Zookeeper Leader 选举算法
本文首发于http://www.yidooo.net/2014/10/18/zookeeper-leader-election.html 转载请注明出处
当Leader崩溃或者Leader失去大多数的Follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的Leader,让所有的Server都恢复到一个正确的状态。Zookeeper中Leader的选举采用了三种算法:
- LeaderElection
- FastLeaderElection
- AuthFastLeaderElection
并且在配置文件中是可配置的,对应的配置项为electionAlg。
背景知识
Zookeeper Server的状态可分为四种:
- LOOKING:寻找Leader
- LEADING:Leader状态,对应的节点为Leader。
- FOLLOWING:Follower状态,对应的节点为Follower。
- OBSERVING:Observer状态,对应节点为Observer,该节点不参与Leader选举。
成为Leader的必要条件: Leader要具有最高的zxid;当集群的规模是n时,集群中大多数的机器(至少n/2+1)得到响应并follow选出的Leader。
心跳机制:Leader与Follower利用PING来感知对方的是否存活,当Leader无法相应PING时,将重新发起Leader选举。
术语
zxid:zookeeper transaction id, 每个改变Zookeeper状态的操作都会形成一个对应的zxid,并记录到transaction log中。 这个值越大,表示更新越新。
electionEpoch/logicalclock:逻辑时钟,用来判断是否为同一次选举。每调用一次选举函数,logicalclock自增1,并且在选举过程中如果遇到election比当前logicalclock大的值,就更新本地logicalclock的值。
peerEpoch: 表示节点的Epoch。
LeaderElection选举算法
LeaderElection是Fast Paxos最简单的一种实现,每个Server启动以后都询问其它的Server它要投票给谁,收到所有Server回复以后,就计算出zxid最大的哪个Server,并将这个Server相关信息设置成下一次要投票的Server。该算法于Zookeeper 3.4以后的版本废弃。
选举算法流程如下:
- 选举线程首先向所有Server发起一次询问(包括自己);
- 选举线程收到回复后,验证是否是自己发起的询问(验证xid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
- 收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
- 线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得多数Server票数, 设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
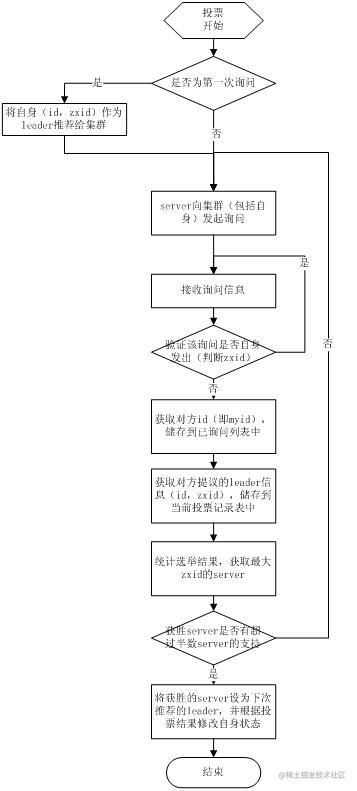
通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1.
异常问题的处理:
- 选举过程中,Server的加入
当一个Server启动时它都会发起一次选举,此时由选举线程发起相关流程,那么每个 Serve r都会获得当前zxi d最大的哪个Serve r是谁,如果当次最大的Serve r没有获得n/2+1 个票数,那么下一次投票时,他将向zxid最大的Server投票,重复以上流程,最后一定能选举出一个Leader。 - 选举过程中,Server的退出
只要保证n/2+1个Server存活就没有任何问题,如果少于n/2+1个Server 存活就没办法选出Leader。 - 选举过程中,Leader死亡
当选举出Leader以后,此时每个Server应该是什么状态(FLLOWING)都已经确定,此时由于Leader已经死亡我们就不管它,其它的Fllower按正常的流程继续下去,当完成这个流程以后,所有的Fllower都会向Leader发送Ping消息,如果无法ping通,就改变自己的状为(FLLOWING ==> LOOKING),发起新的一轮选举。 - 选举完成以后,Leader死亡
处理过程同上。 - 双主问题
Leader的选举是保证只产生一个公认的Leader的,而且Follower重新选举与旧Leader恢复并退出基本上是同时发生的,当Follower无法ping同Leader是就认为Leader已经出问题开始重新选举,Leader收到Follower的ping没有达到半数以上则要退出Leader重新选举。
FastLeaderElection选举算法
由于LeaderElection收敛速度较慢,所以Zookeeper引入了FastLeaderElection选举算法,FastLeaderElection也成了Zookeeper默认的Leader选举算法。
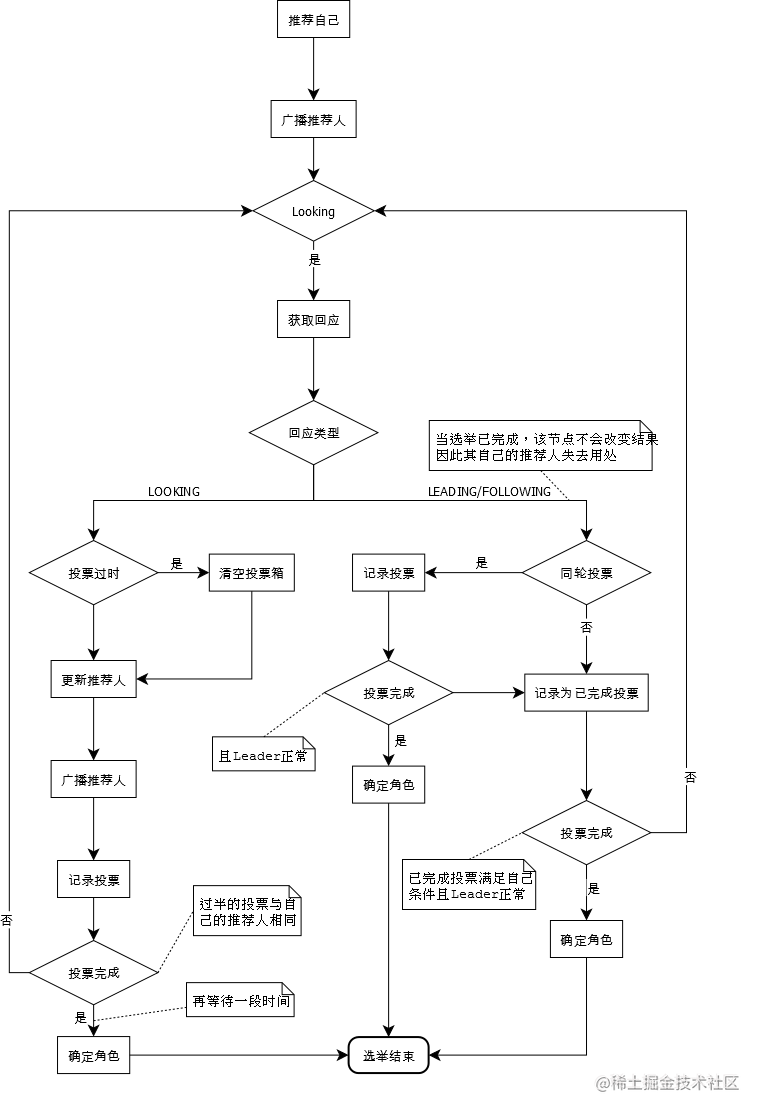
FastLeaderElection是标准的Fast Paxos的实现,它首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决 epoch 和 zxid 的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息。FastLeaderElection算法通过异步的通信方式来收集其它节点的选票,同时在分析选票时又根据投票者的当前状态来作不同的处理,以加快Leader的选举进程。
算法流程
数据恢复阶段
每个ZooKeeper Server读取当前磁盘的数据(transaction log),获取最大的zxid。
发送选票
每个参与投票的ZooKeeper Server向其他Server发送自己所推荐的Leader,这个协议中包括几部分数据:
- 所推举的Leader id。在初始阶段,第一次投票所有Server都推举自己为Leader。
- 本机的最大zxid值。这个值越大,说明该Server的数据越新。
- logicalclock。这个值从0开始递增,每次选举对应一个值,即在同一次选举中,这个值是一致的。这个值越大说明选举进程越新。
- 本机的所处状态。包括LOOKING,FOLLOWING,OBSERVING,LEADING。
处理选票
每台Server将自己的数据发送给其他Server之后,同样也要接受其他Server的选票,并做一下处理。
如果Sender的状态是LOOKING
- 如果发送过来的logicalclock大于目前的logicalclock。说明这是更新的一次选举,需要更新本机的logicalclock,同事清空已经收集到的选票,因为这些数据已经不再有效。然后判断是否需要更新自己的选举情况。首先判断zxid,zxid大者胜出;如果相同比较leader id,大者胜出。
- 如果发送过来的logicalclock小于于目前的logicalclock。说明对方处于一个比较早的选举进程,只需要将本机的数据发送过去即可。
- 如果发送过来的logicalclock等于目前的logicalclock。根据收到的zxid和leader id更新选票,然后广播出去。
当Server处理完选票后,可能需要对Server的状态进行更新:
- 判断服务器是否已经收集到所有的服务器的选举状态。如果是根据选举结果设置自己的角色(FOLLOWING or LEADER),然后退出选举。
- 如果没有收到没有所有服务器的选举状态,也可以判断一下根据以上过程之后更新的选举Leader是不是得到了超过半数以上服务器的支持。如果是,那么尝试在200ms内接收下数据,如果没有心数据到来说明大家已经认同这个结果。这时,设置角色然后退出选举。
如果Sender的状态是FOLLOWING或者LEADER
- 如果LogicalClock相同,将数据保存早recvset,如果Sender宣称自己是Leader,那么判断是不是半数以上的服务器都选举它,如果是设置角色并退出选举。
- 否则,这是一条与当前LogicalClock不符合的消息,说明在另一个选举过程中已经有了选举结果,于是将该选举结果加入到OutOfElection集合中,根据OutOfElection来判断是否可以结束选举,如果可以也是保存LogicalClock,更新角色,退出选举。
具体实现
数据结构
本地消息结构:
static public class Notification {
long leader; //所推荐的Server id
long zxid; //所推荐的Server的zxid(zookeeper transtion id)
long epoch; //描述leader是否变化(每一个Server启动时都有一个logicalclock,初始值为0)
QuorumPeer.ServerState state; //发送者当前的状态
InetSocketAddress addr; //发送者的ip地址
}
网络消息结构:
static public class ToSend {
int type; //消息类型
long leader; //Server id
long zxid; //Server的zxid
long epoch; //Server的epoch
QuorumPeer.ServerState state; //Server的state
long tag; //消息编号
InetSocketAddress addr;
}
线程处理
每个Server都一个接收线程池和一个发送线程池, 在没有发起选举时,这两个线程池处于阻塞状态,直到有消息到来时才解除阻塞并处理消息,同时每个Server都有一个选举线程(可以发起选举的线程担任)。
- 接收线程的处理
notification: 首先检测当前Server上所被推荐的zxid,epoch是否合法(currentServer.epoch <= currentMsg.epoch && (currentMsg.zxid > currentServer.zxid || (currentMsg.zxid == currentServer.zxid && currentMsg.id > currentServer.id))) 如果不合法就用消息中的zxid,epoch,id更新当前Server所被推荐的值,此时将收到的消息转换成Notification消息放入接收队列中,将向对方发送ack消息。
ack: 将消息编号放入ack队列中,检测对方的状态是否是LOOKING状态,如果不是说明此时已经有Leader已经被选出来,将接收到的消息转发成Notification消息放入接收对队列 - 发送线程池的处理
notification: 将要发送的消息由Notification消息转换成ToSend消息,然后发送对方,并等待对方的回复,如果在等待结束没有收到对方法回复,重做三次,如果重做次还是没有收到对方的回复时检测当前的选举(epoch)是否已经改变,如果没有改变,将消息再次放入发送队列中,一直重复直到有Leader选出或者收到对方回复为止。
ack: 主要将自己相关信息发送给对方 - 选举线程的处理
首先自己的epoch加1,然后生成notification消息,并将消息放入发送队列中,系统中配置有几个Server就生成几条消息,保证每个Server都能收到此消息,如果当前Server的状态是LOOKING就一直循环检查接收队列是否有消息,如果有消息,根据消息中对方的状态进行相应的处理。
AuthFastLeaderElection选举算法
AuthFastLeaderElection算法同FastLeaderElection算法基本一致,只是在消息中加入了认证信息,该算法在最新的Zookeeper中也建议弃用。
Example
下面看一个Leader选举的例子以加深对Leader选举算法的理解。
- 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态.
- 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
- 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的Leader,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的Leader.
- 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能是Follower.
- 服务器5启动,同4一样,Follower.
参考资料
blog.csdn.net/xhh198781/a…
blog.cnsolomo.com/ld/liunx/ng…
blog.sina.com.cn/s/blog_3fe9…
blog.csdn.net/xhh198781/a…
csrd.aliapp.com/?p=162
codemacro.com/2014/10/19/…
作者:核动力蜗牛
链接:https://juejin.cn/post/6844903672824987661