数据湖 | Apache Hudi 设计与架构最强解读
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源


大数据技术与架构
点击右侧关注,大数据开发领域最强公众号!


大数据真好玩
点击右侧关注,大数据真好玩!

本文将介绍Apache Hudi的基本概念、设计以及总体基础架构。
1. 简介
Apache Hudi(简称:Hudi)允许您在现有的hadoop兼容存储之上存储大量数据,同时提供两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。
这两种原语分别是:
1)Update/Delete记录:Hudi使用细粒度的文件/记录级别索引来支持Update/Delete记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
2)变更流:Hudi对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已updated/inserted/deleted的所有记录的增量流,并解锁新的查询姿势(类别)。

这些原语紧密结合,解锁了基于DFS抽象的流/增量处理能力。如果您熟悉流处理,那么这和从kafka主题消费事件,然后使用状态存储逐步累加中间结果类似。
在架构上会有以下几点优势:
1)效率的提升:摄取数据通常需要处理更新、删除以及强制唯一键约束。然而,由于缺乏像Hudi这样能对这些功能提供标准支持的系统,数据工程师们通常会采用大批量的作业来重新处理一整天的事件,或者每次运行都重新加载整个上游数据库,从而导致大量的计算资源浪费。由于Hudi支持记录级更新,它通过只处理有变更的记录并且只重写表中已更新/删除的部分,而不是重写整个表分区甚至整个表,为这些操作带来一个数量级的性能提升。
2)更快的ETL/派生Pipelines:从外部系统摄入数据后,下一步需要使用Apache Spark/Apache Hive或者任何其他数据处理框架来ETL这些数据用于诸如数据仓库、机器学习或者仅仅是数据分析等一些应用场景。通常,这些处理再次依赖以代码或SQL表示的批处理作业,这些作业将批量处理所有输入数据并重新计算所有输出结果。通过使用增量查询而不是快照查询来查询一个或多个输入表,可以大大加速此类数据管道,从而再次导致像上面一样仅处理来自上游表的增量更改,然后upsert或者delete目标派生表。
3)获取新鲜数据:减少资源还能获取性能上的提升并不是常见的事。毕竟我们通常会使用更多的资源(例如内存)来提升性能(例如查询延迟)。通过从根本上摆脱数据集的传统管理方式,Hudi将批量处理增量化的一个很好的副作用是:与以前的数据湖相比,pipeline运行的时间会更短,数据交付会更快。
4)统一存储:基于以上三个优点,在现有数据湖之上进行更快速、更轻量的处理意味着仅出于访问近实时数据的目的时不再需要专门的存储或数据集市。
2. 设计原则
2.1 流式读/写
Hudi是从零设计的,用于从大型数据集输入和输出数据,并借鉴了数据库设计的原理。为此,Hudi提供了索引实现,可以将记录的键快速映射到其所在的文件位置。同样,对于流式输出数据,Hudi通过其特殊列添加并跟踪记录级别的元数据,从而可以提供所有发生变更的精确增量流。
2.2 自管理
Hudi注意到用户可能对数据新鲜度(写友好)与查询性能(读/查询友好)有不同的期望,并支持了三种查询类型,这些类型提供实时快照,增量流以及稍早的纯列数据。在每一步,Hudi都努力做到自我管理(例如自动优化编写程序的并行性,保持文件大小)和自我修复(例如:自动回滚失败的提交),即使这样做会稍微增加运行时成本(例如:在内存中缓存输入数据已分析工作负载)。如果没有这些内置的操作杠杆/自我管理功能,这些大型流水线的运营成本通常会翻倍。
2.3 万物皆日志:
Hudi还具有 append only、云数据友好的设计,该设计使Hudi无缝管理所有云提供商伤的数据,并实现了日志结构化存储系统的原理。
2.4 键-值数据模型
在写方面,Hudi表被建模为键值对数据集,其中每条记录都有一个唯一的记录键。此外,一个记录键还可以包括分区路径,在该路径下,可以对记录进行分区和存储。这通常有助于减少索引查询的搜索空间。
3. 表设计
了解了Hudi项目的关键技术动机后,现在让我们更深入地研究Hudi系统本身的设计。在较高的层次上,用于写Hudi表的组件使用了一种受支持的方式嵌入到Apache Spark作业中,它会在支持DFS的存储上生成代表Hudi表的一组文件。然后,在具有一定保证的情况下,诸如Apache Spark、Presto、Apache Hive之类的查询引擎可以查询该表。
Hudi表的三个主要组件:
1)有序的时间轴元数据。类似于数据库事务日志。
2)分层布局的数据文件:实际写入表中的数据。
3)索引(多种实现方式):映射包含指定记录的数据集。
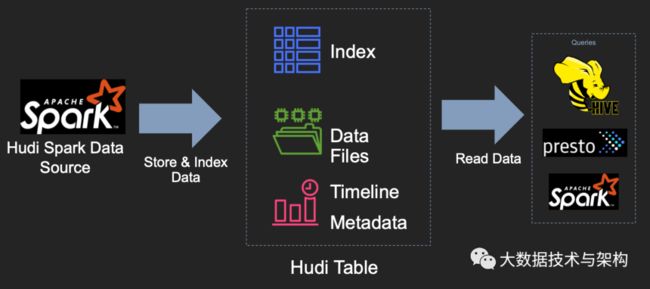
Hudi提供了以下功能来对基础数据进行写入、查询,这使其成为大型数据湖的重要模块:
1)支持快速,可插拔索引的upsert();
2)高效、只扫描新数据的增量查询;
3)原子性的数据发布和回滚,支持恢复的Savepoint;
4)使用mvcc风格设计的读和写快照隔离;
5)使用统计信息管理文件大小;
6)已有记录update/delta的自管理压缩;
7)审核数据修改的时间轴元数据;
8)满足GDPR(通用数据保护条例)、数据删除功能。
3.1 时间轴
在其核心,Hudi维护了一条包含在不同的即时时间(instant time)对数据集做的所有instant操作的timeline,从而提供表的即时视图,同时还有效的支持按到达顺序进行数据检索。时间轴类似于数据库的redo/transaction日志,由一组时间轴实例组成。Hudi保证在时间轴上执行的操作的原子性和基于即时时间的时间轴一致性。时间轴被实现为表基础路径下.hoodie元数据文件夹下的一组文件。具体来说,最新的instant被保存为单个文件,而较旧的instant被存档到时间轴归档文件夹中,以限制writers和queries列出的文件数量。
一个Hudi 时间轴instant由下面几个组件构成:
1)操作类型:对数据集执行的操作类型;
2)即时时间:即时时间通常是一个时间戳(例如:20190117010349),该时间戳按操作开始时间的顺序单调增加;
3)即时状态:instant的当前状态;
每个instant都有avro或者json格式的元数据信息,详细的描述了该操作的状态以及这个即时时刻instant的状态。
关键的Instant操作类型有:
1)COMMIT:一次提交表示将一组记录原子写入到数据集中;
2)CLEAN: 删除数据集中不再需要的旧文件版本的后台活动;
3)DELTA_COMMIT:将一批记录原子写入到MergeOnRead存储类型的数据集中,其中一些/所有数据都可以只写到增量日志中;
4)COMPACTION: 协调Hudi中差异数据结构的后台活动,例如:将更新从基于行的日志文件变成列格式。在内部,压缩表现为时间轴上的特殊提交;
5)ROLLBACK: 表示提交/增量提交不成功且已回滚,删除在写入过程中产生的所有部分文件;
6)SAVEPOINT: 将某些文件组标记为"已保存",以便清理程序不会将其删除。在发生灾难/数据恢复的情况下,它有助于将数据集还原到时间轴上的某个点;
任何给定的即时都会处于以下状态之一:
1)REQUESTED:表示已调度但尚未初始化;
2)INFLIGHT: 表示当前正在执行该操作;
3)COMPLETED: 表示在时间轴上完成了该操作.
3.2 数据文件
Hudi将表组织成DFS上基本路径下的文件夹结构中。如果表是分区的,则在基本路径下还会有其他的分区,这些分区是包含该分区数据的文件夹,与Hive表非常类似。每个分区均由相对于基本路径的分区路径唯一标识。在每个分区内,文件被组织成文件组,由文件ID唯一标识。每个文件组包含一个或多个文件片,每个文件片都包含一个base file(某个提交/压缩即时时间生成的列式存储文件,例如:parquet文件)以及一组日志文件(包含自生成基本文件以来对基本文件的插入/更新)。Hudi采用了MVCC设计,压缩操作会将日志和基本文件合并以产生新的文件片,而清理操作则将未使用的/较旧的文件片删除以回收DFS上的空间。
3.3 索引
Hudi通过索引机制提供高效的upsert操作,该机制会将一个记录键+分区路径组合一致性的映射到一个文件ID.这个记录键和文件组/文件ID之间的映射自记录被写入文件组开始就不会再改变。简而言之,这个映射文件组包含了一组文件的所有版本。Hudi当前提供了3种索引实现(HBaseIndex,、HoodieBloomIndex(HoodieGlobalBloomIndex)、InMemoryHashIndex)来映射一个记录键到包含该记录的文件ID。这将使我们无需扫描表中的每条记录,就可显著提高upsert速度。
Hudi索引可以根据其查询分区记录的能力进行分类:
1)全局索引:不需要分区信息即可查询记录键映射的文件ID。比如,写程序可以传入null或者任何字符串作为分区路径(partitionPath),但索引仍然会查找到该记录的位置。全局索引在记录键在整张表中保证唯一的情况下非常有用,但是查询的消耗随着表的大小函数式增加。
2)非全局索引:与全局索引不同,非全局索引依赖分区路径(partitionPath),对于给定的记录键,它只会在给定分区路径下查找该记录。这比较适合总是同时生成分区路径和记录键的场景,同时还能享受到更好的扩展性,因为查询索引的消耗只与写入到该分区下数据集有关系。
4.1 写时复制(CopyOnWrite)表
COW表写的时候数据直接写入basefile,(parquet)不写log文件。所以COW表的文件片只包含basefile(一个parquet文件构成一个文件片)。
这种的存储方式的Spark DAG相对简单。关键目标是是使用partitioner将tagged Hudi记录RDD(所谓的tagged是指已经通过索引查询,标记每条输入记录在表中的位置)分成一些列的updates和inserts.为了维护文件大小,我们先对输入进行采样,获得一个工作负载profile,这个profile记录了输入记录的insert和update、以及在分区中的分布等信息。把数据重新打包:
1)对于updates, 该文件ID的最新版本都将被重写一次,并对所有已更改的记录使用新值;
2)对于inserts.记录首先打包到每个分区路径中的最小文件中,直到达到配置的最大大小。之后的所有剩余记录将再次打包到新的文件组,新的文件组也会满足最大文件大小要求。

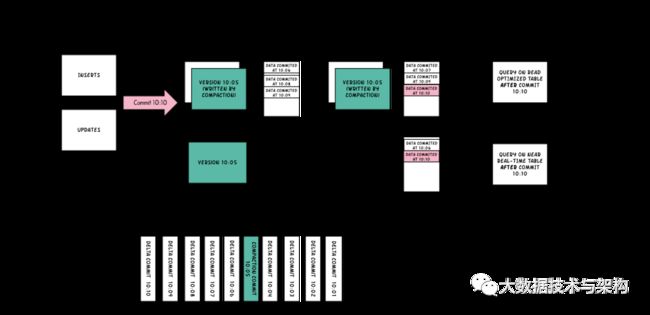
4.2 读时合并(MergeOnRead)表
MOR表写数据时,记录首先会被快速的写进日志文件,稍后会使用时间轴上的压缩操作将其与基础文件合并。根据查询是读取日志中的合并快照流还是变更流,还是仅读取未合并的基础文件,MOR表支持多种查询类型。
在高层次上,MOR writer在读取数据时会经历与COW writer 相同的阶段。这些更新将追加到最新文件篇的最新日志文件中,而不会合并。对于insert,Hudi支持两种模式:
1)插入到日志文件:有可索引日志文件的表会执行此操作(HBase索引);
2)插入parquet文件:没有索引文件的表(例如布隆索引)
与写时复制(COW)一样,对已标记位置的输入记录进行分区,以便将所有发往相同文件id的upserts分到一组。这批upsert会作为一个或多个日志块写入日志文件。Hudi允许客户端控制日志文件大小。对于写时复制(COW)和读时合并(MOR)writer来说,Hudi的WriteClient是相同的。几轮数据的写入将会累积一个或多个日志文件。这些日志文件与基本的parquet文件(如有)一起构成一个文件片,而这个文件片代表该文件的一个完整版本。
这种表是用途最广、最高级的表。为写(可以指定不同的压缩策略,吸收突发写流量)和查询(例如权衡数据的新鲜度和查询性能)提供了很大的灵活性。同时它包含一个学习曲线,以便在操作上掌控他。

5. 写设计
5.1 写
了解Hudi数据源或者deltastreamer工具提供的3种不同写操作以及如何最好的利用他们可能会有所帮助。这些操作可以在对数据集发出的每个commit/delta commit中进行选择/更改。
1)upsert操作:这是默认操作,在该操作中,首先通过查询索引将数据记录标记为插入或更新,然后再运行试探法确定如何最好地将他们打包到存储,以对文件大小进行优化,最终将记录写入。对于诸如数据库更改捕获之类的用例,建议在输入几乎肯定包含更新的情况下使用此操作。
2)insert操作:与upsert相比,insert操作也会运行试探法确定打包方式,优化文件大小,但会完全跳过索引查询。因此对于诸如日志重复数据删除(结合下面提到的过滤重复项选项)的用例而言,它比upsert的速度快得多。这也适用于数据集可以容忍重复项,但只需要Hudi具有事务性写/增量拉取/存储管理功能的用例。
3)bulk insert操作:upsert 和insert操作都会将输入记录保留在内存中,以贾逵爱存储启发式计算速度,因此对于最初加载/引导Hudi数据集的用例而言可能会很麻烦。Bulk insert提供了与insert相同的语义,同时实现了基于排序的数据写入算法,该算法可以很好的扩展数百TB的初始负载。但是这只是在调整文件大小方面进行的最大努力,而不是像insert/update那样保证文件大小。
5.2 压缩
压缩是一个 instant操作,它将一组文件片作为输入,将每个文件切片中的所有日志文件与其basefile文件(parquet文件)合并,以生成新的压缩文件片,并写为时间轴上的一个commit。压缩仅适用于读时合并(MOR)表类型,并且由压缩策略(默认选择具有最大未压缩日志的文件片)决定选择要进行压缩的文件片。这个压缩策略会在每个写操作之后评估。
从高层次上讲,压缩有两种方式:
1)同步压缩:这里的压缩由写程序进程本身在每次写入之后同步执行的,即直到压缩完成后才能开始下一个写操作。就操作而言,这个是最简单的,因为无需安排单独的压缩过程,但保证的数据新鲜度最低。不过,如果可以在每次写操作中压缩最新的表分区,同时又能延迟迟到/较旧分区的压缩,这种方式仍然非常有用。
2)异步压缩:使用这种方式,压缩过程可以与表的写操作同时异步运行。这样具有明显的好处,即压缩不会阻塞下一批数据写入,从而产生近实时的数据新鲜度。Hudi DeltaStreamer之类的工具支持边界的连续模式,其中的压缩和写入操作就是以这种方式在单个Spark运行时集群中进行的。
5.3 清理
清理是一项基本的即时操作,其执行的目的时删除旧的文件片,并限制表占用的存储空间。清理会在每次写操作之后自动执行,并利用时间轴服务器上缓存的时间轴元数据来避免扫描整个表来评估清理时机。
Hudi支持两种清理方式:
1)按commits / deltacommits清理:这是增量查询中最常见且必须使用的模式。以这种方式,Cleaner会保留最近N次commit/delta commit提交中写入的所有文件切片,从而有效提供在任何即时范围内进行增量查询的能力。尽管这对于增量查询很有帮助,但由于保留了配置范围内所有版本的文件片,因此,在某些高写入负载的场景下可能需要更大的存储空间。
2)按保留的文件片清理:这是一种更为简单的清理方式,这里我们仅保存每个文件组中的最后N个文件片。诸如Apache Hive之类的某些查询引擎会处理非常大的查询,这些查询可能需要几个小时才能完成,在这种情况下,将N设置为足够大以至于不会删除查询仍然可以访问的文件片是很有用的。
此外,清理操作会保证每个文件组下面会一直只有一个文件片(最新的一片)。
5.4 DFS访问优化
Hudi还对表中存储的数据执行了几种秘钥存储管理功能。在DFS上存储数据的关键是管理文件大小和技术以及回收存储空间。例如,HDFS在处理小文件问题上臭名昭著--在NameNode上施加内存/RPC压力,可能破坏整个集群的稳定性。通常,查询引擎可在适当大小的列文件上提供更好的性能,因为它们可以有效地摊销获取列统计信息等的成本。即使在某些云数据存储上,列出包含大量小文件的目录也会产生成本。
下面是一些Hudi高效写,管理数据存储的方法:
1)小文件处理特性会剖析输入的工作负载,并将内容分配到现有的文件组,而不是创建新文件组(这会导致生成小文件)。
2)在writer中使用一个时间轴缓存,这样只要Spark集群不每次都重启,后续的写操作就不需要列出DFS目录来获取指定分区路径下的文件片列表。
3)用户还可以调整基本文件和日志文件大小之间的比值系数以及期望的压缩率,以便将足够数量的insert分到统一文件组,从而生成大小合适的基本文件。
4)智能调整bulk insert并行度,可以再次调整大小合适的初始文件组。实际上,正确执行此操作非常关键,因为文件组一旦创建就不能被删除,而智能如前面所述对其进行扩展。
6. 查询
鉴于这种灵活而全面的数据布局和丰富的时间线,Hudi能够支持三种不同的查询表方式,具体取决于表的类型。


6.1 快照查询
可查看给定delta commit或者commit即时操作后表的最新快照。在读时合并(MOR)表的情况下,它通过即时合并最新文件片的基本文件和增量文件来提供近实时表(几分钟)。对于写时复制(COW),它可以替代现有的parquet表(或相同基本文件类型的表),同时提供upsert/delete和其他写入方面的功能。
6.2 增量查询
可查看自给定commit/delta commit即时操作以来新写入的数据。有效的提供变更流来启用增量数据管道。
6.3 读优化查询
可查看给定的commit/compact即时操作的表的最新快照。仅将最新文件片的基本/列文件暴露给查询,并保证与非Hudi表相同的列查询性能。



版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。
编辑|冷眼丶
微信公众号|import_bigdata
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧! ????