GAN逆映射(Inversion):综述
GAN Inversion: A Survey
公众号:EDPJ
目录
0. 摘要
1. 简介
2. 问题定义与总览
3. 基础知识
3.1 GAN 模型和数据集
3.1.1 GAN 模型
3.1.2 数据集
3.2 评估指标
3.2.1 逼真度
3.2.2 忠实度
3.2.3 可编辑性
3.2.4 主观指标(Subjective Metric)
4. GAN Inversion 方法
4.1 嵌入哪个空间——从 Z 空间到 P 空间
4.2 GAN Inversion 方法
4.2.1 基于学习的方法
4.2.2 基于优化的方法
4.2.3 基于混合的方法
4.3 GAN Inversion 方法的属性
4.3.1 支持的分辨率
4.3.2 语义感知(Semantic Awareness)
4.3.3 分层(Layerwise)
4.3.4 分布外泛化能力(Out-of-Distribution Generalizability)
4.4.1 探索可解释的方向
4.4.2 探索解耦的方向
5. 应用
5.1 图像处理
5.2 图象生成
5.3 图像恢复
5.4 图像插值
5.5 3D 重建
5.6 图象理解
5.7 多模态(Multimodal)学习
5.8 医学图像
6. 挑战和未来方向
7. 结论
参考
总结 & 一些想法
补充知识
1. 反卷积
2. 扩展 latent space W+
3. 仿射变换
4. 白化(Whitening)
0. 摘要
GAN 逆映射(inversion)把给定图像映射到预训练 GAN 模型的 latent space,以便生成器可以从 latent code 重建图像。 作为一种连接真假图像域的新兴技术,GAN Inversion 在使用预训练 GAN 模型(例如 StyleGAN 和 BigGAN)进行真实图像编辑方面,发挥着至关重要的作用。 此外,GAN Inversion 解释了 GAN 的 latent space 以及如何生成逼真的图像。 在本文中,我们综述了 GAN Inversion,重点介绍了其代表性算法及其在图像恢复和图像处理中的应用。 我们进一步讨论了未来研究的趋势和挑战。GAN Inversion 方法、数据集和其他相关信息参见论文内网站。
1. 简介
生成对抗网络 (Generative Adversarial Network,GAN) 是一种深度生成模型(deep generative model),它通过对抗训练学习生成新数据。 它由两个神经网络组成:生成器 G 和鉴别器 D,它们通过对抗过程联合训练。 G 的目标是合成类似于真实数据的假数据,而 D 的目标是区分真假数据。 通过对抗训练过程,生成器 G 试图生成与真实数据分布匹配的假数据来愚弄鉴别器。 近年来,GAN 已应用于计算机视觉任务,例如:图像翻译、图像处理到图像恢复。
目前的许多 GAN 模型,例如 PGGAN、BigGAN 和 StyleGAN,从随机得 latent code 合成具有高质量和多样性的图像。 最近的研究表明,GAN 通过图像生成的监督,有效地在中间特征和 latent space 中编码丰富的语义信息。 这些方法可以合成具有多种属性的图像,例如具有不同年龄和表情的人脸,以及具有不同光照条件的场景。 通过改变 latent code,我们可以在保留生成图像一些属性的同时操纵另一些属性。 然而,由于 GAN 缺乏推理能力,这种对 latent space 的操作仅适用于 GAN 生成器生成的图像,而不适用于任何给定的真实图像。

GAN Inversion 基于已训练的 GAN 的 latent space 编辑真实图像,且无需任何临时监督或昂贵的优化。 如上图所示,将真实图像映射到 latent space 后,我们可以沿着一个特定的方向改变它的 latent code 来编辑图像的相应属性。 作为结合 GAN 和可解释机器学习技术的快速发展方向,GAN Inversion 不仅是一个灵活的图像编辑框架,而且有助于揭示深度生成模型的内部工作原理。
在本文中,我们全面回顾了 GAN Inversion 并比较了它们的不同属性和性能。我们进一步讨论了未来研究的挑战、未解决的问题和趋势。
本文剩余部分结构如下:
- 我们首先在第 2 节中给出 GAN Inversion 的问题公式。给定图像 latent code 应具有两个属性:1) 忠实且逼真地重建输入图像,以及 2) 促进下游任务。 实现这两个属性也是 GAN Inversion 的目标。
- 3.1 节介绍了许多不同的预训练 GAN 模型 G(z)。 后续章节介绍了不同的GAN Inversion 方法。
- 为了评估 GAN Inversion 的性能,我们在 3.2 节中考虑了两个重要方面,即重建图像的逼真度(感知质量)和忠实度(反演精度)。第一个方面取决于问题是如何求解的。由于 G(z) 的非凸性,它通常是一个非凸优化问题,很难找到准确的解。第二个方面主要取决于使用哪个 latent space 。
- 4.1 节介绍、分析和比较了不同潜在空间的特征。
- 在 4.2、4.3 和 4.4 节中,我们介绍了现有方法如何尝试解决问题,并讨论了这些 GAN Inversion 的一些重要特征。
- 第 5 节和第 6 节介绍了 GAN Inversion 的应用和未来发展方向。
2. 问题定义与总览
首先定义 GAN Inversion 问题统一的数学公式。 无条件 GAN 的生成器学习映射 G: Z→X。当z1、z2∈Z 在latent space Z 中很近时,对应图像 x1、x2∈X 在视觉上是相似的。GAN Inversion将数据 x 映射回 latent representation z*,或者等效地找到一个图像 x(它可以完全由训练有素的生成器 G 合成并保持接近真实图像 x)。形式上,将要逆映射的图像表示为 x∈Rn,训练有素的生成器表示为 G : Rn0→Rn, latent vector z∈Rn0 ,我们研究如下 Inversion 问题:
![]()
其中 l(·) 是图像或特征空间中的距离度量,假设 G 是前馈神经网络。 通常, l(·) 可以基于l1、l2、感知或 LPIPS 度量。 在实践中也可以包括对 latent code 或面部识别的一些其他限制。 从得到的 z*,可以获得原始图像; 可通过改变 z* 来处理获得的图像。
促进下游任务的第二个目标主要取决于使用哪个 latent space(参见第 4.1 节)。 第一个目标取决于如何准确地求解等式(1),由于 G(z) 的非凸性,这通常是一个非凸优化问题。 因此,不容易找到准确的解决方案。 目前,已经开发了许多方法来求解等式 (1):基于学习、优化或两者。
- 基于学习的方法旨在学习编码器网络将图像映射到 latent space,使得基于 latent code 的重建图像看起来尽可能类似于原始图像。
- 基于优化的方法通过反向传播直接求解目标函数,以找到最小化像素重建损失的 latent code。
- 混合方法首先使用编码器生成初始 latent code,然后使用优化算法对其进行优化。
- 通常,基于学习的方法不能忠实地重建图像内容。例如,基于学习的方法在重建人脸图像时,有时无法保留身份以及一些细节。 虽然基于优化的技术已经实现了卓越的图像重建质量,但它们不可避免的缺点是计算成本显着增加。
- 基于学习的方法的改进主要集中在如何忠实地重建图像,例如,在训练过程中加入额外的面部身份损失或迭代反馈机制。基于优化的方法的最新改进强调如何更快地找到所需的 latent code,因此提出了几种初始化策略和优化器。
- 现有的方法无法同时实现重建质量和推理时间,从而导致“质量-时间权衡”。 尽管另外提出了一些混合方法来平衡这种权衡,但快速找到准确的 latent code 仍然是一个挑战。
与 GAN inversion 类似,一些任务也旨在学习 GAN 模型的逆映射。
- 一些方法使用额外的编码器网络来学习 GAN 的逆映射,但它们的目标是联合训练编码器与生成器、鉴别器,而不是使用一个训练好的 GAN 模型。
- 其他一些方法,例如 PULSE、ILO或 PICGM,也依赖预训练生成器来解决修复、超分辨率或去噪等问题。 他们设计不同的优化机制来搜索满足给定退化观察(degraded observations,例如,噪声图像)的 latent code。 由于他们的目标是从退化的观察中搜索准确可靠的估计,而不是对给定图像的忠实重建,因此在本文不将它们归类为 GAN inversion。但关注这些工作将是有益的,因为它们有着相同的想法,即在预训练的 GAN 模型的 latent space 中找到所需的 latent code。
3. 基础知识
3.1 GAN 模型和数据集
诸如 GAN 之类的深度生成模型已被用于对自然图像分布进行建模并合成逼真的图像。GAN 的最新进展,例如 DCGAN、WGAN、PGGAN、BigGAN、StyleGAN、StyleGAN2、StyleGAN2-Ada 和 StyleGAN3 开发了更好的架构、损失和训练策略。
这些模型在不同数据集上训练,包括人脸(CelebA-HQ、FFHQ、AnimeFaces、AnimalFace)、场景(LSUN)和对象(LSUN 和 ImageNet)。具体来说,在 ImageNet 上预训练的 BigGAN、在 CelebA-HQ 上预训练的 PGGAN 以及在 FFHQ 或 LSUN 上基于样式的 GAN 被广泛用于 GAN inversion。
与上述 2D GAN 相比,最近开发的 3D 感知 GAN 弥合了 2D 图像和 3D 物理世界之间的差距。 基于这些 3D 感知 GAN 的逆映射方法目前研究较少,但在图像、视频和 3D 应用方面具有巨大潜力。
3.1.1 GAN 模型
DCGAN 在鉴别器中使用卷积,在生成器中使用反卷积(fractional-strided convolution)。
WGAN 最小化了生成数据分布和真实数据分布之间的 Wasserstein 距离,这提供了更高的模型稳定性并使训练过程更容易。
BigGAN 生成高分辨率和高质量的图像,并针对放大、架构变化和正交正则化进行修改,以提高大规模 GAN 的可扩展性、鲁棒性和稳定性。 BigGAN 可以在 ImageNet 上以 256*256 和 512*512 像素进行训练。
PGGAN,也称为 ProGAN 或渐进式 GAN,在训练过程中使用增长策略。关键思想是从生成器和鉴别器的低分辨率开始,然后添加新层,随着训练的进行对越来越细粒度的细节进行建模。 这种方法提高了训练速度和稳定性,从而促进更高分辨率的图像合成,例如 1024*1024 像素的 CelebA 图像。

Style-based GAN,例如 StyleGAN,隐式地学习用于图像生成的分层 latent style。该模型操纵每个通道的均值和方差来有效地控制图像的风格。
如图 2(a) 所示,StyleGAN 生成器将样式向量(由映射网络 f 定义)和随机变量(由噪声层提供)作为图像合成的输入。这提供了对不同细节级别的生成图像样式的控制。
StyleGAN2 模型通过权重解调、路径长度正则化、生成器重新设计和去除渐进式增长来进一步提高感知质量。
StyleGAN2-Ada 提出了一种自适应鉴别器增强机制来稳定有限数据的训练。
StyleGAN3 观察到 GAN 中的“纹理粘连”问题(混叠),并通过考虑连续域中的混叠效应以及对结果进行适当的低通滤波,提出了一种更适合视频和动画的新架构。
对于 StyleGAN 和 StyleGAN2,它们的层数 L 由输出图像大小 R 决定:L=2log2 R - 2;对于最大分辨率 1024*1024 的层数为18层。对于 StyleGAN3,层数是一个自由参数,与输出分辨率没有直接关系。
3.1.2 数据集
ImageNet 是一个用于视觉对象识别研究的大规模手动标注数据集,包含超过 1400 万张图像和 20,000 多个类别。
CelebA 是一个大规模的人脸属性数据集,由 20 万张名人图像组成,每张图像有 40 个属性注释。 CelebA 及其后续的 CelebA-HQ 和 CelebAMask-HQ 被广泛用于人脸图像生成和处理。
Flickr-Faces-HQ (FFHQ) 是从 Flickr 上爬取的高质量人脸图像数据集,由 70,000 张 1024*1024 像素的高质量人脸图像组成,在年龄、种族等方面存在较大差异 , 和图像背景。
LSUN 包含 10 个场景类别(例如,卧室、教堂或塔)和 20 个对象类别(例如,鸟、猫或公共汽车)中的每一个的大约一百万个标记图像。教堂和卧室场景图像以及汽车和鸟类物体图像通常用于 GAN inversion。
其它一些 GAN inversion 研究也在其实验中使用其他数据集,例如 DeepFashion、Anime-Faces 和 StreetScapes。
3.2 评估指标
有不同的方法来评估 GAN inversion,例如逼真度、重建图像的忠实度和逆映射的 latent code 的可编辑性。
3.2.1 逼真度
IS、FID 和 LPIPS 被广泛用于评估 GAN 生成图像的逼真质量。 其他指标,如 Frechet 分割距离 (FSD) 和切片 Wasserstein 差异 (SWD) 也已用于图像感知质量评估。
Inception score (IS) 是一种广泛使用的度量标准,用于衡量从 GAN 模型生成的图像的质量和多样性。它使用在 ImageNet 上预训练的 Inception-v3 网络计算合成图像的统计数据。分数越高越好。
Frechet inception distance (FID) 由基于 Inception-v3 pool3 层的真实图像和生成图像的特征向量之间的 Frechet 距离定义。较低的 FID 表示更好的感知质量。
Learned perceptual image patch similarity (LPIPS) 使用在 ImageNet 上预训练的 VGG 模型测量图像感知质量。较低的值意味着图像块之间的相似度较高。
3.2.2 忠实度
忠实度衡量真实图像与生成图像之间的相似性。最广泛使用的指标是 PSNR 和 SSIM。 一些方法使用逐像素重建距离,例如平均绝对误差 (MAE)、均方误差 (MSE) 或均方根误差 (RMSE)。
Peak signal-to-noise ratio (PSNR) 是最广泛使用的衡量重建质量的标准之一。真实图像和重建图像之间的 PSNR 由图像的最大可能像素值和图像之间的均方误差定义。
Structural similarity (SSIM) 基于亮度、对比度和结构方面的独立比较,来衡量图像之间的结构相似性。
3.2.3 可编辑性
可编辑性衡量对应于生成图像某些属性的 latent code 的可编辑灵活性。直接评估 latent code 的可编辑性很困难。
现有方法使用余弦相似度、欧氏距离或分类精度来评估输入 x 和输出 x' 之间的某些属性(即修改目标属性,同时保持其他属性不变)。这些方法侧重于评价人脸数据和人脸属性的可编辑性。
- Nitzan 等人使用余弦相似度来比较面部表情保存的准确性,这是通过 x 和 x' 的 2D 地标(landmarks)之间的欧氏距离计算的。
- 相比之下,姿势保持计算 x 和 x' 的欧拉角之间的欧氏距离。
- Abdal 等人开发编辑一致性分数(由属性分类器回归)来衡量编辑后的面部图像之间的一致性。该方法基于一个假设:在使用属性分器分类时,不同的编辑排列应具有相同的属性分数。
这些方法测量面部人物身份的保留程度以评估编辑图像的质量。 我们注意到上述方法可能不适用于面部以外的所有图像域。
3.2.4 主观指标(Subjective Metric)
除了上述指标外,一些研究还包括人类评分者或用户研究。
- 对于主观图像质量评估,人类评分者被要求为图像分配感知质量分数,例如从 1(差)到 5(好)。 最终得分,通常称为平均意见得分 (MOS) 或差异平均意见得分 (DMOS),计算所有评分的算术平均值。
- 典型的用户研究要求参与者从给定的三幅图像(源图、基线结果、建议方法结果)中选择最符合问题的图像。 问题可以是“从给定的两张编辑图像中选择一张能更好地保留源图像中人的身份”或“哪个编辑图像更逼真?” 最终的响应百分比表示所提出的方法相对于基线的偏好率。
这些指标的缺点包括人类判断的非线性尺度、潜在的偏差和方差以及高昂的人力成本。
4. GAN Inversion 方法
本节介绍 GAN 模型的不同 latent space、代表性的 GAN inversion 方法及其性质。 随着 StyleGAN 模型实现了最先进的图像合成,基于 StyleGAN 的各种 latent space 开发了许多 GAN inversion 方法。 除了用于通用 GAN 的 Z 空间外,还有几个 latent space 是专门为 StyleGAN 设计的,包括 W、W+、S 和 P 空间。
4.1 嵌入哪个空间——从 Z 空间到 P 空间
无论 GAN inversion 方法如何,一个重要的设计选择是将图像嵌入到哪个 latent space。 一个好的 latent space 应该是(各种语义属性相互)分离的并且易于嵌入。这种 latent space 中的 latent code 具有以下两个属性:它忠实地、逼真地重建输入图像,并有助于下游图像编辑任务。
本节介绍从原始 Z 空间到最新的 P 空间对 latent space 进行分析和正则化的工作。Z 空间适用于所有 GAN,一些 latent space 是专门为 StyleGAN 设计的。Latent space 的选择取决于预训练模型和任务。例如,使用 StyleGAN 进行图像编辑主要在 W+ 空间中进行。
Z 空间。 GAN 架构中的生成模型学习将从简单分布(例如正态分布或均匀分布)采样的值映射到生成的图像。这些值直接从分布中采样,通常称为 latent code 或 latent representation(由 z∈Z 表示),如图 2 所示。它们形成的结构通常称为 latent Z 空间。Z 空间适用于所有无条件 GAN 模型,如 DCGAN、PGGAN、BigGAN 和 StyleGANs。 然而,服从正态分布的 Z 空间的约束限制了其表示能力和语义属性的分离。
W 和 W+ 空间。 最近的 GAN Inversion 方法大多采用 StyleGAN 中使用的 latent space。 这些 latent space 具有更高的自由度,因此比 Z 空间更具表现力。
如图 2 所示,各种 latent space 都是从原始 Z 空间派生出来的。 StyleGAN 通过使用由 8 层多层感知器 (multilayer perceptron,MLP) 实现的非线性映射网络 f 将原始 z 转换为映射样式向量 w。这个中间的 latent space 被命名为 W 空间。由于映射网络和仿射变换,StyleGAN 的 W 空间包含比 Z 空间更多的分离性。
然而,W 空间的表现力仍然有限,限制了可以忠实重建的图像范围。因此,一些作品使用另一个逐层 latent space W+,其中不同的中间 latent code w 通过 AdaIN 送到生成器的每个层。 然而,将图像逆映射到 W+ 空间,以牺牲可编辑性为代价,从而减轻重建失真。最近的方法旨在通过预测 W+ 中靠近 W 的 latent code 来平衡重建与可编辑性。对于具有 18 层的 StyleGAN,w∈W 有 512 个维度,w∈W+ 有 18*512 个维度。
S 空间。 风格空间 S 由通道风格参数 s 扩展获得,其中 s 是通过对生成器的每一层使用不同的仿射变换,从 w∈W 转换而来。在具有 18 层的 1024*1024 StyleGAN2 中,W、W+ 和 S 的维度分别为 512、9216(18*512), 和 9088。
提出 S 空间是为了在语义层面之外的空间维度上实现更好的空间分离。空间纠缠主要是由基于样式的生成器的内在复杂性和 AdaIN 规范化的空间不变性引起的。
Xu 等人用编码器学习的分离的多级视觉特征替换原始样式编码,他们将这些由样式参数扩展的空间称为 Y 空间,但实际上可以看作是 S 空间。
通过直接干预风格代码 s∈S,基于 S 空间的方法实现了对局部变换的细粒度控制。
P 空间。 最近 PULSE 在搜索生成模型的 latent space 以找到所需点时观察到“肥皂泡”效应。 顾名思义,“肥皂泡”效应是指,高维高斯分布的大部分密度靠近超球体的表面。上述作者建议将图像嵌入到 Z 空间中的超球体表面。 基于观察,Zhu 等人提出了一个 P 空间。
由于最近的 leaky ReLU 使用 0.2 的斜率,从 W 空间到 P 空间的转换 x = LeakyReLU_5.0 (w),其中 w 和 x 分别是 W 和 P 空间中的 latent code。
他们做出最简单的假设,即 latent code 的联合分布近似于多元高斯分布,并进一步提出 P_N 空间来消除依赖性和去除冗余。通过 PCA 白化(whitening)得到 P 空间到 P_N 空间的变换:![]() ,其中,
,其中,![]() 分别为缩放矩阵、正交矩阵、均值向量,它们都是从 PCA(X) 中获得的,其中,
分别为缩放矩阵、正交矩阵、均值向量,它们都是从 PCA(X) 中获得的,其中,![]() 由 P 空间中的 100 万个 latent samples 组成。 这种变换将分布归一化为零均值和单位方差,导致 P 空间在所有方向上各向同性。
由 P 空间中的 100 万个 latent samples 组成。 这种变换将分布归一化为零均值和单位方差,导致 P 空间在所有方向上各向同性。
![]() 空间是从 P_N 空间扩展而来的:
空间是从 P_N 空间扩展而来的:![]() 。 每个 latent code 都用于解调(demodulate)不同层的相应 StyleGAN 特征图。
。 每个 latent code 都用于解调(demodulate)不同层的相应 StyleGAN 特征图。
4.2 GAN Inversion 方法

上图显示了 GAN inversion 的三种主要技术,即将图像投影到基于学习、优化或两者混合的 latent space 中。 Latent code 具有其他属性,即支持解析、语义感知、分层和分布外的泛化。

上表列出了现有 GAN inversion 方法的一些重要属性。
4.2.1 基于学习的方法
基于学习的 GAN inversion 训练编码神经网络 E,通过以下方式将图像 x 映射为 latent code z
![]()
其中 xn 表示数据集中的第 n 个图像。等式 (2) 具有编码器 E 和解码器 G,让人回想起自编码器流水线(autoencoder pipeline)。解码器 G 在整个训练过程中是固定的。 除了准确的重建之外,一个好的 GAN inversion 编码器应该具有以下特点:1)轻量级; 2)数据有效性; 3) 支持高分辨率图像(见第 4.3.1 节); 4) 对任意图像的泛化性(参见第 4.3.4 节)。
Perarnau 等人提出了一种较早的基于学习的 GAN inversion 方法。
- 给定 conditional GAN (cGAN) 模型,真实图像 x 由 latent code z 和属性向量 y 编码,通过改变 y 合成修改后的图像 x'。
- 这种方法用训练好的 cGAN 训练编码器 E。
- 与Zhu 等人的工作不同,该编码器 E 由两个模块组成:Ez,将图像编码为 z;Ey,将图像编码为 y。
- 为了训练 Ez,该方法使用生成器创建生成图像 x' 和latent vector z 的数据集,最小化 z 和 Ez(G(z; y)) 之间的平方重建损失 L_ez,并通过直接使用
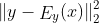 训练来改进 Ey。
训练来改进 Ey。 - Ey 最初使用生成的图像 x' 及其条件信息 y 进行训练。
由于 StyleGAN 的流行,最近基于学习的方法为 StyleGAN 设计了编码器。
- Richardson 等人提出 MAP2STYLE 模块从相应的特征图中学习样式,其中分别预测了 18 个单层 latent code。
- Wei 等人没有使用 18 个模块学习 StyleGAN 的样式,而是提出了一个简单高效的头部(head),它只由一个平均池化层和一个全连接层组成。基于特征金字塔网络(feature pyramid network,FPN)可获得三个不同语义级别的特征,这三个头产生的 w15,...,w18、w10,...,w14、w1,...,w9 分别来自浅层、中层和深层特征。
- Tov 等人分析了 StyleGAN latent space 中失真、感知质量和可编辑性之间的权衡。编码器用于控制权衡并促进下游图像编辑。
- 为了提高 inversion 精度,Alaluf 等人为编码器引入了一种迭代优化机制。在步骤 t 中,编码器不是在前向传播中直接预测给定真实图像的 latent code,而是对将给定图像 x 与预测图像连接而获得的扩展输入进行操作:
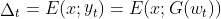 ,然后将步骤 t+1 处的 latent code 更新为
,然后将步骤 t+1 处的 latent code 更新为 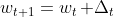 。 w0 和 y0 的初始化值分别设置为平均 latent code 及其对应的图像。
。 w0 和 y0 的初始化值分别设置为平均 latent code 及其对应的图像。
尽管一些方法通过添加编码器来学习 GAN 的逆映射,但我们不将它们归类为 GAN inversion。因为它们的目标是联合训练编码器与生成器、鉴别器,而不是确定训练好的 GAN 模型的 latent space。
4.2.2 基于优化的方法
现有的基于优化的方法通常通过优化 latent vector 来重建目标图像。
![]()
选择优化器至关重要,因为好的优化器有助于缓解局部最小值问题。
- 有两种类型的优化器:基于梯度的(ADAM、LBFGS、Hamiltonian Monte Carlo (Hamiltonian Monte Carlo,HMC))和无梯度(协方差矩阵自适应 (covariance matrix adaptation,CMA))方法。
- 基于优化的方法使用不同的优化器。例如,ADAM 用于 Image2StyleGAN,L-BFGS 被 Zhu 等人使用。
- Huh 等人系统地试验了基于梯度和无梯度优化器,发现 CMA 及其变体 BasinCMA,可以更好地将具有挑战性的数据集(例如 LSUN Cars)逆映射到 StyleGAN2 的 latent space。
基于优化的方法的另一个重要问题是 latent code 的初始化。
- 由于等式(1)是高度非凸的,重建质量在很大程度上依赖于 z 的良好初始化(对于 StyleGAN 有时是 w)。实验表明,不同的初始值会导致生成图像的显著感知差异。
- 一个直观的解决方案是从几个随机初始值开始,以最小的成本获得最好的结果。
- Image2StyleGAN 研究了两种初始化选择,一种基于随机选择,另一种基于 latent code 的平均值。
- 然而,在获得稳定的重建之前,可能需要测试大量的随机初始值,这使得实时处理变得不可能。
- 因此,一些人改为训练深度神经网络以直接最小化,如第 4.2.1 节所述(基于学习的方法)。 一些人建议使用编码器为优化提供更好的初始化,这将在第 4.2.3 节中讨论(基于混合的方法)。
我们注意到,基于优化的方法通常需要在内存和运行时间方面进行昂贵的迭代,因为它们必须独立应用于每个 latent code。
4.2.3 基于混合的方法
混合方法利用了上述两种方法的优点。作为该领域的开创性工作之一,Zhu 等人提出了一个框架,首先通过训练一个单独的编码器 E 来预测给定真实照片 x 的 z,然后使用获得的 z 作为优化的初始值。学习的预测模型,用作非凸优化问题 (1) 的快速自下而上的初始化。
随后的研究遵循上述框架,并提出了几个变体。
- 为了反转 G,Bau 等人首先训练网络 E 以获得 latent code z0 = E(x) 及其中间表示 r0 = gn( ...(g1(z0))) 的合适初始化,其中 gn(...( g1(·))) 是 G(·) 的分层表示。 然后,此方法使用 r0 初始化对 r* 的搜索,以获得接近目标 x 的重建 x0 = G(r*)。有关更多详细信息,请参见第 4.3.3 节。
- Zhu 等人表明,在大多数现有方法中,生成器 G 不提供其领域知识来指导编码器 E 的训练,因为根本没有考虑 G(·) 的梯度。为了解决这个问题,开发了一种特定领域的 GAN inversion 方法,它既可以重建输入图像,又可以确保 latent code 对语义编辑有意义。有关此方法的更多详细信息,请参见第 4.3.2 节。
- 与以前的方法相比,Roich 等人开发了一种生成器调谐技术。他们使用初始 latent code 作为基准,缓慢调整预训练生成器,以便可以忠实地重建输入图像。这个过程被称为基准调整,它有助于将域外图像忠实地映射到域内 latent code。
- Alaluf 等进一步引入了一个超网络(supernetwork),它学习基于给定的输入图像改进生成器权重。超网络由轻量级特征提取器和一组精调块组成。
4.3 GAN Inversion 方法的属性
在本节中,我们将讨论 GAN inversion 方法的重要属性,即支持的分辨率、语义感知、分层和分布外泛化能力。
4.3.1 支持的分辨率
GAN inversion 可以支持的图像分辨率主要取决于生成器和 inversion 机制的能力。
- Zhu 等人使用在 64*64 像素图像的几个数据集上训练的 GCGAN
- Bau 等人采用 PGGANs,使用来自 Lsun 的大小为 256*256 像素的图像进行训练。
然而,有些方法不能充分利用预训练的 GAN 模型。
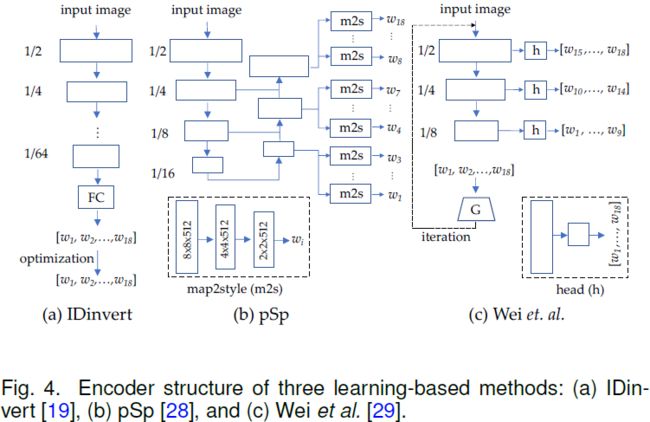
Zhu 等人提出了一个编码器,将给定的图像映射到 StyleGAN 的 latent code。这种方法(图 4(a))对于 256*256 像素的图像表现良好,但由于计算成本高,不能很好地扩展到 1024*1024 像素的图像(图中的1/n表示1/n原始输入分辨率的语义特征图)。
与此相反,Richardson 等人提出的 pSp 方法(如图 4(b))可以合成 1024*1024 像素的图像。无论输入图像大小如何,因为他们提出的 18 个 map2style 模块分别用于预测 18 个单层 latent code。
Wei 等人提出了一个类似的模型,但带有轻量级编码器。来自三个语义级别的特征用于预测 latent code 的不同部分。 尽管如此,该模型从每个语义级别预测了 9、5 和 4 层的 latent code,如图 4 (c) 所示。
最近的应用,例如 megapixels 上的换脸和无限分辨率图像合成被开发为可以支持高分辨率图像编辑的图像逆映射方法。
4.3.2 语义感知(Semantic Awareness)
具有语义感知特性的 GAN inversion 方法可以在像素级别执行图像重建,并将 latent code 与 latent space 中出现的知识对齐。语义感知 latent code 通过重复使用 GAN 模型中编码的丰富知识来更好地支持图像编辑。 现有方法通常随机采样一组 z 并将latent code它们输入 G 以获得相应的合成 x'。 编码器 E 基于下式训练
![]()
Collins 等人使用 latent object representation 来合成具有不同风格的图像并减少非预期错误。 然而,仅通过重建 z(或等效地,合成数据)的监督不足以训练准确的编码器。
为了缓解这个问题,Zhu 提出了一种特定领域的 GAN inversion 方法来恢复像素和语义级别的输入真实图像。该方法首先训练域引导的(domain-guided)编码器 E 将图像空间映射到 latent space ,这样编码器生成的所有代码都是域内 latent code。 编码器 E 被训练来恢复真实图像,而不是用合成数据训练来恢复 latent code。 然后,他们通过将这个训练有素的 E 作为正则化项来执行实例级域正则化优化,从而在优化 z 时微调语义域中的 latent code。 这种优化有助于更好地重建像素值而不影响 latent code 的语义属性。 训练过程表述为
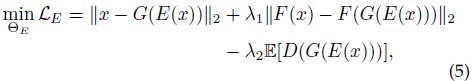
其中,F 是 VGG 特征提取器,E[D(·)] 是鉴别器损失。
由域引导编码器生成的逆映射编码,可以基于预训练生成器很好地重建输入图像,并确保编码本身在语义上是有意义的。 然而,编码仍然需要改进以更好地适用于像素值上单个目标图像。基于域引导编码器,他们设计了一个包含两个模块的域正则化优化:(i)把域引导编码器的输出用作起点,以避免局部最小值并缩短优化过程,以及(ii)用域引导编码器规范化生成器语义域内的 latent code。 目标函数是

4.3.3 分层(Layerwise)
当层数很大时,确定由等式(1)定义的完整 inversion 问题的生成器是不可行的。 最近的一些方法通过将生成器 G 分层来解决易于处理的子问题。
![]()
最简单的分层 GAN inversion 基于一层。 Lei 等人考虑 G = g(z) = ReLU(Wz + b) 形式的单层模型。 当问题可实现时,要找到一个可行的 z 使得 x = G(z),可以通过求解如下线性规划问题来逆函数:

(8) 的解集是凸的,形成一个多面体(polytope)。 然而,它可能包含无数的的可行点,这使得如何进行分层 inversion 变得不清楚。
一些方法做出额外的假设以将上述结果推广到更深的神经网络。 Lei 等人假设输入信号以 ![]() 的方式被有界噪声破坏,并提出了一种逐层使用线性规划的生成模型的 inversion 方案。 可靠稳定 inversion 的分析仅限于以下情况:(1)网络的权重应该是高斯独立同分布变量; (2) 每一层都应该用一个常数因子扩大; (3) 最后一个激活函数应该是 ReLU [109] 或 leaky ReLU。 然而,这些假设在实践中往往不成立。
的方式被有界噪声破坏,并提出了一种逐层使用线性规划的生成模型的 inversion 方案。 可靠稳定 inversion 的分析仅限于以下情况:(1)网络的权重应该是高斯独立同分布变量; (2) 每一层都应该用一个常数因子扩大; (3) 最后一个激活函数应该是 ReLU [109] 或 leaky ReLU。 然而,这些假设在实践中往往不成立。
为了逆转复杂的最先进的 GAN,Bau 等人建议解决更简单的逆转最终层 Gf 的问题:
![]()
其中,r* = arg min L(Gf (r); x),r 是中间 representation,L 是图像特征空间中的距离度量。
他们在两步混合 GAN inversion 框架中解决 inversion 问题 (1):
- 构建一个神经网络 E,它近似逆转整个 G 并计算估计值 z0 = E(x)
- 解决优化问题,确认
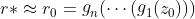 ,生成重建图像 Gf (r*),从而接近恢复 x。
,生成重建图像 Gf (r*),从而接近恢复 x。
对于每一层 ![]() ,首先训练一个小型网络 ei 来反转 gi。也就是说,当定义
,首先训练一个小型网络 ei 来反转 gi。也就是说,当定义 ![]() 时,目标是学习一个网络 ei,它近似计算
时,目标是学习一个网络 ei,它近似计算 ![]() , 并确保网络 ei 的预测能够很好地保持 gi 层的输出 ,即
, 并确保网络 ei 的预测能够很好地保持 gi 层的输出 ,即 ![]() 。 因此,ei 被训练以最小化左反转和右反转损失:
。 因此,ei 被训练以最小化左反转和右反转损失:

其中,![]() 被设置为 0.01,从而强调对
被设置为 0.01,从而强调对 ![]() 的重建。
的重建。
为了专注于生成器生成的 representations 的流形附近的训练,该方法使用样本 z 和层 gi 来计算 ![]() 和 ri 的样本,使得
和 ri 的样本,使得 ![]() 。 一旦所有层都被反转,所有 G 的反转网络可以组成如下:
。 一旦所有层都被反转,所有 G 的反转网络可以组成如下:
![]()
通过微调组合网络 E*,将 G 作为一个整体联合反转并获得最终结果 E,可以进一步改进结果。
对于 StyleGANs,中间 latent code w∈W+ 或 s∈S 在不同层是不同的,它们通过 AdaIN或仿射变换送到生成器的相应层。 因此,将图像逆映射到 W+ 或 S 空间中可以看作是分层的。
4.3.4 分布外泛化能力(Out-of-Distribution Generalizability)
GAN inversion 方法可以支持逆映射图像,尤其是任何给定的真实图像,这些图像未在训练数据中给出。我们将这种能力称为分布外泛化能力。
- 具体来说,给定一个在 FFHQ 数据集上预训练的 StyleGAN,该属性与以下两个方面密切相关:1)生成具有所有面部属性组合的面部图像,即使训练数据集中不存在某些组合; 2) 处理与训练集样本不同的图像,例如损坏的图像、漫画或黑白照片。
- 此属性是 GAN inversion 方法编辑更广泛图像的先决条件。许多 GAN inversion 方法已经证明了分布外的普遍性。
- Zhu 等人提出了一种特定领域的 GAN inversion 来恢复像素和语义级别的输入图像。尽管仅使用 FFHQ 数据集进行训练,但他们的模型不仅可以推广到来自多个面部数据集的真实面部图像,还可以推广到从互联网上收集的绘画、漫画和黑白照片。
- Kang 等人提出了一种逆映射分布外图像的方法。以面部图像为例,分布外图像可能是具有极端姿势的图像或损坏的图像,以前的方法通常无法处理这些图像。
- 逆映射分布外图像使得 GAN inversion 可被应用于更广泛的领域。一些方法探索了仅在给定降级或部分观察的情况下将图像逆映射为所需 latent code 的潜力。
- 除了图像,最近的方法还显示了其他模式的分布外泛化能力,例如,草图和文本。
当与基于 latent code 的编辑方法(参见第 4.4 节)相结合时,GAN inversion 的分布外泛化性有助于开放世界图像操作。
- 一个显著的缺点是,逆映射包含不可见属性的图像时,很容易产生意想不到的结果,因为它们位于预训练图像生成器所在域之外。
- 这限制了将 GAN inversion 扩展到更广泛的应用,例如由不常见的文本描述引导的图像合成 。
- 最近的一些方法旨在通过将在一个图像域上预训练的 GAN 转移到一个新图像域来缓解这个问题:由来自一个或几个目标图像的某些参考或语义引导(few-shot 和 one-shot)、预训练语言- 图像模型(zero-shot),或两者相结合。
4.4 隐空间导航(Latent Space Navigation)
GAN inversion 不是最终目标。我们将真实图像逆映射到经过训练的 GAN 模型的 latent space 中是因为,它允许我们通过改变 latent space 中特定属性的 latent code 来操纵图像。这种技术通常被称为隐空间导航或遍历(latent space navigation or traversals)、GAN 可操纵性或 latent code操作。虽然经常被视为一个独立的研究领域,但它是 GAN inversion 不可或缺的应用 [94]。许多方法也探索了如何有效地发现所需的 latent code。4.1 节已经介绍了不同的 latent space。本节介绍在 GAN 的 latent space 中发现可解释和分离的方向。
4.4.1 探索可解释的方向
一些方法支持在 latent space 中发现可解释的方向,即通过在所需方向 n 上,以步长 α 改变 latent code z 来控制生成过程,这是矢量运算 z' = z + αn。可以通过有监督、无监督或自我监督的方式来识别此类方向。此外,最近的方法以封闭的形式,直接基于预训练模型计算可解释方向,而无需任何类型的训练或优化。
基于监督学习的方法。现有的基于监督学习的方法通常随机抽取大量 latent code,合成相应图像的集合,并通过引入预训练分类器(例如,预测面部属性或光照方向)或提取统计图像信息(例如,颜色变化)。
- 为了解释 GAN 学到的的人脸 representation,Shen 等人使用一些现有的分类器来学习 latent space 中的超平面,以此作为分离边界,并预测合成图像的语义分数。
- Abdal 等人通过使用连续归一化流 (continuous normalizing flows,CNF) 学习 Z 空间和 W 空间之间的语义映射。
这两种方法都依赖于属性的可用性(通常通过面部分类器网络获得),这些属性对于新数据集可能难以获得,且可能需要手动标记。
基于无监督学习的方法。监督设置会在实验中引入偏差,因为用作监督的采样编码和合成图像在每次采样中都是不同的,可能发现不同的可解释方向。它还严重限制了现有方法可以发现的方向范围,尤其是在缺少标签的情况下。此外,这些方法发现的单个操控(individual controls)通常是纠缠在一起的,影响多个属性,并且通常是非局部的。
因此,一些方法旨在以无监督的方式发现 latent space 中的可解释方向,即不需要配对数据。
例如,H¨ark¨onen 等人通过识别基于 latent space 或 feature sapce 中应用的 PCA 的重要 latent directions,为图像合成建立可解释的操控。得到的主成分对应一定的属性,主成分的选择性应用可以控制图像的很多属性。这种方法被认为是“无监督”的,因为 PCA 可以在不使用任何标签的情况下发现方向。不需要人工干预和监督来将这些方向注释到目标操作以及它们应该应用于哪些层。
而 Jahanian 等人以自我监督的方式优化迹(trajectories)(线性和非线性)。以线性行走(linear walk) w 为例,给定一个逆映射的源图像 G(z),他们通过下式学习 w。
![]()
其中 L 测量在 latent directions 上采取 α-step 后生成的图像 G(z + αw) 与目标图像 edit(G(z), α) 之间的距离。 这种方法被认为是“自我监督”的,因为目标图像 (G(z), α) 可以从源图像 G(z) 导出。
封闭形式的方法。 最近的一些方法表明,图像合成的可解释方向可以直接以封闭形式获得,无需训练或优化。
Chen 等人提出了一种基于预训练 GAN 第一层权重奇异值分解的语义分解方法。 他们观察到图像的语义变换,通常表示为将 latent code 向某个方向 n' = z + αn 移动,实际上是由 latent direction n 决定的,而 n 与采样编码 z 无关。 一种语义分解 (Semantics Factorization,SeFa) 方法被开发,来发现可能导致输出图像显著变化 △y 的方向 n:
![]()
其中 A 和 b 分别是 G 中某些层的权重和偏差。得到的公式 △y = αAn 表明可以通过在投影编码上添加项 αAn 来实现方向 n 的所需编辑,还表明权重参数 A 应包含图像变化的基本信息。 因此,可以通过解决以下优化问题来分解探索 latent semantics 的问题:
![]()
所需的方向 n*,即 GAN 中 latent semantics 封闭形式的分解,是矩阵 ![]() 的特征向量。
的特征向量。
与 SeFa 相比,一种基于正交雅可比正则化(orthogonal Jacobian regularization)的方法,应用于生成器的多个层,以确定图像合成的可解释方向。
4.4.2 探索解耦的方向
当涉及多个属性时,编辑一个属性可能会影响另一个属性,因为某些语义没有分开。一些方法旨在无干扰地解决多属性图像操作。这一特征在文献中也被称为多维或条件编辑。目标是发现所需属性的分离方向。
Shen 等人将基于逆映射的图像处理公式化为 x' = G(z* + n),其中 n 是单位法向量,是由两个 latent code 定义的超平面(一个超平面分离两个属性)。其中,k 个属性 {z1,...,zk} 可以形成 m (m≤k*(k-1)/2) 个超平面 {n1,...,nm} 。要编辑多个属性而不相互干扰,这些解耦的方向 {n1,...,nm} 应该是正交的。如果这个条件不成立,那么一些语义就会相互关联,![]() 可以用来衡量第 i 个和第 j 个语义之间的相关度。特别是,该方法使用投影来正交化不同的向量。
可以用来衡量第 i 个和第 j 个语义之间的相关度。特别是,该方法使用投影来正交化不同的向量。

如图 5 所示,给定两个法向量为 n1 和 n2 的超平面,目标是找到一个投影方向 ![]() 使得沿着这个新方向移动样本可以改变“属性一”而不影响 “属性二”。对于涉及多个属性的情况,他们用原始方向减去其在其他所有条件方向上的投影。
使得沿着这个新方向移动样本可以改变“属性一”而不影响 “属性二”。对于涉及多个属性的情况,他们用原始方向减去其在其他所有条件方向上的投影。
基于预训练的 StyleGAN 或 StyleGAN2 模型的其他 GAN inverison方法,也可以操纵多个属性,因为 W 空间的分离性比 Z 空间强。然而,正如最近的方法所观察到的,一些属性在 W 空间中仍然耦合,导致我们在操作给定图像时发生一些非预期的变化。
Wu 等人没有在语义 W 空间中进行操作,而是提出了 S 空间(style space)。样式编码(style code)是通过连接 StyleGAN2 生成器的所有仿射层的输出而形成的。实验表明,S 空间可以缓解空间耦合变化并进行精确的局部修改。通过直接干预style code s∈S,他们的方法可以在不影响其他属性的情况下操纵不同的面部属性以及各种语义方向,并且可以实现对局部转换的精细控制。
5. 应用
找到好的 GAN Inversion 方法,使我们能够在不影响下游任务的编辑能力的情况下匹配目标图像。 GAN Inversion 不需要任务特定的密集标记数据集,可以应用于许多任务,例如图像处理、图像插值、图像恢复、风格转换、新视图合成,甚至对抗防御。除了常见的图像编辑应用之外,在过去几个月中,GAN Inversion 已被广泛引入许多其他任务,例如 3D 重建、图像理解、多模态学习和医学成像,这显示了它对不同任务的多功能性和使更多研究领域受益的能力。
5.1 图像处理
给定图像 x,我们希望通过改变其 latent code z 来编辑某些区域,并通过对训练有素的 GAN 模型 G 的 latent representation 进行线性变换来获得目标图像 x' 的 z'。这可以在 GAN Inversion 的框架中表述为
![]()
其中 n 是对应于 latent space 中特定语义的法线方向,α 是操作的步长。换句话说,如果一个 latent code 在某个方向上移动,那么输出图像中包含的语义应该相应地发生变化。
- Voynov 等人在不改变前景(foreground)的情况下,逐渐确定对应于背景去除或背景模糊的方向。
- Shen等人通过投影和正交化不同的向量来实现单个和多个面部属性操作。
- Zhu 等人通过降低或增加语义程度来执行语义操作。
- Shen 和 Zhu 的方法都使用投影策略来搜索语义方向 n。
一些方法可以执行感兴趣区域编辑,这允许用户图像中的某些所需区域进行编辑。此类操作通常需要额外的工具来选择所需的区域。 例如,
- Abdal 等人分析了在 FFHQ 上训练的 StyleGAN 的有缺陷的图像 embedding,即带有 mask 区域的图像的 embedding。实验表明,StyleGAN embedding 对图像中的缺陷具有很强的鲁棒性,并且不同面部特征的 embedding 相互独立。根据观察,他们开发了一种基于 mask 的局部操作方法。他们为 mask 外的区域找到了合理的 embedding,并在 mask 的像素中填充了合理的语义内容。
- Zhu 等人使用他们的域内逆映射方法进行语义 diffusion。 该任务是将目标人脸插入到语境中并使它们兼容。他们的方法可以保持目标图像的显著特征(例如,面部身份)并同时适应语境信息。
除了语义外,一些方法还可以操纵图像的其他方面,例如几何、纹理和颜色。例如,改变面部朝向的姿势旋转,操纵几何(例如,缩放/移动/旋转)、纹理(例如,背景模糊/添加草/锐度)和颜色( 例如,光照/饱和度)。
5.2 图象生成
针对图像生成任务提出了几种基于 GAN inversion 的方法,例如改变发型、few-shot 语义图像合成 和无限分辨率图像合成。
- Saha 等人通过优化 StyleGAN2 的扩展 latent space 和噪声空间,开发了一种逼真的发型转变方法。
- Endo 等人假设,共享相同语义的像素具有相似的 StyleGAN 特征,以从 latent space 中的随机噪声生成图像和相应的伪语义 mask,并使用最近邻搜索进行合成。该方法将编码器与固定的 StyleGAN 生成器集成在一起,并以监督方式,使用伪标记数据训练编码器,从而控制生成器。
- Cheng 等人提出了一种基于 GAN inversion 的图像修复(inpainting)和图像扩展(outpainting)方法。坐标条件生成器(coordinate-conditioned generator)旨在生成可连接成完整图像的补丁。 基于联合 latent code 及其坐标的 latent code 合成与输入图像重叠的图像。可用输入补丁的最佳 latent code,是在 outpainting 阶段,在经过训练的基于补丁的生成器的 latent space 中确定的。
GAN inversion 可以应用于交互式生成,即从用户绘制的笔画开始,生成最能满足用户约束的自然图像。
- Zhu 等人显示用户可以使用画笔工具从头开始生成图像,然后不断添加更多涂鸦(scribbles)来完善结果。
- Abdal 等人逆转 StyleGAN 以根据用户涂鸦执行语义局部编辑。使用这种方法,可以将简单的涂鸦嵌入到 StyleGAN 的某些层中,从而将其转换为逼真的图像。此应用有助于现有的交互式图像处理任务,例如草图到图像生成和基于草图的图像检索,这些任务通常需要密集标记的数据集。
5.3 图像恢复
许多图像恢复任务可以看作是修复图像的缺陷。一种常见的做法是学习从有缺陷图像到修复图像 x 的映射,这通常需要针对不同的映射进行特定于任务的训练。或者,GAN inversion 可以使用存储在一些先验中的 x 的统计信息,并通过将有缺陷图像视为 x 的部分观察,从而在 x 的空间中搜索与有缺陷图像最匹配的最佳 x。
Abdal 等人观察到 StyleGAN embedding 对图像中的缺陷(例如 mask 区域)非常稳健。基于这一观察,他们提出了一种基于 inversion 的图像修复方法,将源缺陷图像嵌入到 W+ 空间的早期层以预测缺失内容,并嵌入到后期层以保持颜色一致性。
Pan 等人声称固定的 GAN 生成器不可避免地受到训练数据分布的限制,其 inversion 不能忠实地重建未看过的复杂图像。因此,他们提出了一种轻松且更实用的重建公式,用于在经过训练的 GAN 模型中捕获自然图像的统计数据,就像先验方法一样,即深度生成先验 (deep generative prior,DGP)。 具体来说,他们重写公式 (3),使其允许生成器参数在目标图像上动态微调:
![]()
其中,![]() 分别是有缺陷图像、正常图像到有缺陷图像的映射。他们的方法在着色、修复和超分辨率方面的性能可与最先进的方法相媲美。虽然未预期的错误(artifacts)有时会出现在 GAN 模型合成的人脸图像中,但 Shen 等人表明,在 latent space 中编码的质量信息可用于恢复。PGGAN 生成的 artifacts 可以通过使用线性 SVM,将 latent code 移向由分离超平面定义的正质量方向来纠正。
分别是有缺陷图像、正常图像到有缺陷图像的映射。他们的方法在着色、修复和超分辨率方面的性能可与最先进的方法相媲美。虽然未预期的错误(artifacts)有时会出现在 GAN 模型合成的人脸图像中,但 Shen 等人表明,在 latent space 中编码的质量信息可用于恢复。PGGAN 生成的 artifacts 可以通过使用线性 SVM,将 latent code 移向由分离超平面定义的正质量方向来纠正。
5.4 图像插值
使用 GAN inversion,可以通过在给定图像的相应 latent code 之间进行渐变(morphing)来插入新结果。给定一个训练有素的 GAN 生成器 G 和两个目标图像 xA 和 xB,它们之间的渐变可以通过在它们的 latent code zA 和 zB 之间进行插值来实现。 通常,可以通过应用线性插值来获得 xA 和 xB 之间的 latent code:
![]()
此外,在 DGP中,重建两个目标图像 xA 和 xB 将分别产生两个生成器,以及相应的 latent code zA 和 zB,因为它们还微调了生成器。在这种情况下, xA 和 xB 之间的变形可以通过 latent code 和生成器参数的线性插值来实现:
![]()
然后,可以基于 latent code 和生成器参数生成图像。
5.5 3D 重建
对于 3D 数据,Pan 等人和 Zhang 等人提出基于 GAN inversion 的单幅图像和点云补全(point cloud completion)的 3D 形状重建。
给定由 GAN 生成的图像,从初始椭圆形(ellipsoid) 3D 目标形状开始,Pan 等人首先用各种随机采样的视角和光照条件(称为伪样本)渲染一些不自然的图像。 通过使用 GAN 重建它们,这些伪样本可以将原始图像引导到 GAN 流形中的采样视角和光照条件,从而产生许多看起来很自然的图像(称为投影样本)。 这些投影样本可以用作可微分渲染过程的真值(ground truth),以改进先前的 3D 形状。
Zhang 等人没有使用现有的在图像上训练的 2D GAN,而是首先以点云的形式在 3D 形状上训练生成器 G。 预训练生成器使用 latent code 来生成完整的形状。给定部分形状,他们寻找目标 latent code z 并微调 G 的参数,以通过梯度下降最好地重建完整形状。
5.6 图象理解
一些方法使用预训练的 GAN 模型的 representation,并将这些 representation 用于语义分割和 alpha 抠图(matting)。
Tritrong 等人首先将图像嵌入到 latent space 中获得 latent code z,然后将 z 送到具有多个激活映射的生成器中。这些图被上采样并沿通道维度连接,从而形成所需的 representation。使用一些手动注释的图像和提取的 representation 来训练分割模块。在推断过程中,从测试图像中提取 representation 并将其输入分割器以获得分割映射。
抠图任务使用两个预训练生成器、一个 alpha 网络和一个鉴别器。 一个生成器 G(z) 负责生成前景图像,另一个生成器 Gbg (z') 负责生成背景图像。 alpha 网络预测用于抠图的 mask A(z)⊙G(z)。 合成图像可以通过使用 A(z)⊙G(z) + (1 - A(z)) Gbg (z') 混合背景和前景来获得,目标是鉴别器 D 无法区分其与真实图像。 训练时,两个生成器被冻结,只有 alpha 网络和判别器通过对抗学习进行训练。
5.7 多模态(Multimodal)学习
对于多模态学习,最近的几项研究都集中在使用 StyleGAN 进行语言驱动的图像生成和操作上。
- Xia 等人通过训练编码器,将文本映射到 StyleGAN 的 latent space,并进行风格混合,从而产生不同的结果,为文本到图像生成和文本引导图像处理任务提出了一个新的统一框架。
- Wang 等人提出了类似的想法,但在 inversion 期间引入了循环一致性(cycle-consistency)训练,以学习更稳健和一致的 latent code。
另一方面,一些方法首先获取给定图像的 latent code,并在一些强大的预训练语言模型的指导下找到目标图像中所需属性的 latent code,例如 CLIP 或 ALIGN。
- Logacheva 等人提出了一种基于 StyleGAN inversion 的风景动画视频生成模型。
- Lee 等人提出了一个声音引导的图像编辑框架。他们训练音频编码器将声音编码到多模态 latent space 中,其中音频的 representation 与文本-图像的 representation 对齐,从而指导图像处理。
5.8 医学图像
GAN inversion 最近被引入到医学应用中。这些方法用于数据扩充,其中公开的可用的医学数据集通常已过时、有限或注释不充分。通常,这些方法在特定领域的医学图像数据集上训练 GAN 模型,例如计算机断层扫描 (CT) 或磁共振 (MR),并使用现有的 GAN inversion 方法进行逆映射和操作。
- Fetty 等人提出了一种基于 Style-GAN 的方法,可通过遍历 latent space 中的点(参见第 4.4 节)或样式混合 [13] 来合成具有所需属性的 CT 或 MR 图像。
- 为了合成具有所需属性的医学图像,Ren 等人使用特定领域的 GAN inversion 技术生成具有所需形状和纹理的乳房 X 光照片,用于心理物理学实验。
总体而言,这些基于 GAN inversion 的方法在医学图像合成中实现了更好的可解释性和可控性。
6. 挑战和未来方向
理论理解。 虽然在将 GAN inversion 应用于图像编辑方面做出了重大努力,但很少有人关注从理论上更好地理解 latent space:数据中的非线性结构可以紧凑地表示,并且导出的几何结构需要使用非线性统计工具、黎曼流形(Riemannian manifolds)和局部线性方法。 相关领域的成熟理论可以促进从不同角度进行理解。 最近的一些方法将潜在空间视为 latent space 结构,它涉及不同的概念和度量。
Inversion 类型。除了 GAN inversion 之外,还开发了一些方法来逆映射基于编码器-解码器架构的生成模型。
- IIN 学习变分自动编码器 (variational autoencoders,VAE) 的可逆解耦解释。
- Zhu 等人开发隐式可逆自动编码器来学习面部图像的分离的 representation,可以基于属性进行编辑。
- LaDDer 使用基于生成先验(包括添加 VAE 和混合超先验)的元嵌入(meta-embedding),将训练有素的 VAE 的 latent space 投影到低维 latent space,其中多个 VAE 模型用于生成分层 representation。
探索结合 GAN inversion 和编码器-解码器 inversion 是有益的,这样我们就可以两全其美。
域泛化(Domain Generalization)。正如第 5 节中所讨论的,GAN inversion 被证明在跨域应用(例如样式转换和图像恢复)中是有效的,这表明预训练模型已经学习了与域无关的特征。来自不同域的图像可以逆映射到相同的 latent space 中,从中可以得出有效的度量。
目前已经开发了多任务方法来协同利用视觉线索,例如 GAN 框架内的图像恢复、图像分割或语义分割、深度估计。
开发有效且一致的方法来逆映射中间共享 representations 是具有挑战性但值得的,这样我们就可以在统一的框架下处理不同的视觉任务。
隐式表示(Implicit Representation)。 一些基于预训练 GAN 的方法可以操纵几何(例如,缩放、移位和旋转)、纹理(例如,背景模糊和锐度)和颜色(例如,光照和饱和度)。 这种能力表明在大规模数据集上预训练的 GAN 模型已经从真实场景中学习了一些物理信息。
隐式神经表示学习(Implicit neural representation learning)是 3D 计算机视觉的最新趋势,它学习 3D 形状或场景的隐式函数,并能够控制场景属性,例如光照、相机参数、姿势、几何形状、 外观和语义结构。 它已被用于立体性能捕获(volumetric performance capture)、新视图合成、面部形状生成、对象建模和人体重建。
最近的 StyleRig 方法被训练为将 3D 可变形模型 (3DMM) 的参数与 Style-GAN 的输入对齐。 它开辟了一个有趣的研究方向,逆映射预训练 GAN 的隐式表示来 3D 重建,例如,使用 StyleGAN 进行人脸建模或延时视频生成。
精确控制。 GAN inversion 可用于寻找图像处理的方向,同时保留身份和其他属性。 然而,需要进行一些调整,以在细粒度级别上实现所需的精确控制粒度,例如,凝视重定向(gaze redirection)、重新照明(relighting)、和连续视图控制。 这些任务需要精确控制,即相机视图或凝视方向的 1°。当前的 GAN inversion 方法无法处理这些任务。因此需要更多的努力,例如创造更多解耦的 latent space 和发现更多可解释的方向。
多模态逆映射(Multimodal Inversion)。现有的 GAN inversion 方法主要集中在图像上。 然而,生成模型的最新进展超出了图像领域,例如用于音频合成的 GPT-3 语言模型和 WaveNet。 这些复杂的深度神经网络在不同的大规模数据集上进行训练,证明能够代表广泛的不同内容、风格、情感和主题。 将 GAN inversion 应用于不同的模态可以为语言风格迁移等任务提供新的视角。此外,许多 GAN 模型被开发用于多模态生成或转换。将 GAN 模型逆映射为多模式 representation 以创建新颖的内容、行为和交互是一个很有前途的方向。
评估指标。可以更好地评估逼真且多样化的图像,或确认与原始图像一致性新的感知质量指标,仍有待探索。目前的评估主要集中在评估逼真度,或者生成图像的分布是否与用于训练的真实图像一致。 然而,仍然缺乏有效的评估工具来评估生成图像与预期结果之间的差异,或更直接地评估倒逆映射的 latent code。
7. 结论
GAN 等深度生成模型通过图像生成的弱监督,学习训练数据的潜在变化因素。在图像生成中,发现和控制可解释的 latent representation 有助于广泛的图像编辑应用。本文对 GAN inversion 进行了全面调查,重点介绍了算法和应用。我们总结了 GAN latent space 和模型的重要属性,然后介绍了四种 GAN inversion 方法及其关键属性。然后,我们介绍 GAN inversion 的几个引人入胜的应用,包括图像处理、图像生成、图像恢复以及图像处理以外的最新应用。我们最后讨论了 GAN inversion 的挑战和未来方向。
参考
Xia, W., Zhang, Y., Yang, Y., Xue, J. H., Zhou, B., & Yang, M. H. (2022). Gan inversion: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence.
总结 & 一些想法
一种便捷的处理图像的方式就是,基于逆映射的方法,把图像和处理方式(基于文字、图像、视频、音频等多模态的引导)逆映射到 latent space 中获得相应的 latent code(embedding、latent representation)。通过对 latent code 的处理来实现对图像的间接处理。
逆映射的方法有三种:
- 基于学习的方法(训练一个编码器)、
- 基于优化的方法(创建一个生成最优 latent code 的目标函数)、
- 基于前两者混合的方法(训练一个编码器预测一个大概的值,把该值当做优化的初始值)。
隐空间有七种:
- Z 空间:从简单分布中随机采样得到的空间。
- W 空间:使用由多层感知器构成的非线性映射网络把 Z 空间映射到 W 空间。相比于 Z 空间,可以缓解简单分布的限制。
- W+ 空间:把与网络层数对应数目的 latent code w 串联,然后送入每一层的 AdaIN,得到 W+ 空间。相比于 W 空间,属性有更高的解耦度。
- S 空间:通过对生成器的每一层使用不同的仿射变换,把 W 空间转换为 S 空间。相比于 W 空间,属性有更高的解耦度。
- P 空间:高维高斯分布的大部分密度靠近超球体的表面,(假设)latent code 的联合分布近似于多元高斯分布,则可以把图像嵌入到 Z 空间的超球体的表面,从而得到 P 空间。
- P_N 空间:通过 PCA 白化操作把 P 空间转换为 P_N 空间,从而消除依赖性和冗余。
- P_N+ 空间:对 P_N 空间空间进一步扩展可以得到 P_N+ 空间
补充知识
1. 反卷积
反卷积的英文:Deconvolution、Transposed Convolution 或 Fractional-strided Convolutions。
反卷积是从低分辨率映射到大分辨率的过程,用于扩大图像尺寸。
反卷积是一种特殊的正向卷积,而不是卷积的反过程。
反卷积的具体操作:为输入大小为 n*n 的图像的相邻像素之间添加 n-1 个零元素,则获得大小为 (2n-1)*(2n-1)的图像。对该图像进行常规卷积操作即可。
2. 扩展 latent space W+

为获取相比于初始 latent space Z 和中间 latent space W 更好的性能,使用一个扩展的 latent space W+:若 StyleGAN 总共有 L 层,则把 L 个不同的 latent code w 串联,并通过 AdaIN 分别送入 StyleGAN 的每一层。如上图所示。StyleGAN 的层数由输出图像分辨率决定:L=2log2 R - 2。最大分辨率 1024*1024 对应 18 层的结构。
3. 仿射变换
以矩阵乘法(线性变换)和向量加法(平移变换)的形式表示的一种变换。
可以用仿射变换来表示:旋转(线性变换)、尺度变化(线性变换)、平移(向量加法)
4. 白化(Whitening)
Whitening 的目的是去掉数据之间的相关联度,是很多算法进行预处理的步骤。比如说当训练图片数据时,由于图片中相邻像素值有一定的关联,所以很多信息是冗余的。这时候去相关的操作就可以采用白化操作。数据的 whitening 必须满足两个条件:一是不同特征间相关性最小,接近0;二是所有特征的方差相等(不一定为1)。常见的白化操作有PCA whitening和ZCA whitening。
PCA whitening 是指,将数据 x 经过 PCA 降维为 z 后,可以看出 z 中每一维是独立的,满足whitening 的第一个条件。此时,只需要将 z 中的每一维都除以标准差就得到了每一维的方差为1,也就是说方差相等。
ZCA whitening 是指数据 x 先经过 PCA 变换为 z,但是并不降维,因为这里是把所有的成分都选进去了。此时,也同样满足 whtienning 的第一个条件,特征间相互独立。然后同样进行方差为 1 的操作,最后将得到的矩阵左乘一个特征向量矩阵 U 即可。