Nebula 分布式图数据库介绍
1 什么是图(Graph)
本文介绍的图和日常生活中常见的图片有所不同。通常,在英文中,为了区分这两种不同的图,前者会称为 Image,后者称为 Graph。在中文中,前者会强调为“图片”,后者会强调为“拓扑图”、“网络图”等。
一张图(Graph)由一些小圆点(称为顶点或节点,即 Vertex)和连接这些圆点的直线或曲线(称为边,即 Edge)组成。“图(Graph)“这一名词最早由西尔维斯特在 1878 年提出。
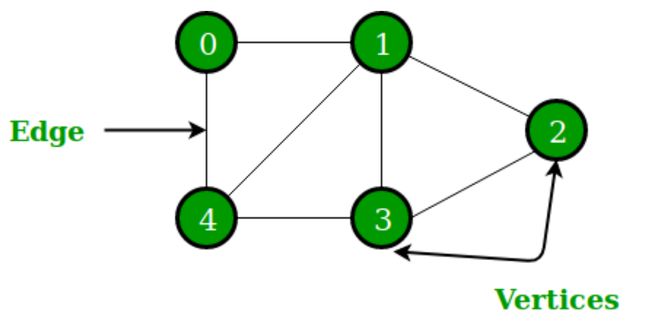
图还可以分为无向图和有向图。

2 什么是图数据库
图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。

3 图数据库的应用例子
例如企查查或者 BOSS 直聘这类的公司,用图来建模商业股权关系网络。这个网络中,点通常是一个自然人或者是一家企业,边通常是某自然人与某企业之间的股权关系。点上的属性可以是自然人姓名、年龄、身份证号等。边上的属性可以是投资金额、投资时间、董监高等职位关系。
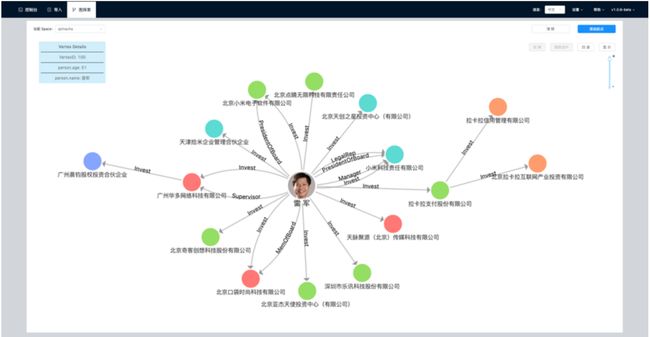
图关系还可以是类似《权力的游戏》这样电视剧中的人物关系网:点为人物,边为人物之间的互动关系;点的属性为人物姓名、年龄、阵营等,边的属性(距离)为两个人物之间的互动次数,互动越频繁距离越近。

4 Nebula Graph 概念介绍
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。

4.1 Nebula 数据模型
- 图空间(Space):图空间是 Nebula Graph 中彼此隔离的图数据集合,与 MySQL 中的 database 概念类似。
- 点(Vertex):点用来保存实体对象,特点如下:
- 点是用点标识符(
VID或称为Vertex ID)标识的。VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)。 - 点必须有至少一个 Tag,也可以有多个 Tag,但不能没有 Tag。
- 点是用点标识符(
- 边(Edge):边是用来连接点的,表示两个点之间的关系或行为,特点如下:
- 两点之间可以有多条边。
- 边是有方向的,不存在无向边。
- 四元组
<起点VID、Edge type、边排序值(Rank)、终点VID>用于唯一标识一条边。边没有 EID。 - 一条边有且仅有一个 Edge type。
- 一条边有且仅有一个 rank。其为 int64,默认为 0。
- 标签(Tag):点的类型,定义了一组描述点类型的属性。
- 边类型(Edge type):边的类型,定义了一组描述边的类型的属性。Tag 和 Edge type 的作用,类似于关系型数据库中“点表”和“边表”的表结构。
- 属性(Properties):属性是指以键值对(Key-value pair)形式存储的信息。
4.2 Nebula 架构总览
Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
- Graph 服务主要负责处理查询请求,包括解析查询语句、校验语句、生成执行计划以及按照执行计划执行四个大步骤。
- Meta 服务负责管理元数据信息,包括用户账号和权限信息、分片位置信息、图空间、Schema 信息、作业信息等等。
- Storage 服务负责数据的存储,通过 Raft 协议保证数据多副本之间的一致性。

4.3 Nebula 快速入门
本文将介绍在 Centos7 操作系统上通过 RPM 安装 Nebula。
4.3.1 安装 Nebula Graph
下载 RPM 安装包。
wget https://oss-cdn.nebula-graph.com.cn/package/2.6.1/nebula-graph-2.6.1.el7.x86_64.rpm
安装 RPM 包。
sudo rpm -ivh nebula-graph-2.6.1.el7.x86_64.rpm
4.3.2 启动 Nebula Graph 服务
Nebula Graph 使用脚本 nebula.service 管理服务,包括启动、停止、重启、中止和查看。
nebula.service 的默认路径是 /usr/local/nebula/scripts,如果修改过安装路径,请使用实际路径。
nebula.service 脚本的语法如下。
sudo /usr/local/nebula/scripts/nebula.service
[-v] [-c <config_file_path>]
<start|stop|restart|kill|status>
<metad|graphd|storaged|all>
参数说明如下。

我们使用以下命令启用 Nebula Graph 的所有服务,包括 Meta 服务、Graph 服务和 Storage 服务。
sudo /usr/local/nebula/scripts/nebula.service start all
查看所有服务的状态,可以看到此时 Nebula Graph 的服务都已经正常启动。
sudo /usr/local/nebula/scripts/nebula.service status all
# 返回结果
[WARN] The maximum files allowed to open might be too few: 1024
[INFO] nebula-metad(de03025): Running as 62568, Listening on 9559
[INFO] nebula-graphd(de03025): Running as 62658, Listening on 9669
[INFO] nebula-storaged(de03025): Running as 62673, Listening on 9779
4.3.3 连接 Nebula Graph
Nebula Graph 支持多种类型客户端,包括 CLI 客户端、GUI 客户端和流行编程语言开发的客户端,详情可以查看 Nebula Graph 生态工具概览。
接下来将介绍如何使用原生 CLI 客户端 Nebula Console 来连接 Nebula Graph 数据库。
首先在 Github 的 Nebula Console 下载页面 根据机器的系统和 CPU 架构选择对应的二进制文件。我使用的机器的 CPU 架构是 x86_64 的,因此这里选择下载 amd64 的二进制文件。
为了方便使用,将文件重命名为 nebula-console。
wget https://github.com/vesoft-inc/nebula-console/releases/download/v2.6.0/nebula-console-linux-amd64-v2.6.0
mv nebula-console-linux-amd64-v2.6.0 nebula-console
为 nebula-console 二进制文件赋予可执行权限。
chmod +x nebula-console
nebula-console 的语法如下。
./nebula-console -addr <ip> -port <port> -u <username> -p <password> [-t 120] [-e "nGQL_statement" | -f filename.nGQL]
参数说明如下。

使用以下命令连接 Nebula Graph。
./nebula-console -addr 192.168.1.12 -port 9669 -u root -p nebula
看到以下输出说明连接成功。

4.3.4 使用常用命令
接下来将使用下图的数据集演示 Nebula Graph 基础的操作语法,包括用于 Schema 创建和常用增删改查操作的语句。nGQL(Nebula Graph Query Language)是 Nebula Graph 使用的的声明式图查询语言,支持灵活高效的图模式,而且 nGQL 是为开发和运维人员设计的类 SQL 查询语言,易于学习。
下表为 basketballplayer 数据集的结构示例,包括两种类型的点(player、team)和两种类型的边(serve、follow)。

本文将使用下图的数据集演示基础操作的语法。

4.3.4.1 创建和选择图空间
执行如下语句创建名为basketballplayer的图空间。
(root@nebula) [(none)]> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
选择图空间basketballplayer。
(root@nebula) [(none)]> USE basketballplayer;
查看创建的图空间。
(root@nebula) [basketballplayer]> SHOW SPACES;
+--------------------+
| Name |
+--------------------+
| "basketballplayer" |
+--------------------+
4.3.4.2 创建 Tag 和 Edge type
Tag 和 Edge type 的作用,类似于关系型数据库中“点表”和“边表”的表结构。创建 Tag: player 和 team ,以及 Edge type: follow 和 serve 。
CREATE TAG player(name string, age int);
CREATE TAG team(name string);
CREATE EDGE follow(degree int);
CREATE EDGE serve(start_year int, end_year int);
4.3.4.3 插入点和边
可以使用 INSERT 语句,基于现有的 Tag 插入点,或者基于现有的 Edge type 插入边。
插入代表球员和球队的点。
INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
插入代表球员和球队之间关系的边。
INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
4.3.4.4 创建索引
MATCH 和 LOOKUP 语句的执行都依赖索引,但是索引会导致写性能大幅降低(降低 90% 甚至更多)。请不要随意在生产环境中使用索引,除非很清楚使用索引对业务的影响。
必须为“已写入但未构建索引”的数据重建索引,否则无法在 MATCH 和 LOOKUP 语句中返回这些数据,参见 重建索引。
原生索引可以基于指定的属性查询数据,创建原生索引分为以下 3 种情况:
- 创建 Tag/Edge type 索引。Tag 索引和 Edge type 索引应用于和Tag、Edge type 自身相关的查询,例如用
LOOKUP查找有 Tagplayer的所有点。 - 创建单属性索引。“属性索引”应用于基于属性的查询,例如基于属性
age找到age == 19的所有的点。 - 创建复合属性索引(遵循"最左匹配原则")。
关于创建索引的详细内容可以查看 CREATE INDEX
4.3.4.4.1 为 TAG 创建索引
为 TAG team 的创建索引,需要重建索引确保对已存在数据生效,注意在重建索引之前我们等待 20s,因为新创建的索引并不会立刻生效,因为创建索引是异步实现的,Nebula Graph 需要在下一个心跳周期才能完成索引的创建。
# 为 Tag team 创建索引 team_index_1。
CREATE TAG INDEX team_index_1 ON team();
# 重建索引确保能对已存在数据生效。
:sleep 20
REBUILD TAG INDEX team_index_1;
为 TAG player 的 name 属性创建单属性索引,为 name 和 age 属性创建复合属性索引。
# 为 Tag player 的 name 属性创建单属性索引 player_index_1。
# 索引长度为10。即只使用属性 name 的前 10 个字符来创建索引。
CREATE TAG INDEX player_index_1 ON player(name(20));
# 重建索引确保能对已存在数据生效。
REBUILD TAG INDEX player_index_1;
# 为 Tag player 的 name 和 age 属性创建复合属性索引 player_index_2。
CREATE TAG INDEX player_index_2 ON player(name,age);
# 重建索引确保能对已存在数据生效。
:sleep 20
REBUILD TAG INDEX player_index_2;
新创建的索引并不会立刻生效,创建新的索引并尝试立刻使用(例如
LOOKUP或者REBUILD INDEX)通常会失败(报错can't find xxx in the space)。因为创建步骤是异步实现的,Nebula Graph 要在下一个心跳周期才能完成索引的创建。可以使用如下方法之一:
- 1.在
SHOW TAG/EDGE INDEXES语句的结果中查找到新的索引。 - 2.等待两个心跳周期,例如 20 秒。如果需要修改心跳间隔,请为所有配置文件修改参数
heartbeat_interval_secs。
4.3.4.4.2 为 EDGE type 创建索引
为 EDGE type 创建索引的方式和点相同,只是把关键字改成 EDGE 即可。
# 为 EDGE follow 的 degree 属性创建索引,并重建索引。
CREATE EDGE INDEX follow_index_1 on follow(degree);
:sleep 20
REBUILD EDGE INDEX follow_index_1;
# 为 EDGE serve 创建索引,并重建索引。
CREATE EDGE INDEX serve_index_1 on serve();
:sleep 20
REBUILD EDGE INDEX serve_index_1;
# 为 EDGE serve 创建复合属性索引,并重建索引。
CREATE EDGE INDEX serve_index_2 on serve(start_year,end_year);
:sleep 20
REBUILD EDGE INDEX serve_index_2;
4.3.4.5 查看索引
查看为 TAG player 和 team 创建的索引。
(root@nebula) [basketballplayer]> SHOW TAG INDEXES;
+------------------+----------+-----------------+
| Index Name | By Tag | Columns |
+------------------+----------+-----------------+
| "player_index_1" | "player" | ["name"] | # 单属性索引
| "player_index_2" | "player" | ["name", "age"] | # 复合属性索引
| "team_index_1" | "team" | [] | # TAG 索引
+------------------+----------+-----------------+
查看为 EDGE follow 和 serve 创建的索引。
(root@nebula) [basketballplayer]> SHOW EDGE INDEXES;
+------------------+----------+----------------------------+
| Index Name | By Edge | Columns |
+------------------+----------+----------------------------+
| "follow_index_1" | "follow" | ["degree"] | # 单属性索引
| "serve_index_1" | "serve" | [] | # EDGE 索引
| "serve_index_2" | "serve" | ["start_year", "end_year"] | # 复合属性索引
+------------------+----------+----------------------------+
4.3.4.6 删除索引
删除 TAG player 的索引 player_index_2。
(root@nebula) [basketballplayer]> DROP TAG INDEX player_index_2;
删除 EDGE serve 的索引 serve_index_2。
(root@nebula) [basketballplayer]> DROP EDGE INDEX serve_index_2;
4.3.4.7 查询数据
查询数据主要有以下 4 种语句:
- GO 语句可以根据指定的条件遍历数据库。
GO语句从一个或多个点开始,沿着一条或多条边遍历,可以使用YIELD子句中指定的返回的信息。 - FETCH 语句可以获得点或边的属性。
- LOOKUP 语句是基于索引的,和
WHERE子句一起使用,查找符合特定条件的数据。 - MATCH 语句是查询图数据最常用的,与
GO或LOOKUP等其他查询语句相比,MATCH的语法更灵活。MATCH 语句可以描述各种图模式,它依赖索引去匹配 Nebula Graph 中的数据模型。
4.3.4.7.1 GO 语句示例
从 TAG player 中 VID 为 player101 的球员开始,沿着边 follow 找到连接的球员。
(root@nebula) [basketballplayer]> GO FROM "player101" OVER follow;
+-------------+
| follow._dst |
+-------------+
| "player100" |
| "player102" |
+-------------+
4.3.4.7.2 FETCH 语句示例
查询 TAG player 中 VID 为 player100 的球员的属性值。
(root@nebula) [basketballplayer]> FETCH PROP ON player "player100";
+----------------------------------------------------+
| vertices_ |
+----------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
+----------------------------------------------------+
获取连接 player102 和 team203 的边 serve 的所有属性值。
(root@nebula) [basketballplayer]> FETCH PROP ON serve "player102" -> "team203";
+-----------------------------------------------------------------------+
| edges_ |
+-----------------------------------------------------------------------+
| [:serve "player102"->"team203" @0 {end_year: 2015, start_year: 2006}] |
+-----------------------------------------------------------------------+
4.3.4.7.3 LOOKUP 语句示例
列出 TAG player 的所有 VID。
(root@nebula) [basketballplayer]> LOOKUP ON player;
+-------------+
| VertexID |
+-------------+
| "player100" |
| "player102" |
| "player103" |
+-------------+
列出 EDGE serve 所有边的起始点、目的点和 rank。
(root@nebula) [basketballplayer]> LOOKUP ON serve;
+-------------+-----------+---------+
| SrcVID | DstVID | Ranking |
+-------------+-----------+---------+
| "player101" | "team204" | 0 |
| "player102" | "team203" | 0 |
+-------------+-----------+---------+
LOOKUP 也可以基于 where 条件进行过滤,例如在 EDGE serve 中查询 start_year == 2006 的属性值。
(root@nebula) [basketballplayer]> LOOKUP ON serve where serve.start_year == 2006;
+-------------+-----------+---------+
| SrcVID | DstVID | Ranking |
+-------------+-----------+---------+
| "player102" | "team203" | 0 |
+-------------+-----------+---------+
4.3.4.7.4 MATCH 语句示例
通过 MATCH 语句分别查询 TAG player 和 team 的属性值。
# 查询 Tag 为 player 的点的属性值
(root@nebula) [basketballplayer]> MATCH (x:player) return x;
+-----------------------------------------------------------+
| x |
+-----------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim Duncan"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
# 查询 Tag 为 team 的点的属性值
(root@nebula) [basketballplayer]> MATCH (x:team) return x;
+------------------------------------------+
| x |
+------------------------------------------+
| ("team203" :team{name: "Trail Blazers"}) |
| ("team204" :team{name: "Spurs"}) |
+------------------------------------------+
也可以根据索引所在的属性进行查询,例如我们查询 TAG player 的 name 字段名为 Tony parker 的属性值。
(root@nebula) [basketballplayer]> MATCH (v:player{name:"Tony Parker"}) RETURN v;
+-----------------------------------------------------+
| v |
+-----------------------------------------------------+
| ("player101" :player{age: 36, name: "Tony Parker"}) |
+-----------------------------------------------------+
由于 TAG team 上的 name 属性并没有建立索引,因此无法根据 name 属性进行查询。
(root@nebula) [basketballplayer]> MATCH (v:team{name:'Spurs'}) RETURN v;
[ERROR (-1005)]: IndexNotFound: No valid index found
使用 MATCH 查询 EDGE serve 的属性值。
(root@nebula) [basketballplayer]> MATCH ()-[e:serve]-() RETURN e;
+-----------------------------------------------------------------------+
| e |
+-----------------------------------------------------------------------+
| [:serve "player101"->"team204" @0 {end_year: 2018, start_year: 1999}] |
| [:serve "player102"->"team203" @0 {end_year: 2015, start_year: 2006}] |
+-----------------------------------------------------------------------+
4.3.4.7.5 实际的查询例子
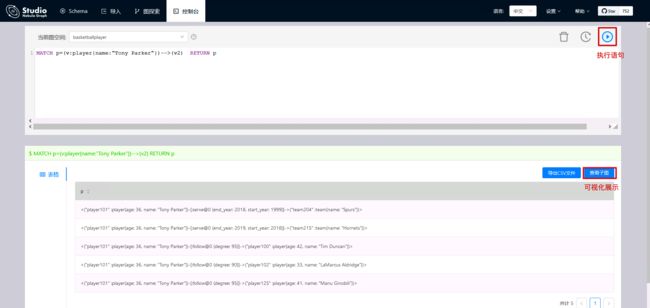
使用以下语句查询和 Tony Parker 有关的球员和球队。
(root@nebula) [basketballplayer]> MATCH p=(v:player{name:"Tony Parker"})-->(v2) RETURN p
+-------------------------------------------------------------------------------------------------------------------------------------------+
| p |
+-------------------------------------------------------------------------------------------------------------------------------------------+
| <("player101" :player{age: 36, name: "Tony Parker"})-[:serve@0 {end_year: 2018, start_year: 1999}]->("team204" :team{name: "Spurs"})> |
| <("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 95}]->("player100" :player{age: 42, name: "Tim Duncan"})> |
| <("player101" :player{age: 36, name: "Tony Parker"})-[:follow@0 {degree: 90}]->("player102" :player{age: 33, name: "LaMarcus Aldridge"})> |
+-------------------------------------------------------------------------------------------------------------------------------------------+
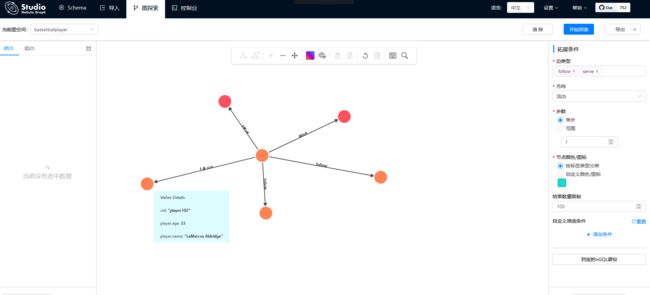
和 Tony Parker 有关系的球员和球队在下图中用绿色方框标识。
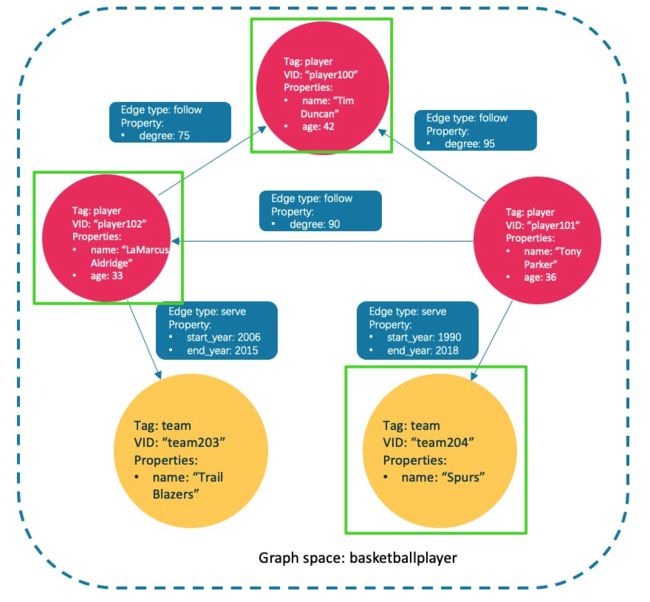
4.3.4.8 修改点和边
用户可以使用 UPDATE 语句或 UPSERT 语句修改现有数据。UPSERT 是 UPDATE 和 INSERT 的结合体。当使用 UPSERT 更新一个点或边,如果它不存在,数据库会自动插入一个新的点或边。
首先查询 TAG player 现在的属性值。
(root@nebula) [basketballplayer]> match (n:player) return n;
+-----------------------------------------------------------+
| n |
+-----------------------------------------------------------+
| ("player100" :player{age: 42, name: "Tim"}) |
| ("player101" :player{age: 36, name: "Tony Parker"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
+-----------------------------------------------------------+
用 UPDATE 修改 VID 为 player100 的球员的 name 属性,然后用 FETCH 语句检查结果。
(root@nebula) [basketballplayer]> UPDATE VERTEX "player100" SET player.name = "Tim";
(root@nebula) [basketballplayer]> FETCH PROP ON player "player100";
+---------------------------------------------+
| vertices_ |
+---------------------------------------------+
| ("player100" :player{age: 42, name: "Tim"}) |
+---------------------------------------------+
执行 UPSERT 语句,分别对已存在的 player101 和未存在的 player103 进行操作,通过 MATCH 查询可以看到在 UPSERT 修改了原本 player101 的值,新插入的 player103。
(root@nebula) [basketballplayer]> UPSERT VERTEX "player101" SET player.name = "CRIS", player.age = 18;
(root@nebula) [basketballplayer]> UPSERT VERTEX "player103" SET player.name = "THOMAS", player.age = 20;
(root@nebula) [basketballplayer]> match (n:player) return n;
+-----------------------------------------------------------+
| n |
+-----------------------------------------------------------+
| ("player101" :player{age: 18, name: "CRIS"}) |
| ("player100" :player{age: 42, name: "Tim"}) |
| ("player102" :player{age: 33, name: "LaMarcus Aldridge"}) |
| ("player103" :player{age: 20, name: "THOMAS"}) |
+-----------------------------------------------------------+
4.3.4.9 删除点和边
删除点。
nebula> DELETE VERTEX "player101";
删除边。
nebula> DELETE EDGE follow "player101" -> "team204";
4.3.4.10 删除 TAG 和 EDGE
删除 TAG/EDGE 前要确保 TAG/EDGE 不包含任何索引,否则 DROP TAG 时会报冲突错误 [ERROR (-8)]: Conflict!
删除 TAG。
# 删除 TAG 的索引
DROP TAG INDEX player_index_1;
DROP TAG INDEX team_index_1;
# 删除 TAG
DROP TAG player;
DROP TAG team;
删除 EDGE。
# 删除 EDGE 的索引
DROP EDGE INDEX follow_index_1
DROP EDGE INDEX serve_index_1
# 删除 EDGE
DROP EDGE follow;
DROP EDGE serve;
5 部署 Nebula Graph 集群
在生产环境中,为了保证服务的高可用和高性能,通常会以集群的方式部署 Nebula Graph。
5.1 机器规划
在 3 台服务器上都部署 Graph 服务、Meta 服务和 Storage 服务,这 3 个服务是 Nebula Graph 的核心组件。在 ydt-net-nebula1 服务器上部署 Nebula Dashboard 和 Nebula Graph Studio 服务用于可视化操作和监控。
| 主机名 | IP 地址 | 角色 |
|---|---|---|
| ydt-net-nebula1 | 11.8.38.149 | Nebula Graph,Nebula Dashboard,Nebula Graph Studio |
| ydt-net-nebula2 | 11.8.38.150 | Nebula Graph |
| ydt-net-nebula3 | 11.8.38.151 | Nebula Graph |
5.2 修改配置文件
分别修改 3 台机器的 nebula-graphd.conf,nebula-storaged.conf,nebula-metad.conf 配置文件,这 3 个配置文件中都只需要修改 --meta_server_addrs 和 __local_ip 两个参数。
--meta_server_addrs参数表示的 Meta 服务的地址和端口,所有机器该参数值都一样。--local_ip表示本机在哪个 IP 监听服务,每台机器的需要改成自己的本身的 IP 地址。

5.3 启动服务
在 3 台服务器上使用以下命令启用 Nebula Graph 的所有服务,包括 Meta 服务、Graph 服务和 Storage 服务。
sudo /usr/local/nebula/scripts/nebula.service start all
5.4 验证 Nebula 集群状态
通过 Nebula Console 连接任何一个已启动 Graph 服务的机器,执行命令 SHOW HOSTS 检查集群状态。
# 连接 Graph 服务
./nebula-console --addr 11.8.38.149 --port 9669 -u root -p nebula
# 查看集群状态
(root@nebula) [(none)]> SHOW HOSTS;
+---------------+------+----------+--------------+--------------------------------------------+--------------------------------------------+
| Host | Port | Status | Leader count | Leader distribution | Partition distribution |
+---------------+------+----------+--------------+--------------------------------------------+--------------------------------------------+
| "11.8.38.149" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
| "11.8.38.150" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
| "11.8.38.151" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
| "Total" | | | 0 | "No valid partition" | "No valid partition" |
+---------------+------+----------+--------------+--------------------------------------------+--------------------------------------------+
6 安装 Nebula Dashboard
Nebula Dashboard 是一款用于监控 Nebula Graph 集群中机器和服务状态的可视化工具。
- 监控集群中所有机器的状态,包括 CPU、内存、负载、磁盘和流量。
- 监控集群中所有服务的信息,包括服务 IP 地址、版本和监控指标(例如查询数量、查询延迟、心跳延迟等)。
- 监控集群本身的信息,包括集群的服务信息、分区信息、配置和长时任务。
Nebula Dashboard 由以下 5 种服务组成,通过 这个地址 下载压缩包并解压后可以在目录 nebula-graph-dashboard 看到 5 个子目录,分别对应 5 个服务的目录。除了 node-exporter 服务需要在 3 台服务器上都部署,其余服务只需要在 ydt-net-nebula1 上部署。

6.1 部署 node-exporter 服务
在目录 node-exporter 内执行如下命令启动服务:
nohup ./node-exporter --web.listen-address=":9100" &
6.2 部署 nebula-stats-exporter 服务
在目录 nebula-stats-exporter 内修改文件 config.yaml,配置所有服务的 HTTP 端口。
version: v0.0.2
nebulaItems:
- instanceName: metad0
endpointIP: 11.8.38.149
endpointPort: 9559
componentType: metad
- instanceName: metad1
endpointIP: 11.8.38.150
endpointPort: 9559
componentType: metad
- instanceName: metad2
endpointIP: 11.8.38.151
endpointPort: 9559
componentType: metad
- instanceName: graphd0
endpointIP: 11.8.38.149
endpointPort: 9669
componentType: graphd
- instanceName: graphd1
endpointIP: 11.8.38.150
endpointPort: 9669
componentType: graphd
- instanceName: graphd2
endpointIP: 11.8.38.151
endpointPort: 9669
componentType: graphd
- instanceName: storaged0
endpointIP: 11.8.38.149
endpointPort: 9779
componentType: storaged
- instanceName: storaged1
endpointIP: 11.8.38.150
endpointPort: 9779
componentType: storaged
- instanceName: storaged2
endpointIP: 11.8.38.151
endpointPort: 9779
componentType: storaged
执行如下命令启动服务:
nohup ./nebula-stats-exporter --listen-address=":9200" --bare-metal --bare-metal-config=./config.yaml &
6.3 部署 prometheus 服务
在目录 prometheus 内修改文件 prometheus.yaml,配置 node-exporter 服务和 nebula-stats-exporter 服务的 IP 地址和端口。
global:
scrape_interval: 5s # 收集监控数据的间隔时间。默认为1分钟。
evaluation_interval: 5s # 告警规则扫描时间间隔。默认为1分钟。
scrape_configs:
- job_name: 'node-exporter'
static_configs:
- targets: [
'11.8.38.149:9100', # node-exporter 服务的 IP 地址和端口。
'11.8.38.150:9100',
'11.8.38.151:9100'
]
- job_name: 'nebula-stats-exporter'
static_configs:
- targets: [
'11.8.38.149:9200', # nebula-stats-exporter 服务的 IP 地址和端口。
]
执行如下命令启动服务:
nohup ./prometheus --config.file=./prometheus.yaml &
6.4 部署 nebula-http-gateway 服务
在目录 nebula-http-gateway 内执行如下命令启动服务:
nohup ./nebula-httpd &
6.5 部署 nebula-graph-dashboard 服务
在目录 nebula-graph-dashboard/static/ 内修改文件custom.json,配置 Graph 服务的 IP 地址和端口。
{
"connection": {
"ip": "11.8.38.149",
"port": 9669
},
"alias": {
"ip:port": "instance1"
},
"chartBaseLine": {
}
}
在目录 nebula-graph-dashboard 内执行如下命令启动服务:
npm run start
6.6 访问 Nebula Dashboard 界面
在浏览器输入 http://11.8.38.149:7003 访问 Graph Dashboard 界面。用户名: root,密码: nebula。在 Nebula Dashboard 界面上我们可以看到 CPU,内存,磁盘使用率和上下行流量等信息。

7 安装 Nebula Graph Studio
Nebula Graph Studio 是一款可以通过 Web 访问的图数据库开源可视化工具,搭配 Nebula Graph 内核使用,提供构图、数据导入、编写 nGQL 查询、图探索等一站式服务。
7.1 前提准备
在安装 Nebula Graph Studio 之前需要确保安装版本为 v10.16.0 + 以上的 Node.js。
# 下载并解压 Node 压缩包
wget https://nodejs.org/dist/v16.13.0/node-v16.13.0-linux-x64.tar.xz
tar -xzvf node-v16.13.0-linux-x64.tar.xz
# `node` 及 `npm` 命令需要安装在 `/usr/bin/`目录下,以防出现 RPM 安装时 node 命令找不到的情况,可以使用以下命令建立软连接。
ln -s /root/node-v16.13.0-linux-x64/bin/node /usr/bin/node
ln -s /root/node-v16.13.0-linux-x64/bin/npm /usr/bin/npm
7.2 部署 Nebula Graph Studio
下载 RPM 安装包。
wget https://oss-cdn.nebula-graph.com.cn/nebula-graph-studio/3.1.0/nebula-graph-studio-3.1.0.x86_64.rpm
使用 sudo rpm -ivh 命令安装 RPM 包。
sudo rpm -ivh nebula-graph-studio-3.1.0.x86_64.rpm
当屏幕返回以下信息时,表示 PRM 版 Studio 已经成功启动。
egg started on http://0.0.0.0:7001 nohup: 把输出追加到"nohup.out"
7.3 访问 Nebula Graph Studio
在浏览器地址栏输入 http://11.8.38.149:7001 访问 Nebula Graph Studio 界面,填写 Nebula Graph 数据库的连接信息后,点击连接按钮。

如果能看到如下图所示的界面,表示已经成功连接到 Nebula Graph 数据库。

我们可以在控制台中执行 nGQL 语句。
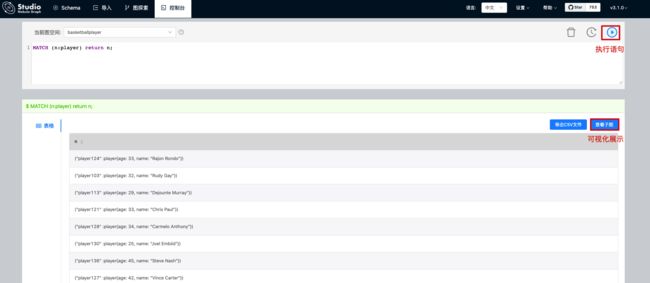
执行命令的结果可以通过可视化的方式进行展现。
接下来通过查询和 Tony Parker 有关系的球员,同样可以以可视化的方式展示结果。
8 通过 Nebula Exchange 导入数据
Nebula Exchange 是一款 Apache Spark 应用,用于在分布式环境中将集群中的数据批量迁移到 Nebula Graph 中,能支持多种不同格式(CSV,JSON,Parquet,Neo4j, MySQL 等等)的批式数据和流式数据的迁移。
接下来将用一个示例说明如何使用 Nebula Exchange 将存储在 HDFS 或本地的 CSV 文件数据导入 Nebula Graph。关于本地 CSV 的导入也可以使用 Nebula Import,详细信息参见 使用 Nebula Importer。
8.1 下载示例数据
下载 basketballplayer数据集。
解压后可以看到有 4 张表,数据结构和 Nebula 快速入门章节中介绍的一样,有 player 和 team 两个 TAG,follow 和 serve 两个 EDGE type。

8.2 在 Nebula Graph 中创建 Schema
使用 Nebula Console 创建一个图空间 basketballplayer,并创建一个 Schema,如下所示。
## 创建图空间
nebula> CREATE SPACE basketballplayer \
(partition_num = 10, \
replica_factor = 1, \
vid_type = FIXED_STRING(30));
## 选择图空间basketballplayer
nebula> USE basketballplayer;
## 创建Tag player
nebula> CREATE TAG player(name string, age int);
## 创建Tag team
nebula> CREATE TAG team(name string);
## 创建Edge type follow
nebula> CREATE EDGE follow(degree int);
## 创建Edge type serve
nebula> CREATE EDGE serve(start_year int, end_year int);
8.3 修改 Nebula Exchange 配置文件
在 /root/csv_application.conf 创建 Nebula Exchange 配置文件,设置 CVS 数据源相关配置。本地和 HDFS 导入 CSV 除了 path 路径不同以外,其余配置都一样。如果你使用的是 basketballplayer 数据集,那么只需要修改 Nebula 的连接信息和 CSV path 路径即可。
{
# Spark相关配置
spark: {
app: {
name: Nebula Exchange 2.6.0
}
driver: {
cores: 1
maxResultSize: 1G
}
executor: {
memory:1G
}
cores {
max: 16
}
}
# Nebula Graph相关配置
nebula: {
address:{
# 指定Graph服务和所有Meta服务的IP地址和端口。
# 如果有多台服务器,地址之间用英文逗号(,)分隔。
# 格式: "ip1:port","ip2:port","ip3:port"
graph:["11.8.38.149:9669","11.8.38.150:9669","11.8.38.151:9669"]
meta:["11.8.38.149:9559","11.8.38.150:9559","11.8.38.151:9559"]
}
# 指定拥有Nebula Graph写权限的用户名和密码。
user: root
pswd: nebula
# 指定图空间名称。
space: basketballplayer
connection {
timeout: 3000
retry: 3
}
execution {
retry: 3
}
error: {
max: 32
output: /tmp/errors
}
rate: {
limit: 1024
timeout: 1000
}
}
# 处理点
tags: [
# 设置Tag player相关信息。
{
# 指定Nebula Graph中定义的Tag名称。
name: player
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的路径。
# 如果文件存储在HDFS上,用双引号括起路径,以hdfs://开头,例如"hdfs://ip:port/xx/xx"。
# 如果文件存储在本地,用双引号括起路径,以file://开头,例如"file:///tmp/xx.csv"。
#path: "hdfs://192.168.*.*:9000/data/vertex_player.csv"
path: "/root/dataset/vertex_player.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c1, _c2]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [age, name]
# 指定一个列作为VID的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.6.1仅支持字符串或整数类型的VID。
vertex: {
field:_c0
# policy:hash
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大点数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 设置Tag team相关信息。
{
# 指定Nebula Graph中定义的Tag名称。
name: team
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的路径。
# 如果文件存储在HDFS上,用双引号括起路径,以hdfs://开头,例如"hdfs://ip:port/xx/xx"。
# 如果文件存储在本地,用双引号括起路径,以file://开头,例如"file:///tmp/xx.csv"。
# path: "hdfs://192.168.*.*:9000/data/vertex_team.csv"
path: "/root/dataset/vertex_team.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c1]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [name]
# 指定一个列作为VID的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.6.1仅支持字符串或整数类型的VID。
vertex: {
field:_c0
# policy:hash
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大点数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 如果需要添加更多点,请参考前面的配置进行添加。
]
# 处理边
edges: [
# 设置Edge type follow相关信息。
{
# 指定Nebula Graph中定义的Edge type名称。
name: follow
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的路径。
# 如果文件存储在HDFS上,用双引号括起路径,以hdfs://开头,例如"hdfs://ip:port/xx/xx"。
# 如果文件存储在本地,用双引号括起路径,以file://开头,例如"file:///tmp/xx.csv"。
# path: "hdfs://192.168.*.*:9000/data/edge_follow.csv"
path: "/root/dataset/edge_follow.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c2]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [degree]
# 指定一个列作为起始点和目的点的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.6.1仅支持字符串或整数类型的VID。
source: {
field: _c0
}
target: {
field: _c1
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 指定一个列作为rank的源(可选)。
#ranking: rank
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大边数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
# 设置Edge type serve相关信息。
{
# 指定Nebula Graph中定义的Edge type名称。
name: serve
type: {
# 指定数据源,使用CSV。
source: csv
# 指定如何将点数据导入Nebula Graph:Client或SST。
sink: client
}
# 指定CSV文件的路径。
# 如果文件存储在HDFS上,用双引号括起路径,以hdfs://开头,例如"hdfs://ip:port/xx/xx"。
# 如果文件存储在本地,用双引号括起路径,以file://开头,例如"file:///tmp/xx.csv"。
# path: "hdfs://192.168.*.*:9000/data/edge_serve.csv"
path: "/root/dataset/edge_serve.csv"
# 如果CSV文件没有表头,使用[_c0, _c1, _c2, ..., _cn]表示其表头,并将列指示为属性值的源。
# 如果CSV文件有表头,则使用实际的列名。
fields: [_c2,_c3]
# 指定Nebula Graph中定义的属性名称。
# fields与nebula.fields的顺序必须一一对应。
nebula.fields: [start_year, end_year]
# 指定一个列作为起始点和目的点的源。
# vertex的值必须与上述fields或者csv.fields中的列名保持一致。
# 目前,Nebula Graph 2.6.1仅支持字符串或整数类型的VID。
source: {
field: _c0
}
target: {
field: _c1
}
# 指定的分隔符。默认值为英文逗号(,)。
separator: ","
# 指定一个列作为rank的源(可选)。
#ranking: _c5
# 如果CSV文件有表头,请将header设置为true。
# 如果CSV文件没有表头,请将header设置为false。默认值为false。
header: false
# 指定单批次写入Nebula Graph的最大边数量。
batch: 256
# 指定Spark分片数量。
partition: 32
}
]
# 如果需要添加更多边,请参考前面的配置进行添加。
}
8.4 向 Nebula Graph 导入数据
通过 这个连接 下载编译完成的 Nebula Exchange jar 包。

在 Spark 官方下载页面下载 Spark 2.4.7 版本压缩包。

运行 spark-submit 以 local 方式在本地运行 Spark 程序将 CSV 文件数据导入到 Nebula Graph 中。
/root/spark-2.4.7-bin-hadoop2.7/bin/spark-submit \
--master "local" \
--class com.vesoft.nebula.exchange.Exchange \
/root/nebula-exchange-2.6.0.jar \
-c /root/csv_application.conf
参考资料
- 准备编译、安装和运行Nebula Graph的环境
- 使用RPM/DEB包部署Nebula Graph多机集群
- 部署 Studio
- 部署Dashboard
- 编译Exchange
- 导入CSV文件数据
- Nebula Graph 生态工具概览
- 引用属性