post json后台处理数据_【翻译】使用 Golang 处理每分钟 100 万次的请求
使用 Golang 处理每分钟 100 万次的请求
Marcio Castilho
2017 年 8 月 31 日・大概 7 分钟阅读时间
我在反垃圾邮件、反病毒和反恶意软件行业工作了 15 年,由于我们每天处理的数据量巨大,这些系统最终可能会变得非常复杂。
目前我是 smsjunk.com 公司的 CEO 和 KnowBe4 公司的首席架构师,这两家公司都活跃在网络安全行业。
在过去的 10 年里,我作为一名软件工程师,参与的所有 Web 后端开发大部分都是在 Ruby on Rails 中完成的。不要误解我,我喜欢 Ruby on Rails,我相信它是一个很棒的环境,但是过了一段时间,您开始以 ruby 的方式思考和设计系统,您就会忘记利用多线程、并行化、快速执行和较小的内存开销等方式,来使你的软件体系结构变的高效和简单。多年来,我一直是一名 C/C++, Delphi 和 C# 开发者,我最近才意识到,使用合适的工具工作可以把事情变的简单。
我对互联网上经常发生的语言和框架的战争不是很感兴趣。我相信,效率、生产率和代码可维护性主要取决于您构建的解决方案的难易程度。
问题
在开发匿名遥测和分析系统时,我们的目标是能够处理来自数百万个客户端的大量 POST 请求。web 处理程序将接收一个 JSON 文档,该文档可能包含许多需要写入 Amazon S3 的有效负载集合,以便我们的 map-reduce 系统以后对这些数据进行操作。
我们会考虑使用以下工具创建工作层架构:
Sidekiq
Resque
DelayedJob
Elasticbeanstalk Worker Tier
RabbitMQ
等等 …
设置两个不同的集群,一个用于 web 前端,另一个用于工作人员,这样我们就可以扩展我们能够处理的后台工作的数量。
从一开始,我们的团队就知道我们应该使用 Go 来开发,因为在讨论阶段,我们预测到这将会是一个非常庞大的流量系统。我已经使用 Go 开发大约两年了,但是在开发的系统中没有一个能够承受这么大的负载。
我们首先创建了一些结构来定义通过 POST 调用接收的 web 请求负载,把它上传到我们的 S3 bucket 中的方法。
type PayloadCollection 简单的 Go 协程方法
一开始我们采用了一个非常简单的 POST 处理程序实现,只是试图将工作处理并行化为一个简单的 goroutine :
func 对于中等负载,这对大多数人来说是可行的,但事实很快证明,这种方法在大规模应用时效果不是很好。我们预估会有很多请求,但并没有达到我们的第一个版本部署到生产环境时看到的数量级。我们完全低估了流量。
上面的方法在几个方面都很糟糕。我们没有办法控制生成 go 协程的数量。因为我们每分钟收到 100 万个 POST 请求,这段代码很快就崩溃了。
再次尝试
我们需要找到另一种方法。从一开始,我们就开始讨论如何让请求处理程序的生命周期尽可能的短,并在后台生成处理。当然,这是在 Ruby on Rails 的世界中必须做的,否则你将阻塞所有可用的 worker web 处理器,无论您使用的是 puma、unicorn 还是 passenger (请不要讨论 JRuby)。然后,我们需要利用常见的解决方案来实现这一点,如 Resque、Sidekiq、SQS 等。这样的例子不胜枚举,因为实现这个目标的方法有很多种。
因此,第二个迭代是创建一个缓冲通道,在这里我们可以使用队列将作业上传到 S3,因为我们可以控制队列中的最大项目数量,并且我们有足够的 RAM 在内存中处理作业队列,所以我们认为只缓冲通道队列中的作业是可行的。
var Queue 然后,要实际取消作业的排队和处理它们,我们可以使用类似的方法:
func 说实话,我不知道我们在想什么。这一定是一个充满红牛的深夜。这种方法没有给我们带来任何好处,我们用一个缓冲队列来交换有缺陷的并发性,这个缓冲队列只是推迟了问题的解决。我们的同步处理器一次只向 S3 上传一个负载,由于传入请求的速率远远大于单处理器向 S3 上传的能力,我们的缓冲通道很快就达到了它的极限,并阻止了请求处理程序对更多项目进行排队的能力。
我们只是在回避这个问题,在我们部署这个有缺陷的版本后,我们的延迟率在几分钟内一直在以恒定的速率增长。
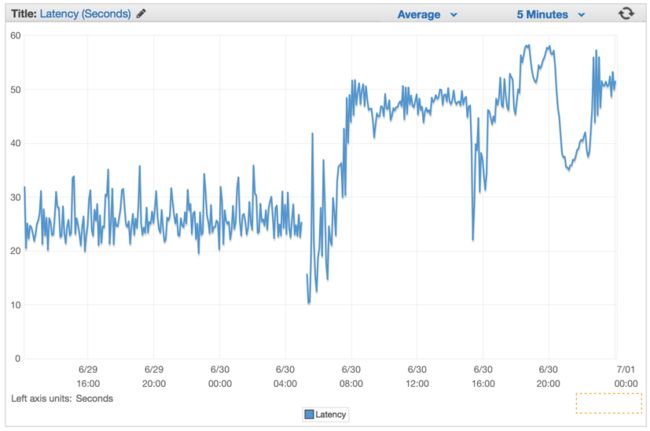
更好的解决方案
我们决定在使用 Go 通道时使用一个公共模式,以创建一个两层通道系统,一个用于排队作业,另一个用于控制有多少工作人员同时操作作业队列。
我们的想法是将上传到 S3 的数据并行化,以一种可持续的速度,既不会使机器瘫痪,也不会从 S3 开始产生连接错误。所以我们选择创建 Job/Worker 模式。对于那些熟悉 Java,C# ,等语言的人来说,可以将其视为利用 Go 通道实现的 Worker 线程池。
var 代码已被折叠,点此展开
我们已经修改了 Web 请求处理程序,用有效负载创建了一个 Job 结构的实例,并发送到 JobQueue 通道,供 worker 获取数据。
func 在我们 web 服务器初始化期间,我们创建了一个 Dispatcher 并调用 Run() 以创建工作池并开始侦听将出现在 JobQueue 中的作业。
:= 下面是我们的 dispatcher 实现的代码:
type Dispatcher 代码已被折叠,点此展开
注意,我们提供了要实例化并添加到工作池中的最大工作线程数。因为我们在这个项目中使用了 Amazon Elasticbeanstalk 和 dockerized 的 Go 环境,并且我们始终遵循 12 - 因素 方法来配置生产环境中的系统,所以我们从环境变量中读取这些值。这样我们就可以控制作业队列的 worker 数量和最大值,这样我们就可以快速地调整这些值,而不需要重新部署集群。
var 在我们部署它之后,我们看到所有的延迟率下降到微不足道的数字,我们处理请求的能力急剧增加。
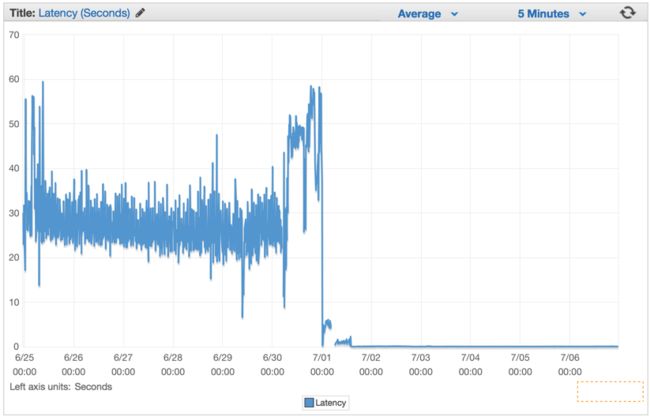
在弹性负载平衡器完全预热几分钟后,我们看到 ElasticBeanstalk 应用程序每分钟服务近 100 万个请求。在早上的几个小时里,我们的流量通常会达到每分钟一百多万次。
当我们部署了新代码,服务器的数量从 100 台大幅度减少到大约 20 台。
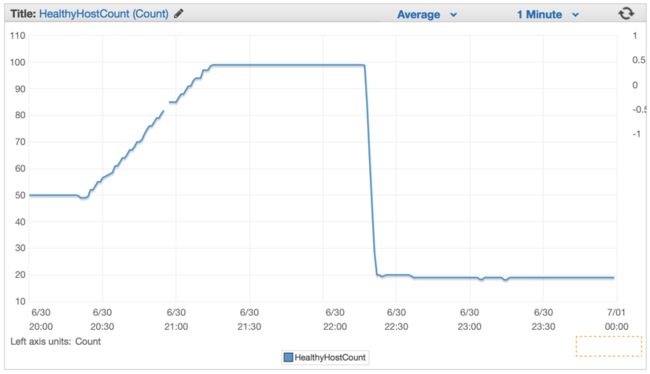
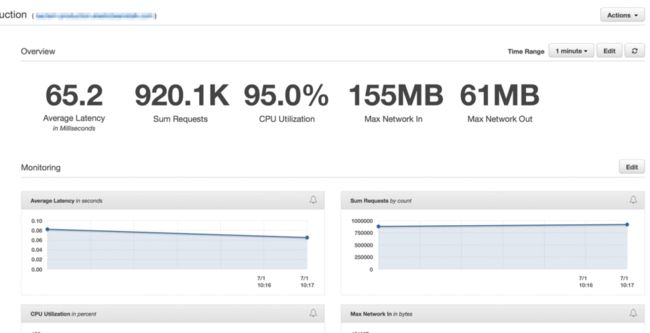
在正确配置集群和自动伸缩设置后,我们能够将其进一步降低到只有 4x EC2 c4。如果 CPU 连续 5 分钟超过 90%,大实例和弹性自动伸缩设置将生成一个新实例。
总结
在我的字典里,简单是最重要的。我们本可以设计一个包含许多队列、后台工作人员、复杂的开发环境,但我们决定利用 Elasticbeanstalk 的自动伸缩功能以及 Golang 为我们提供的简单有效的并发方法。
不是每天都能有一个仅需要 4 台机器,性能远不如我现在的 MacBook Pro 的,可以每分钟处理 100 万次向 AmazonS3 bucket 写入 POST 请求的集群。
总会有合适的工具。有时候当你的 Ruby on Rails 系统需要一个非常强大的 web 处理程序时,请在 Ruby 生态系统之外考虑一些更简单、更强大的替代解决方案。