二、postgre数据库SQL优化:查看执行计划
目录
-
- 一、前言
- 二、执行计划(explain)
-
- 2.1 执行计划
- 2.2 explain语法简介
- 2.3 执行计划节点类型
- 2.4 示例讲解
- 2.5 explain可视化
- 三、参考资料
一、前言
上一篇(一、postgre数据库SQL优化:相关视图介绍)总结了辅助记录相关活动的视图信息,借助这些统计信息,可以帮助我们检测或者分析程序运行的状态,及时发现相关问题并优化处理。本文在此基础上,进一步总结如何分析慢查询和查看执行计划。
注意:在 SQL 标准中没有EXPLAIN语句。
二、执行计划(explain)
2.1 执行计划
pg在查询规划路径过程中,查询请求的不同执行方案是通过建立不同的路径来表达的,在生成较多符合条件的路径之后,要从中选择出代价最小的路径,把它转化为一个执行计划,传递给执行器执行。那么如何生成最小代价的计划呢?基于统计信息估计计划中各个节点的成本,其中与之相关的参数如下所示1:
show seq_page_cost; -- 顺序扫描磁盘单个页面的开销
show cpu_tuple_cost; -- cpu处理每一行的开销
show cpu_operator_cost; -- cpu处理每个运算符/函数调用的开销
select relpages, -- 磁盘页
reltuples -- 行数
from pg_class where relname='b_kjs_zyzx_hl';
计算代价:
估算代价:
total_cost = seq_page_cost * relpages + cpu_tuple_cost * reltuples
有时我们不想用系统默认的执行计划,这时可以通过禁止/开启某种运算的语法来强制控制执行计划:
enable_bitmapscan = on
enable_hashagg = on
enable_hashjoin = on
enable_indexscan = on #索引扫描
enable_indexonlyscan = on #只读索引扫描
enable_material = on #物化视图
enable_mergejoin = on
enable_nestloop = on
enable_seqscan = on
enable_sort = on
enable_tidscan = on
按照上面扫描方式并过滤代价:
Cost = seq_page_cost * relpages + cpu_tuple_cost * reltuples + cpu_operation_cost * reltuples
每个SQL语句都会有自己的执行计划,显示一个语句的执行计划,我们可以使用explain指令来获取。
2.2 explain语法简介
explain指令的语法结构2:
EXPLAIN [ ( option [, …] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
这里的 option可以是下列之一:
ANALYZE [ boolean ] – 是否真正执行,默认false
VERBOSE [ boolean ] – 是否显示详细信息,默认false
COSTS [ boolean ] – 是否显示代价信息,默认true
BUFFERS [ boolean ] – 是否显示缓存信息,默认false,前置事件是analyze
TIMING [ boolean ] – 是否显示时间信息
FORMAT { TEXT | XML | JSON | YAML } – 输格式,默认为text
这条命令显示PostgreSQL规划器为所提供的语句生成的执行规划。 执行规划显示语句引用的表是如何被扫描的(简单的顺序扫描,还是索扫描),并且如果引用了多个表, 采用了什么样的连接算法从每个输入的表中取出所需要的记录。
显示出来的最关键的部分是预计的语句执行开销,这就是规划器对运行该语句所需时间的估计 (以任意的开销单位计量,但是通常意味着磁盘页面存取)。实际上显示了两个数字: 返回第一行记录前的启动开销,和返回所有记录的总开销。对于大多数查询而言,关心的是总开销, 但是,在某些环境下,比如一个EXISTS子查询里, 规划器将选择最小启动开销而不是最小总开销(因为执行器在获取一条记录后总是要停下来)。 同样,如果你用一条LIMIT子句限制返回的记录数, 规划器会在最终的开销上做一个合理的插值以计算哪个规划开销最省。
ANALYZE选项导致查询被实际执行,而不仅仅是规划。显示中加入了实际的运行时间统计, 包括在每个规划节点内部花掉的总时间(以毫秒计)和它实际返回的行数。 这些数据对搜索该规划器的预期是否和现实相近很有帮助。
重要: 要记住的是查询实际上在使用ANALYZE选项的时候是执行的。 尽管EXPLAIN会抛弃任何SELECT返回的输出, 但是其它查询的副作用还是一样会发生的。如果你在INSERT, UPDATE, DELETE, CREATE TABLE AS, EXECUTE 语句里使用EXPLAIN ANALYZE而且还不想让查询影响数据,可以用下面的方法:
BEGIN;
EXPLAIN ANALYZE …;
ROLLBACK;
只能声明ANALYZE和VERBOSE选项,并且只能以那种顺序, 不能将选项列表放在圆括号中。PostgreSQL 9.0之前, 只支持不用圆括号的语法。人们希望只在圆括号语法中支持所有新的选项。
参数
- ANALYZE:执行命令并显示实际运行时间和其他统计。这个参数缺省为FALSE。
VERBOSE:显示关于规划的额外的信息。特别的包括规划树上的每个节点的输出字段列表, 模式修饰表和函数名,表达式中的标签变量总是和他们的范围表别名在一起, 并且总是打印统计数据中显示的每个触发器的名字。这个参数缺省为FALSE。- COSTS:包括每个规划节点的估计启动成本和总成本的信息,也包括估计行数和估计的每行的宽度。 这个参数缺省为TRUE。
- BUFFERS:包含缓冲区使用的信息。特别的,包括共享块命中、读、脏和写的次数,本地块命中、读、脏和写的次数, 临时块读和写的次数。命中意味着避免了读,因为块在需要时已经在缓存中发现了。 共享块包含普通表和索引的数据;本地块包含临时表和索引的数据;而临时块包含用于排序、哈希、 物化规划节点和相似情况的短期工作数据。脏块的数量表示这个查询改变的先前未更改的块的数量; 写块的数量表示在查询处理的时候被这个后端驱逐出缓存的先前脏了的块的数量。 高级节点显示的块的数量包含所有它的子节点使用的块的数量。在文本格式中,只打印非零值。 这个参数可能只在ANALYZE也启用的时候使用。它的缺省为FALSE。
- TIMING:在输出中包含实际启动时间和每个节点花费的时间。重复读系统块的总开销会在某些系统上显著的减缓查询的速度, 所以当需要只有实际行被计算,并且没有准确时间时,设置这个参数为FALSE会很有用。 即使是用这个选项关闭了节点级别的时间,也测量整个语句的运行时间。 这个参数可能只在ANALYZE也启用的时候使用。它缺省为TRUE。
- FORMAT:声明输出格式,可以为TEXT, XML, JSON 或 YAML。非文本的输出包含文本输出格式相同的信息, 但是更容易被程序解析。这个参数缺省为TEXT。
- boolean:声明选中的选项打开或者关闭。可以用TRUE, ON 或 1 启用这个选项,用FALSE, OFF 或 0 禁用这个选项。在假设为TRUE的情况下, boolean值也可以忽略,
- statement:你想要查看执行规划的任何SELECT、INSERT、UPDATE、 DELETE、VALUES、EXECUTE、DECLARE、 CREATE TABLE AS或CREATE MATERIALIZED VIEW AS语句之一。
输出
命令的结果是从statement选择的规划的文字描述, 可选的有执行统计数据的注释。3描述提供的信息。
2.3 执行计划节点类型
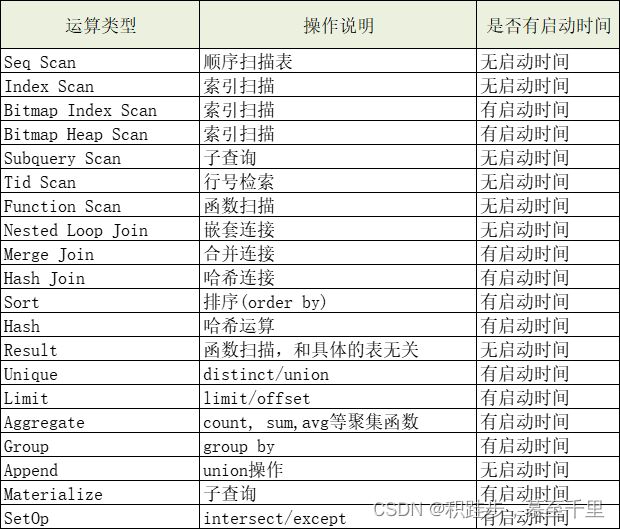
在PostgreSQL的执行计划中,是自上而下阅读的,通常执行计划会有相关的索引来表示不同的计划节点,其中计划节点类型分为四类:
- 控制节点(Control Node)
- 扫描节点(Scan Node)
- 物化节点(Materialization Node)
- 连接节点(Join Node)。
-
控制节点:append,组织多个字表或子查询的执行节点,主要用于union操作。
-
扫描节点:用于扫描表等对象以获取元组
- Seq Scan(全表扫描):把表的所有数据块从头到尾读一遍,筛选出符合条件的数据块;
- Index Scan(索引扫描):为了加快查询速度,在索引中找到需要的数据行的物理位置,再到表数据块中把对应数据读出来,如B树,GiST,GIN,BRIN,HASH
- Bitmap Index/Heap Scan(位图索引/结果扫描):把满足条件的行或块在内存中建一个位图,扫描完索引后,再根据位图列表的数据文件把对应的数据读出来,先通过Bitmap Index Scan在索引中找到符合条件的行,在内存中建立位图,之后再到表中扫描Bitmap Heap Scan。
- 物化节点:能够缓存执行结果到缓存中,即第一次被执行时生成的结果元组缓存,等待上层节点使用,例如,sort节点能够获取下层节点返回的所有元组并根据指定的属性排序,并将排序结果缓存,每次上层节点取元组时就从缓存中按需读取。
- Materialize:对下层节点返回的元组进行缓存(如连接表时)
- Sort:对下层返回的节点进行排序(如果内存超过iwork_mem参数指定大小,则节点工作空间切换到临时文件,性能急剧下降)
- Group:对下层排序元组进行分组操作
- Agg:执行聚集函数(sum/max/min/avg)
.
条件过滤,一般在where后加上过滤条件,当扫描数据行时,会找出满足过滤条件的行,条件过滤在执行计划里面显示Filter,如果条件的列上面有索引,可能会走索引,不会走过滤。
- 连接节点:对应于关系代数中的连接操作,可以实现多种连接方式(条件连接/左连接/右连接/全连接/自然连接)
- Nestedloop Join(嵌套连接): 内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大,要把返回子集较小的表作为外表,且内表的连接字段上要有索引。 执行过程为,确定一个驱动表(outer table),另一个表为inner table,驱动表中每一行与inner table中的相应记录关联;
- Hash Join(哈希连接):优化器使用两个比较的表,并利用连接属性在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行;
- Merge Join(合并连接):通常hash连接的性能要比merge连接好,但如果源数据上有索引,或结果已经被排过序,这时merge连接性能会优于hash连接;
运算类型(explain)
2.4 示例讲解
慢sql如下:
SELECT
te.event_type,
sum(tett.feat_bytes) AS traffic
FROM t_event te
LEFT JOIN t_event_traffic_total tett
ON tett.event_id = te.event_id
WHERE
((te.event_type >= 1 AND te.event_type <= 17) OR (te.event_type >= 23 AND te.event_type <= 26) OR (te.event_type >= 129 AND te.event_type <= 256))
AND te.end_time >= '2017-10-01 09:39:41+08:00'
AND te.begin_time <= '2018-01-01 09:39:41+08:00'
AND tett.stat_time >= '2017-10-01 09:39:41+08:00'
AND tett.stat_time < '2018-01-01 09:39:41+08:00'
GROUP BY te.event_type
ORDER BY total_count DESC
LIMIT 10
耗时:约4s
作用:事件表和事件流量表关联,查出一段时间内按照总流量大小排列的TOP10事件类型。
-- 记录数:
select count(1) from t_event; -- 535881条
select count(1) from t_event_traffic_total; -- 2123235条
---------- 结果: -------------------
event_type traffic
17 2.26441505638877E17
2 2.25307250128674E17
7 1.20629298837E15
26 285103860959500
1 169208970599500
13 47640495350000
6 15576058500000
3 12671721671000
15 1351423772000
11 699609230000
执行计划:
Limit (cost=5723930.01..5723930.04 rows=10 width=12) (actual time=3762.383..3762.384 rows=10 loops=1)
Output: te.event_type, (sum(tett.feat_bytes))
Buffers: shared hit=1899 read=16463, temp read=21553 written=21553
-> Sort (cost=5723930.01..5723930.51 rows=200 width=12) (actual time=3762.382..3762.382 rows=10 loops=1)
Output: te.event_type, (sum(tett.feat_bytes))
Sort Key: (sum(tett.feat_bytes))
Sort Method: quicksort Memory: 25kB
Buffers: shared hit=1899 read=16463, temp read=21553 written=21553
-> HashAggregate (cost=5723923.69..5723925.69 rows=200 width=12) (actual time=3762.360..3762.363 rows=18 loops=1)
Output: te.event_type, sum(tett.feat_bytes)
Buffers: shared hit=1899 read=16463, temp read=21553 written=21553
-> Merge Join (cost=384982.63..4390546.88 rows=266675361 width=12) (actual time=2310.395..3119.886 rows=2031023 loops=1)
Output: te.event_type, tett.feat_bytes
Merge Cond: (te.event_id = tett.event_id)
Buffers: shared hit=1899 read=16463, temp read=21553 written=21553
-> Sort (cost=3284.60..3347.40 rows=25119 width=12) (actual time=21.509..27.978 rows=26225 loops=1)
Output: te.event_type, te.event_id
Sort Key: te.event_id
Sort Method: external merge Disk: 664kB
Buffers: shared hit=652, temp read=84 written=84
-> Append (cost=0.00..1448.84 rows=25119 width=12) (actual time=0.027..7.975 rows=26225 loops=1)
Buffers: shared hit=652
-> Seq Scan on public.t_event te (cost=0.00..0.00 rows=1 width=12) (actual time=0.001..0.001 rows=0 loops=1)
Output: te.event_type, te.event_id
Filter: ((te.end_time >= '2017-10-01 09:39:41+08'::timestamp with time zone) AND (te.begin_time <= '2018-01-01 09:39:41+08'::timestamp with time zone) AND (((te.event_type >= 1) AND (te.event_type <= 17)) OR ((te.event_type >= 23) AND (te.event_type <= 26)) OR ((te.event_type >= 129) AND (te.event_type <= 256))))
-> 扫描子表过程,省略...
-> Materialize (cost=381698.04..392314.52 rows=2123296 width=16) (actual time=2288.881..2858.256 rows=2123235 loops=1)
Output: tett.feat_bytes, tett.event_id
Buffers: shared hit=1247 read=16463, temp read=21469 written=21469
-> Sort (cost=381698.04..387006.28 rows=2123296 width=16) (actual time=2288.877..2720.994 rows=2123235 loops=1)
Output: tett.feat_bytes, tett.event_id
Sort Key: tett.event_id
Sort Method: external merge Disk: 53952kB
Buffers: shared hit=1247 read=16463, temp read=21469 written=21469
-> Append (cost=0.00..49698.20 rows=2123296 width=16) (actual time=0.026..470.610 rows=2123235 loops=1)
Buffers: shared hit=1247 read=16463
-> Seq Scan on public.t_event_traffic_total tett (cost=0.00..0.00 rows=1 width=16) (actual time=0.001..0.001 rows=0 loops=1)
Output: tett.feat_bytes, tett.event_id
Filter: ((tett.stat_time >= '2017-10-01 09:39:41+08'::timestamp with time zone) AND (tett.stat_time < '2018-01-01 09:39:41+08'::timestamp with time zone))
-> 扫描子表过程,省略...
Total runtime: 3771.346 ms
1.说明:
阅读顺序:从下到上(从左到右),(按照剪头->)我们可以看到是有层次的,我们应该从最底层(即最里面的)开始看。每行的大致规律:操作描述+(估计成本/代价/开销)+条件。
2.执行计划解读:
第40->30行:通过结束时间上创建的索引,顺序扫描t_event_traffic_total表,根据时间跨度三个月过滤出符合条件的数据,共2123235条记录;
第26->21行:根据时间过滤出t_event表中符合条件的记录,共26225条记录;
第30->27行:根据流量大小排序,执行sort操作;
第12->09行:两个表执行join操作,执行完记录200条;
第08->04行:对最终的200条记录按照大小排序;
第01行:执行limit取10条记录。
整个执行计划中花时间最长的是根据时间条件过滤t_event_traffic_total表,因为字表较多,记录较多,导致花费2.8s之多,所以我们优化的思路就比较简单了,直接根据actual time,花费较多的子表去查看表中是否有索引,以及记录是不是很多,有没有优化的空间,而经过排查,发现一个子表中的数据量达到1531147条。
2.5 explain可视化
explain可视化4
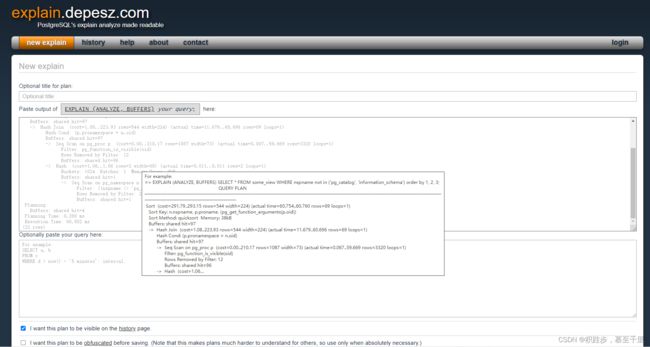
例如上面这个例子,可视化之后是这样的5
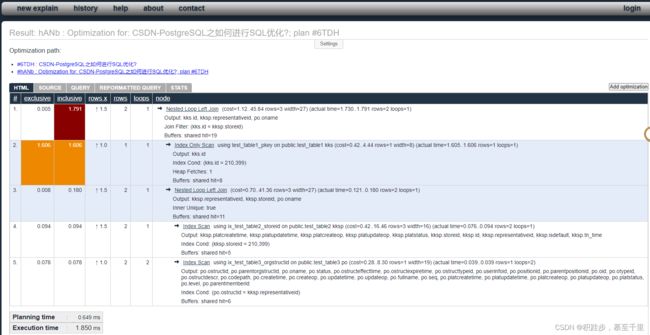
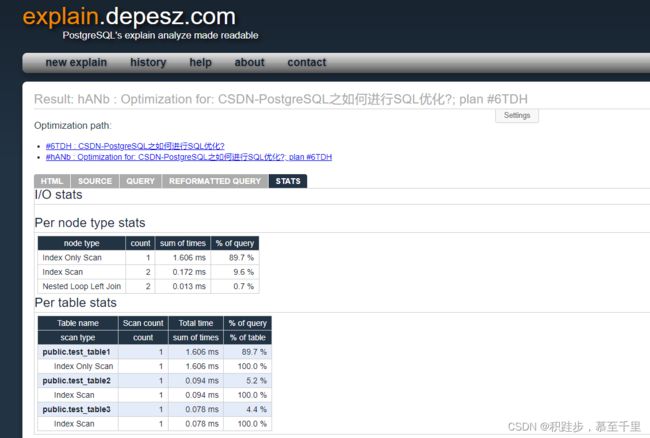
汇总分析:
三、参考资料
- [1]PostgreSQL执行计划:https://blog.csdn.net/JAVA528416037/article/details/91998019
- [2]PostgreSQL 9.4.4 中文手册-explain:http://postgres.cn/docs/9.4/sql-explain.html
- [3]PostgreSQL 9.4.4 中文手册-性能提升技巧:http://postgres.cn/docs/9.4/using-explain.html
- [4]explain.depesz.com
- [5]https://explain.depesz.com/s/hANb#html