学习Tensorflow之卷积神经网络
学习Tensorflow之卷积神经网络
- 卷积神经网络
-
- 1. 卷积神经网络发展历史
- 2. 卷积神经网络原理
-
- (1) 局部感知
- (2) 权值共享
- (3) 边缘处理和步长
- (4) 下采样(池化)
- (5) 卷积后的宽度计算
- (6) 池化后的宽度计算
- 3. TensorFlow实现卷积神经网络
-
- (1) tf.nn.conv2d
- (2) tf.nn.max_pool 与 tf.nn.avg_pool
- (3) 卷积层类与池化层类
- 4. CIFAR-10数据集实战
-
- (1) 数据加载
- (2) 数据预处理
- (3) 模型搭建和训练测试
- (4) 模型预测
- (5) 完整代码
- LeNet实战
- AlexNet实战
卷积神经网络
1. 卷积神经网络发展历史
卷积神经网络最早的研究可以追溯到1968年,两位科学家对矛盾视觉系统进行了研究,得出了一个结论:生物的神经元在接收视觉信息时,往往是逐级进行处理的,先由简单细胞对图像的点、线等简单结果进行分析,之后再由复杂的细胞对图像更复杂的特征进行分析,最后识别出图像
1980年,一位日本科学家提出了一个包含卷积层和池化层的神经网络,这个结构被许多人认为是卷积神经网络的雏形。
1998年,再基于以往的卷积神经网络的研究基础上,LeNet-5卷积神经网络问世,并且该网络将反向传播算法应用于神经网络的训练。
2012年,伴随GPU等计算硬件和神经网络的更深入研究,AlexNet卷积神经网络横空出世,并且在ImageNet图像识别大赛中获胜。
2014年,牛津大学一个研究组提出了VGGNet的卷积神经网络。并且该年,谷歌的GoogLeNet也诞生。
2016年,ResNet被提出,它独有的残差网络结构可以很好的解决模型退化、梯度消失等问题。
2. 卷积神经网络原理
普通的神经网络再训练图像时,通常会因为全连接层的权重参数过多而导致模型收敛困难和训练困难,借助生物视觉系统的启发,卷积神经网络凭借着局部感知、权值共享、下采样三大特性,在图像处理中脱颖而出。与普通神经网络相比,卷积神经网络不仅减少了大量的训练参数,同时实现了特征的不变性,使模型能够适应不同尺度的数据。
(1) 局部感知
通常人或其他生物在接收不同的图像信息时,神经系统会对它们做出不同程度的吸收和反应,如果从图像的像素空间联系来看,图像像素通常与距离较近像素的联系更为密切,而与距离较远的像素联系较弱,因此,从这些分析中可以推断出:神经网络的神经元在处理图像信息时,并不需要对全局信息进行感知,只需要先对图像的局部信息进行感知,之后在更高层将这些局部感知信息进行结合,这样便可以得到完整的全局图像信息。
举一个简单的例子,假设输入的图像为100×100像素,第一层神经网络的神经元个数为1000个,如果通过全连接的方式进行连接,则网络模型的第一层权重参数的数量一共有100×100×1000=107个,如果通过局部感知的连接方式,假设局部感知区域图像大小为10×10像素,那么此时的权重参数就为10×10×1000=105个,与前者相比,权重参数减少了两个数量级。
(2) 权值共享
但是通过局部感知连接方式减少参数的数量还是有限的,因此就引入了权值共享的思想。还是刚才的例子,第一层神经网络的1000个神经元分别与大小10×10像素的局部区域进行连接,连接的总参数是10^5次方,这主要是由于1000个神经元的参数权重都不同,引入权值共享的思想后,可以把这1000个神经元都采用相同的权重参数进行连接,那么所需要保存的权重参数的数目就变成了10×10=100个,参数进一步减少了。
在卷积神经网络中,这10×10的局部感知,就类似卷积神经网络的卷积核,对于一幅图像,用相同的卷积核去扫描这张图像,在图像不同的位置,卷积核的参数都是相等的。
卷积是一种操作,放在图像上来考虑,就是二维卷积,卷积处理的过程中,最关键的就是卷积核,它实际上是一组由不同参数构成的矩阵,不同参数的卷积核的功能不同。
下面是卷积的过程,整个过程中,都是用是相同的参数
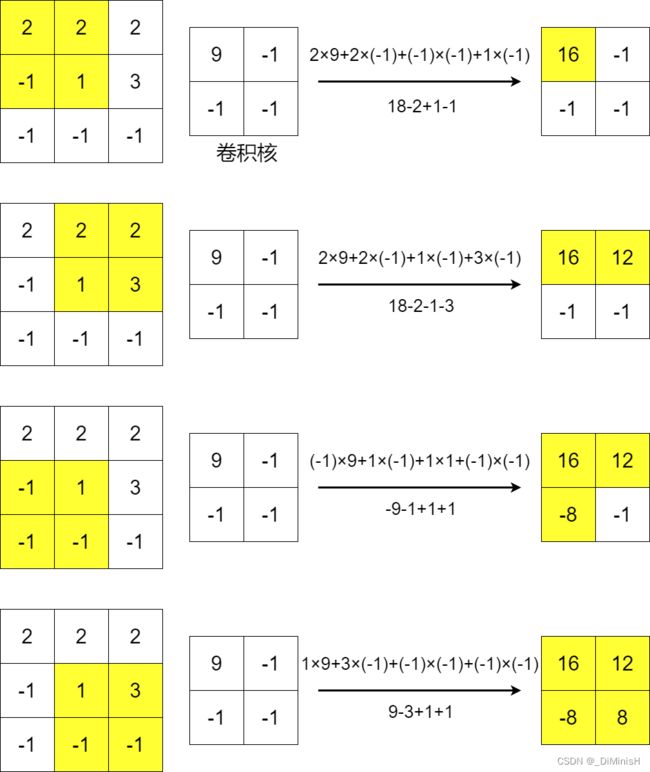
(3) 边缘处理和步长
在卷积运算的过程中,图像的填充大小和卷积核运算的步长也需要关注。为了保证经过卷积后的图像尺寸和原来的图像尺寸保持不变,通过会选择在原图像卷积之前进行一定的无干扰填充,即用0填补这些增加的空间以起到增大图像尺寸的效果。
下图是填充后的卷积
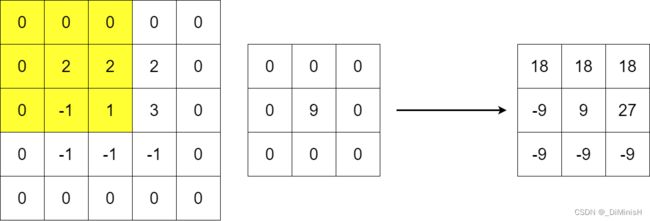
可以看到,在原来图像的边缘增加了一圈0
卷积的步长是指卷积在图像上扫描运动时每步移动的距离
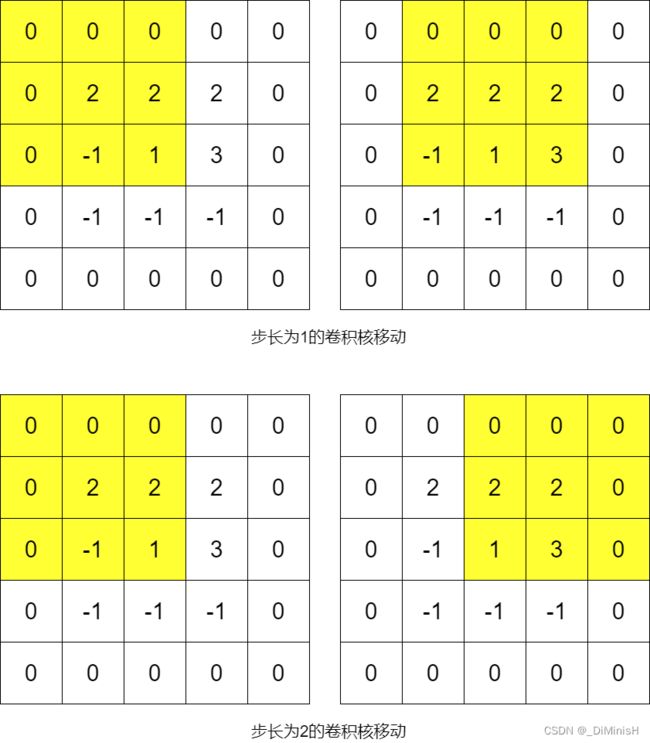
对于信息密度较大且重要的输入,通常会选用较小的步长,以防止丢失有用的信息,而对于信息密度较小的输入,则可以选择较大的步长,步长也会影响输出图像的尺寸。
(4) 下采样(池化)
在卷积神经网络中,池化的主要作用是对卷积后的图像特征进行压缩,来摒弃一些不重要的特征。
最常见的池化操作主要是平均池化和最大池化。
平均池化是指计算图像局部区域时,以它的平均值作为该区域的池化后的值,而最大池化则是指计算图像局部区域时以它的最大值作为该区域的池化后的值。
下图为最大池化
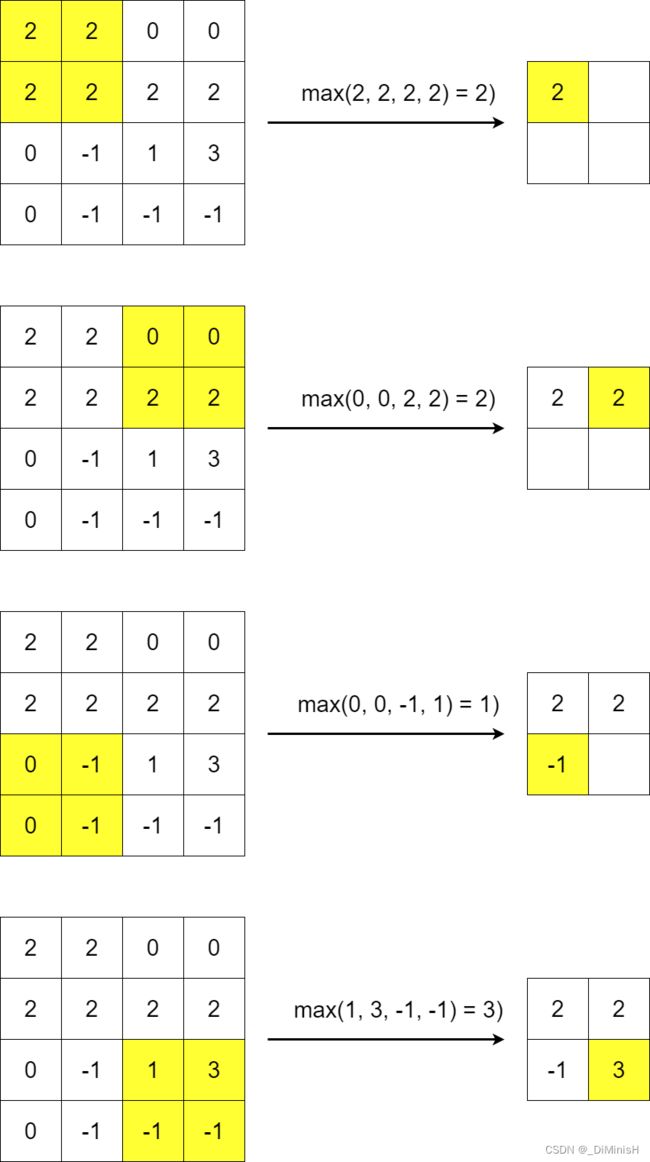
下图为平均池化
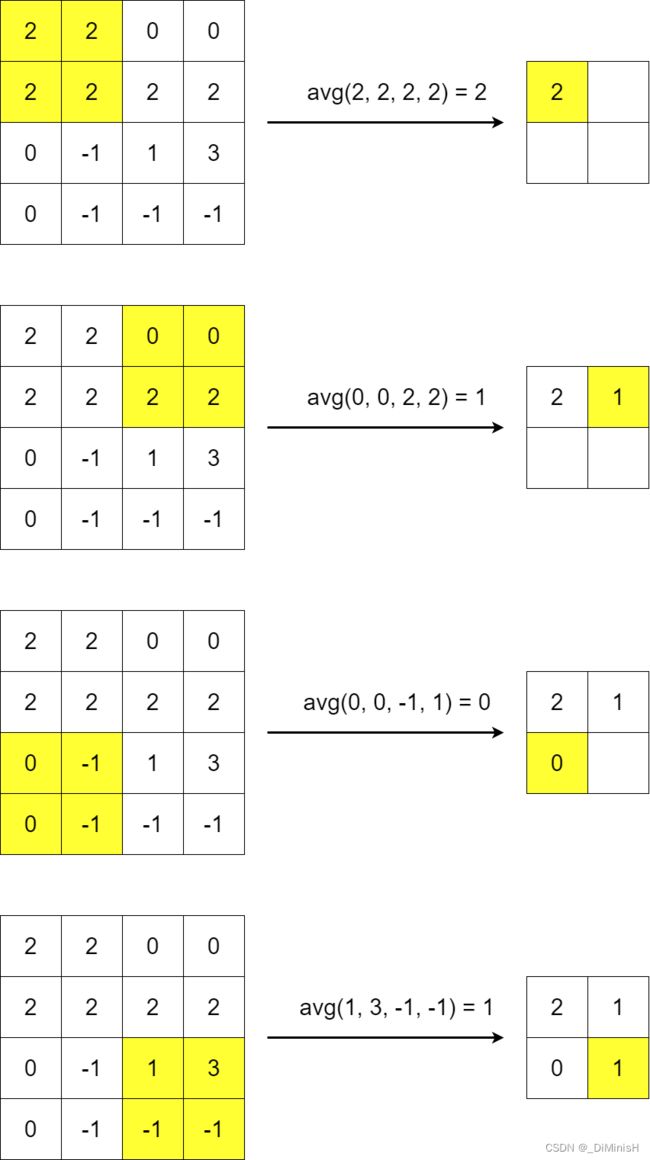
(5) 卷积后的宽度计算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h6B0p0H8-1680600426694)(…/Image/卷积尺寸计算公式.png)]
其中W’和H’为输出图像的宽和高,W和H为原图像的宽和高,F为卷积核的尺寸,S为步长,P为填充数量
(6) 池化后的宽度计算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eu289H8E-1680600426694)(…/Image/池化尺寸计算公式.png)]
其中W’和H’为输出图像的宽和高,W和H为原图像的宽和高,F为卷积核的尺寸,S为步长
如果在计算图像尺寸过程中出现了非整数的结果,那么对卷积后的图像采用向下取整的方式,对池化后的图像采用向上取整的方式
3. TensorFlow实现卷积神经网络
(1) tf.nn.conv2d
在tensorflow中,卷积操作使用tf.nn.conv2d()函数
tensorflow.nn.conv2d(
input, 输入图像,传入四维张量,(批大小,图像高度,图像宽度,图像输入通道数)
filters, 滤波器,传入四维张量,(卷积核高度,卷积核宽度,图像输入通道数,图像输出通道数)
strides, 步长,传入四维张量,(1,卷积核高度方向移动步长,卷积核宽度方向移动步长,1)
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不补0
)
import tensorflow as tf
# 构建(1, 4, 4, 1)的图像,(批大小,图像高度,图像宽度,图像输入通道数)
x = tf.random.normal([1, 4, 4, 1])
# 构建(4, 4, 1, 3)的图像,(卷积核高度,卷积核宽度,图像输入通道数,图像输出通道数)
w = tf.random.normal([4, 4, 1, 3])
# 卷积操作
out = tf.nn.conv2d(x, w, strides = (1, 1, 1, 1), padding = 'SAME')
print(out)
tf.Tensor(
[[[[ 0.778583 0.6619002 -1.4790113 ]
[ 1.188636 6.9371667 2.4374297 ]
[-1.3913952 4.410543 0.9859319 ]
[ 3.764593 1.4423373 -0.57055104]]
[[-3.1921675 -3.5124316 0.12658274]
[ 1.7132416 8.54721 3.15142 ]
[ 5.921658 -0.7486387 3.092455 ]
[ 3.8225932 -2.166392 0.58514506]]
[[ 0.7406579 0.98013824 -0.11164892]
[ 4.0433965 4.182381 4.203079 ]
[ 3.3941646 -0.89256984 2.5597715 ]
[ 3.1939588 -6.945467 0.7768513 ]]
[[-1.4998848 0.6666786 0.37684834]
[-0.01673996 -0.9329472 1.2827355 ]
[ 0.95153683 2.4550169 -1.023754 ]
[ 1.0801587 -1.7805198 1.407831 ]]]], shape=(1, 4, 4, 3), dtype=float32)
(2) tf.nn.max_pool 与 tf.nn.avg_pool
在tensorflow中,最大池化使用tf.nn.max_pool()函数,平均池化使用tf.nn.avg_pool()函数
tensorflow.nn.max_pool(
input, 输入图像,传入四维张量,(批大小,图像高度,图像宽度,图像输入通道数)
ksize, 池化核,传入四维张量,(1,池化核高度,池化核宽度,1)
strides, 步长,传入四维张量,(1,池化核高度方向移动步长,池化核宽度方向移动步长,1)
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不补0
)
tensorflow.nn.avg_pool(
input, 输入图像,传入四维张量,(批大小,图像高度,图像宽度,图像输入通道数)
ksize, 池化核,传入四维张量,(1,池化核高度,池化核宽度,1)
strides, 步长,传入四维张量,(1,池化核高度方向移动步长,池化核宽度方向移动步长,1)
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不补0
)
import tensorflow as tf
# 构建(1, 4, 4, 1)的图像,(批大小,图像高度,图像宽度,图像输入通道数)
x = tf.random.normal([1, 4, 4, 1])
out = tf.nn.max_pool(x, ksize = [1, 2, 2, 1], strides = 2, padding = 'VALID')
print(out)
tf.Tensor(
[[[[ 0.3602327]
[-0.3215486]]
[[ 0.6309148]
[ 1.9575975]]]], shape=(1, 2, 2, 1), dtype=float32)
可以看到,4×4的图像经过池化后被压缩成了2×2的图像了
(3) 卷积层类与池化层类
由于每次都需要认为的定义w等参数,可以使用tf.keras.layers.Conv2D()卷积层类和tf.keras.layers.MaxPooling2D(), tf.keras.layers.AveragePooling2D()池化层类提高效率。
卷积层类在调用它们时无需定义权值、张量等参数,系统会自动进行构建,但是在灵活性上有所降低
tensorflow.keras.layers.Conv2D(
filters, 整数,输出空间的维数,即卷积中输出滤波器的数量
kernel_size, 卷积核尺寸,(高度, 宽度) 或者 整数
strides, 步长,(高度方向移动步长, 宽度方向移动步长) 或者 整数
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不填充
)
tensorflow.keras.layers.MaxPooling2D(
pool_size, 池化核尺寸,(高度, 宽度) 或者 整数
strides, 步长,(高度方向移动步长, 宽度方向移动步长) 或者 整数
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不填充
)
tensorflow.keras.layers.AveragePooling2D(
pool_size, 池化核尺寸,(高度, 宽度) 或者 整数
strides, 步长,(高度方向移动步长, 宽度方向移动步长) 或者 整数
padding, 图像的填充方式,SAME:补0,输入图像和输出图像的尺寸一样;VALID:不填充
)
利用卷积层类和池化层类实现卷积和池化
import tensorflow as tf
# 构建(1, 4, 4, 1)的图像,(批大小,图像高度,图像宽度,图像输入通道数)
x = tf.random.normal([1, 4, 4, 1])
convLayer = tf.keras.layers.Conv2D(filters = 3, kernel_size = 4, strides = 1, padding = 'SAME')
print(convLayer(x).shape)
maxPool = tf.keras.layers.MaxPool2D(pool_size = 2, strides = 1, padding = 'SAME')
print(maxPool(x).shape)
avgPool = tf.keras.layers.AvgPool2D(pool_size = 2, strides = 1, padding = 'SAME')
print(avgPool(x).shape)
(1, 4, 4, 3)
(1, 4, 4, 1)
(1, 4, 4, 1)
4. CIFAR-10数据集实战
CIFAR-10数据集是一个彩色图像数据集,里面包含了10个类别的RGB图像,一共60000张,每个图像的尺寸都是32×32。
(1) 数据加载
import tensorflow as tf
# 读入训练集和测试集
(xTrain, yTrain), (xTest, yTest) = tf.keras.datasets.cifar10.load_data()
print(f"训练集数据大小:{xTrain.shape}")
print(f"训练集标签大小:{yTrain.shape}")
print(f"测试集数据大小:{xTest.shape}")
print(f"测试集标签大小:{yTest.shape}")
训练集数据大小:(50000, 32, 32, 3)
训练集标签大小:(50000, 1)
测试集数据大小:(10000, 32, 32, 3)
测试集标签大小:(10000, 1)
其中,(50000, 32, 32, 3)表示图片数量为50000张,单张图像的尺寸是32×32像素,通道数为3,RGB图像。
定义一个函数,展示几张图片
import matplotlib.pyplot as plt
def plotImage(images, labels, prediction, index, nums = 10):
fig = plt.gcf()
fig.set_size_inches(14, 14)
for i in range(0, nums):
ax = plt.subplot(5, 5, 1 + i)
ax.imshow(images[index])
title = 'label:' + str(labels[index][0])
if len(prediction) > 0:
title += 'prediction:' + str(prediction[index])
ax.set_title(title, fontsize = 13)
ax.set_xticks([])
ax.set_yticks([])
index += 1
plotImage(xTrain, yTrain, [], 0, 10)

(2) 数据预处理
数据归一化的目的:为了将特征值尺度调整到相近的范围。如果不归一化,尺度大的特征值,梯度也就大,尺度小的特征值,梯度就小,而梯度更新时的学习率是一样的,如果学习率小,梯度小的就更新慢,如果学习率大,梯度大的方向不稳定,不易收敛,通常需要使用最小的学习率迁就大尺度的维度才能保证损失函数有效下降,因此,通过归一化,把不同维度的特征值范围调整到相近的范围内,就能统一使用较大的学习率加速学习。因为图片像素值的范围都在0~255,图片数据的归一化可以简单地除以255。
# 数据归一化
xTrainNormalize = xTrain.astype('float32') / 255
xTestNormalize = xTrain.astype('float32') / 255
# 标签one-hot编码
yTrainOneHot = tf.keras.utils.to_categorical(yTrain)
yTestOneHot = tf.keras.utils.to_categorical(yTest)
print(f"归一化前:{xTrain[0][0][0]}")
print(f"归一化后:{yTrainOneHot[0][0][0]}")
归一化前:[59 62 63]
归一化后:[0.23137255 0.24313726 0.24705882]
(3) 模型搭建和训练测试
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters = 32, kernel_size = 3, padding = 'SAME', input_shape = (32, 32, 3), activation = 'relu'
),
tf.keras.layers.MaxPool2D(pool_size = 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1500, activation = tf.keras.activations.relu),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model.summary()
model.compile(
loss = tf.losses.CategoricalCrossentropy(),
optimizer = tf.optimizers.Adam(),
metrics = ['accuracy']
)
modelTrain = model.fit(
xTrainNormalize, yTrainOneHot, validation_split = 0.2, epochs = 30, batch_size = 300, verbose = 1
)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
max_pooling2d (MaxPooling2D (None, 16, 16, 32) 0
)
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 1500) 12289500
dropout (Dropout) (None, 1500) 0
dense_1 (Dense) (None, 10) 15010
=================================================================
Total params: 12,305,406
Trainable params: 12,305,406
Non-trainable params: 0
_________________________________________________________________
......
Epoch 25/30
134/134 [==============================] - 27s 203ms/step - loss: 0.1873 - accuracy: 0.9438 - val_loss: 1.0956 - val_accuracy: 0.6941
Epoch 26/30
134/134 [==============================] - 28s 212ms/step - loss: 0.1700 - accuracy: 0.9501 - val_loss: 1.1301 - val_accuracy: 0.6963
Epoch 27/30
134/134 [==============================] - 26s 196ms/step - loss: 0.1617 - accuracy: 0.9511 - val_loss: 1.1702 - val_accuracy: 0.6902
Epoch 28/30
134/134 [==============================] - 25s 184ms/step - loss: 0.1450 - accuracy: 0.9565 - val_loss: 1.1638 - val_accuracy: 0.6903
Epoch 29/30
134/134 [==============================] - 25s 187ms/step - loss: 0.1419 - accuracy: 0.9562 - val_loss: 1.2282 - val_accuracy: 0.6873
Epoch 30/30
134/134 [==============================] - 25s 189ms/step - loss: 0.1384 - accuracy: 0.9585 - val_loss: 1.2215 - val_accuracy: 0.6864
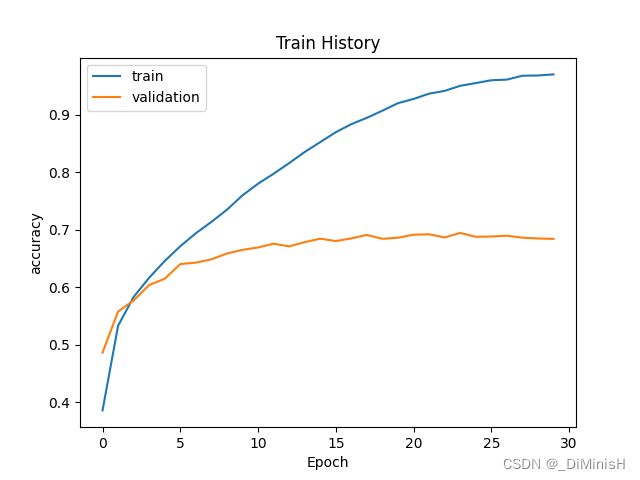
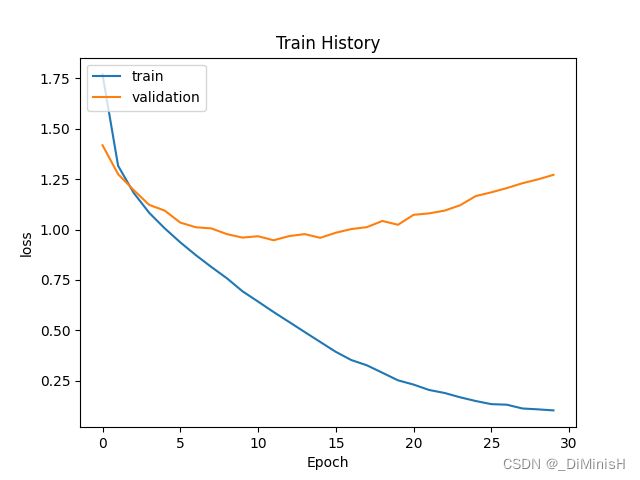
画出训练集和验证集的准确率和损失变化曲线
def plotTrainHistory(history, train, val):
plt.plot(history[train])
plt.plot(history[val])
plt.title('Train History')
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'validation'], loc = 'upper left')
plotTrainHistory(modelTrain.history, 'accuracy', 'val_accuracy')
plotTrainHistory(modelTrain.history, 'loss', 'val_loss')
(4) 模型预测
对模型进行预测
import numpy as np
# 对模型测试集进行测试
score = model.evaluate(xTestNormalize, yTestOneHot, verbose = 2)
print(score)
# 对测试集进行预测
prediction = model.predict(xTestNormalize)
prediction = np.argmax(prediction, axis=1)
print(prediction)
[3 8 8 ... 5 1 7]
利用字典更具体的显示每张图片的概率
labelDict = {
0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog',
6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'
}
def predictedProbability(X, y, prediction, predictionProbability, i):
plt.figure(figsize = (2, 2))
plt.imshow(X[i])
plt.show()
print("标签:", labelDict[y[i][0]], '预测:', labelDict[prediction[i]])
for j in range(10):
print(labelDict[j] + '概率:%1.9f' % (predictionProbability[i][j]))
predictionProbability = model.predict(xTestNormalize)
prediction = np.argmax(predictionProbability, axis=1)
predictedProbability(xTest, yTest, prediction, predictionProbability, 0)
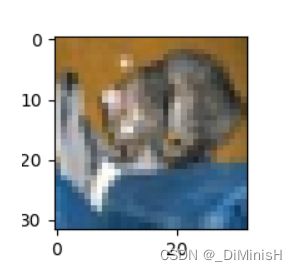
标签: cat 预测: cat
airplane概率:0.000000192
automobile概率:0.000002428
bird概率:0.000009391
cat概率:0.997480690
deer概率:0.000047810
(5) 完整代码
import tensorflow as tf
import matplotlib.pyplot as plt
import pandas as pd
# 读入训练集和测试集
(xTrain, yTrain), (xTest, yTest) = tf.keras.datasets.cifar10.load_data()
print(f"训练集数据大小:{xTrain.shape}")
print(f"训练集标签大小:{yTrain.shape}")
print(f"测试集数据大小:{xTest.shape}")
print(f"测试集标签大小:{yTest.shape}")
# %%
def plotImage(images, labels, prediction, index, nums = 10):
fig = plt.gcf()
fig.set_size_inches(14, 14)
for i in range(0, nums):
ax = plt.subplot(5, 5, 1 + i)
ax.imshow(images[index])
title = 'label:' + str(labels[index][0])
if len(prediction) > 0:
title += 'prediction:' + str(prediction[index])
ax.set_title(title, fontsize = 13)
ax.set_xticks([])
ax.set_yticks([])
index += 1
plotImage(xTrain, yTrain, [], 0, 10)
# %%
# 数据归一化
xTrainNormalize = xTrain.astype('float32') / 255
xTestNormalize = xTest.astype('float32') / 255
# 标签one-hot编码
yTrainOneHot = tf.keras.utils.to_categorical(yTrain)
yTestOneHot = tf.keras.utils.to_categorical(yTest)
print(f"归一化前:{xTrain[0][0][0]}")
print(f"归一化后:{xTrainNormalize[0][0][0]}")
# %%
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters = 32, kernel_size = 3, padding = 'SAME', input_shape = (32, 32, 3), activation = 'relu'
),
tf.keras.layers.MaxPool2D(pool_size = 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(1500, activation = tf.keras.activations.relu),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Dense(10, activation = 'softmax')
])
model.summary()
model.compile(
loss = tf.losses.CategoricalCrossentropy(),
optimizer = tf.optimizers.Adam(),
metrics = ['accuracy']
)
modelTrain = model.fit(
xTrainNormalize, yTrainOneHot, validation_split = 0.2, epochs = 30, batch_size = 300, verbose = 1
)
print(modelTrain.history)
# %%
def plotTrainHistory(history, train, val):
plt.plot(history[train])
plt.plot(history[val])
plt.title('Train History')
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'validation'], loc = 'upper left')
plt.show()
plotTrainHistory(modelTrain.history, 'accuracy', 'val_accuracy')
plotTrainHistory(modelTrain.history, 'loss', 'val_loss')
#%%
import numpy as np
# 对模型测试集进行测试
score = model.evaluate(xTestNormalize, yTestOneHot, verbose = 2)
print(score)
# 对测试集进行预测
prediction = model.predict(xTestNormalize)
prediction = np.argmax(prediction, axis=1)
print(prediction)
#%%
labelDict = {
0: 'airplane', 1: 'automobile', 2: 'bird', 3: 'cat', 4: 'deer', 5: 'dog',
6: 'frog', 7: 'horse', 8: 'ship', 9: 'truck'
}
def predictedProbability(X, y, prediction, predictionProbability, i):
plt.figure(figsize = (2, 2))
plt.imshow(X[i])
plt.show()
print("标签:", labelDict[y[i][0]], '预测:', labelDict[prediction[i]])
for j in range(10):
print(labelDict[j] + '概率:%1.9f' % (predictionProbability[i][j]))
predictionProbability = model.predict(xTestNormalize)
prediction = np.argmax(predictionProbability, axis=1)
predictedProbability(xTest, yTest, prediction, predictionProbability, 0)
LeNet实战
LeNet-5卷积神经网络是1998年被提出的,当时该网络主要用于手写数字及机器字符的识别任务中。
import tensorflow as tf
import matplotlib.pyplot as plt
(xTrain, yTrain), (xTest, yTest) = tf.keras.datasets.cifar10.load_data()
# 归一化
xTrainNormalize = xTrain.astype('float32') / 255
xTestNormalize = xTest.astype('float32') / 255
yTrainOneHot = tf.keras.utils.to_categorical(yTrain)
yTestOneHot = tf.keras.utils.to_categorical(yTest)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters = 6, kernel_size = 3, strides = 1, input_shape = (32, 32, 3)
),
tf.keras.layers.MaxPool2D(pool_size = 2, strides = 2),
tf.keras.layers.ReLU(),
tf.keras.layers.Conv2D(
filters = 16, kernel_size = 3, strides = 1
),
tf.keras.layers.MaxPool2D(pool_size = 2, strides = 2),
tf.keras.layers.ReLU(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(120, activation = tf.keras.activations.relu),
tf.keras.layers.Dense(84, activation = 'relu'),
tf.keras.layers.Dense(10, activation = tf.keras.activations.softmax)
])
model.summary()
model.compile(
loss = tf.keras.losses.CategoricalCrossentropy(),
optimizer = tf.keras.optimizers.Adam(),
metrics = ['accuracy']
)
modelTrain = model.fit(
xTrainNormalize, yTrainOneHot, validation_split = 0.2, epochs = 20,
batch_size = 300, verbose = 1
)
def plotTrainHistory(history, train, val):
plt.plot(history[train])
plt.plot(history[val])
plt.title('Train History')
plt.xlabel('Epoch')
plt.ylabel(train)
plt.legend(['train', 'validation'], loc = 'upper left')
plt.show()
plotTrainHistory(modelTrain.history, 'accuracy', 'val_accuracy')
plotTrainHistory(modelTrain.history, 'loss', 'val_loss')
scores = model.evaluate(xTestNormalize, yTestOneHot, verbose = 2)
print(scores)
313/313 - 1s - loss: 1.1129 - accuracy: 0.6195 - 1s/epoch - 4ms/step
AlexNet实战
import tensorflow as tf
from Draw import plotTrainHistory
(xTrain, yTrain), (xTest, yTest) = tf.keras.datasets.cifar10.load_data()
# 归一化
xTrainNormalize = xTrain.astype('float32') / 255
xTestNormalize = xTest.astype('float32') / 255
# 数据独热编码
yTrainOneHot = tf.keras.utils.to_categorical(yTrain)
yTestOneHot = tf.keras.utils.to_categorical(yTest)
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(
filters = 96, kernel_size = 11, strides = 4, input_shape = (32, 32, 3),
padding = 'SAME', activation = tf.keras.activations.relu
),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPool2D(pool_size = 3, strides = 2, padding = 'SAME'),
tf.keras.layers.Conv2D(
filters = 256, kernel_size = 5, strides = 1,
padding = 'SAME', activation = tf.keras.activations.relu
),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.MaxPool2D(pool_size = 3, strides = 2, padding = 'SAME'),
tf.keras.layers.Conv2D(
filters = 384, kernel_size = 3, strides = 1,
padding = 'SAME', activation = tf.keras.activations.relu
),
tf.keras.layers.Conv2D(
filters = 384, kernel_size = 3, strides = 1,
padding = 'SAME', activation = tf.keras.activations.relu
),
tf.keras.layers.Conv2D(
filters = 256, kernel_size = 3, strides = 1,
padding = 'SAME', activation = tf.keras.activations.relu
),
tf.keras.layers.MaxPool2D(pool_size = 3, strides = 2, padding = 'SAME'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096, activation = tf.keras.activations.relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(4096, activation = tf.keras.activations.relu),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(10, activation = tf.keras.activations.softmax)
])
model.compile(
loss = tf.keras.losses.CategoricalCrossentropy(),
optimizer = tf.keras.optimizers.Adam(),
metrics = ['accuracy']
)
modelTrain = model.fit(
xTrainNormalize, yTrainOneHot, validation_split = 0.2,
epochs = 10, batch_size = 300, verbose = 1
)
plotTrainHistory(modelTrain.history, 'loss', 'val_loss')
model.evaluate(xTestNormalize, yTestOneHot)