现最频繁的单词,并查看其对特征数量和性能有什么影响。
用tf_idf缩放数据:另一种删除没有信息量的单词(也是最常用的方法)是词频-逆向文档频率(tf-idf)方法,该方法对在某个特定文档中经常出现的术语给予很高的权重,但对于在语料库的许多文档中经常出现的术语给予的权重却不高。
如果一个单词在某个特定文档中经常出现,但是在许多文档中却不常出现,那么这个单词很可能是对文档的很好描述。scikit-learn在两个类中实现了td-idf的方法——TfidfTransform和TfidfVectorizer。前者接受CountVectorizer生成的稀疏矩阵并将其变换,后者接受文本数据并完成词袋特征提取和tf-idf变换。
由于tf-idf实际上利用了训练数据的统计学属性,所以我们将使用管道以确保网格搜索结果有效,对应代码如下:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(TfidfVectorizer(min_df=5),LogisticRegression())
#对于高维稀疏数据,类似于LogisticRegression的线性模型通常效果最好
param_grid = {'logisticregression__C':[0.001, 0.01, 0.1, 1, 10],
'tfidfvectorizer__ngram_range':[(1,1),(1,2),(1,3)]}
#首先需要用一个字典指定要搜索的参数,字典的键是我们要调节的参数名称
grid = GridSearchCV(pipe, param_grid, cv=5)#cv=5,分层k折交叉验证中k取值为5
grid.fit(text_train, y_train)
#grid对象的行为就像一个分类器,我们可以对它调用标准的fit、predict、score方法
#调用fit时,对我们指定的所有参数组合都运行交叉验证
#拟合fit对象不仅会搜索最佳参数,还会利用得到的最佳验证性能的参数在整个训练数据集上自动拟合一个新模型
#可以用predict、score方法来访问重新训练过的模型
#我们找到的参数保存在best_params_中
#交叉验证的最佳精度保存在best_score_中
print("Best cross-validation score:{:.3f}".format(grid.best_score_))
运行上述代码后结果为:
Best cross-validation score:0.723
从运行结果可以看出,使用tf-idf替代仅统计词数对性能有所提高,同时要注意的是tf-idf可以查看找到的最重要的单词,其缩放目的是找到能够区分文档的单词,但是它完全是一种无监督技术。因此,这里的“重要”不一定是我们所需要的“正面评论”和“负面评论”标签相关,所以我们还需要进行如下操作:
首先,从管道中提取TfidfVectorizer:
vectorizer = grid.best_estimator_.named_steps["tfidfvectorizer"]
x_train=vectorizer.transform(text_train)
#变换训练数据集,并找到数据集中每个特征的最大值
max_value = x_train.max(axis=0).toarray().ravel()
sorted_by_tfidf = max_value.argsort()
#获取特征名称
feature_names = np.array(vectorizer.get_feature_names())
print('Features with lowest tfidf:{}'.format(feature_names[sorted_by_tfidf[:20]]))
print('Features with highest tfidf:{}'.format(feature_names[sorted_by_tfidf[-20:]]))
#下面是找出逆向文档频率较低的词——出现次数很多,但是被认为不那么重要的单词
#这些词被保存在idf_属性中
sorted_by_idf=np.argsort(vectorizer.idf_)
print('Feature with lowest idf:{}'.format(feature_names[sorted_by_idf[:100]]))
运行结果如下:

tf-idf 对应的各种特征
tf-idf较小的特征要么在很多文档里都很常用,要么就是很少使用,且仅出现在非常长的文档中。而tf-idf叫他的特征实际上对应的是特定的电影或演出中。而在lowest idf中表现出来的是对应的停用词。
接着我们来看一下这些评估分数对应的热图,对应代码如下:
scores=grid.cv_results_['mean_test_score'].reshape(-1,3).T
#获取对应热图
heatmap=mglearn.tools.heatmap(
scores,xlabel='C',ylabel='ngram_range',cmap='viridis',fmt='%.3f',
xticklabels=param_grid['logisticregression__C'],
yticklabels=param_grid['tfidfvectorizer__ngram_range']
)
plt.colorbar(heatmap)
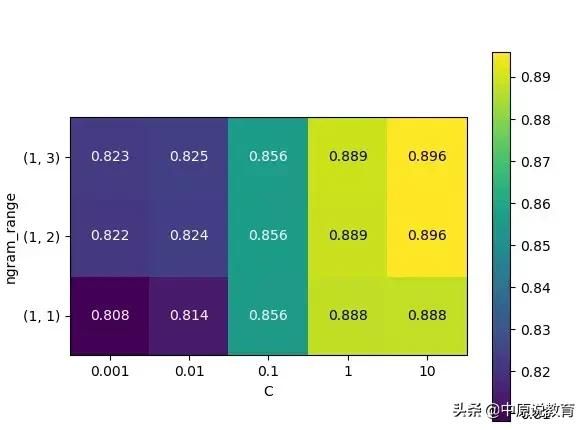
ngram_range和C参数控制下的预测分数热图