翻译:Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
目录
- 摘要
- 介绍
- 方法描述:
-
- (1)树亲和生成
- (2)级联过滤生成伪标签
- (3)为未标记的像素分配伪标签
文章地址: Tree Energy Loss: Towards Sparsely Annotated Semantic Segmentation
摘要
稀疏注释语义分割(SASS)的目的是训练一个具有粗粒度(即点、涂鸦和块)监督的分割网络,每幅图像中只有一小部分像素被标记。
在本文中,我们提出了一种新的树能量损失的SASS,通过为未标记像素提供语义指导。树的能量损失表示图像为最小生成树,以模拟低水平和高水平的成对亲和性。通过将这些亲和性依次应用于网络预测,以一种从粗到细的方式生成未标记像素的软伪标签,实现了动态的在线自训练。将树的能量损失与传统的分割损失相结合,既有效且容易整合到现有的框架中。与以前的SASS方法相比,我们的方法不需要多阶段的训练策略、交替的优化程序、额外的监督数据或耗时的后处理,同时在所有的SASS设置中都优于它们。
介绍
SASS分为三个级别:点 涂鸦 块

原图 全标签 点 涂鸦 块(介于全标签和涂鸦之间)
在SASS中,每个图像可以分为标记区域和未标记区域。标记区域可以直接由ground truth监督。对于同一对象的区域,标记像素和未标记像素在低级颜色(图像的RGB值)和高级响应(CNN产生的特征)上具有相似的模式。利用这对相似性,为未标记区域生成软伪标签,并实现在线自训练。
具体来说,引入了一种基于图像的低级和高级相似性的新型树形能量损失(TEL)。在TEL中,两个最小生成树(MSTs)分别构建在低级颜色和高级语义特征上。每个MST都是通过依次消除差异较大的相邻像素之间的连接来获得的,从而分离出较少的相关像素,并保持像素之间的基本关系。然后,将沿MST累积边权值得到的两个结构感知亲和矩阵以级联的方式与网络预测相乘,生成软伪标签。最后,将生成的伪标签分配给未标记的区域。将TEL与标准的分割损失(例如,交叉熵损失)相结合,任何分割网络都可以通过动态在线自我训练从未标记区域学习额外的知识。
TEL容易插入到大多数现有的分割网络中。
树过滤器:
成对关系建模对许多计算机视觉任务具有重要意义。将图像视为无向平面图,其中节点均为像素,相邻节点之间的边通过外观不相似性进行加权,可以根据大量权值去除边来构造最小生成树(MST)。由于相邻像素之间的梯度可以看作是对象边界的强度,因此节点倾向于在树上的同一对象内优先地相互交互。由于MST的结构保持特性,传统的树形滤波器被应用于立体匹配[40,41]、显著目标检测[33]、图像平滑[1]、去噪[27]和抽象[14]中。最近,LTF[26]提出了一种可学习的树过滤器来捕获语义分割的长期依赖性。LTFV2[25]结合了可学习树滤波器和马尔可夫随机场[16],进一步提高了性能。
方法描述:
通过在传统的分割模型S(·)中加入一个辅助分支来实现:
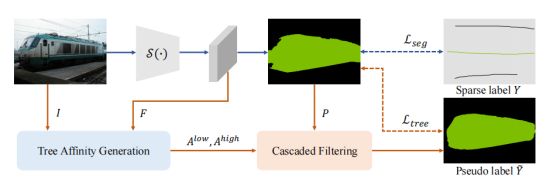
预测的掩码P被分割为已标记部分和未标记部分,分别由分割损失Lseg和树的能量损失Ltree监督,分割分支将稀疏标注的标签Y分配给被标记的像素。
对于辅助分支,从原始图像I和嵌入的特征F中生成成对亲和矩阵 A l o w A^{low} Alow、 A h i g h A^{high} Ahigh,然后利用亲和矩阵 A l o w A^{low} Alow、 A h i g h A^{high} Ahigh采用级联过滤操作对网络预测P进行细化,生成软伪标签Y˜。生成的软标签被分配给未标记的像素。
Tree Energy Loss:
TEL主要包括以下三个步骤:
(1)一个树亲和生成步骤来建模成对关系。
(2)一个用于生成伪标签的级联过滤步骤。
(3)一个软标签分配步骤,用来为未标记的像素分配伪标签。

(1)树亲和生成
树的亲和度生成的过程。首先在给定的低级颜色或高级语义特征上建立一个初始图,然后通过边缘剪枝算法[9]得到MST。在MST上,两个顶点之间的距离是通过沿其超边的边权值之和来计算的。有一个例子用红色虚线表示(如上图)。最后,利用亲和投影将距离映射投影成亲和矩阵。
1.生成两种特征(RGB颜 色和语义特征)的无向图,获取所有相邻边的权重:
图像可以表示为一个无向图G=(V,E),顶点集V由所有像素和两个相邻顶点之间的边缘组成边缘集E,假设顶点i和顶点j在图上相邻,它们之间的低级和高级权值函数可以分别定义为:
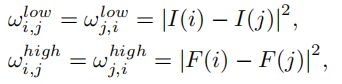
![]() 分别为像素 i i i 的RGB颜色(原图 I I I)和语义特征( F F F), F ( i ) F(i) F(i)是由一个1×1的卷积层产生,由分割模型的分类层之前的特征产生的。
分别为像素 i i i 的RGB颜色(原图 I I I)和语义特征( F F F), F ( i ) F(i) F(i)是由一个1×1的卷积层产生,由分割模型的分类层之前的特征产生的。
2.删除差异较大的相邻点之间的边,获取距离图:
从E中依次去除权值最大的边来构造一个MST。基于MST的拓扑结构,同一对象内的顶点具有相似的特征表示,并倾向于优先相互交互。
MST的两个顶点之间的距离可以通过它们连接边的权和来计算。而顶点之间的最短路径的距离,记为超边E,形成了MST的距离图,

j、k和m是顶点,∗∈{low,high},为了捕获顶点之间的长期关系
3.映射为亲和矩阵:
将距离映射映射到正亲和矩阵:

σ是用于调节颜色信息的预设调节常量值。给定一个训练图像,低水平亲和力 A l o w A^{low} Alow是静态的,而高水平亲和力 A h i g h A^{high} Ahigh在训练过程中是动态的。它们在不同的特征级别上捕获成对的关系。通过共同利用它们,可以学习到互补的知识。
(2)级联过滤生成伪标签
从网络预测中生成伪标签Y˜:
![]()
P为softmax操作后的预测。通过连续地与低层次和高级的亲和度相乘,网络预测可以以粗到细的方式进行细化,产生高质量的软伪标签。通过级联过滤生成的伪标签可以比原始预测保持更清晰的语义边界。
过滤操作F(·)表示如下:
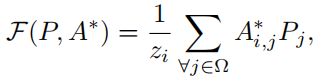
Ω=ΩL∪ΩU是所有像素的完整集合(ΩL:标注的像素 ΩU:未标注的像素)![]() 是归一化项。
是归一化项。
(3)为未标记的像素分配伪标签
软标签分配:
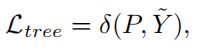
δ是一个标签赋值函数,度量预测概率P和伪标签Y˜之间的距离(可以是L1距离、L2距离等)。
TEL的最终形成就可以描述如下:

TEL从网络预测中生成软标签。因此,数据驱动的模型学习过程将有利于我们的在线自我训练策略。