力扣mysql刷题记录
mysql刷题记录
刷题链接https://leetcode.cn/tag/database/problemset/
230220开始更新-
mysql冲!
- mysql刷题记录
- 1699. 两人之间的通话次数
- 1251. 平均售价
- 1571. 仓库经理
- 1445. 苹果和桔子
- 1193. 每月交易 I
- 1633. 各赛事的用户注册率
- 1173. 即时食物配送 I
- 1211. 查询结果的质量和占比
- 175. 组合两个表
- ⭐176. 第二高的薪水(查询第N高的数据)
- ⭐178. 分数排名
- ⭐180. 连续出现的数字
- 181. 超过经理收入的员工
- ⭐182. 查找重复的名字
- ⭐183. 从不订购的客户
- ⭐184. 部门工资最高的员工
- 185. 部门工资前三高的所有员工
- 196. 删除重复的电子邮箱
- 197. 上升的温度
- ⭐⭐262. 行程和用户
- 511. 游戏玩法分析 I
- 512. 游戏玩法分析 II
- 534. 游戏玩法分析 III
- ⭐⭐550. 游戏玩法分析 IV
- ⭐⭐ 569. 员工薪水中位数
- 570. 至少有5名直接下属的经理
- ⭐⭐571. 给定数字的频率查询中位数--对比569题
- 574. 当选者
- 577. 员工奖金
- ⭐578. 查询回答率最高的问题
- ⭐⭐⭐579. 查询员工的累计薪水
- 580. 统计各专业学生人数
- 584. 寻找用户推荐人
- 585. 2016年的投资
- 586. 订单最多的客户
- 595. 大的国家
- 596. 至少5名学生的课
- 597. 好友申请 I:总体通过率
- 601. 体育馆的人流量
- 602. 好友申请 II :谁有最多的好友
- ⭐⭐⭐603. 连续空余座位
- 607. 销售员
- 608. 树节点
- 610. 判断三角形
- 612. 平面上的最近距离
- 613. 直线上的最近距离
- 614. 二级关注者
- 615. 平均工资:部门与公司比较
- ⭐⭐⭐表格格式化问题:行转列 618. 学生地理信息报告
- 1777. 每家商店的产品价格
- 列转行 1435. 制作会话柱状图
- 1795. 每个产品在不同商店的价格
1699. 两人之间的通话次数
题
编写 SQL 语句,查询每一对用户 (person1, person2) 之间的通话次数和通话总时长,其中 person1 < person2 。
该表没有主键,可能存在重复项。
该表包含 from_id 与 to_id 间的一次电话的时长。
from_id != to_id
示例 :
解释:
用户 1 和 2 打过 2 次电话,总时长为 70 (59 + 11)。
用户 1 和 3 打过 1 次电话,总时长为 20。
用户 3 和 4 打过 4 次电话,总时长为 999 (100 + 200 + 200 + 499)。
解
解法一
select
least(from_id, to_id) person1,
greatest(from_id, to_id) person2,
count(1) call_count,--count(1)≈count(*)统计列个数
sum(duration) total_duration
from
Calls
group by
least(from_id, to_id), greatest(from_id, to_id);
--根据最小,最大值相同点去判断
解法二
select
if(from_id<to_id,from_id,to_id) person1,
if(from_id<to_id,to_id,from_id) person2,
count(1) call_count,
sum(duration) total_duration
from
Calls
group by
person1,person2;
知识点:
-
least():一条记录中取几个字段的最小值
greates(): 一条记录中取几个字段的最大值
eg:
SELECT greatest(3,5,1,8,33,99,34,55,67,43) as max;
结果:99 -
if语句语法:
if(条件,如果是,如果不是) -
group by分组匹配,可以多条件
1251. 平均售价
题
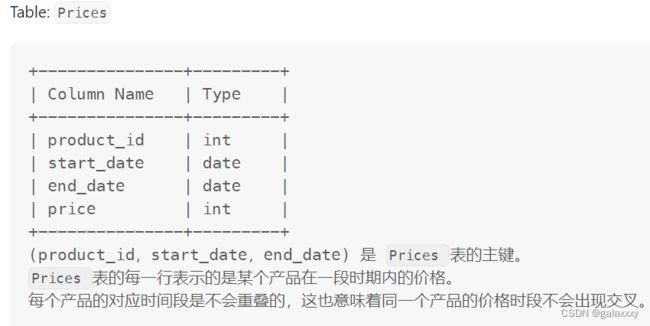

编写SQL查询以查找每种产品的平均售价。
average_price 应该四舍五入到小数点后两位。
units是卖出多少个

解
--每个价格的销售总额为 对应时间内的价格∗对应时间内的数量对应时间内的价格 * 对应时间内的数量对应时间内的价格∗对应时间内的数量。
--因为价格和时间在 Prices 表中,数量在 UnitsSold 表中,这两个表通过 product_id 关联
select
p.product_id,
round(sum(u.units * p.price)/sum(u.units),2) as average_price
from
Prices p inner join UnitsSold u
on
p.product_id=u.product_id
and u.purchase_date between p.start_date and p.end_date
group by p.product_id;-- 先按产品分类
知识点:
- inner join……on显式内连接
- round(~,小数位数):保留n位小数
1571. 仓库经理
题
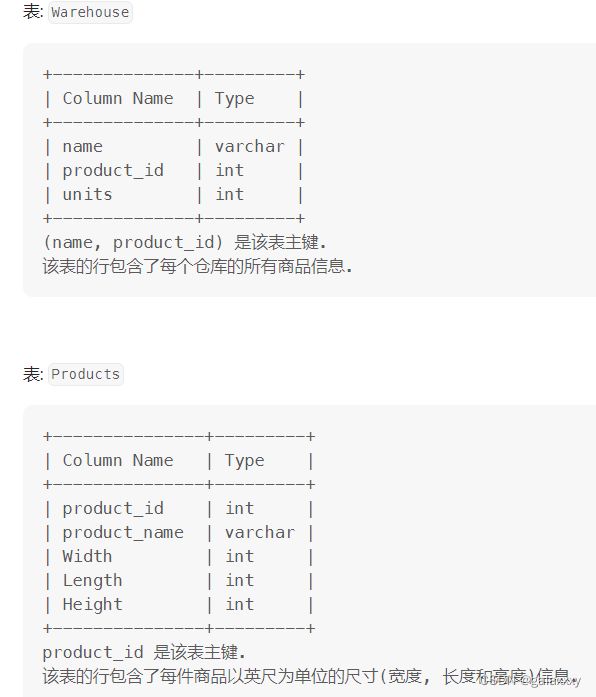
写一个 SQL 查询来报告, 每个仓库的存货量是多少立方英尺.
返回结果没有顺序要求.

解释:
Id为1的商品(LC-TV)的存货量为 5x50x40 = 10000
Id为2的商品(LC-KeyChain)的存货量为 5x5x5 = 125
Id为3的商品(LC-Phone)的存货量为 2x10x10 = 200
Id为4的商品(LC-T-Shirt)的存货量为 4x10x20 = 800
仓库LCHouse1: 1个单位的LC-TV + 10个单位的LC-KeyChain + 5个单位的LC-Phone.
总存货量为: 110000 + 10125 + 5200 = 12250 立方英尺
仓库LCHouse2: 2个单位的LC-TV + 2个单位的LC-KeyChain.
总存货量为: 210000 + 2125 = 20250 立方英尺
仓库LCHouse3: 1个单位的LC-T-Shirt.
总存货量为: 1800 = 800 立方英尺.
解
-- 第一个自己写出来的sql题!
--先分组,再按分组计算体积*数量
select
w.name WAREHOUSE_NAME,
sum(p.Width*p.Length*p.Height*w.units) VOLUME
from
Warehouse w,
Products p
where
w.product_id = p.product_id
group by
WAREHOUSE_NAME;
1445. 苹果和桔子
写一个 SQL 查询, 报告每一天 苹果 和 桔子 销售的数目的差异.
返回的结果表, 按照格式为 (‘YYYY-MM-DD’) 的 sale_date 排序.

解
select
s.sale_date,
s.sold_num-a.sold_num diff
from
Sales s,Sales a
where
s.sale_date=a.sale_date and
s.fruit='apples' and a.fruit='oranges'
group by s.sale_date
1193. 每月交易 I
题

编写一个 sql 查询来查找每个月和每个国家/地区的事务数及其总金额、已批准的事务数及其总金额。
以 任意顺序 返回结果表。

解
select
DATE_FORMAT(t.trans_date, '%Y-%m') month ,
t.country country ,
count(1) trans_count ,
count(if(t.state='approved',1,NULL)) approved_count,
sum(t.amount) trans_total_amount,
sum(if(t.state='approved',amount,0)) approved_total_amount
from
Transactions t
group by
DATE_FORMAT(t.trans_date, '%Y-%m'),t.country;-- 按照国家,年月分类
知识点:
- DATE_FORMAT(t.trans_date, ‘%Y-%m’),数据表中的 trans_date 是精确到日,我们可以使用 DATE_FORMAT() 函数将日期按照年月 %Y-%m 输出。比如将 2019-01-02 转换成 2019-01
- if用法:if(t.state=‘approved’,1,NULL),如果(t.state=‘approved’)成立,就返回1,不成立就返回null
1633. 各赛事的用户注册率
题
写一条 SQL 语句,查询各赛事的用户注册百分率,保留两位小数。
返回的结果表按 percentage 的 降序 排序,若相同则按 contest_id 的 升序 排序。

解释:
所有用户都注册了 208、209 和 210 赛事,因此这些赛事的注册率为 100% ,我们按 contest_id 的降序排序加入结果表中。
Alice 和 Alex 注册了 215 赛事,注册率为 ((2/3) * 100) = 66.67%
Bob 注册了 207 赛事,注册率为 ((1/3) * 100) = 33.33%
解
select
--先按id分组,round保留两位小数
r.contest_id contest_id,
round(100*count(1)/(select count(1) from users),2) percentage
from
Register r
group by
r.contest_id
order by
percentage desc,contest_id asc;
1173. 即时食物配送 I
题
如果顾客期望的配送日期和下单日期相同,则该订单称为 「即时订单」,否则称为「计划订单」。
写一条 SQL 查询语句获取即时订单所占的百分比, 保留两位小数。
查询结果如下所示。
解
select
round(
sum(IF(order_date = customer_pref_delivery_date, 1, NULL))
/ COUNT(1)* 100,2)
as immediate_percentage
from
Delivery;
1211. 查询结果的质量和占比
题
“位置”(position)列的值为 1 到 500 。
“评分”(rating)列的值为 1 到 5 。评分小于 3 的查询被定义为质量很差的查询。
将查询结果的质量 quality 定义为:
各查询结果的评分与其位置之间比率的平均值。
将劣质查询百分比 poor_query_percentage 为:
评分小于 3 的查询结果占全部查询结果的百分比。
编写一组 SQL 来查找每次查询的名称(query_name)、质量(quality) 和 劣质查询百分比(poor_query_percentage)。
质量(quality) 和劣质查询百分比(poor_query_percentage) 都应四舍五入到小数点后两位。

解
select
q.query_name query_name ,
round(avg(q.rating/q.position),2) quality,
round(sum(if(q.rating<3,1,0))/count(1)*100,2) poor_query_percentage
from
Queries q
group by
q.query_name;
175. 组合两个表
编写一个SQL查询来报告 Person 表中每个人的姓、名、城市和州。如果 personId 的地址不在 Address 表中,则报告为空 null 。
解
select
p.firstName firstName,
p.lastName lastName,
a.city city ,
a.state state
from
Person p
left join
Address a
on
p.personId=a.personId;
知识点:
总结:
内连接 inner join:A,B表值都存在情况
外连接 outer join:附表中值可能存在null的情况。
①A inner join B:取交集
②A left join B:取A全部,B没有对应的值,则为null
③A right join B:取B全部,A没有对应的值,则为null
④A full outer join B:取并集,彼此没有对应的值为null
上述4种的对应条件,在on后填写。
⭐176. 第二高的薪水(查询第N高的数据)
题
编写一个 SQL 查询,获取并返回 Employee 表中第二高的薪水 。如果不存在第二高的薪水,查询应该返回 null 。

解
select
ifnull(
(select distinct salary from Employee order by salary desc limit 1 offset 1) ,null)
SecondHighestSalary
知识点:
- 数据去重:SELECT DISTINCT
- limit y 分句表示: 读取 y 条数据
limit x, y 分句表示: 跳过 x 条数据,读取 y 条数据
limit y offset x 分句表示: 跳过 x 条数据,读取 y 条数据
eg:limit 1 offset 1跳过1条数据,读取1条数据 - IFNULL(value1, value2) :如果value1不为空,返回value1,否则返回value2
题
编写一个SQL查询来报告 Employee 表中第 n 高的工资。如果没有第 n 个最高工资,查询应该报告为 null
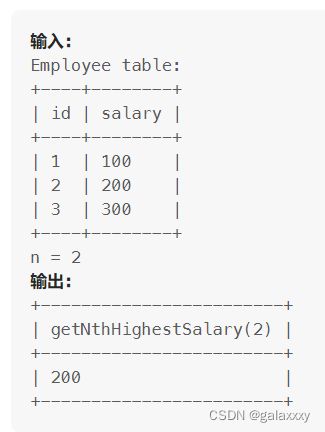
解
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
declare m int;
SET m = N-1;
RETURN (
select
ifnull(
(select distinct salary from Employee order by salary desc limit 1 offset m),null)
);
END
知识点:
- limit不支持运算,所以不能直接N-1,需要先声明一个int型变量m,并且set他的值为N-1
- 另外,这题不需要再为列起别名,因为在一个函数里,这个函数返回的是一个int值,那么后台在调用这个函数时,返回的列名就是——函数名(N)
⭐178. 分数排名
编写 SQL 查询对分数进行排序。排名按以下规则计算:
分数应按从高到低排列。
如果两个分数相等,那么两个分数的排名应该相同。
在排名相同的分数后,排名数应该是下一个连续的整数。换句话说,排名之间不应该有空缺的数字。
按 score 降序返回结果表。
select
score ,
dense_rank() over(order by Score desc) 'rank'
from
Scores;
知识点:
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
select *,
rank() over (order by 成绩 desc) as ranking,
dense_rank() over (order by 成绩 desc) as dese_rank,
row_number() over (order by 成绩 desc) as row_num
from 班级
得到结果:
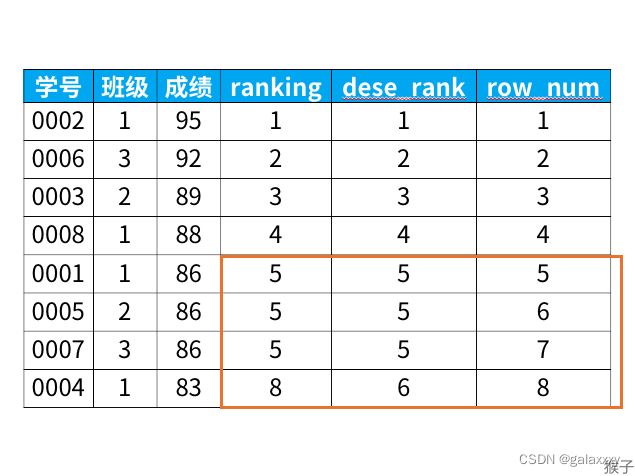
从上面的结果可以看出: 1)rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
2)dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
3)row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
⭐180. 连续出现的数字
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
返回的结果表中的数据可以按 任意顺序 排列。
select
distinct Num as ConsecutiveNums
from
(select Num,lead(Num,1) over(order by id) Num1,lead(Num,2) over (order by id) Num2 from Logs)
temp -- 此处创立一张新表,要有自己的姓名
where
Num=Num1 and Num1=Num2;
# 法二:ID连续,Num相等
SELECT DISTINCT
l1.Num AS ConsecutiveNums
FROM
Logs l1,
Logs l2,
Logs l3--自连接
WHERE
l1.Id = l2.Id - 1
AND l2.Id = l3.Id - 1
AND l1.Num = l2.Num
AND l2.Num = l3.Num
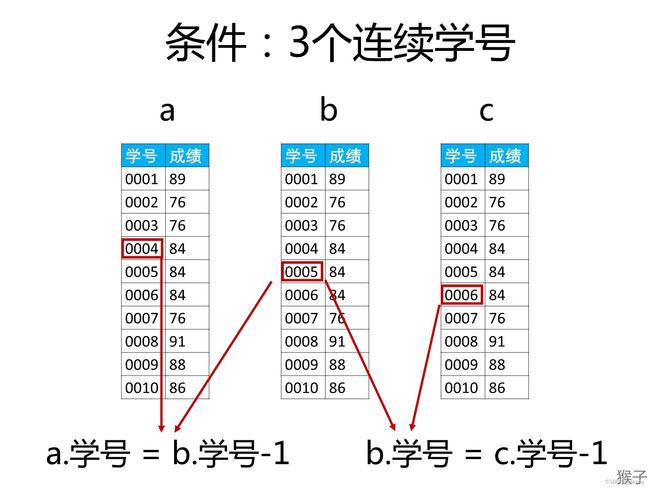
知识点:
1.
向上窗口函数lead:取出字段名所在的列,向上N行的数据,作为独立的列
向下窗口函数lag:取出字段名所在的列,向下N行的数据,作为独立的列
窗口函数语法如下:
lag(字段名,N,默认值) over(partion by …order by …)
lead(字段名,N,默认值) over(partion by …order by …)
例题:找出连续3次为球队得分的球员

用向上窗口函数lead,得到球员姓名向上1行的列(第2列),因为A1向上1行超出了表行列的范围,所以这里对应的值就是默认值(不设置默认值就是null)

select 球员姓名,
lead(球员姓名,1) over(partition by 球队
order by 得分时间) as 下一项
from 分数表;

select 球员姓名,
lead(球员姓名,1) over(partition by 球队 order by 得分时间) as 姓名1,
lead(球员姓名,2) over(partition by 球队 order by 得分时间) as 姓名2
from 分数表;
结果
完成上面工作,现在就可以使用where子句筛选出出三个值都相同的行,也就是球员姓名 = 姓名1 and 球员姓名 = 姓名2。
select distinct 球员姓名
from(
select 球员姓名,
lead(球员姓名,1) over(partition by 球队 order by 得分时间) as 姓名1,
lead(球员姓名,2) over(partition by 球队 order by 得分时间) as 姓名2
from 分数表
) as a
where (a.球员姓名 = a.姓名1 and a.球员姓名 = a.姓名2);
解题步骤:
-
要用窗口函数,先根据球队分组,再按得分时间排序

-
找出连续出现3次的值,用lag,lead函数排出一张新表
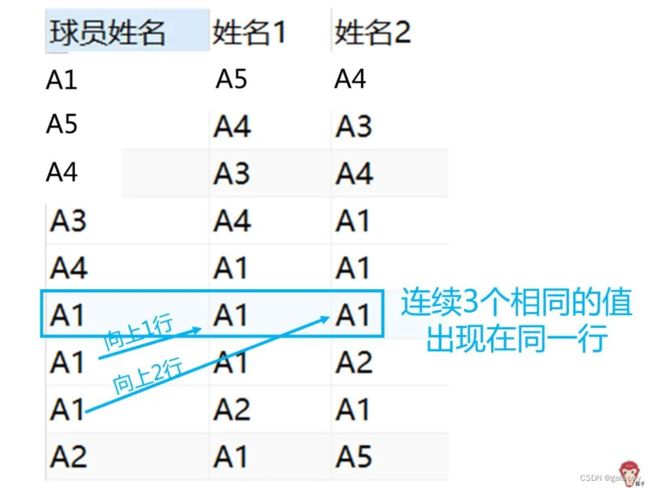
3.使用where子句筛选出出三个值都相同的行,也就是球员姓名 = 姓名1 and 球员姓名 = 姓名2。
181. 超过经理收入的员工
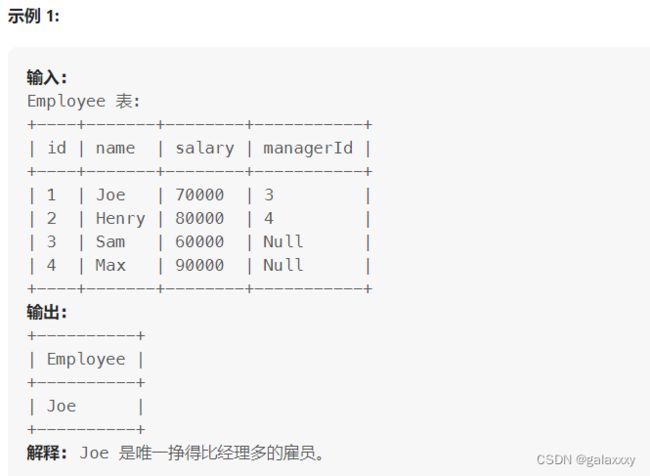
select
a.name Employee
from
Employee a,
Employee b
where
a.managerId=b.id and
a.salary>b.salary
⭐182. 查找重复的名字

1.看到“找重复”的关键字眼,首先要用分组函数(group by),再用聚合函数中的计数函数count()给姓名列计数。
2.分组汇总后,生成了一个如下的表。从这个表里选出计数大于1的姓名,就是重复的姓名。

select 姓名, count(姓名) as 计数
from 学生表
group by 姓名;
select 姓名 from
(
select 姓名, count(姓名) as 计数
from 学生表
group by 姓名
) as 辅助表
where 计数 > 1;
法二:having
select 姓名
from 学生表
group by 姓名
having count(姓名) > 1;
【举一反三】
本题也可以拓展为:找出重复出现n次的数据。只需要改变having语句中的条件即可:
select 列名
from 表名
group by 列名
having count(列名) > n;
⭐183. 从不订购的客户
某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。


上图黑色框里的sql解决的问题是:不在表里的数据,也就是在表A里的数据,但是不在表B里的数据
select
c.Name Customers
from
Customers c
left join
Orders o
on
c.id=o.CustomerId
where
o.CustomerId is null;
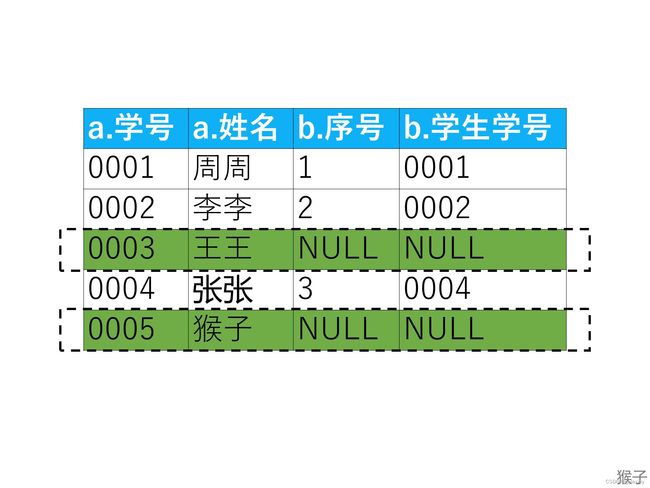
请问不是近视眼的学生都有谁?

select a.姓名 as 不近视的学生名单
from 学生表 as a
left join 近视学生表 as b
on a.学号=b.学生学号
where b.序号 is null;
在不加where字句的情况下,两表联结得到下图的表

假设where字句(where b.序号 is null;)就会把b.序号这一列里为空值(NULL)的行选出来,就是题目要求的不近视的学生。(下图绿色框里的行)
⭐184. 部门工资最高的员工

法一:
select Department.name,Employee.name,Salary
from Employee
left join Department on Employee.DepartmentId = Department.Id
where (Employee.DepartmentId,Salary) in
(select DepartmentId,max(Salary)
from Employee
group by DepartmentId);
解题步骤:
- 两表连结
因为要查的是所有员工,所以是以员工表(表名Employee)进行左联结。
联结条件是什么?通过部门Id联结。
所以多表联结的sql如下:
from Employee
left join Department on Employee.DepartmentId = Department.Id
- 在合并表里查询,找出每个部门内最高的工资
where (Employee.DepartmentId,Salary) in
(select DepartmentId,max(Salary)
from Employee
group by DepartmentId)
/* 此语句可查出每个部门里的最高工资,
in里是包含多条数据的,在指定的集合范围内,多选一
eg:-- 查询销售部和市场部的所有员工信息
select * from employee
where dept in
(select id from dept where name = '销售部' or name = '市场部');*/
详细解题过程点此
法二:窗口函数
select Department, Employee, Salary
from
(
select
D.Name as Department,
E.Name as Employee,
E.Salary as Salary,
rank() over(partition by D.Name order by E.Salary desc) as rank_
from Employee E join Department D on E.DepartmentId = D.Id
) as tmp
where rank_ = 1
解题步骤:
1.rank() over(partition by D.Name order by E.Salary desc) as rank_
此句代码是先按照D.Name分区,再按照E.Salary 降序排序,每个分区里的rank排序都重新开始

select
D.Name as Department,
E.Name as Employee,
E.Salary as Salary,
rank() over(partition by D.Name order by E.Salary desc) as rank_
from Employee E join Department D on E.DepartmentId = D.Id
此代码意思是在左连接表中打出排名,再在此表中查询每个rank_=1的行
185. 部门工资前三高的所有员工
topN问题:每组最大的N条记录。这类问题涉及到“既要分组,又要排序”的情况,要能想到用窗口函数来实现。

解释:
在IT部门:
- Max的工资最高
- 兰迪和乔都赚取第二高的独特的薪水
- 威尔的薪水是第三高的
在销售部:
- 亨利的工资最高
- 山姆的薪水第二高
- 没有第三高的工资,因为只有两名员工
-- 与上题一致,修改where即可
select
Department ,Employee , Salary
from
(
select
d.name Department ,
e.name Employee ,
e.salary Salary,
dense_rank() over(partition by e.departmentId order by salary desc)rank_
from
Employee e left join Department d
on e.departmentId=d.id
) temp
where rank_<=3;
196. 删除重复的电子邮箱
编写一个 SQL 删除语句来 删除 所有重复的电子邮件,只保留一个id最小的唯一电子邮件。
以 任意顺序 返回结果表。 (注意: 仅需要写删除语句,将自动对剩余结果进行查询)

delete a
from person a inner join person b
where a.email = b.email and a.id > b.id
知识点
- delete语法如何作用于联结表
delete语法
最原始的delete语句delete from table1 where table1.id = 1;
如果需要关联其他表进行删除
delete table1
from table1 inner join table2 on table1.id = table2.id
where table2.type = 'something' and table1.id = 'idnums';
- inner join的原理
组成笛卡尔积
select * from person as a inner join person as b

筛选笛卡尔积中,email相同的记录
select * from person as a inner join person as b where a.email = b.email

选出email相同且a中id更大的记录,从而保留小的id
select * from person as a inner join person as b where a.email = b.email and a.id > b.id

197. 上升的温度
编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 id 。
返回结果 不要求顺序 。

select
b.id id
from
Weather a,Weather b
where
DATEDIFF(a.RecordDate,b.RecordDate) = -1 and a.Temperature<b.Temperature;
知识点:
- DATEDIFF(date1, date2) : 返回起始时间date1和结束时间date2之间的天数
where b.recordDate = ADDDATE( a.recordDate, INTERVAL 1 DAY ) and a.Temperature
DATE_ADD(date, INTERVAL expr type) :返回一个日期/时间值加上一个时间间隔expr后的时间值
⭐⭐262. 行程和用户
取消率 的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。
写一段 SQL 语句查出 “2013-10-01” 至 “2013-10-03” 期间非禁止用户(乘客和司机都必须未被禁止)的取消率。非禁止用户即 banned 为 No 的用户,禁止用户即 banned 为 Yes 的用户。
返回结果表中的数据可以按任意顺序组织。其中取消率 Cancellation Rate 需要四舍五入保留 两位小数 。
查询结果格式如下例所示。


SELECT
T.request_at Day,
round(
sum(
if(T.status='completed',0,1)
)
/
count(T.status),2
) as 'Cancellation Rate'
FROM Trips AS T
JOIN Users AS U1 ON (T.client_id = U1.users_id AND U1.banned ='No')
JOIN Users AS U2 ON (T.driver_id = U2.users_id AND U2.banned ='No')
where t.request_at between '2013-10-01' and '2013-10-03'
group by T.request_at;
步骤:
- 内连接:先筛出两表id相等,且都不被禁止的用户,inner join取交集(两边条件都要存在)
- 按日期分组
- 公式计算:(取消订单数量) / (订单总数)
511. 游戏玩法分析 I
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的日期。

--法一:按照 player_id 将 activity 分组
--使用 min 函数,求出日期的最小值
select
player_id ,
min(event_date) first_login
from Activity
group by player_id;
--法二:先排名
select player_id, event_date as first_login from (
select
player_id,
event_date,
dense_rank()
over(partition by player_id order by event_date) as 排名
from activity
) as temp
where 排名 = 1;
512. 游戏玩法分析 II
写一条 SQL 查询语句获取每位玩家 第一次登陆平台的设备

select
player_id,
device_id
from
(select
player_id,device_id,event_date,
rank()over(partition by player_id order by event_date) ranking
from Activity
)temp
where temp.ranking=1;
534. 游戏玩法分析 III
编写一个 SQL 查询,同时报告每组玩家和日期,以及玩家到目前为止玩了多少游戏。也就是说,在此日期之前玩家所玩的游戏总数。详细情况请查看示例。

--窗口函数sum
select
player_id ,
event_date ,
sum(games_played)over(partition by player_id order by event_date asc) games_played_so_far
from
Activity ;
知识点:
- 聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。
⭐⭐550. 游戏玩法分析 IV
报告在首次登录的第二天再次登录的玩家的比率,四舍五入到小数点后两位。换句话说,您需要计算从首次登录日期开始至少连续两天登录的玩家的数量,然后除以玩家总数。

select
round(
count(a.player_id)/
(select count(distinct player_id)from Activity),
2)
fraction
from
Activity a
inner join
(
select
player_id,min(event_date) first_login
from
Activity
group by
player_id
)b
on DATEDIFF(a.event_date, b.first_login)= 1 and a.player_id=b.player_id;
解题步骤:
1.
找出每个用户首次登录日期,并打印,作为b表
select
player_id,min(event_date) first_login
from
Activity
group by
player_id
- a,b表内连接,条件是a.日期比b.日期多1天并且id相同,从此筛出一条记录

- 公式计算:内连表记录数/原表总id数
内连表记录数=a.count(a.player_id)
原表总id数 =select count(distinct player_id)from Activity
⭐⭐ 569. 员工薪水中位数
写一个SQL查询,找出每个公司的工资中位数。

select
id , company ,Salary
from
(
select
id,
company,
salary,
row_number()over(partition by company order by salary asc) ranking,
count(Id) over(partition by Company)as cnt
from
Employee
)temp
where ranking>=cnt/2 and ranking<=cnt/2+1;
# where temp.ranking in(floor((cnt + 1) / 2), floor((cnt + 2) / 2));也可以
知识点:
1.
select
id,
company,
salary,
row_number()over(partition by company order by salary asc) ranking,-- 排序
count(Id) over(partition by Company)as cnt-- 每个公司总人数
from
Employee
row_number()——排序,相同的数序号不同

count(Id) over(partition by Company)as cnt按公司分组,统计每个公司的总人数为cnt

2. 筛出中位数条件:①where ranking>=cnt/2 and ranking<=cnt/2+1;
(当排序的序号>=cnt/2且<=cnt/2+1)
eg:
当 total = 6,中位数是 3 和 4 , 排名 ≥ 3 and 排名 ≤ 4 ,筛选出来的是 3 和 4(一般来说中位数是取平均,但此题取2个中位数)
当 total = 5,中位数是 3 , 排名 ≥ 2.5 and 排名 ≤ 3.5 ,筛选出来的就是 3
② where temp.ranking in(floor((cnt + 1) / 2), floor((cnt + 2) / 2));
floor 是向下取整
当 total = 6,中位数是 3 和 4 ,这里计算的结果正是 3 和 4
当 total = 5,中位数是 3,这里计算的两个值分别是 3 和 3
570. 至少有5名直接下属的经理

select
e.name name
from
Employee e
inner join
(
select
managerId ,count(1) summ
from
Employee
group by
managerId
)temp
where temp.summ>=5 and temp.managerId=e.id;
解题步骤:1. 先做表计算总数
select
managerId ,count(1) summ
from
Employee
group by
managerId

2. 两表连接inner join
法二:
select Name
from Employee
where Id in
(
select distinct ManagerId
from Employee
group by ManagerID
having count(ManagerID)>=5
)
知识点:
- having分组后的条件筛选
- 子查询匹配(where in)
⭐⭐571. 给定数字的频率查询中位数–对比569题
中位数 是将数据样本中半数较高值和半数较低值分隔开的值。
编写一个 SQL 查询,解压 Numbers 表,报告数据库中所有数字的中位数 。结果四舍五入至 一位小数 。

select
round(avg(num),1) median
from
(
select
num,
sum(frequency) over(order by num desc) desc_frequency,
sum(frequency) over(order by num asc) asc_frequency,
sum(frequency) over() total_frequency
from numbers
)temp
where desc_frequency>=total_frequency/2
and asc_frequency>=total_frequency/2;
解题思路:
- 使用sum over(order by ) 对数字个数进行正序和逆序累计, 当某一数字的 正序和逆序累计 均大于 整个序列的数字个数的一半 时即为中位数, 将最后选定的一个或两个中位数进行求均值即可。

中位数就是将所有数字按照升序或者降序排列,然后取最中间的数字
数字个数是奇数的话,那么中位数会在这个序列中
数字个数是偶数的话,那么中位数是最中间的两个数的平均值
574. 当选者
编写一个SQL查询来报告获胜候选人的名字(即获得最多选票的候选人)。
生成测试用例以确保 只有一个候选人赢得选举。


select c.name
from
Candidate c
inner join
(
select
candidateId,count(*),rank()over(order by count(*) desc) ranking
from
Vote
group by candidateId
)temp
where ranking = 1 and temp.candidateId=c.id;
577. 员工奖金
选出所有 bonus < 1000 的员工的 name 及其 bonus。

select
e.name name,b.bonus bonus
from
Employee e
left join
Bonus b
on b.empId=e.empId
where bonus<1000 or bonus is null
知识点:
- 不能用bonus=‘null’,因为是数字型,用is null
⭐578. 查询回答率最高的问题

回答率 是指:同一问题编号中回答次数占显示次数的比率。
编写一个 SQL 查询以报告 回答率 最高的问题。如果有多个问题具有相同的最大 回答率 ,返回 question_id 最小的那个。
select
question_id survey_log
from
SurveyLog
group by
question_id
order by sum(if(action='answer',1,0))/count(*) desc,question_id asc
limit 1
知识点:
order by 里也是可以写聚合函数的,因为order by 的执行顺序在group by之后
⭐⭐⭐579. 查询员工的累计薪水
Employee 表保存了一年内的薪水信息。
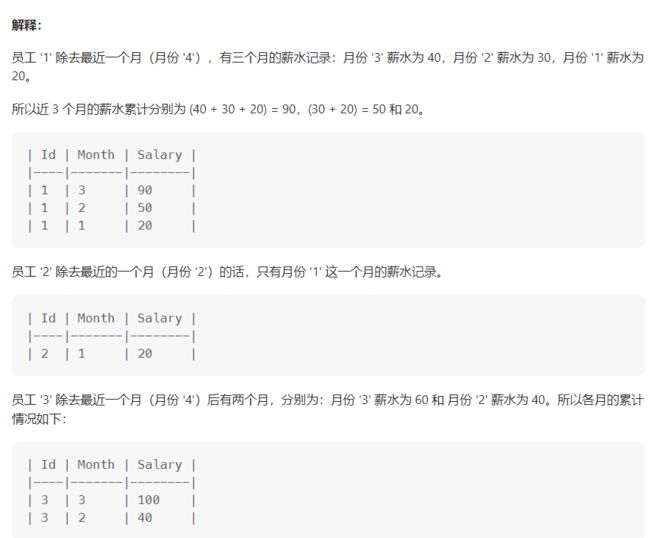
请你编写 SQL 语句,对于每个员工,查询他除最近一个月(即最大月)之外,剩下每个月的近三个月的累计薪水(不足三个月也要计算)。
结果请按 Id 升序,然后按 Month 降序显示。

select
A.id id,
A.Month month,
sum(A.Salary) over(partition by A.Id order by A.Month range BETWEEN 2 PRECEDING AND CURRENT ROW) Salary
from
(# 删掉最大月份,其他月份及薪水重新排列--1
select
e2.Id Id ,e2.Month Month,e2.Salary Salary
from Employee e2
inner join
(# 找出最大月份,之后删掉--2
select
Id,max(Month) maxmonth,Salary
from Employee
group by Id
)e1--2
where e1.maxmonth>e2.Month and e1.Id=e2.Id
order by e2.id asc,e2.Month asc
)A--1
order by A.id asc,A.Month desc
解题步骤:
思路整体为先找到每个用户最大月份,然后过滤当前用户的最大月份,查询每个月最近前N月份的数据总和
- 查询最近前N月份(题目为3,N换3)的数据总和
⭐窗口函数rows和range用法
sum(A.Salary) over(partition by A.Id order by A.Month range BETWEEN 2 PRECEDING AND CURRENT ROW)
假如有1,2,3,4,7,8月份的数据,7月份的累积前三个月工资应该是5,6,7月份工资
使用"rows 2 PRECEDING"计算的是3,4,7月份的工资
使用"range 2 PRECEDING"计算的是5,6,7月份的工资
580. 统计各专业学生人数
编写一个SQL查询,为 Department 表中的所有部门(甚至是没有当前学生的部门)报告各自的部门名称和每个部门的学生人数。
按 student_number 降序 返回结果表。如果是平局,则按 dept_name 的 字母顺序 排序。

select
d.dept_name ,sum(if(s.dept_id,1,0)) student_number
from
Department d
left join
Student s
on s.dept_id=d.dept_id
group by
d.dept_id
order by
student_number desc,CONVERT (dept_name USING gbk) asc
知识点:
sql 按名称首字母拼音排序
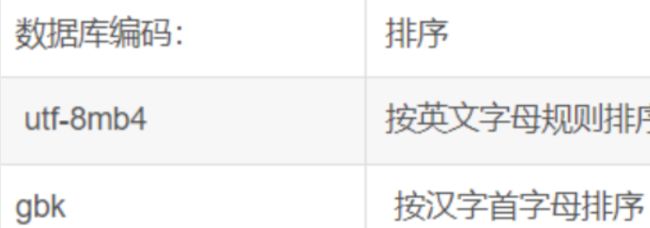
ORDER BY CONVERT (字段 USING gbk);
584. 寻找用户推荐人

select
name
from
customer
where referee_id!=2 or referee_id is null
585. 2016年的投资
写一个查询语句,将 2016 年 (TIV_2016) 所有成功投资的金额加起来,保留 2 位小数。
对于一个投保人,他在 2016 年成功投资的条件是:
他在 2015 年的投保额 (TIV_2015) 至少跟一个其他投保人在 2015 年的投保额相同。
他所在的城市必须与其他投保人都不同(也就是说维度和经度不能跟其他任何一个投保人完全相同)。

解释
就如最后一个投保人,第一个投保人同时满足两个条件:
- 他在 2015 年的投保金额 TIV_2015 为 ‘10’ ,与第三个和第四个投保人在 2015 年的投保金额相同。
- 他所在城市的经纬度是独一无二的。
第二个投保人两个条件都不满足。他在 2015 年的投资 TIV_2015 与其他任何投保人都不相同。
且他所在城市的经纬度与第三个投保人相同。基于同样的原因,第三个投保人投资失败。
所以返回的结果是第一个投保人和最后一个投保人的 TIV_2016 之和,结果是 45 。
SELECT
ROUND(SUM(TIV_2016), 2) as TIV_2016
FROM(
SELECT
*,
count(*) over(partition by TIV_2015) as cnt_1,
count(*) over(partition by LAT, LON) as cnt_2
FROM
insurance
) a
WHERE a.cnt_1 > 1 AND a.cnt_2 < 2
586. 订单最多的客户
编写一个SQL查询,为下了 最多订单 的客户查找 customer_number 。
测试用例生成后, 恰好有一个客户 比任何其他客户下了更多的订单。

select
customer_number
from
Orders
group by
customer_number
order by
count(*) desc
limit 1
-- 题目中有一个进阶要求:如果有多个订单数最多并列的用户呢?
select customer_number from orders group by customer_number
having count(*)=(-- 先获取最大的数字
select count(*) as c
from orders
group by customer_number order by c desc limit 1)
595. 大的国家
如果一个国家满足下述两个条件之一,则认为该国是 大国 :
面积至少为 300 万平方公里(即,3000000 km2),或者
人口至少为 2500 万(即 25000000)
编写一个 SQL 查询以报告 大国 的国家名称、人口和面积。
按 任意顺序 返回结果表。
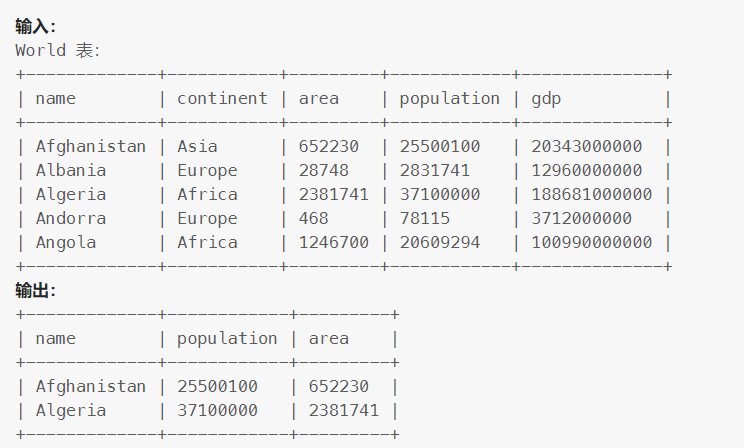
select
name ,
population,
area
from
World
where
area >=3000000 or population>=25000000
596. 至少5名学生的课

select
class
from
Courses
group by
class
having
count(*) >=5
知识点:
- sql执行顺序:

- group by 之后 筛选只能用having不能用where
- where 子句基于指定的条件对记录行进行筛选
- 使用 having 子句筛选分组
597. 好友申请 I:总体通过率
写一个查询语句,求出好友申请的通过率,用 2 位小数表示。通过率由接受好友申请的数目除以申请总数。
提示:
- 通过的好友申请不一定都在表 friend_request 中。你只需要统计总的被通过的申请数(不管它们在不在表 FriendRequest 中),并将它除以申请总数,得到通过率
- 一个好友申请发送者有可能会给接受者发几条好友申请,也有可能一个好友申请会被通过好几次。这种情况下,重复的好友申请只统计一次。
- 如果一个好友申请都没有,你应该返回 accept_rate 为 0.00 。

# 总体通过率 = 总的被通过的申请数 / 申请总数
select
round(--1
ifnull(-- 2
(select distinct count(distinct requester_id,accepter_id)from RequestAccepted )
/(select distinct count(distinct sender_id,send_to_id)from FriendRequest )
,0)-- 2
,2) -- 1
accept_rate
知识点:
- 注意:申请总数可能为0 则计算出的结果为NULL, 可以使用IFNULL对计算结果进行处理
NULL(value1, value2) :如果value1不为空,返回value1,否则返回value2 count(distinct requester_id,accepter_id)是计算去重之后的总数
601. 体育馆的人流量
编写一个 SQL 查询以找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列 的结果表。
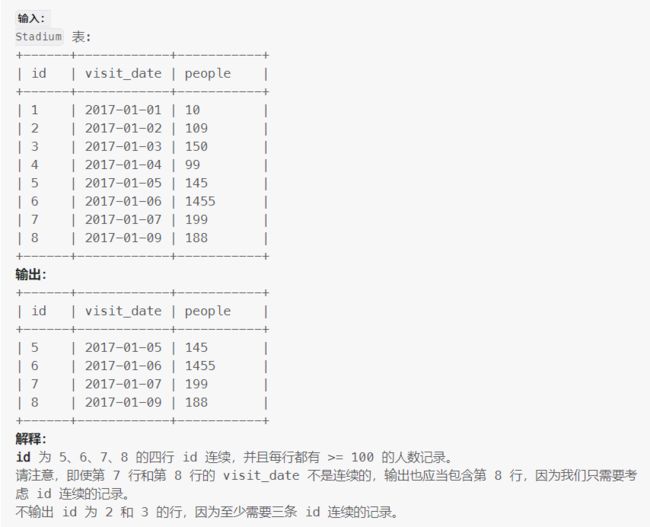
select
id,visit_date,people
from
(# 打印表显示上一个、上上一个,下一个,下下个--1
select id,
lead(id,1) over(order by id asc) as ied1,
lead(id,2) over(order by id asc) as ied2,
lag(id,1) over(order by id asc) as ia1,
lag(id,2) over(order by id asc) as ia2,
visit_date,
people
from
(# 先筛选出>=100的id--2
select
*
from
Stadium
where people >=100
)b--2
)a--1
where (a.id+1=a.ied1 and a.id+2=a.ied2)or# 情况1:id下一个、下下个连续4 5 6
(a.id-1=a.ia1 and a.id-2=a.ia2)or# 情况2:id上一个、上上个连续2 3 4
(a.id+1=a.ied1 and a.id-1=a.ia1)# 情况3:id上一个、下个连续3 4 5
#Eg:id=4
步骤:
1.
# 先筛选出>=100的id--2
select
*
from
Stadium
where people >=100
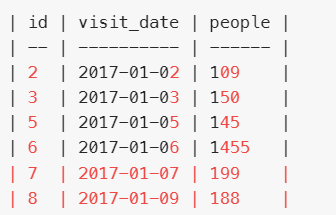
2.
# 打印表显示上一个、上上一个,下一个,下下个--1
select id,
lead(id,1) over(order by id asc) as ied1,
lead(id,2) over(order by id asc) as ied2,
lag(id,1) over(order by id asc) as ia1,
lag(id,2) over(order by id asc) as ia2,
visit_date,
people
from # 先筛选出>=100的id--2
(select * from Stadiumwhere people >=100 )b--2

3. 分情况筛选
法二:也可以筛选人数
select id,visit_date,people
from
(
select id ,
lead(people,1) over(order by id) ld ,
lead(people,2) over(order by id) ld2 ,
visit_date ,
lag(people,1) over(order by id) lg
,lag(people,2) over(order by id) lg2
,people
from stadium
) a where
(a.people>=100 and a.ld>=100 and a.lg>=100 ) #情况1:本身>100,上一个下一个也>100
or (a.people>=100 and a.ld>=100 and a.ld2>=100)#情况2:本身>100,下一个下下一个也>100
or (a.people>=100 and a.lg>=100 and a.lg2>=100)#情况3:本身>100,上一个上上一个也>100

602. 好友申请 II :谁有最多的好友
写一个查询语句,找出拥有最多的好友的人和他拥有的好友数目。
生成的测试用例保证拥有最多好友数目的只有 1 个人。
select
temp.id ,count(*) num
from
(
select requester_id id from RequestAccepted
union all
select accepter_id id from RequestAccepted
)temp
group by id
order by count(*) desc
limit 1
知识点:
union all 把多次查询的结果合并,形成一个新的查询集
⭐⭐⭐603. 连续空余座位
编写一个SQL查询来报告电影院所有连续可用的座位。
返回按 seat_id 升序排序 的结果表。
测试用例的生成使得两个以上的座位连续可用。

select
distinct c1.seat_id
from cinema c1 join cinema c2 #自连接
on abs(c1.seat_id - c2.seat_id) = 1 and c1.free = 1 and c2.free = 1
order by c1.seat_id
解题步骤:
join 连接后的结果是笛卡尔积,所以需要有筛选条件,筛选条件是
abs(c1.seat_id - c2.seat_id) = 1 因为,两个座位号相连,座位号 seat_id 相减为 1 的就是相连的座位号。这里使用 abs() 取绝对值,就无需考虑 c1 、 c2 表顺序的问题了。
c1.free = 1 and c2.free = 1 ,因为 free = 1 表示这个座位空闲

法二:
with temp as ( #相当于先建了一个temp表
select
seat_id,
seat_id - row_number() over() as k
from cinema where free = 1
)
select
seat_id
from temp
where k in (# 找出同一个值>=2的排序号 ,此处为1
select k
from temp
group by k
having count(*) >= 2
)
知识点:
with……as():其实就是把一大堆重复用到的sql语句放在with as里面,取一个别名,后面的查询就可以用它

2.seat_id - row_number() over() as k:如果座位连续,这组 k 值应该是相等的
与row_number()区别:

连续的数字排序相同(连续数字分组)
607. 销售员
编写一个SQL查询,报告没有任何与名为 “RED” 的公司相关的订单的所有销售人员的姓名。
以 任意顺序 返回结果表。

解释:
根据表 orders 中的订单 ‘3’ 和 ‘4’ ,容易看出只有 ‘John’ 和 ‘Pam’ 两个销售员曾经向公司 ‘RED’ 销售过。
所以我们需要输出表 salesperson 中所有其他人的名字。
select
name
from
SalesPerson
where sales_id not in# 注意是not in
(# 找出Orders表中此编号的sales_id
select
sales_id
from
Orders
where com_id in
( #先找出company表中RED的编号
select com_id
from Company
where name = 'RED'
)
)
608. 树节点

解释
节点 ‘1’ 是根节点,因为它的父节点是 NULL ,同时它有孩子节点 ‘2’ 和 ‘3’ 。
节点 ‘2’ 是内部节点,因为它有父节点 ‘1’ ,也有孩子节点 ‘4’ 和 ‘5’ 。
节点 ‘3’, ‘4’ 和 ‘5’ 都是叶子节点,因为它们都有父节点同时没有孩子节点。
样例中树的形态如下:
1
/ \
2 3
/ \
4 5
注意
如果树中只有一个节点,你只需要输出它的根属性。
select
distinct a.id,
(case when a.p_id is null then 'Root' #判断三条件
when a.p_id is not null && b.id is not null then 'Inner'
else 'Leaf' end) type
from
tree a
left join tree b
on a.id=b.p_id
解题步骤:
left join 后

610. 判断三角形
写一个SQL查询,每三个线段报告它们是否可以形成一个三角形。
以 任意顺序 返回结果表。

select
x,
y,
z,
if(x+y>z && x+z>y && y+z>x && x-y,"Yes","No") triangle
from
Triangle
知识点:
构成三角形的条件:(1)两边之和大于第三边(2)两边之差小于第三边
612. 平面上的最近距离

select
round(min(sqrt(power(a.x-b.x,2)+power(a.y-b.y,2))),2) shortest
from
Point2D a
join
Point2D b
on a.x!=b.x or a.y!=b.y
613. 直线上的最近距离
表 point 保存了一些点在 x 轴上的坐标,这些坐标都是整数。
写一个查询语句,找到这些点中最近两个点之间的距离。
| x |
|---|
| -1 |
| 0 |
| 2 |
最近距离显然是 ‘1’ ,是点 ‘-1’ 和 ‘0’ 之间的距离。所以输出应该如下:
| shortest |
|---|
| 1 |
注意:每个点都与其他点坐标不同,表 table 不会有重复坐标出现。
进阶:如果这些点在 x 轴上从左到右都有一个编号,输出结果时需要输出最近点对的编号呢?
select
min(abs(a.x-b.x)) shortest
from
point a
join
point b
on
a.x!=b.x
614. 二级关注者
在 facebook 中,表 follow 会有 2 个字段: followee, follower ,分别表示被关注者和关注者。
请写一个 sql 查询语句,对每一个关注者,查询关注他的关注者的数目。

select
a.follower follower,
count(distinct b.follower) num
from
follow a
join
follow b
on
a.follower=b.followee
group by b.followee
615. 平均工资:部门与公司比较
给如下两个表,写一个查询语句,求出在每一个工资发放日,每个部门的平均工资与公司的平均工资的比较结果 (高 / 低 / 相同)。
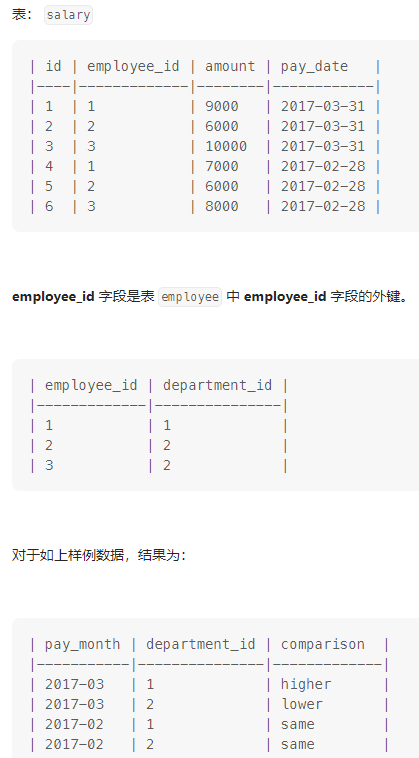
with #创建部门平均工资表
a as(
select
DATE_FORMAT(pay_date, '%Y-%m') pay_month, e.department_id department_id,avg(amount) bumen
from
salary s
left join
employee e
on
s.employee_id=e.employee_id
group by DATE_FORMAT(s.pay_date, '%Y-%m'),e.department_id
),
b as #创建公司平均工资表
(
select
DATE_FORMAT(pay_date, '%Y-%m') pay_month,avg(amount) gongsi
from
salary
group by
DATE_FORMAT(pay_date, '%Y-%m')
)
select #对比
a.pay_month,a.department_id,
(case when a.bumen<b.gongsi then 'lower' when a.bumen=b.gongsi then 'same' else 'higher' end) comparison
from
a
left join
b
on a.pay_month=b.pay_month
知识点:
- DATE_FORMAT(pay_date, ‘%Y-%m’),数据表中的 pay_date是精确到日,我们可以使用 DATE_FORMAT() 函数将日期按照年月 %Y-%m 输出。比如将 2019-01-02 转换成 2019-01
- with a as():创立临时表起名为a,多个用逗号隔开
步骤: - a表

b表
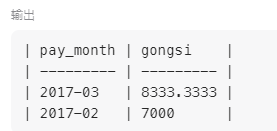
连接表
⭐⭐⭐表格格式化问题:行转列 618. 学生地理信息报告
1.1 行转列问题
通用解题技巧1:group by+sum/max/min(case when)
tips:原表格有基准id如product_id,department_id等。
通用解题技巧2:row_number()+group by+max(if) tips:原表格没有基准id需要自己构造。
一所学校有来自亚洲、欧洲和美洲的学生。
写一个查询语句实现对大洲(continent)列的 透视表 操作,使得每个学生按照姓名的字母顺序依次排列在对应的大洲下面。输出的标题应依次为美洲(America)、亚洲(Asia)和欧洲(Europe)。
测试用例的生成使得来自美国的学生人数不少于亚洲或欧洲的学生人数。
查询结果格式如下所示。

select
max(case when continent='America' then name else null end) America,
max(case when continent='Asia' then name else null end) Asia,
max(case when continent='Europe' then name else null end) Europe
from
(
select
*,
row_number() over (partition by continent order by name) ranking
from
Student
)a
group by ranking
步骤:
- 使得每个学生按照姓名的字母顺序依次排列在对应的大洲
select
*,row_number() over (partition by continent order by name) ranking
from Student

2. 按照排名筛选group by ranking
3. 因为末尾使用了group by语句,那么select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中。select语句中的continent,name字段不是分组依据字段,要想查询出来,需要套一层聚合函数,这里使用max或min函数都可以。这里加max函数无实际含义,仅语法意义。
4. 本题未选择sum函数的原因在于,表格中输出的数据为文本数据,不能进行直接加减。
1777. 每家商店的产品价格

SELECT product_id,
SUM(IF(store = 'store1', price, NULL)) AS 'store1',
SUM(IF(store = 'store2', price, NULL)) AS 'store2',
SUM(IF(store = 'store3', price, NULL)) AS 'store3'
FROM Products
GROUP BY product_id
SELECT product_id AS 'product_id',
SUM(CASE store WHEN 'store1' THEN price ELSE NULL END) AS 'store1',
SUM(CASE store WHEN 'store2' THEN price ELSE NULL END) AS 'store2',
SUM(CASE store WHEN 'store3' THEN price ELSE NULL END) AS 'store3'
FROM Products
GROUP BY product_id
解题:
-
分组
-
必须用聚合函数 SUM, MIN, MAX,AVG这些都是
否则,分组只随机显示第一条记录
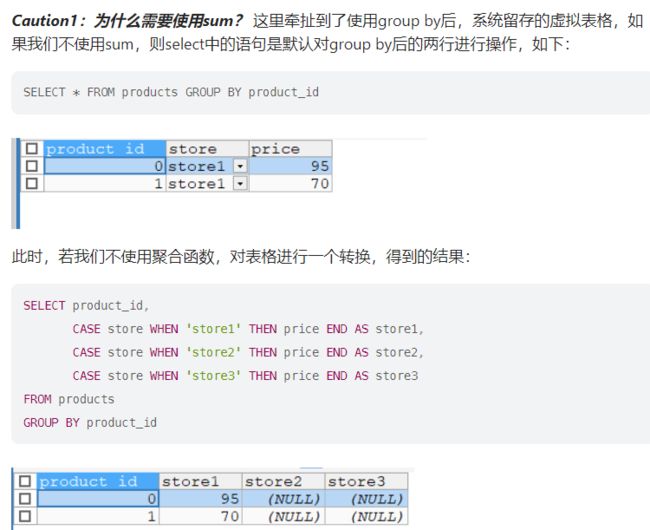
因此系统默认我们只对group by筛选出的第一行进行判断而舍弃了剩下的数据行。 正确的做法是加上聚合函数sum
列转行 1435. 制作会话柱状图
1.2 列转行问题
通用解题技巧:union all
你想知道用户在你的 app 上的访问时长情况。因此决定统计访问时长区间分别为 “[0-5>”, “[5-10>”, “[10-15>” 和 “15 or more” (单位:分钟)的会话数量,并以此绘制柱状图。
写一个SQL查询来报告(访问时长区间,会话总数)。结果可用任何顺序呈现。
duration 是用户访问应用的时间, 以秒为单位

select '[0-5>' as bin,
count(*) as total
from Sessions
where duration/60>=0 and duration/60<5
union
select '[5-10>' as bin,
count(*) as total
from Sessions
where duration/60>=5 and duration/60<10
union
select '[10-15>' as bin,
count(*) as total
from Sessions
where duration/60>=10 and duration/60<15
union
select '15 or more'as bin,
count(*) as total
from Sessions
where duration/60>=15
知识点;
union把多次查询的结果合并,形成一个新的查询集
1795. 每个产品在不同商店的价格
请你重构 Products 表,查询每个产品在不同商店的价格,使得输出的格式变为(product_id, store, price) 。如果这一产品在商店里没有出售,则不输出这一行。
输出结果表中的 顺序不作要求 。

select product_id, 'store1' as store, store1 as price
from Products
where store1 is not null
union
select product_id, 'store2' as store, store2 as price
from Products
where store2 is not null
union
select product_id, 'store3' as store, store3 as price
from Products
where store3 is not null
其中一个表格:

