对标大厂的技术派详细方案设计,带你了解一个项目从0到1实现的全过程
01 整体介绍
背景
这个项目诞生的背景和企业内生的需求不太一样,主要是某一天二哥说,“我们一起搞事吧”, 楼仔问,“搞什么”,然后这个项目的需求就来了
言归正传,我们主要的目的是希望打造一个切实可用的项目,依托于这个项目,将java从业者所用到的技术栈真实的展现出来,对于经验不是那么足的小伙伴,可以在一个真实的系统上,理解到自己学习的知识点是如何落地的,同时也能真实的了解一个项目是从0到1实现的全过程
系统模块介绍
系统架构
基于社区系统的分层特点,将整个系统架构划分为展示层,应用层,服务层,如下图

展示层
其中展示层主要为用户直接接触的视图层,基于用户角色,分别提供为面向普通用户的前台与面向管理员的后台
前台web
-
采用Thymleaf模板引擎进行视图渲染
-
对于不关心前端技术栈的小伙伴相对友好,学习成本低,只用会基本的html,css,js即可
管理后台
-
采用成熟的前后端分离技术方案
-
前端基于react成熟框架搭建
应用层
应用层,也可以称为业务层,强业务相关,其中每个划分出来的模块有较明显的业务边界,虽然在上图中区分了前台、后台
但是需要注意的是,后台也是同样有文章、评论、用户等业务功能的,前台与后台可使用应用主要是权限粒度管理的差异性,对于技术派系统而言,我们的应用可分为:
-
文章
-
专栏
-
评论
-
用户
-
收藏
-
订阅
-
运营
-
审核
-
类目标签
-
统计
服务层
我们将一些通用的、可抽离业务属性的功能模块,沉淀到服务层,作为一个一个的基础服务进行设计,比如计数服务、消息服务等,通常他们最大特点就是独立与业务之外,适用性更广,并不局限在特定的业务领域内,可以作为通用的技术方案存在
在技术派的项目设计中,我们拟定以下基础服务
-
用户权限管理 (auth)
-
消息中心 (mq)
-
计数 (redis)
-
搜索服务 (es)
-
推荐 (recommend)
-
监控运维 (prometheus)
平台资源层
这一层可以理解为更基础的下层支撑
-
服务资源:数据库、redis、es、mq
-
硬件资源:容器,ecs服务器
术语介绍
技术派整个系统中涉及到的术语并不多,也很容易理解,下面针对几个常用的进行说明
-
用户:特指通过微信公众号扫码注册的用户,可以发布文章、阅读文章等
-
管理员:可以登录后台的特殊用户
-
文章:即博文
-
专栏:由一系列相关的文章组成的一个合集
-
订阅:专指关注用户
02 系统模块设计
针对前面技术派的业务架构拆分,技术派的实际项目划分,主要是五个模块,相反并没由将上面的每个应用、服务抽离为独立的模块,主要是为了避免过渡设计,粒度划分太细会增加整个项目的理解维护成本
这里设置五个相对独立的模块,则主要是基于边界特别清晰这一思考点进行,后续做微服务演进时,下面每个模块可以作为独立的微服务存在
用户模块
在技术派中,整个用户模块从功能角度可以分为
-
注册登录
-
权限管理(是的,权限管理也放在这里了)
-
业务逻辑
注册登录
方案设计
注册登录除了常见的用户名+密码的登录方式之外,现在也有流行的手机号+验证,第三方授权登录;我们最终选择微信公众号登录方式(其最主要的目的,相信大家也知道...)
对于个人公众号,很多权限没有;因此这个登录的具体实现,有两种实现策略
-
点击登录,登录页显示二维码 + 输入框 -> 用户关注公众号,输入 "login" 获取登录验证码 -> 在登录界面输入验证码实现登录
-
点击登录,登录页显示二维码 + 验证码 -> 用户关注公众号,将登录页面上的验证码输入到微信公众号 -> 自动登录
其中第一种策略,类似于手机号/验证码的登录方式,主要是根据系统返回的验证码来主动登录
优点:
-
代码实现简单,逻辑清晰
缺点:
-
操作流程复杂,用户需要输入两次
对于第二种策略,如果是企业公众号,是可以省略输入验证码这一步骤的,借助动态二维码来直接实现扫码登录;对于我们这种个人公众号,则需要多来一步,通过输入验证码来将微信公众号的用户与需要登录的用户绑定起来
登录工作流程如下:
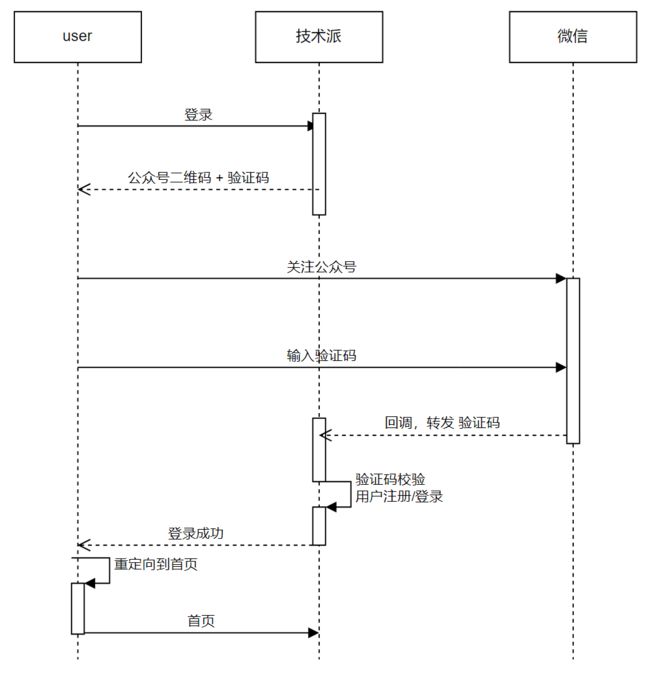
库表设计
基于公众号的登录方式,看一下用户登录表的设计
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`third_account_id` varchar(128) NOT NULL DEFAULT '' COMMENT '第三方用户ID',
`user_name` varchar(64) NOT NULL DEFAULT '' COMMENT '用户名',
`password` varchar(128) NOT NULL DEFAULT '' COMMENT '密码',
`login_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '登录方式: 0-微信登录,1-账号密码登录',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `key_third_account_id` (`third_account_id`),
KEY `key_user_name` (`user_name`),
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户登录表';
注意上面的表结构设计,我们冗余了 user_name, password 用户名密码的登录方式,主要是给管理员登录后台使用
用户首次登录之后,会在user表中插入一条数据,主要关注 third_account_id 这个字段,它记录的是微信开放平台返回的唯一用户id
权限管理
权限管理会分为两块:用户身份识别 + 鉴权
方案设计
用户身份识别:
现在用户的身份识别有非常多的方案,我们现在采用的是最基础、历史最悠久的方案,cookie + session 方式(后续会迭代为分布式session + jwt)
整体流程:
-
用户登录成功,服务器生成sessionId -> userId 映射关系
-
服务器返回sessionId,写到客户端的浏览器cookie
-
后续用户请求,携带cookie
-
服务器从cookie中获取sessionId,然后找到uesrId

服务内部身份传递:
另外一个需要考虑的点则是用户的身份如何在整个系统内传递? 对于一期我们采用的单体架构而言,借助ThreadLocal来实现
-
自定义Filter,实现用户身份识别(即上面的流程,从cookie中拿到SessionId,转userId)
-
定义全局上下文ReqInfoContext:将用户信息,写入全局共享的ThreadLocal中
-
在系统内,需要获取当前用户的地方,直接通过访问 ReqInfoContext上下文获取用户信息
-
请求返回前,销毁上下文中当前登录用户信息
鉴权
根据用户角色与接口权限要求进行判定,我们设计三种权限点类型
-
ADMIN:只有管理员才能访问的接口
-
LOGIN:只有登录了才能访问的接口
-
ALL:默认,没有权限限制
我们在需要权限判定的接口上,添加上对应的权限要求,然后借助AOP来实现权限判断
-
当接口上有权限点要求时(除ALL之外)
-
首先获取用户信息,如果没有登录,则直接报403
-
对于ADMIN限制的接口,要求查看用户角色,必须为admin
库表设计
我们将用户角色信息写入用户基本信息表中,没有单独抽出一个角色表,然后进行映射,主要是因为这个系统逻辑相对清晰,没有太复杂的角色关系,因此采用了轻量级的设计方案
-- pai_coding.user_info definition
CREATE TABLE `user_info` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`user_name` varchar(50) NOT NULL DEFAULT '' COMMENT '用户名',
`photo` varchar(128) NOT NULL DEFAULT '' COMMENT '用户图像',
`position` varchar(50) NOT NULL DEFAULT '' COMMENT '职位',
`company` varchar(50) NOT NULL DEFAULT '' COMMENT '公司',
`profile` varchar(225) NOT NULL DEFAULT '' COMMENT '个人简介',
`user_role` int(4) NOT NULL DEFAULT '0' COMMENT '0 普通用户 1 超管',
`extend` varchar(1024) NOT NULL DEFAULT '' COMMENT '扩展字段',
`ip` json NOT NULL COMMENT '用户的ip信息',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `key_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户个人信息表';
业务逻辑
在业务模块,主要说两块,一个是用户的轨迹,一个是订阅关注
订阅关注
订阅关注这块业务主要是用户可以相互关注,核心点就在于维护用户与用户之间的订阅关系
业务逻辑上没有太复杂的东西,核心就是需要一张表来记录关注与被关注情况
-- pai_coding.user_relation definition
CREATE TABLE `user_relation` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '作者用户ID',
`follow_user_id` int(10) unsigned NOT NULL COMMENT '关注userId的用户id,即粉丝userId',
`follow_state` tinyint(2) unsigned NOT NULL DEFAULT '0' COMMENT '阅读状态: 0-未关注,1-已关注,2-取消关注',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_follow` (`user_id`,`follow_user_id`),
KEY `key_follow_user_id` (`follow_user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户关系表';
用户轨迹
在技术派的整体设计中,我们希望记录用户的阅读历史、关注列表、收藏列表、评价的文章列表,对于这种用户行为轨迹的诉求,我们采用设计一张大宽表的策略,其主要目的在于
-
记录用户的关键动作
-
便于文章的相关计数
接下来看一下表结构设计
-- pai_coding.user_foot definition
CREATE TABLE `user_foot` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`document_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文档ID(文章/评论)',
`document_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '文档类型:1-文章,2-评论',
`document_user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '发布该文档的用户ID',
`collection_stat` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '收藏状态: 0-未收藏,1-已收藏,2-取消收藏',
`read_stat` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '阅读状态: 0-未读,1-已读',
`comment_stat` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '评论状态: 0-未评论,1-已评论,2-删除评论',
`praise_stat` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '点赞状态: 0-未点赞,1-已点赞,2-取消点赞',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_user_doucument` (`user_id`,`document_id`,`document_type`),
KEY `idx_doucument_id` (`document_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='用户足迹表';
我们将用户 + 文章设计唯一键,用来记录用户对自己阅读过的文章的行为,因此可以直接通过这个表获取用户的历史轨迹
同时也可以从文章的角度出发,查看被哪些用户点赞、收藏过
小结
用户模块的核心支撑在上面几块,请重点关注上面的示意图与表结构;当然用户的功能点不止于上面几个,比如基础的个人主页、用户信息等也属于用户模块的业务范畴
文章模块
我们将文章和专栏都放在一起,同样也将类目管理、标签管理等也都放在这个模块中,实际上若文章模块过于庞大,也是可以按照最开始的划分进行继续拆分的;这里放在一起的主要原因在于他们都是围绕基本的文章这一业务属性来的,可以聚合在一起
文章
文章的核心就在于发布、查看
基本的发布流程:
-
用户登录,进入发布页面
-
输入标题、文章
-
选择分类、标签,封面、简介
-
提交文章,进入待审核状态,仅用户可看详情
-
管理员审核通过,所有人可看详情

文章库表设计
考虑到文章的内容通常较大,在很多的业务场景中,我们实际上是不需要文章内容的,如首页、推荐列表等都只需要文章的标题等信息;此外我们也希望对文章做一个版本管理(比如上线之后,再修改则新生成一个版本)
因此我们对文章设计了两张表
-- pai_coding.article definition
CREATE TABLE `article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`article_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '文章类型:1-博文,2-问答',
`title` varchar(120) NOT NULL DEFAULT '' COMMENT '文章标题',
`short_title` varchar(120) NOT NULL DEFAULT '' COMMENT '短标题',
`picture` varchar(128) NOT NULL DEFAULT '' COMMENT '文章头图',
`summary` varchar(300) NOT NULL DEFAULT '' COMMENT '文章摘要',
`category_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '类目ID',
`source` tinyint(4) NOT NULL DEFAULT '1' COMMENT '来源:1-转载,2-原创,3-翻译',
`source_url` varchar(128) NOT NULL DEFAULT '1' COMMENT '原文链接',
`offical_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '官方状态:0-非官方,1-官方',
`topping_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '置顶状态:0-不置顶,1-置顶',
`cream_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '加精状态:0-不加精,1-加精',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态:0-未发布,1-已发布',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_category_id` (`category_id`),
KEY `idx_title` (`title`),
KEY `idx_short_title` (`short_title`)
) ENGINE=InnoDB AUTO_INCREMENT=173 DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
-- pai_coding.article_detail definition
CREATE TABLE `article_detail` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`version` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '版本号',
`content` longtext COMMENT '文章内容',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_article_version` (`article_id`,`version`)
) ENGINE=InnoDB AUTO_INCREMENT=141 DEFAULT CHARSET=utf8mb4 COMMENT='文章详情表';
文章对应的分类,我们要求一个文章只能挂在一个分类下
-- pai_coding.category definition
CREATE TABLE `category` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`category_name` varchar(64) NOT NULL DEFAULT '' COMMENT '类目名称',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态:0-未发布,1-已发布',
`rank` tinyint(4) NOT NULL DEFAULT '0' COMMENT '排序',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COMMENT='类目管理表';
文章对应的标签属性,一个文章可以有多个标签
-- pai_coding.tag definition
CREATE TABLE `tag` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`tag_name` varchar(120) NOT NULL COMMENT '标签名称',
`tag_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '标签类型:1-系统标签,2-自定义标签',
`category_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '类目ID',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态:0-未发布,1-已发布',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_category_id` (`category_id`)
) ENGINE=InnoDB AUTO_INCREMENT=147 DEFAULT CHARSET=utf8mb4 COMMENT='标签管理表';
-- pai_coding.article_tag definition
CREATE TABLE `article_tag` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`tag_id` int(11) NOT NULL DEFAULT '0' COMMENT '标签',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_tag_id` (`tag_id`)
) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8mb4 COMMENT='文章标签映射';
专栏
专栏主要是一系列文章的合集,基于此最简单的设计方案就是加一个专栏表,然后再加一个专栏与文章的映射表
但是需要注意的是专栏中文章的顺序,支持调整
专栏库表设计
专栏表
-- pai_coding.column_info definition
CREATE TABLE `column_info` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '专栏ID',
`column_name` varchar(64) NOT NULL DEFAULT '' COMMENT '专栏名',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '作者id',
`introduction` varchar(256) NOT NULL DEFAULT '' COMMENT '专栏简述',
`cover` varchar(128) NOT NULL DEFAULT '' COMMENT '专栏封面',
`state` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '状态: 0-审核中,1-连载,2-完结',
`publish_time` timestamp NOT NULL DEFAULT '1970-01-02 00:00:00' COMMENT '上线时间',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
`section` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '排序',
`nums` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '专栏预计的更新的文章数',
`type` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '专栏类型 0-免费 1-登录阅读 2-限时免费',
`free_start_time` timestamp NOT NULL DEFAULT '1970-01-02 00:00:00' COMMENT '限时免费开始时间',
`free_end_time` timestamp NOT NULL DEFAULT '1970-01-02 00:00:00' COMMENT '限时免费结束时间',
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COMMENT='专栏';
专栏文章表
-- pai_coding.column_article definition
CREATE TABLE `column_article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`column_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '专栏ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`section` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '章节顺序,越小越靠前',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_column_id` (`column_id`)
) ENGINE=InnoDB AUTO_INCREMENT=25 DEFAULT CHARSET=utf8mb4 COMMENT='专栏文章列表';
点赞收藏
再技术派中,对于文章提供了点赞、收藏、评论三种交互,这里重点看一下点赞与收藏;
点赞与收藏,实际上就是用户与文章之间的操作行为,再前面的user_foot表就已经介绍具体的表结构, 文章的统计计数就是根据这个表数据来的,当前用户与文章的点赞、收藏关系,同样是根据这个表来的
唯一需要注意的点,就是这个数据的插入、更新策略:
-
首次阅读文章时:插入一条数据
-
点赞:若记录存在,则更新状态,之前时点赞的,设置为取消点赞;若记录不存在,则插入一条点赞的记录
-
收藏:同上
评论模块
评论可以是针对文章进行,也可以是针对另外一个评论进行回复,我们将回复也当作是一个评论

评论
我们将评论和回复都当成普通的评论,只是主体不同而已,因此一篇文章的评论列表,我们需要重点关注的就是,如何构建评论与其回复之间的层级关系
对于这种评论与回复的层级关系,可以是建辅助表来处理;也可以是表内的父子关系来处理,这里我们采用第二种策略
-
每个评论记录它的上一级评论id(若只是针对文章的评论,那么上一级评论id = 0)
-
我们通过父子关系,在业务层进行逻辑还原
库表设计
针对上面的策略,核心的评论库表设计如下
-- pai_coding.comment definition
CREATE TABLE `comment` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`content` varchar(300) NOT NULL DEFAULT '' COMMENT '评论内容',
`top_comment_id` int(11) NOT NULL DEFAULT '0' COMMENT '顶级评论ID',
`parent_comment_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '父评论ID',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_article_id` (`article_id`),
KEY `idx_user_id` (`user_id`)
) ENGINE=InnoDB AUTO_INCREMENT=75 DEFAULT CHARSET=utf8mb4 COMMENT='评论表';
注意:
-
为什么再表中需要冗余一个顶级评论id ?
-
主要的目的是简化业务层评论关系还原的复杂性
通过上面的表结构,关系还原的策略:
-
先查出文章的顶级评论(parent_comment_id = 0)
-
接下来就是针对每个顶级评论,查询它下面的所有回复 ( top_comment_id = comment_id)
-
构建顶级评论下的回复父子关系(根据parent_comment_id来构建依赖关系)
-
拓展:如果不存在top_comment_id,那么要实现上面这个还原,要怎么做呢?
评论点赞
技术派中同样支持对评论进行点赞,取消点赞;对于点赞的整体业务逻辑操作,实际上与文章的点赞一致,因此我们直接复用了文章的点赞逻辑,借助 user_foot 来实现的
说明
-
上面这种实现并不是一种优雅的选择,从
user_foot的设计也能看出,它实际上与评论点赞这个业务是有些隔离的 -
采用上面这个方案的主要原因在于,点赞这种属于通用的服务,使用mysql来维系点赞与否以及计数统计,再数据量大了之后,基本上玩不转;后续会介绍如何设计一个通用的点赞服务,以此来替换技术派中当前的点赞实现
-
这种设计思路也经常体现在一个全新项目的设计中,最开始的设计并不会想着一蹴而就,整一个非常完美的系统出来,我们需要的是在最开始搭好基座、方便后续扩展;另外一点就是,如何在当前系统的基础上,最小成本的支持业务需求(相信各位小伙伴在日常工作中,这些事情不会陌生)
消息模块
消息模块主要是记录一些定义的事件,用于同步给用户;我们整体采用Event/Listener的异步方案来进行
在单机应用中,借助Spring Event/Listener机制来实现;在集群中,将借助MQ消息中间件来实现
消息通知
我们主要定义以下五种消息类型
-
评论
-
点赞
-
收藏
-
关注
-
系统消息

当发生方面的行为之后,再相应的地方进行主动埋点,手动发送一个消息事件,然后异步消费事件,生成消息通知
需要注意一点:
-
当用户点赞了一个文章,产生一个点赞消息之后;又取消了点赞,这个消息会怎样?
-
撤销还是依然保留?(技术派中选择的方案是撤销)
库表设计
-- pai_coding.notify_msg definition
CREATE TABLE `notify_msg` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`related_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '关联的主键',
`notify_user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '通知的用户id',
`operate_user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '触发这个通知的用户id',
`msg` varchar(1024) NOT NULL DEFAULT '' COMMENT '消息内容',
`type` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '类型: 0-默认,1-评论,2-回复 3-点赞 4-收藏 5-关注 6-系统',
`state` tinyint(3) unsigned NOT NULL DEFAULT '0' COMMENT '阅读状态: 0-未读,1-已读',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `key_notify_user_id_type_state` (`notify_user_id`,`type`,`state`)
) ENGINE=InnoDB AUTO_INCREMENT=1086 DEFAULT CHARSET=utf8mb4 COMMENT='消息通知列表';
通用模块
关于技术派中的通用模块大致有下面几种,相关的技术方案也比较简单,将配合库表进行简单说明
统计计数
针对文章的阅读计数,没访问一次计数+1, 因此前面的user_foot不能使用(因为未登录的用户是不会生成user_foot记录的)
我们当前设计的一个简单的计数表如下
-- pai_coding.read_count definition
CREATE TABLE `read_count` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`document_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文档ID(文章/评论)',
`document_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '文档类型:1-文章,2-评论',
`cnt` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '访问计数',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_document_id_type` (`document_id`,`document_type`)
) ENGINE=InnoDB AUTO_INCREMENT=75 DEFAULT CHARSET=utf8mb4 COMMENT='计数表';
注意,上面这个计数表中的cnt的更新,使用 cnt = cnt + 1 而不是 cnt = xxx的方案
pv/uv
每天的请求pv/uv计数统计,直接再filter层中记录
-- pai_coding.request_count definition
CREATE TABLE `request_count` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`host` varchar(32) NOT NULL DEFAULT '' COMMENT '机器IP',
`cnt` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '访问计数',
`date` date NOT NULL COMMENT '当前日期',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_unique_id_date` (`date`,`host`)
) ENGINE=InnoDB AUTO_INCREMENT=8708 DEFAULT CHARSET=utf8mb4 COMMENT='请求计数表';
全局字典
统一配置、全局字典相关的,主要是减少代码中的硬编码
-- pai_coding.dict_common definition
CREATE TABLE `dict_common` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`type_code` varchar(100) NOT NULL DEFAULT '' COMMENT '字典类型,sex, status 等',
`dict_code` varchar(100) NOT NULL DEFAULT '' COMMENT '字典类型的值编码',
`dict_desc` varchar(200) NOT NULL DEFAULT '' COMMENT '字典类型的值描述',
`sort_no` int(8) unsigned NOT NULL DEFAULT '0' COMMENT '排序编号',
`remark` varchar(500) DEFAULT '' COMMENT '备注',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_type_code_dict_code` (`type_code`,`dict_code`)
) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8mb4 COMMENT='通用数据字典';
图片上传
文章的图片上传,我们支持服务器本地存储和oss存储,其中dev开发环境,默认是本地存储,即图片传到本地的一个目录下;prod生产环境,会将图片上传到阿里云的oss(其他厂商的oss也没有什么本质区别,都是一个post请求,将文件上传而已)
注意:
-
再具体的实现中,需要自动检测文章中的图片,进行转存,避免直接引入外部的资源,导致失效问题
-
下载外网资源,是否会有安全问题?
-
采用资源类型限制、校验
-
生产环境中不存储资源到本地服务器/或者限制本地存储的文件名
-
-
下载外网资源,转存是否会导致整个文章发布过程很慢?
-
并发转存策略
-
搜索推荐
技术派当前的搜索推荐主要是基于数据库来实现,后续再介绍es相关教程时,会同步引入ES进行替换当前的数据库方案
03 迭代计划
再详细设计这一阶段,一般来说会预估一下整体搞完需要多少人天,鉴于实际情况分几个迭代版本进行,每个版本的主要功能点有哪些;这一块就通过下面几张图简单给大家介绍下,详情推荐查看项目管理流程的内容
关于技术派当前覆盖的功能点如:

开发进度与后期版本迭代计划:

如果感觉本文对你有帮助,点赞关注支持一下,想要了解更多Java后端,大数据,算法领域最新资讯可以关注我公众号【架构师老毕】私信666还可获取更多Java后端,大数据,算法PDF+大厂最新面试题整理+视频精讲