使用jdk17 搭建Hadoop3.3.5和Spark3.3.2 on Yarn集群模式
搭建Hadoop3.3.5和Spark3.3.2 on Yarn集群模式,使用jdk17
- 搭建Hadoop3.3.5和Spark3.3.2 on Yarn集群模式
-
- 1. 创建一台虚拟机
- 2. 安装jdk17
-
- (1)下载jdk17
- (2)安装jdk17
- (3)配置环境变量
- 3. 虚拟机之间互信
-
- (1)克隆虚拟机
- (2)修改每台虚拟机的hostname
- (3)每台虚拟机生成私钥和公钥
- (4)创建公用公钥(免密登录)
- (5)关闭防火墙
- (6)配置hosts文件
- (7)机器之间相互通信
- 4. 安装hadoop
-
- (1)下载hadoop3.3.5
- (2)上传hadoop3.3.5到虚拟机
- (3)配置core-site.xml
- (4)配置hadoop-env.sh
- (5)配置hdfs-site.xml
- (6)配置mapred-site.xml
- (7)配置workers
- (8)配置yarn-site.xml
- (9)创建localdir
- (10)配置hadoop环境变量
- 5. 启动hadoop
-
- (1)格式化 NameNode
- (2)启动hadoop
- (3)查看进程
- (4)查看 web 界面
- 6. 安装Spark 使用Spark on Yarn集群模式
-
- (1)下载Spark3.3.2
- (2)上传Spark3.3.2到虚拟机
- (3)配置spark-defaults.conf
- (4)配置workers
- (5)配置spark-env.sh
- (6)配置Spark环境变量
- 7. 启动Spark
-
- (1)在hdfs环境中创建出日志存放位置
- (2)启动spark
- (3)web访问
- (4)使用spark计算圆周率
- (5)查看运行结果
搭建Hadoop3.3.5和Spark3.3.2 on Yarn集群模式
准备四台虚拟机或者物理机,我使用虚拟机,需要使用80G外存
我先准备一台虚拟机,配置完成后克隆出剩下的三台,这样可以解决配置时间
1. 创建一台虚拟机
这里我使用的是Centos8.5,虚拟机外存20G,内存4G,我安装的是带桌面版的
阿里Centos8.5下载地址
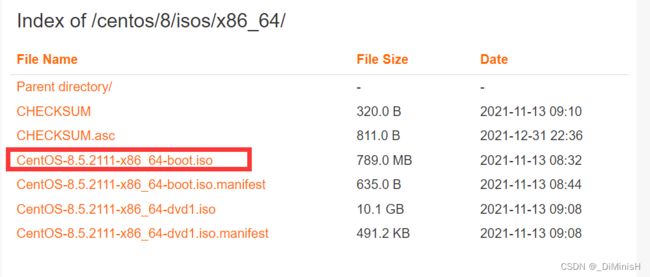
使用VMware安装一台虚拟机
安装过程中设置install source
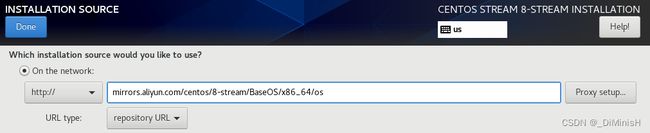
http://mirrors.aliyun.com/centos/8-stream/BaseOS/x86_64/os/

2. 安装jdk17
(1)下载jdk17
jdk17下载地址
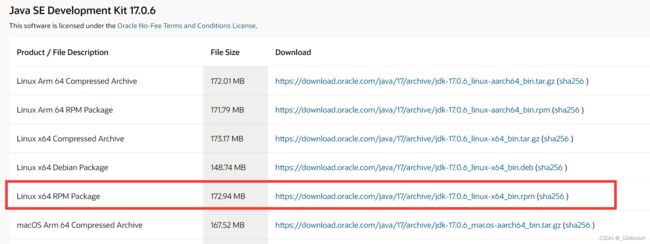
我下载的是rmp的这个
(2)安装jdk17
我把所有的软件都安装在了 /opt 下面
创建一个文件夹 /java17
把安装包上传到该文件夹
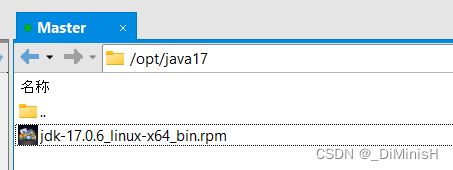
在这里解压
rpm -ivh 软件包名字

(3)配置环境变量
进入**/usr/lib/jvm/jdk-17-oracle-x64**,可以看到刚才的java就安装在这里了
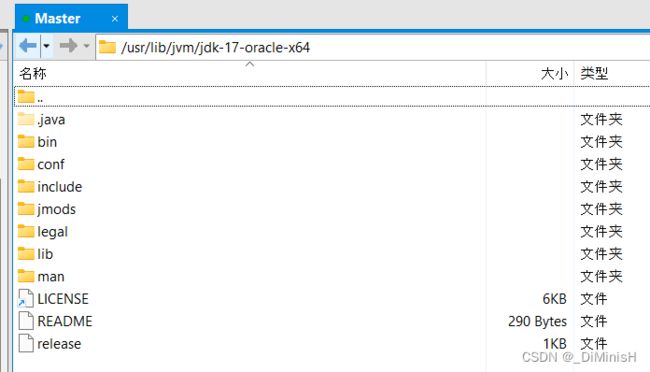
打开**/etc/proflie**文件,添加如下代码来配置环境变量
export JAVA_HOME=/usr/lib/jvm/jdk-17-oracle-x64
export PATH=$PATH:$JAVA_HOME/bin;
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar;
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"
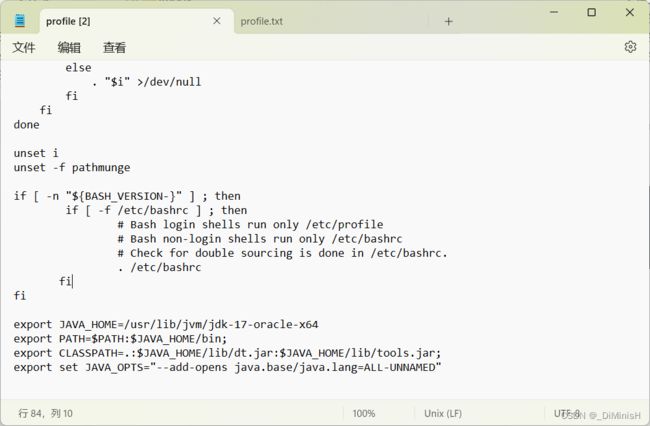
之后输入下面的命令,让配置生效
source /etc/profile

输入$Java_HOME出现路径,说明配置成功
3. 虚拟机之间互信
(1)克隆虚拟机
现在完成了一台虚拟机的配置,把这台虚拟机再克隆三份
点击克隆
点下一步
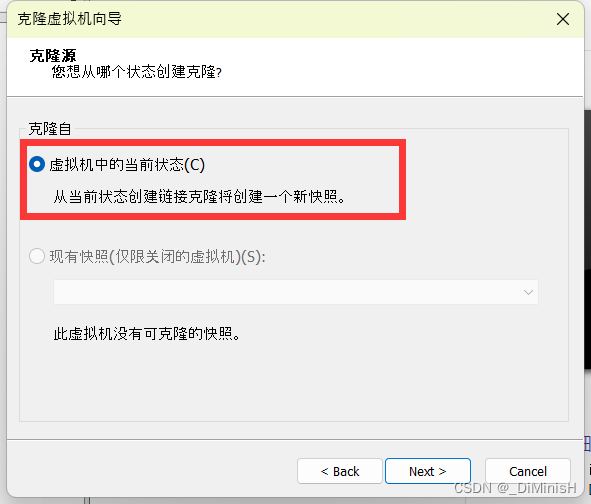
选择位置
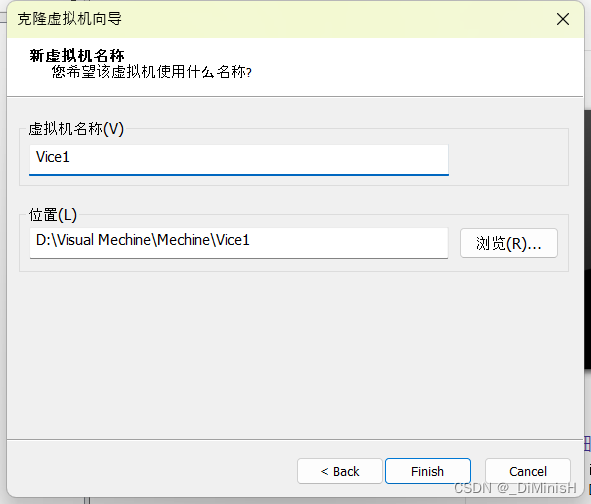
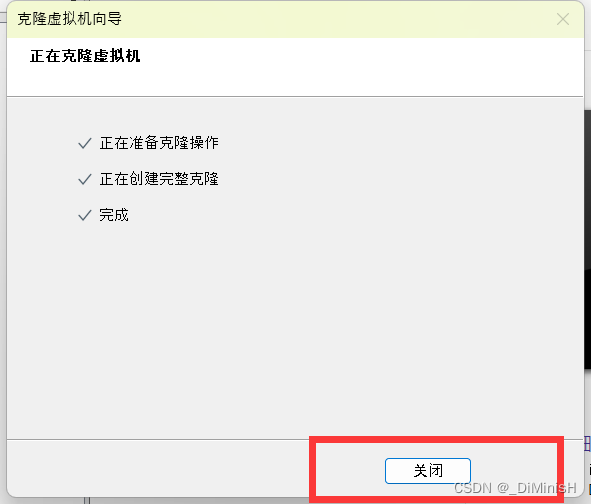
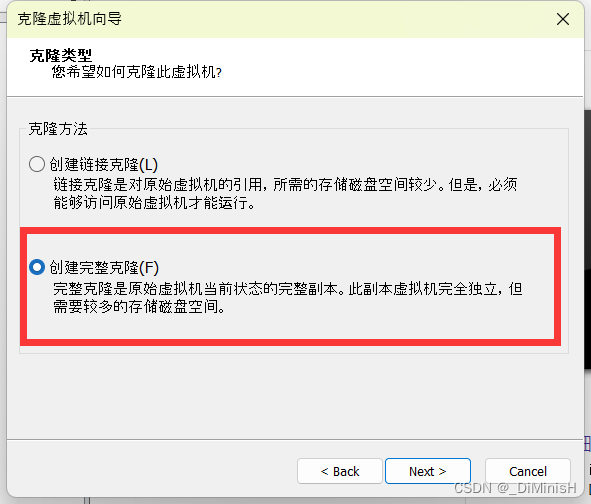
创建完成一台,接下来继续创建
最终的效果

(2)修改每台虚拟机的hostname
一主三从
登陆时选择root用户登录
改完后四台主机的hostname分别为:master vice1 vice2 vice3 vice4
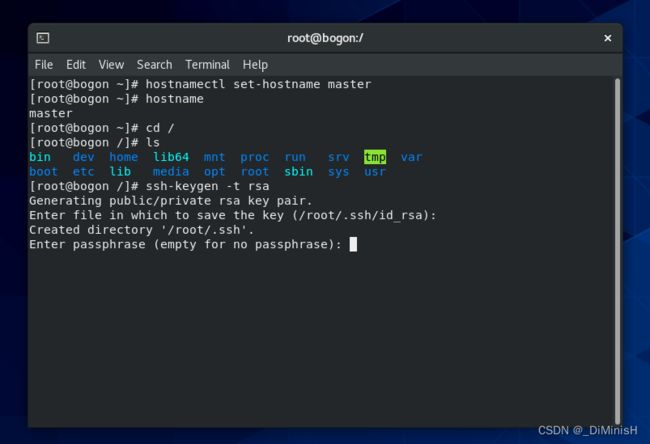
(3)每台虚拟机生成私钥和公钥
在 **/**目录下输入命令
ssh-keygen -t rsa

出现如图所示的情况时,按下回车
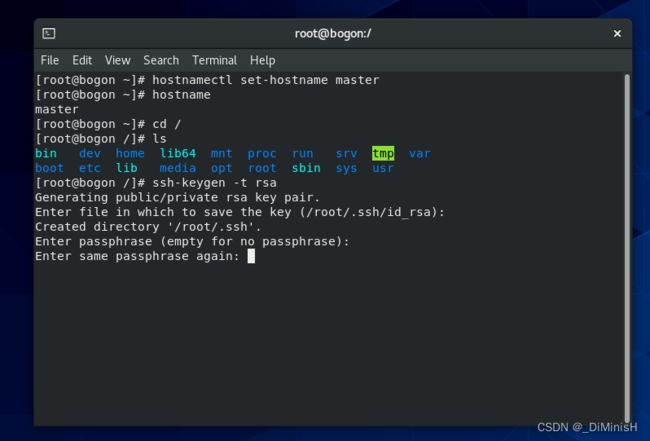
继续按下回车
再按下回车
一共按下三次回车
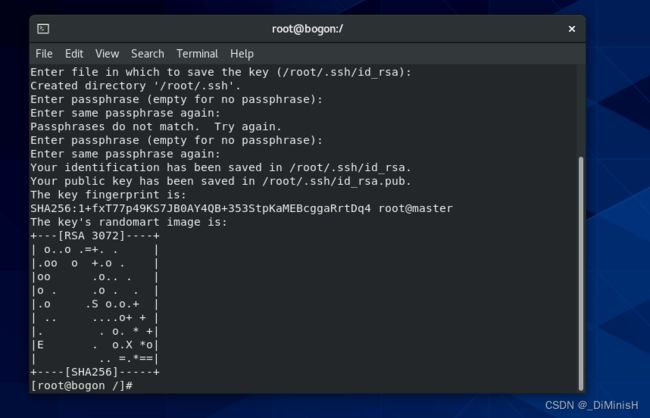
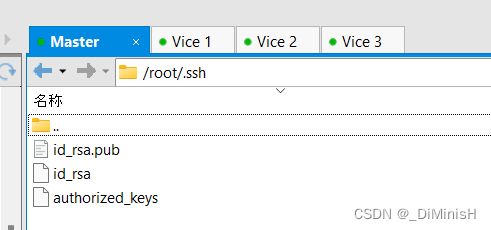
创建成功,之后可以在**/**目录下看到一个 .ssh 的隐藏文件
(4)创建公用公钥(免密登录)
把**.pub**文件打开,复制出里面的内容,把内容复制到一个临时的txt中,我复制到了windows桌面的一个文件里
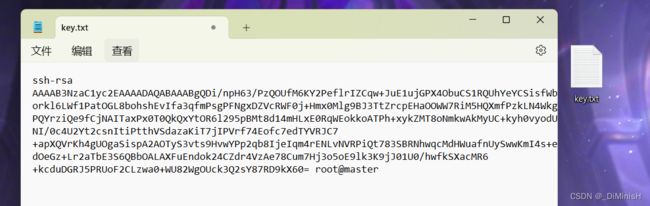
之后把每台虚拟机的 .pub 文件中的内容都复制到这个临时的txt中
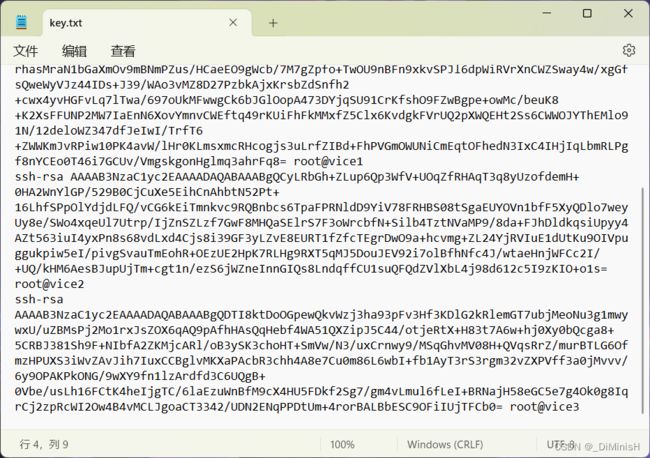
此时我们有了四台虚拟机的公钥
把这个txt临时文件改名为 authorized_keys
之后把这个文件放到每台虚拟机的 /.ssh目录下
(5)关闭防火墙
关闭防火墙,每台虚拟机都需要关闭
systemctl stop firewalld
systemctl disable firewalld

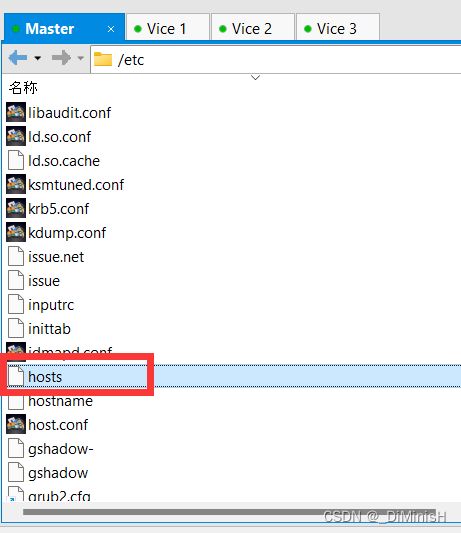
(6)配置hosts文件
获取每台虚拟机的ip,写入每台虚拟机的hosts文件
hosts文件路径是 /etc/hosts
修改内容
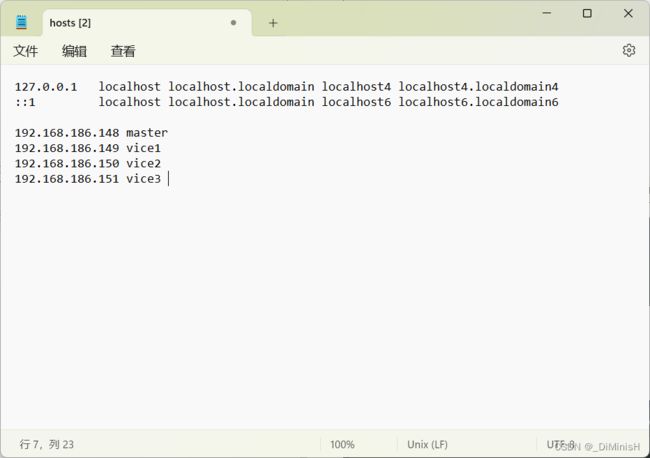
192.168.186.148 master
192.168.186.149 vice1
192.168.186.150 vice2
192.168.186.151 vice3
这4个分别对应四台虚拟机的hostname和ip地址
使用ifconfig可以查看IP地址
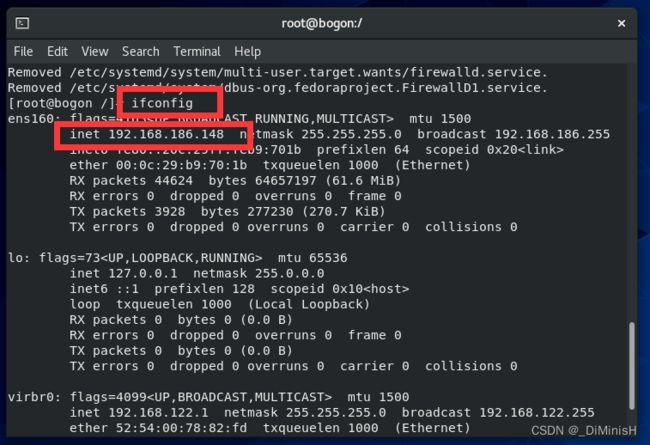
每台虚拟机都需要完成hosts的配置
(7)机器之间相互通信
在每台虚拟机上,分别与其他虚拟机进行通信
输入命令
ssh master/vice
与master腾讯就输入 ssh master
第一次通信会出现让你输入yes的情况,如果要输入密码,那么就是产生公钥和私钥环节出错,重新进行产生公钥和私钥
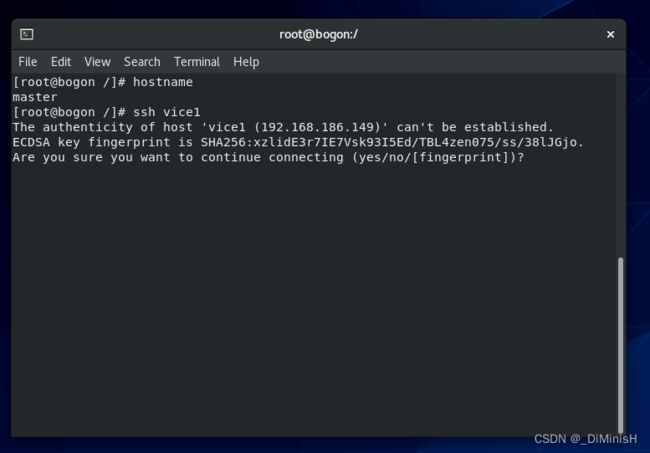
输入yes
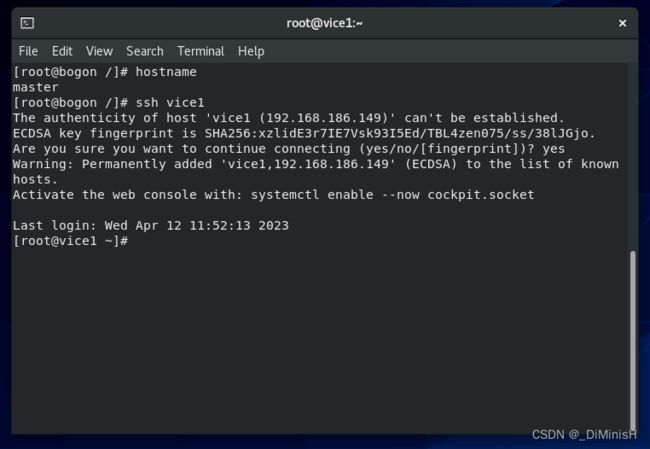
此时就通信成功了,之后输入exit退出,再试一次,看看需不需要输入yes或者密码
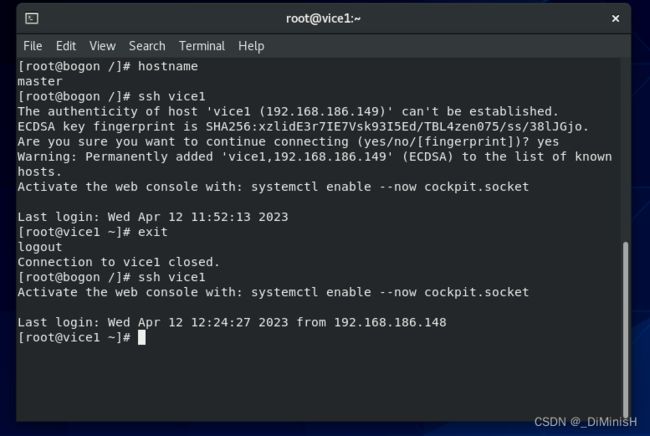
此时直接进来了,说明互信成功,接下来退出去,与其他虚拟机互信,自己与自己也互信一次
如果出现以下问题,说明hosts文件没有配置或者配置错误

4. 安装hadoop
(1)下载hadoop3.3.5
hadoop3.3.5下载地址
下载完成后上传到虚拟机
(2)上传hadoop3.3.5到虚拟机
把安装包上传到 /opt 目录下
解压
tar -xvzf 安装包
解压完成
(3)配置core-site.xml
进入 /opt/hadoop-3.3.5/etc/hadoop 目录
打开 core-site.xml ,加入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.5/tmp</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
(4)配置hadoop-env.sh
配置JAVA_HOME

export JAVA_HOME=/usr/lib/jvm/jdk-17-oracle-x64
设置java虚拟机启动参数
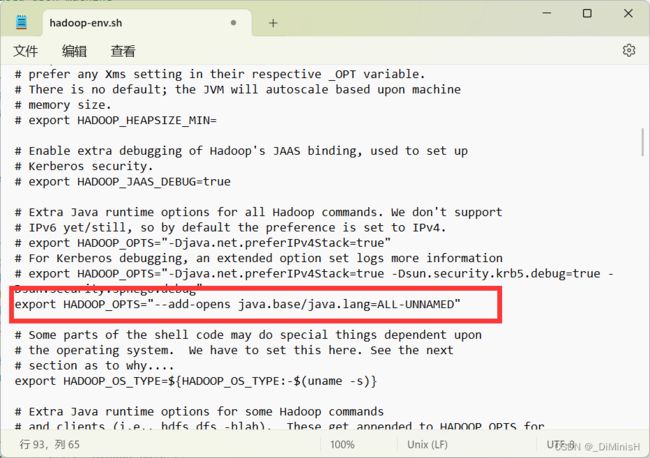
export HADOOP_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"
(5)配置hdfs-site.xml

添加如下代码
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
(6)配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
(7)配置workers

(8)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/localdir</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
(9)创建localdir
在 /opt 目录下创建localdir
(10)配置hadoop环境变量
在 /etc/profile 文件中加入如下代码
export HADOOP_HOME=/opt/hadoop-3.3.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
启用配置
source /etc/profile
至此,一台虚拟机配置完毕,接下来配置其他虚拟器
5. 启动hadoop
现在,四台虚拟机已经都安装了hadoop,并且环境变量已经配置成功,下面就是启动hadoop了
确保四台机子都已经打开
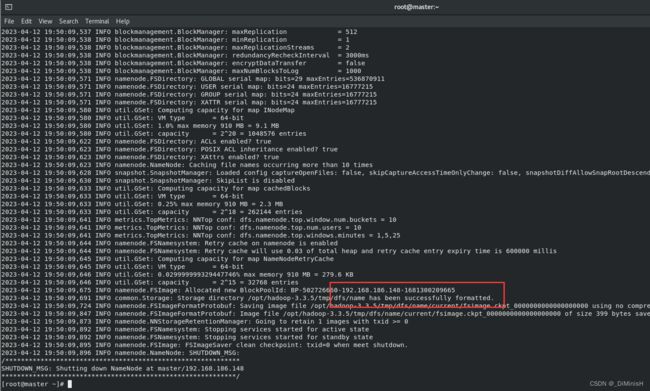
(1)格式化 NameNode
在主节点master机器上运行如下命令
hdfs namenode -format
(2)启动hadoop
start-all.sh
出现报错
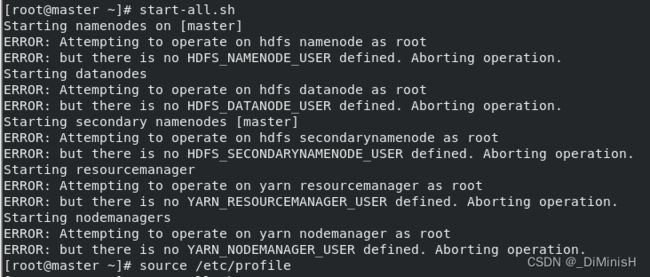
解决方法:在每个虚拟机的 /etc/profile 文件中加入如下代码
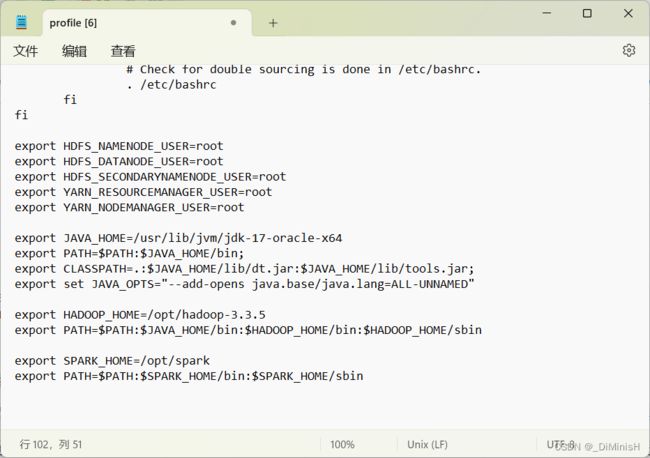
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
启用配置
source /etc/profile
之后再次运行start-all.sh
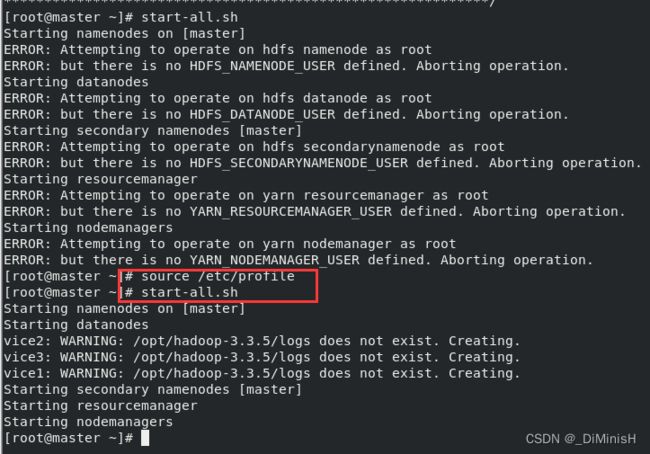
启动成功
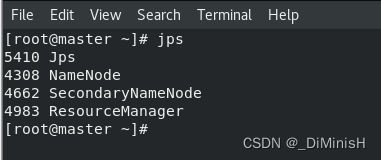
(3)查看进程
使用 jps 命令
主节点查看
从节点查看
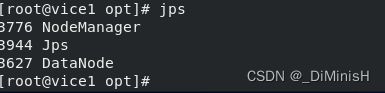
出现上述两个图片中的进程,表示hadoop启动成功
(4)查看 web 界面
在浏览器输入ip
http://主节点IP地址:9870/
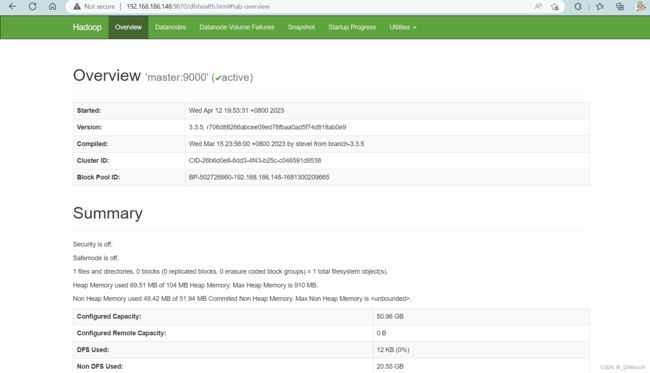
成功进入
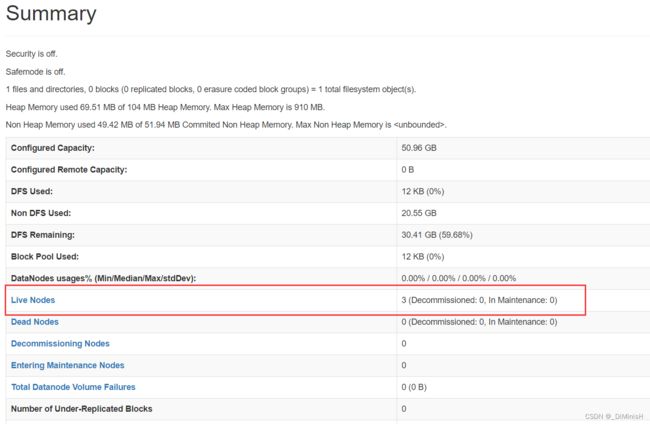
可以看到活着的结点有3个
关闭hadoop,在master节点输入下面的命令
stop-all.sh
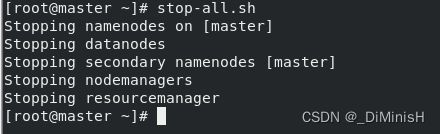
6. 安装Spark 使用Spark on Yarn集群模式
(1)下载Spark3.3.2
https://www.apache.org/dyn/closer.lua/spark/spark-3.3.2/spark-3.3.2-bin-without-hadoop.tgz
下载的是没有自带hadoop的版本
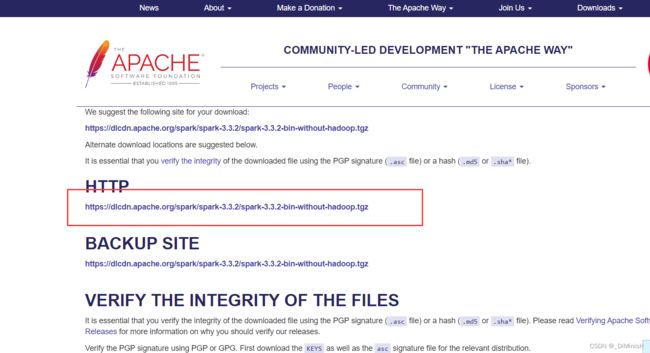
(2)上传Spark3.3.2到虚拟机
解压
tar -xzvf spark-3.3.2-bin-without-hadoop.tgz
给文件夹改个名字,改为spark
(3)配置spark-defaults.conf
进入 /opt/spark/conf 目录下
把spark-defaults.conf.template文件的.template删除
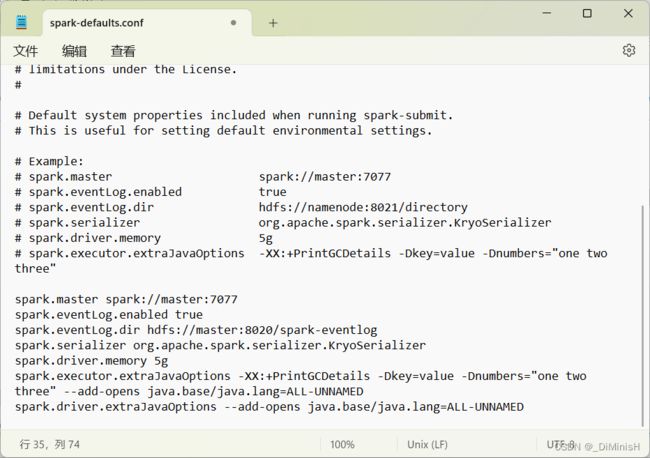
修改其内容
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 5g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" --add-opens java.base/java.lang=ALL-UNNAMED
spark.driver.extraJavaOptions --add-opens java.base/java.lang=ALL-UNNAMED
(4)配置workers
创建workers文件,并修改内容
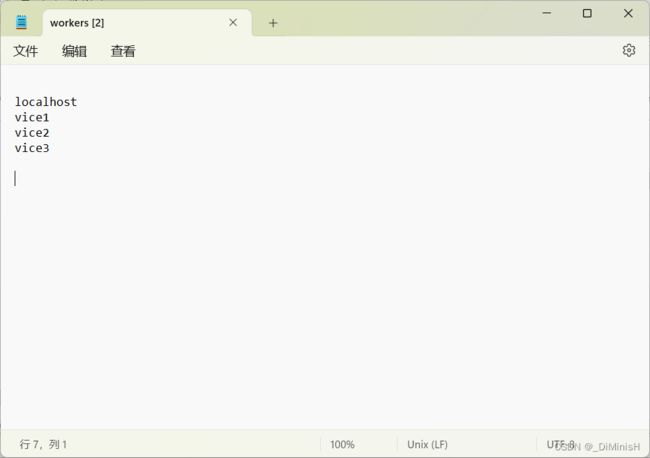
或者把.template文件修改
(5)配置spark-env.sh
把spark-env.sh.template文件的.template删除
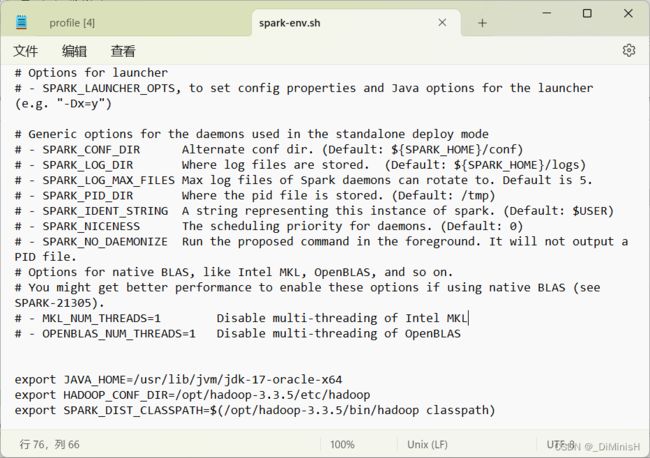
修改其内容
export JAVA_HOME=/usr/lib/jvm/jdk-17-oracle-x64
export HADOOP_CONF_DIR=/opt/hadoop-3.3.5/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/hadoop-3.3.5/bin/hadoop classpath)
(6)配置Spark环境变量
在 /etc/profile 文件中加入如下代码
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
启用配置
source /etc/profile
至此,一台虚拟机的spark配置完毕,接下来配置其他虚拟器,过程与该虚拟机配置过程一致
7. 启动Spark
现在,四台虚拟机已经都安装了Spark,并且环境变量已经配置成功,下面就是启动Spark了
确保四台机子都已经打开
(1)在hdfs环境中创建出日志存放位置
先启动hadoop,start-all.sh
进入浏览器界面,访问hadoop的web页面,点击utilities
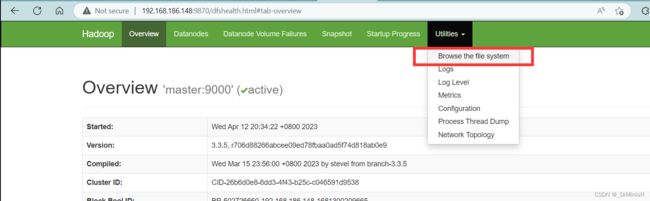
创建文件夹 /spark-eventlog
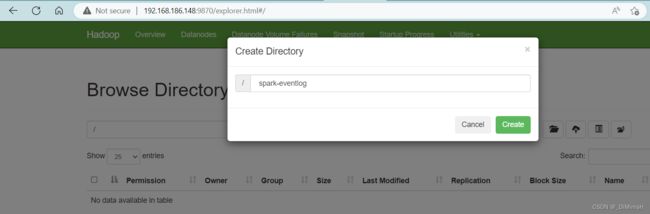
点击create
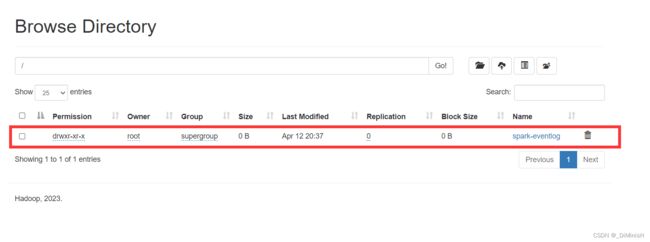
创建成功
(2)启动spark
进入 /opt/spark/sbin 目录下
输入如下命令启动
./start-all.sh
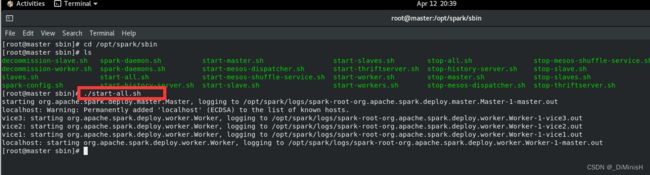
如果出现 permission deny或者权限不足,需要把对应虚拟机的spark文件夹加权限
(3)web访问
访问网址
http://主节点IP地址:8080/
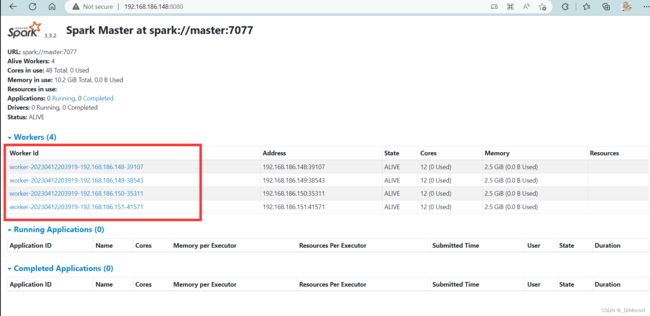
(4)使用spark计算圆周率
在主节点上输入一下命令
spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi /opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar 100
这个 /opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar 是spark路径下的一个jar包,是官方提供的样例
100表示运行100次
下面是运行过程
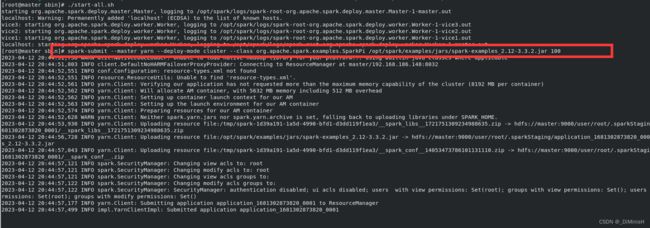
运行出现问题
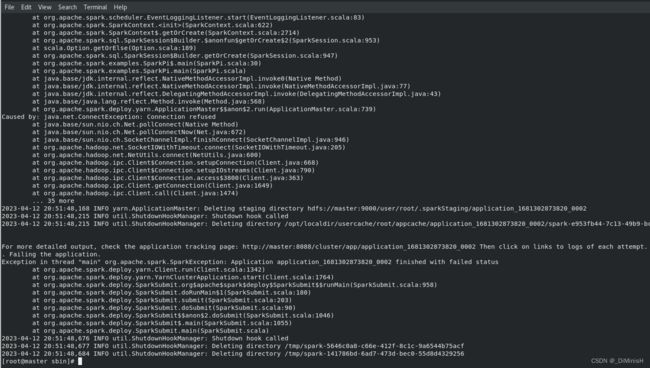
修改 /opt/spark/conf/spark-defaults.conf文件
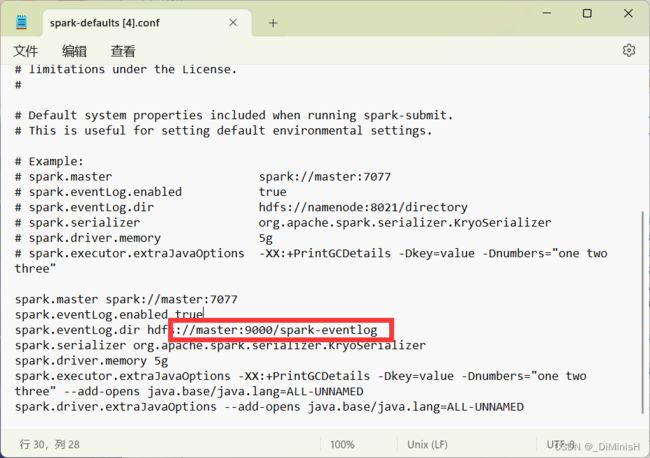
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 5g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three" --add-opens java.base/java.lang=ALL-UNNAMED
spark.driver.extraJavaOptions --add-opens java.base/java.lang=ALL-UNNAMED
其他的虚拟机也要修改
接下来关闭spark,再启动
关闭使用 ./stop-all.sh, 注意要在spark的sbin目录下

再计算PI

这次出现了running,表示正在计算中,说明一切正常
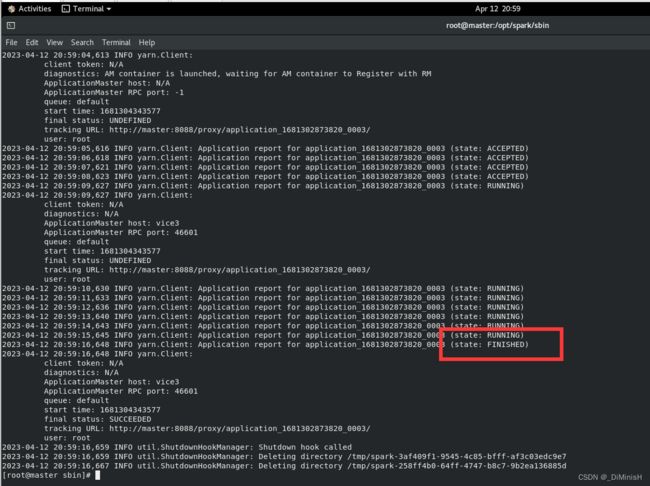
执行结束
(5)查看运行结果
访问下面的url
http://主节点IP地址:8088/cluster
点击下面最后一次的id,因为前两次都出现了错误,所以点开看不到计算结果
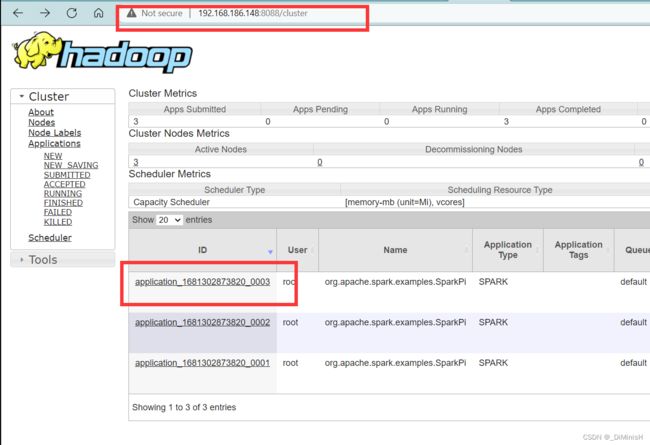
进来后点击Logs
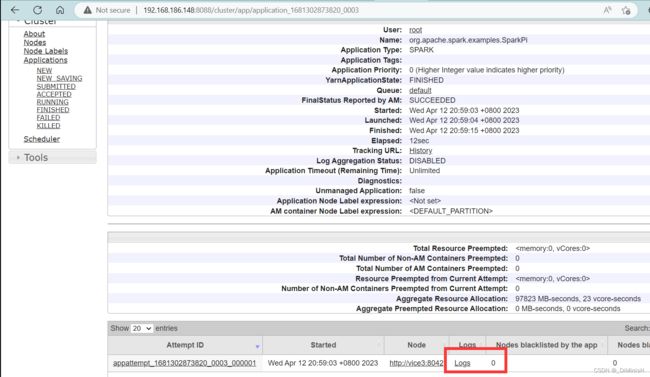
如果进不去这个页面
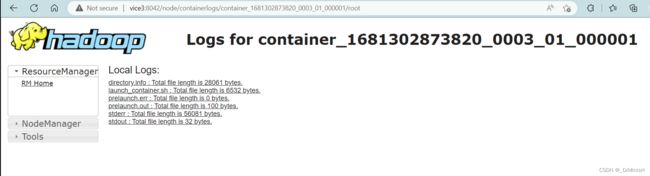
把vice3换成对应虚拟机的ip地址就可以访问了
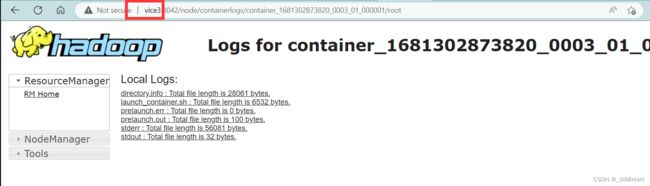
接下来点击stdout
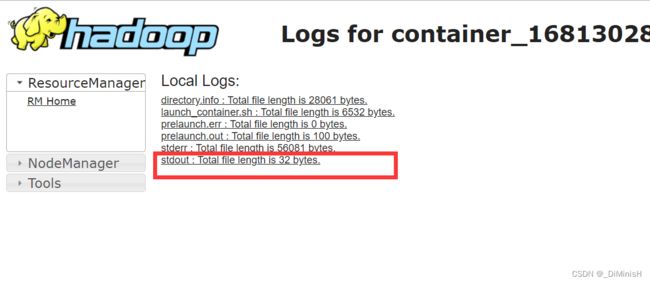
可以看到出现了结果PI
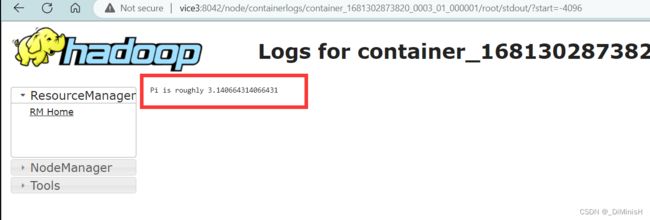
此时说明,spark集群搭建成功,hadoop集群搭建成功