ElasticSearch 认识和深入(一)
ElasticSearch 认识和深入
ElasticSearch 概述
官网地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/intro.html
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。
简单来说,就是 lucene 是一个 jar包。 读写索引的工具 ! 排序,搜索规则的 工具类。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
总结:ElasticSearch ,简称es, es是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台 服务上,处理 非常大的数据。
Solr 概述
Solr 是Apache 下的一个顶级的开源项目,采用Java 开发,它是基于Lucene 的全文搜索服务器。 Solr 提供了比 Lucene 更为丰富的查询语言,同时实现了可配置,可扩展,并对索引,搜索性能进行了优化。
Solr 可以独立运行!运行在 Jetty,Tomcat 等这些Servlet容器中,Solr索引的实现方法很简单,用 POST方法想Solr 服务器发送一个描述Field及其内容的XML文档,Solr 根据XML文档添加,删除,更新索引。Solr 搜索只需要发送 HTTP,GET请求,然后对Solr返回XML,JSON等格式的查询结果进行解析,组织页面布局。Solr 不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr 的配置和运行情况。
Solr 是基于Lucene开发企业级搜索服务器,实际上就是封装了 Lucene。
Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于 Web-Service的API的接口。用户可以通过 HTTP请求,向搜索服务器提交一定格式的文件,生成索引,也可以通过提供查找请求,并得到返回结果。
Lucene概述
Lucene 是 Apache 下Jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目地是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具,就具本身而言。
ElasticSearch和Solr 比较




总结:
- es基本是开箱即用(解压就可以用),非常简单。Solr安装复杂一些。
- Solr利用Zookeeper 进行分布式管理,而ElasticSearch 自身带有分布式协调管理功能。
- Solr支持更多格式的数据,比如JSON,XML,CSV,而ElasticSearch仅支持json文件格式。
- Solr官方提供的功能更多,而ElasticSearch 本身注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要Kibana友好支撑
- Solr查询快,但更新索引时慢,(即插入数据慢),用于电商查询多的应用。
- ElasticSearch 建立索引快(查询慢),即实时性查询快,用户facebook新浪等搜索
- Solr 是传统搜索应用的有力解决方案,但ElasticSearch 更适用于新兴的实时搜索应用
- Solr比较成熟,有一个更大,更成熟的用户,开发和贡献社区,而ElasticSearch相对开发维护者较少,更新太快,学习使用成本较高。
ElasticSearch 的核心概念
集群,节点,索引,类型,文档,分片,映射
ElasticSearch 是面向文档,关系行数据库和 ElasticSearch客观的对比!一切都是JSON
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
ElasticSearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档行,每个文档中又包含多个字段列。
物理设计:
ElasticSearch 在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移。一个人就是一个集群,默认的集群名称就是 elasticSearch。
逻辑设计:
一个索引类型中,包含多个文档,比如说 文档1,文档2。当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引》类型》文档id,通过这个组合我们就能索引到某个具体的文档,注意:ID不必是整数,实际上它是一个字符串
文档
之前说过ElasticSearch 是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticSearch中,文档有几个重要属性:
- 自我包含,一篇文档同事包含字段和对应的值,也就是同事包含key:value
- 可以是层次型的,一个文档中包含文档,复制的逻辑实体就是这么来的。
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticSearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形,因为elasticSearch 会保存字段和类型之间的映射及其他的设置,这种映射具体到每个映射的每种类型,这也是为什么ElasticSearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如 name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么ElasticSearch 是怎么做的呢?elasticSearch 会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticSearch 就开始猜,如果这个值是18,那么elasticSearch会认为它是整型,但是 elasticSearch 也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引
索引是映射类型的容器,ElasticSearch中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置。然后它们被存储到各个分片上了。我们来研究一下分片是如何工作的。
物理设计:节点和分片如何工作
一个集群至少有一个节点,而一个节点就是一个 elasticsearch 进程,节点可以有多个索引默认的,如果你创建索引,那么索引会有5个分片构成,每个主分片会有一个副本(又称为复制分片)
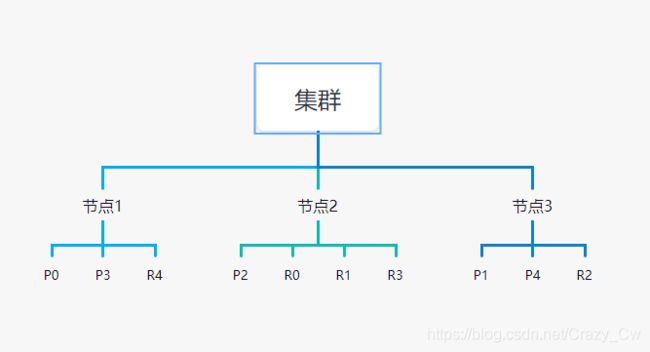
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个 Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch 在不扫描全部文档的情况下,就能告诉你哪些文档含特定的关键字。不过,等等,倒排索引是什么意思呢?
倒排索引
elasticsearch 使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层。这种结构使用于快速的全文索引,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表,例如,现在有两个文档,每个文档包含如下内容:
study every day, good good up to forever # 文档1包含的内容
To forever, study every day,good good up # 文档2包含的内容
为了倒排索引,我们首先要将每个文档拆分独立的词(或称为词条或者tonkens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
| term | doc_1 | doc_2 |
|---|---|---|
| Study | √ | × |
| To | × | × |
| every | √ | √ |
| forever | √ | √ |
| day | √ | √ |
| study | × | √ |
| good | √ | √ |
| every | √ | √ |
| to | √ | × |
| up | √ | √ |
现在我们搜索 to forever,只需要查看包含每个词条的文档
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
两个文档都匹配,但是第一个文档比第二个文档匹配程度更高,如果没有别的条件,现在,这两个包含关键字的文档都返回。
再看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:

如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多,只需要查看标签这一栏,然后获取相关的文章 ID即可。
elasticsearch的索引,和Lucene的索引对比。
在elasticsearch 中,索引这个词被频繁使用,这就是术语的使用。在elasticsearch 中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch 索引是由多个Lucene索引 组成的,别问为什么,谁让elasticsearch 使用lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。