计算机组成原理3--<存储体系>
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、存储器的分类
- 二、存储器的层次结构
-
- 1.主存储器
- 总结
一、存储器的分类
按存储介质分类:半导体存储器,磁存储器,纸带存储器,光存储器等
按照存取方式分类:
随机读写存储器(RAM)
是与CPU直接交换数据的内部存储器,也叫主存(内存)。它可以随时读写,而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储媒介。当电源关闭时RAM不能保留数据(掉电数据消失哦)如果需要保存数据,就必须把它们写入一个长期的存储设备中(例如硬盘)。
只读存储器(ROM)
ROM又被称为“只读存储器”,ROM所存数据,一般是装入整机前事先写好的,整机工作过程中只能读出,而不像随机存储器那样能快速地、方便地加以改写。ROM所存数据稳定,断电后所存数据也不会改变。
相连存储器、顺序存储器,直接存取存储器
二、存储器的层次结构

1.主存储器
 存储体由若跟个存储单元组成,存储单元由多个存储元件组成
存储体由若跟个存储单元组成,存储单元由多个存储元件组成
存储体----存储单元(存储一串二进制串)----存储元件(存储一个0/1)
存储单元:存放一串二进制代码。
存储字:存储单元中的二进制代码
存储字长:存储单元中二进制代码位数。
存储单元按照地址进行寻址
MAR:存储器地址寄存器,反应存储单元个数。保存了存储体的地址(存储单元的编号),反应了存储单元的个数。所以MAR的位数和存储单元的个数有关。
MDR:存储器数据寄存器,反应存储字长(存储单元长度)。保存了要送入CPU中的数据或要保存到存储体中的数据或者刚刚从存储体中取出来来的数据。这个寄存器的长度和存储单元的长度相同。
主存中存储单元的地址分配
1、高位字节地址为字地址(大端大尾)
2、低位字节地址为字地址(小端小尾)
半导体存储芯片基本结构
 容量计算
容量计算
| 地址线(单项) | 数据线(双向) | 芯片容量 |
|---|---|---|
| 10 | 4 | 2^10 * 4 = 1K * 4 |
| 2^10 * 4 = 1K * 4 | 1 | 2^14 * 1 = 16K * 1 |
| 13 | 8 | 2^13 * 1 = 8K * 8 |
存储器速度:存储器的速度一般用存储器的存储时间,存储周期,和存储器的带宽来衡量
1、取数时间tA:存储器接到命令到其数据输出端有信号输出为止的时间,取决于存储介质和访问机构的类型
2、存储周期tc:存储器进行一次完整的读/写操作所需要的时间,也就是连续两次访问存储器所需要的最小时间间隔
很显然tc>ta.
3、存储带宽,单位时间内可以写入存储器或取出信息的最大数量
DRAM的刷新操作
定时刷新的原因:由于存储单元的访问是随机的,有可能某些存储单元长期得不到访问,不进行存储器的读/写操作,其存储单元内的原信息将会慢慢消失,为此,必须采用定时刷新的方法,它规定在一定的时间内,对动态RAM的全部基本单元电路必作一次刷新,一般取2ms,即刷新周期(再生周期)。
例:
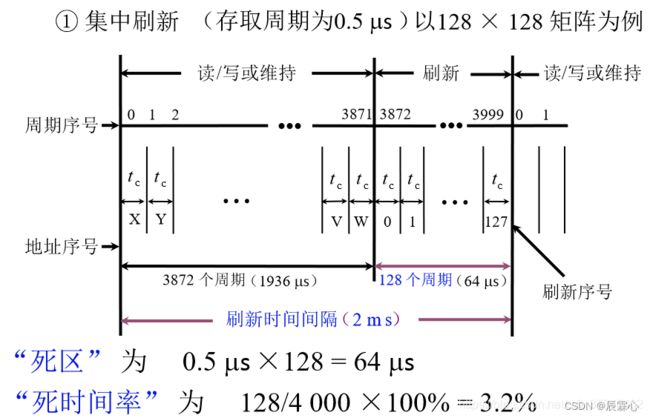
①刷新周期为2ms
②存取周期为0.5μs,即刷新1行的时间为0.5μs(刷新时间是等于存取周期的。因为刷新的过程与一次存取相同,只是没有在总线上输入输出。存取周期>真正用于存取的时间,因为存取周期内、存取操作结束后仍然需要一些时间来更改状态。对于SRAM也是这样,对于DRAM更是如此)。
③对128×128的矩阵的存储芯片进行刷新,按存储单元(1B/单元)分为128行128列,即128×128×1B/单元=2^14个单元×1B/单元 = 16KB内存。 (如果是64×64的矩阵,则为64×64×1B/单元=2^12个单元×1B/单元 = 4KB内存)
集中刷新:集中刷新是在规定的一个刷新周期内,对全部存储单元集中一段时间逐行进行刷新,此刻必须停止读/写操作。
用0.5μs*128=64μs的时间对128行进行逐行刷新,由于这64μs的时间不能进行读/写操作,故称为“死时间”或访存“死区”。
由于存取周期为0.5μs,刷新周期为2ms,即4000个存取周期。
补充一点:为什么刷新与存取不能并行?
因为内存就一套地址译码和片选装置,刷新与存取有相似的过程,它要选中一行——这期间片选线、地址线、地址译码器全被占用着。同理,刷新操作之间也不能并行——意味着一次只能刷一行。
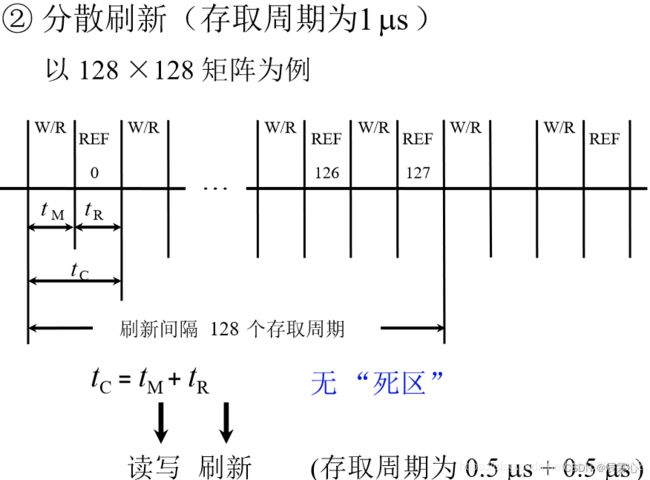
 分散刷新:分散刷新是指对每行存储单元的刷新分散到每个存取周期内完成。其中,把机器的存取周期tc分成两段,前半段tM用来读/写或维持信息,后半段tR用来刷新。
分散刷新:分散刷新是指对每行存储单元的刷新分散到每个存取周期内完成。其中,把机器的存取周期tc分成两段,前半段tM用来读/写或维持信息,后半段tR用来刷新。
即在每个存取操作后绑定一个刷新操作。延长了存取周期,这样存取周期就成了0.5μs + 0.5μs =1μs。但是由于与存取操作绑定,就不需要专门给出一段时间来刷新了。这样,每有128个读取操作,就会把0-127行全部刷新一遍。故每隔128μs 就可将存储芯片全部刷新一遍,即刷新周期是1μs×128=128μs远短于2ms,而且不存在停止读/写的死时间,但是存取周期长了,整个系统速度降低了。
异步刷新:可以缩短“死时间”,又充分利用最大刷新间隔为2ms的特点,具体操作为:在2ms内对128行各刷新一遍
即每隔15.6μs刷新一行(2000μs/128≈15.6μs),而每行刷新的时间仍为0.5μs。这样,刷新一行只能停止一个存取周期,但对每行来说,刷新间隔时间仍为2ms,而死时间为0.5μs。(相对每一段来说,是集中式刷新,相对整体来说,是分散式刷新)
如果将DRAM的刷新安排在CPU对指令的译码阶段,由于这个阶段CPU不访问存储器,所以这种方案既克服了分散刷新需独占0.5μs用于刷新,使存取周期加长且降低系统速度的缺点,又不会出现集中刷新的访存“死区”问题,从根本上上提高了整机的工作效率

存储器的字扩展和位扩展
位扩展
例:1K ✖ 4位 存储芯片组成 1K ✖ 8位 的存储器


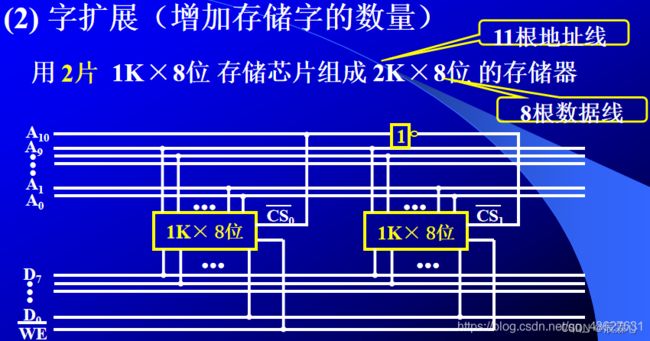
字扩展
1K ✖ 8位 存储芯片组成 2K ✖ 8位 的存储器
z
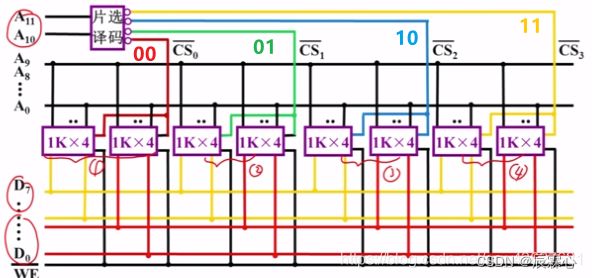
字位扩展:
例:1K ✖ 8位 存储芯片组成 2K ✖ 8位 的存储器
高速缓冲存储器:
我们都知道CPU处理数据的速度非常快,虽然内存的读写速度也不慢,但是相对于CPU它的速度就显得太慢了,所以如果单纯地让CPU对内存进行读写,所消耗的时间绝大部分是在内存对数据的处理上,而这时候CPU就在空等,浪费了资源,因此就需要在CPU与内存之间连接一个Cache来作为缓冲。
程序运行的局部性原理:
时间局部性是指当CPU处理了一个数据以后它很有可能会对它进行第二次处理。
空间局部性是指CPU处理了内存中某一块的数据,它很可能会还对它附近的数据块进行读写操作。
Cache的工作过程:
CPU发出一个地址,同时发给主存和cache的地址映射机构,CPU会从主存中取出字还是从cache中取出字,主存将块号送入主存cache地址变换机构,如果命中,就将主存地址转化为cache地址,从cache存储体中找到对应的字,然后通过数据总线送到CPU,完成一次读写过程;如果没有命中,这个字就不能从cache中取,而应该从主存中取出字送给CPU,与此同时,如果cache中有空间,可以装进,就将这个字所在的块拿到cache中。如果空间不够,不能装进cache,cache替换机构就将cache中不常用的块拿出,将该字的块替换进cache中。

多体交叉存储器:

多模块串行(局部性原理)、相邻地址的数据处于同一存储体、共一个地址寄存器、性能无提升、扩充容量方便

多模块并行(局部性 原理)、相邻地址处于不同存储体中、每个存储体均需要地址寄存器、性能提升、扩充容量方便
主存与cache的映射过程:
1.全相联映射(灵活性大的映象关系)
主存中的任一块映象到缓存中的任一块,将主存中一个块的地址(块号)与块的内容(字)一起存与cache的行中,其中块地址存与cache行的标记部分。cache的数据块大小称为行,主存的数据块大小称为块。cache与主存之间的数据交换以块为单位,CPU与cache之间的数据交换以字为单位。
优点:灵活,命中率高
缺点:主存字块标记为全部块标记,访问cache时,主存的字块标记要和cache的全部标记位进行比较,所需的逻辑电路很多,成本较高,实际的cache还要采用各种措施来减少地址的比较次数。

.直接映射(固定的方式):
主存中的任意块映射到缓存中的唯一块,每个主存块只与一个缓存块相对应。
i为缓存块号,j为主存块号,C为缓存块数,映射关系式:i = j mod C特点:不灵活,每个主存块只能与固定对应某个缓存块,即使还空着许多位置也不能使用。
主存地址的格式:


组相联映射(上述两种映象的折中)
组间直接映射,组内全相联映射
主存块j按模Q(组数)映射到缓存的第i组中任一块,cache分为Q组,每组R块
对应关系有:i = j mod Q
i为缓存的组号,j为主存的块号
组内n块,组相联映射定义为n路组相联


替换算法:
1、随机算法(RAND):随机地确定替换的Cache块。它的实现比较简单,但没有依据程序访问的局部性原理,故可能命中率较低。
2、先进先出算法(FIFO):选择最早调入的行进行替换。它比较容易实现,但也没有依据程序访问的局部性原理,可能会把一些需要经常使用的程序块(如循环程序)也作为最早进入Cache的块替换掉。
3、近期最少使用算法(LRU):依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,平均命中率要比FIFO要高,是堆栈类算法。LRU算法对每行设置一个计数器,Cache每命中一次,命中行计数器清0,而其他各行计数器均加1,需要替换时比较各特定行的计数值,将计数值最大的行换出。
4、最不经常使用算法(LFU):将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从0开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。
虚拟存储器:
在程序运行时,则分配给每个程序一定的运行空间,由地址转换部件(硬件或软件)将编程时的地址转换成实际内存的物理地址。如果分配的内存不够,则只调入当前正在运行的或将要运行的程序块(或数据块),其余部分暂时驻留在辅存中。一个大作业在执行时,其一部分地址空间在主存,另一部分在辅存,当所访问的信息不在主存时,则由操作系统而不是程序员来安排I/O指令,把信息从辅存调入主存。从效果上来看,好像为用户提供了一个存储容量比实际主存大得多的存储器,用户无需考虑所编程序在主存中是否放得下或放在什么位置等问题。称这种存储器为虚拟存储器.
用户编制程序时使用的地址(虚拟地址由编译程序生成)称为虚地址或逻辑地址,其对应的存储空间称为虚存空间或逻辑地址空间;而计算机物理内存的访问地址则称为实地址或物理地址,其对应的存储空间称为物理存储空间或主存空间。程序进行虚地址到实地址转换的过程称为程序的再定位。

总结
http://t.csdn.cn/L1Z3Q
http://t.csdn.cn/NbQ0y
http://t.csdn.cn/dh7AB
http://t.csdn.cn/e7PPv