spring源码系列-beanDefinition(子路,字节跳动Java社招
前提:假设在你的项目或者磁盘上有X和Y两个类,X是被加了spring注解的,Y没有加spring的注解;也就是正常情况下当spring容器启动之后通过getBean(X)能正常返回X的bean,但是如果getBean(Y)则会出异常,因为Y不能被spring容器扫描到不能被正常实例化;
①[^1]当spring容器启动的时候会去调用ConfigurationClassPostProcessor这个bean工厂的后置处理器完成扫描,关于什么是bean工厂的后置处理器下文再来详细解释;spring完成扫描的具体源码放到后续的文章中再来说。阅读本文读者只需知道扫描具体干了什么事情即可;其实所谓的spring扫描就是把类的信息读取到,但是读取到类的信息存放到哪里呢?比如类的类型(class),比如类的名字,类的构造方法。可能有读者会有疑问这些信息不需要存啊,直接存在class对象里面不就可以?比如当spring扫描到X的时候Class clazzx = X.class;那么这个classx里面就已经具备的前面说的那些信息了,确实如此,但是spring实例化一个bean不仅仅只需要这些信息,还有我上文说到的scope,lazy,dependsOn等等信息需要存储,所以spring设计了一个BeanDefintion的类用来存储这些信息。故而当spring读取到类的信息之后②[2]会实例化一个BeanDefinition的对象,继而调用这个对象的各种set方法存储信息;每扫描到一个符合规则的类,spring都会实例化一个BeanDefinition对象,然后把根据类的类名生成一个bean的名字(比如一个类IndexService,spring会根据类名IndexService生成一个bean的名字`indexService`,spring内部有一套默认的名字生成规则,但是程序员可以提供自己的名字生成器覆盖spring内置的,这个后面更新),`③`[3]继而spring会把这个beanDefinition对象和生成的beanName放到一个map当中,key=beanName,value=beanDefinition对象;至此上图的第①②③步完成。
这里需要说明的是spring启动的时候会做很多工作,不仅仅是完成扫描,在扫描之前spring还干了其他大量事情;比如实例化beanFacctory、比如实例化类扫描器等等,这里不讨论,在以后的文章再来讨论
用一段代码和结果来证明上面的理论
Appconfig.java
@ComponentScan("com.enjoy.beanDefinition")
@Configuration
public class Appconfig {
}
X.java
@Component
public class X {
public X(){
System.out.println("X Constructor");
}
}
Y.java
public class Y {
}
Test.java
public class Test{
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(Appconfig.class);
ac.refresh();
}
}
上述代码里面有X和Y两个类(下面有笔者运行这些代码的结果截图),X被注解了,Y没注解,并且在X当中有个构造方法一旦X被实例化便会打印"X Constructor";而且在main方法的最开始打印了"start"按照上面笔者的理论spring首先会扫描X继而把X解析称为一个beanDefinition对象放到map;笔者在spring的源码org.springframework.context.support.AbstractApplicationContext#invokeBeanFactoryPostProcessors方法上打了一个断点(invokeBeanFactoryPostProcessors方法里面就完成了上述所说的扫描解析功能),当应用程序启动的时候首先会打印start,继而启动spring容器,然后调用invokeBeanFactoryPostProcessors方法,在没有执行该方法之前查看beanDefintionMap当中并没有key为"x"的元素,说明X并没有被扫描,然后继续执行,当执行完invokeBeanFactoryPostProcessors方法时候再次查看beanDefintionMap可以看到map当中多了一个key为"x"的元素,其对应的value就是一个beanDefintion的对象,最后查看后台发现还没有打印"X Constructor"这说明这个时候X并没有被实例化,这个例子说明spring是先把类扫描出来解析称为一个beanDefintion对象,然后put到beanDefintionMap后面才会去实例化X,至于这个beanDefintionMap后面的文章我会详细讲解,本文读者只需知道他是一个专门来存放beanDefinition的集合即可
④当spring把类所对应的beanDefintion对象存到map之后,spring会调用程序员提供的bean工厂后置处理器。什么叫bean工厂后置处理器?在spring的代码级别是用一个接口来表示BeanFactoryPostProcessor,只要实现这个接口便是一个bean工厂后置处理器了,BeanFactoryPostProcessor的详细源码解析后面文章再来分析,这里先说一下他的基本作用。BeanFactoryPostProcessor接口在spring内部也有实现,比如第①步当中完成扫描功能的类ConfigurationClassPostProcessor便是一个spring自己实现的bean工厂后置处理器,这个类笔者认为是阅读spring源码当中最重要的类,没有之一;他完成的功能太多了,以后我们一一分析,先看一下这个类的类结构图。
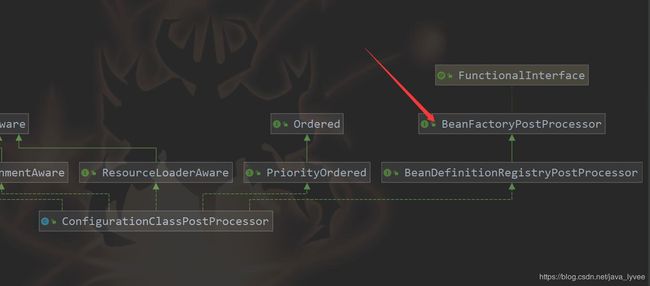
ConfigurationClassPostProcessor实现了很多接口,和本文有关的只需关注两个接口BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor;但是由于BeanDefinitionRegistryPostProcessor是继承了BeanFactoryPostProcessor所以读者也可以理解这是一个接口,但是笔者更加建议你理解成两个接口比较合适,因为spring完成上述①②③步的功能就是调用BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法完成的,到了第④步的时候spring是执行BeanFactoryPostProcessor的postProcessBeanFactory方法;这里可能说的有点绕,大概意思spring完成①②③的功能是调用ConfigurationClassPostProcessor的BeanDefinitionRegistryPostProcessor的postProcessBeanDefinitionRegistry方法,到了第④步spring首先会调用ConfigurationClassPostProcessor的BeanFactoryPostProcessor的postProcessBeanFactory的方法,然后在调用程序员提供的BeanFactoryPostProcessor的postProcessBeanFactory方法,所以上图当中第④步我画的是红色虚线,因为第④步可能没有(如果程序员没有提供自己的BeanFactoryPostProcessor;当然这里一定得说明,即使程序员没有提供自己扩展的BeanFactoryPostProcessor,spring也会执行内置的BeanFactoryPostProcessor也就是ConfigurationClassPostProcessor,所以上图画的并不标准,少了一步;即spring执行内置的BeanFactoryPostProcessor;
重点:我们用自己的话总结一下BeanFactoryPostProcessor的执行时机(不管内置的还是程序员提供)————Ⅰ:如果是直接实现BeanFactoryPostProcessor的类是在spring完成扫描类之后(所谓的扫描包括把类变成beanDefinition然后put到map之中),在实例化bean(第⑤步)之前执行;Ⅱ如果是实现BeanDefinitionRegistryPostProcessor接口的类;诚然这种也叫bean工厂后置处理器他的执行时机是在执行直接实现BeanFactoryPostProcessor的类之前,和扫描(上面①②③步)是同期执行;假设你的程序扩展一个功能,需要在这个时期做某个功能则可以实现这个接口;但是笔者至今没有遇到这样的需求,如果以后遇到或者看到再来补上;(说明一下当笔者发表这篇博客有一个读者联系笔者说他看到了一个主流框架就是扩展了BeanDefinitionRegistryPostProcessor类,瞬间笔者如久旱遇甘霖,光棍遇寡妇;遂立马请教;那位读者说mybatis的最新代码里面便是扩展这个类来实现的,笔者记得以前mybatis是扩展没有用到这个接口,后来笔者看了一下最新的mybatis源码确实如那位读者所言,在下一篇笔者分析主流框架如何扩展spring的时候更新)
这里再次啰嗦一下,这一段比较枯燥和晦涩,但是非常重要,如果想做到精读spring源码这一段尤为重要,建议读者多看多理解;
那么第④步当中提到的执行程序员提供的BeanFactoryPostProcessor到底有什么意义呢?程序员提供BeanFactoryPostProcessor的场景在哪里?有哪些主流框架这么干过呢?
首先回答第一个问题,意义在哪里?可以看一下这个接口的方法签名
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory)
throws BeansException;
其实讨论这个方法的意义就是讨论BeanFactoryPostProcessor的作用或者说意义,参考这个方法的一句javadoc
Modify the application context’s internal bean factory after its standard initialization
在应用程序上下文的标准初始化之后修改它的内部bean工厂
再结合这个方法的执行时机和这段javadoc我们可以理解bean工厂的后置处理器(这里只讨论直接实现BeanFactoryPostProcessor的后置处理器,不包括实现BeanDefinitionRegistryPostProcessor的后置处理器)其实是spring提供的一个扩展点(spring提供很多扩展点,学习spring源码的一个非常重要的原因就是要学会这些扩展点,以便对spring做二次开发或者写出优雅的插件),可以让程序员干预bean工厂的初始化过程(重点会考);这句话最重要的几个字是初始化过程,注意不是实例化过程 ;初始化和实例化有很大的区别的,特别是在读spring源码的时候一定要注意这两个名词;翻开spring源码你会发现整个容器初始化过程就是spring各种后置处理器调用过程;而各种后置处理器当中大体分为两种;一种关于实例化的后置处理器一种是关于初始化的后置处理器,这里不是笔者臆想出来的,如果读者熟悉spring的后置处理器体系就可以从spring的后置处理器命名看出来spring对初始化和实例化是有非常大的区分的。
说白了就是——beanFactory怎么new出来的(实例化)BeanFactoryPostProcessor是干预不了的,但是beanFactory new出来之后各种属性的填充或者修改(初始化)是可以通过BeanFactoryPostProcessor来干预;可以看到BeanFactoryPostProcessor里唯一的方法postProcessBeanFactory中唯一的参数就是一个标准的beanFactory对象——ConfigurableListableBeanFactory;既然spring在调用postProcessBeanFactory方法的时候把已经实例化好的beanFactory对象传过来了,那么自然而然我们可以对这个beanFactory肆意妄为了;
虽然肆意妄为听起来很酷,实则很多人会很迷茫;就相当于现在送给了你一辆奥迪A6(笔者的dream car!重点会考)告诉你可以对这辆车肆意妄为,可你如果只是会按按喇叭,那就对不起赠送者的一番美意了;其实你根本不知道可以在午夜开车这辆车去长沙的解放西路转一圈,继而会收货很多意外的“爱情”;笔者举这个例子就是想说当你拿到beanFactory对象的时候不能只会sout,那不叫肆意妄为;我们可以干很多事情,但是你必须要了解beanFactory的特性或者beanFactory的各种api,但是beanFactory这个对象太复杂了,这里不适合展开讨论,与本文相关的只要知道上述我们讲到的那个beanDefintionMap(存储beanDefintion的集合)就定义在beanFactory当中;而且他也提供额api供程序员来操作这个map,比如可以修改这个map当中的beanDefinition对象,也可以添加一个beanDefinition对象到这个map当中;看一段代码
@Component
public class TestBeanFactoryPostPorcessor implements BeanFactoryPostProcessor {
# 总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
**很多人担心学了容易忘,这里教你一个方法,那就是重复学习。**
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
**[CodeChina开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频】](
)**
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
sj8F9OL-1631185743237)]
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。