MYSQL8窗口函数
MYSQL8窗口函数
-
- MYSQL8窗口函数
-
- 窗口函数分类
- 序号函数--排行榜
-
- row_number()示例
- rank()示例
- dense_rank()示例
-
- partition by对每个分区内的行进行排名
- 不加partition by全局排序
- 开窗聚合函数
- 分布函数
-
- CUME_DIST()
- PERCENT_RANK()
- 前后函数
-
- LAG()的用法
- LEAD()
- 头尾函数
- 其他函数
-
- NTH_VALUE()
- NTILE()
MYSQL8窗口函数
https://www.runoob.com/mysql/mysql-functions.html
窗口函数分类
- 序号函数
- 分布函数
- 前后函数
- 头尾函数
- 其他函数
- 开窗聚合函数
序号函数–排行榜
序号函数的作用主要是用来给结果排名次的,比如说第一名,第二名…
三种排名综合演示: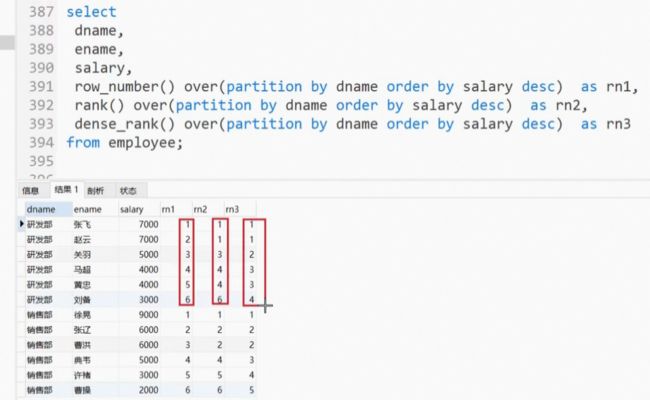
row_number()示例
row_number()函数的作用主要是给排序结果添加编号的。
rank()示例
和 ROW_NUMBER() 函数类似。但是它有一些不同之处:RANK() 函数会跳过相同的排序值,而不是分配相同的排名。
比如,排序编号是并列第一,没有第二名,然后是第三名,并列第四名,么有第五名。
dense_rank()示例
和RANK() 函数类似,但不会跳过相同的排序值。
比如:排序编号有并列第一,并列第二,第三名,中间没有空位,是连续的值。
partition by对每个分区内的行进行排名
在 MySQL 8 中,使用 DENSE_RANK() 函数时,可以通过在 OVER 子句中加入 PARTITION BY 子句来对每个分区内的行进行排名。PARTITION BY 子句与 GROUP BY 子句类似,它将查询结果划分为多个分区,并且在每个分区内使用 DENSE_RANK() 函数来给行分配排名。
假设有一个名为 订单(orders)的表,其中存储了每位客户下的订单信息,包括客户ID、订单日期和订单金额等列。表结构如下所示:
-- 创建订单表
CREATE TABLE orders (
id INT PRIMARY KEY,
customer_id INT,
order_date DATE,
amount DECIMAL(10, 2)
);
-- 插入数据
INSERT INTO orders (id, customer_id, order_date, amount) VALUES
(1, 101, '2021-01-01', 1000.00),
(2, 102, '2021-01-02', 1500.00),
(3, 103, '2021-01-03', 1200.00),
(4, 101, '2021-01-04', 800.00),
(5, 102, '2021-01-05', 2000.00),
(6, 104, '2021-01-06', 1800.00),
(7, 105, '2021-01-07', 900.00),
(8, 101, '2021-01-08', 1600.00),
(9, 102, '2021-01-09', 1100.00),
(10, 106, '2021-01-10', 2200.00);
现在,我们要对该表进行排名,并按照客户ID分组计算订单排名。
-- 对该表进行排名,并按照客户ID分组计算订单排名
SELECT
customer_id AS 客户ID,
order_date AS 订单日期,
amount AS 订单金额,
DENSE_RANK() OVER (PARTITION BY customer_id ORDER BY amount DESC) AS 排名
FROM orders;
该语句使用 DENSE_RANK() 函数根据客户ID进行分组,并使用订单金额降序排序。结果集将返回每个客户的所有订单,并为每个订单分配排名。
执行上面的查询后,返回的结果如下所示:
可以看到,每个客户的订单按照金额进行排名,并且在每个分组内都获得了相应的排名。如果有多个订单拥有相同金额,则他们将会获得相同的排名。
不加partition by全局排序
以下是一个不使用 PARTITION BY 的示例:
假设有一个名为 员工(employees)的表,其中存储了每位员工的 ID、姓名和薪资等列。表结构如下所示:
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
salary DECIMAL(10, 2)
);
INSERT INTO employees (id, name, salary) VALUES
(1, '张三', 5000.00),
(2, '李四', 7000.00),
(3, '王五', 5500.00),
(4, '赵六', 6000.00),
(5, '刘七', 8000.00);
现在,我们要对该表进行排名,并按照薪资降序排序。可以使用如下 SQL 语句:
SELECT
id AS 员工ID,
name AS 姓名,
salary AS 薪资,
RANK() OVER (ORDER BY salary DESC) AS 排名
FROM employees;
该语句使用 RANK() 函数对整个表进行排序,并根据每个员工的薪资进行排名。结果集将返回所有员工的信息,并为他们分配排名。
执行上述查询后,返回的结果如下所示:
可以看到,每个员工根据薪资进行排名,并且获得了相应的排名。如果有多个员工拥有相同的薪资,则他们将会获得相同的排名。由于我们没有使用 PARTITION BY 子句,因此在整张表内都只有一个分组,所有员工都根据薪资进行排名。
开窗聚合函数


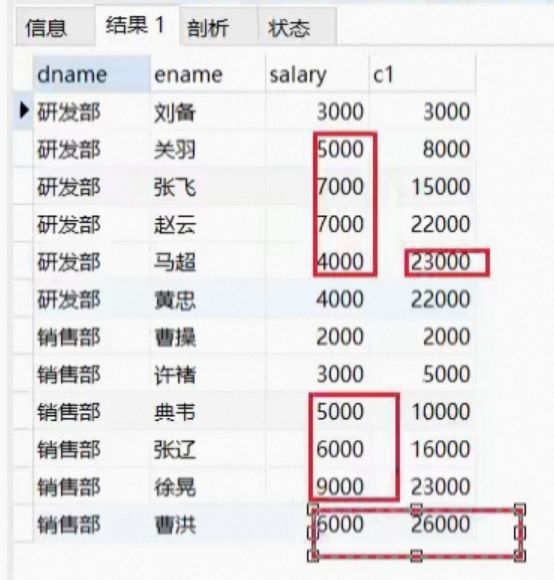
这是一个使用窗口函数 SUM() 的 SQL 查询,它计算每个部门中员工过去 3 行记录的薪资总和,并将其作为别名 c1 返回。
具体来说,语句中的 OVER() 子句用于定义一个窗口(window),其中包含每个部门 dname 中的所有员工。接下来,PARTITION BY 子句将该窗口分成多个分区,每个分区都根据 dname 列进行分组。因此,在这个查询中,每个分区都对应着同一部门的员工。
窗口函数 SUM() 将在每个分区内的每个行上执行,计算出当前行以及前三行的薪资总和。在这里,ORDER BY hiredate 指定了如何排序每个分区内的行,按照 hiredate 列的值进行升序排列。ROWS BETWEEN 3 PRECEDING AND CURRENT ROW 子句指定了要计算的行的范围,即从当前行向前数 3 行到当前行本身。
最后,查询结果将包含每个员工的姓名、所在部门、薪资和部门内前三个员工的薪资总和(c1)。由于这个查询中使用了窗口函数,因此返回的结果集中可能会包含多个行,而不是仅仅一行。
SELECT dname,
ename,
salary,
sum(salary) OVER(
PARTITION BY dname
ORDER BY hiredate ROWS BETWEEN 3 PRECEDING AND CURRENT ROW
) as c1;
分布函数
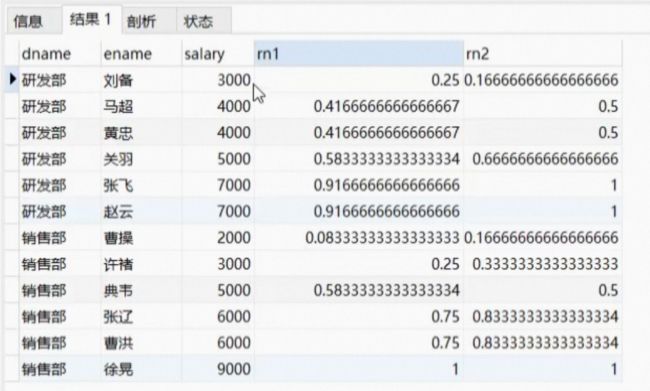
分布函数一般是用来计算占比的。
能够计算排名、行号、百分位数等统计信息的函数,它们可以对查询结果进行排序、分组和限制,进而实现更加高级的数据分析和处理。
CUME_DIST()
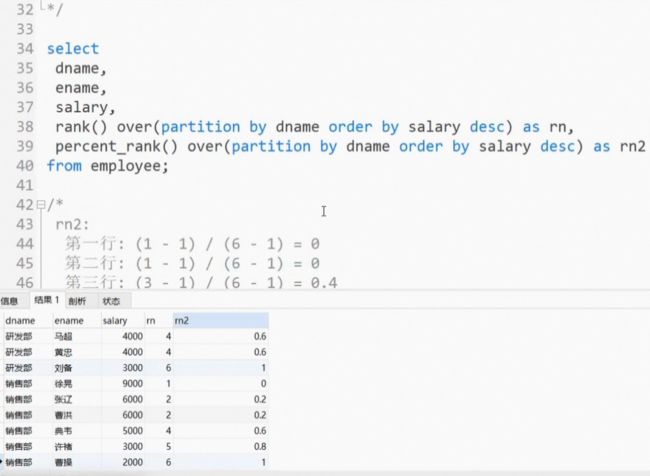
PERCENT_RANK()

前后函数

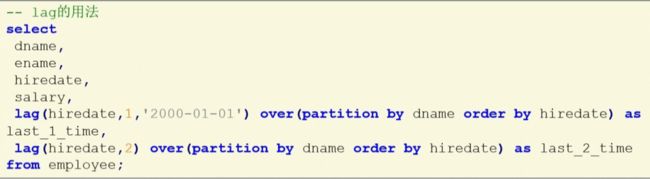
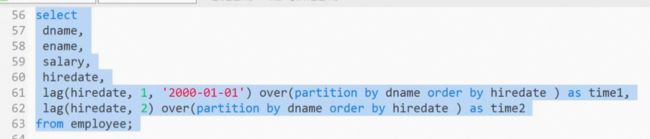
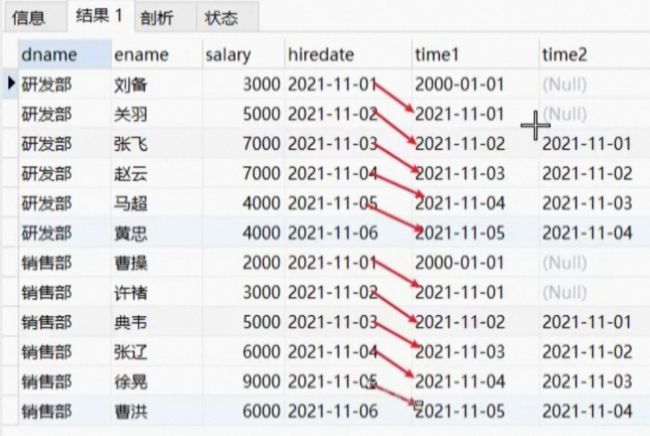
LAG()的用法


LEAD()
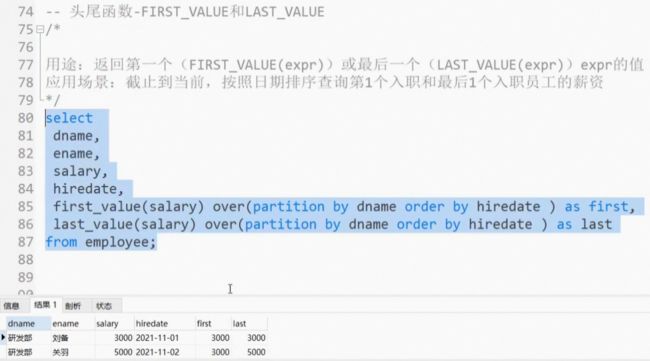
头尾函数

其他函数
NTH_VALUE()
NTILE()


