测试中使用定位搜索框搜索内容_测开系列Selenium Webdriver Python(21)--元素定位1...

元素定位 转帖请注明出处!谢谢
在做自动化的过程中只要掌握四步操作:获取元素,操作元素,获取返回结果,断言(返回结果与期望结果是否一致),最后自动出测试报告。所以在UI层面的自动化测试开发中,元素的定位与操作是基础。
find_element_by_id()作用:通过标签属性id查找元素
实例:
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
# get_webdriver代码实现在本书第一个webdriver脚本中
def login_discuz(driver,str_user,str_pwd):
#登录代码的实现在本书第一个webdriver脚本
def open_my_prompt(dirver):
time.sleep(2)
my_prompt=dirver.find_element_by_id('myprompt')
print(my_prompt)
my_prompt.click()
if __name__ == '__main__':
#用变量存储用户名,密码
str_user="admin"
str_pwd="admin"
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
login_discuz(wb,str_user,str_pwd)
open_my_prompt(dirver)技术解释:登录discuz后,用webdriver的find_element_by_id方法定位到页面‘提醒‘元素,该函数的参数id是HTML代码中的id属性。为了获得id属性,在打开的网页上鼠标点选要获得的元素右键,出现菜单后,点击“使用filebug查看该元素”,得到提醒代码,该元素有id为myprompt,把它作为参数传给webdriver脚本find_element_by_id方法。
find_element_by_name()作用:标签属性name查找元素
实例:登录discuz论坛,测试搜索框功能,搜索关键字"最漂亮的模版"
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
# get_webdriver代码实现在本书第一个webdriver脚本中
def login_discuz(driver,str_user,str_pwd):
#登录代码的实现在本书第一个webdriver脚本
def search_function(driver,kkeyword):
ctxt_search = driver.find_element_by_name('srchtxt')
ctxt_search.clear()
ctxt_search.send_keys(kkeyword)
btn_sumbit_search = driver.find_element_by_name('searchsubmit')
btn_sumbit_search.click()
search_winhadle=driver.window_handles[1]
driver.switch_to.window(search_winhadle)
print('窗体标题:'+driver.title)
if driver.title=='搜索 - Discuz! Board - Powered by Discuz!':
print('搜索页面窗口打开正确')
else:
print('搜索页面窗口打开错误')
if __name__ == '__main__':
#用变量存储用户名,密码
str_user="admin"
str_pwd="admin"
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
login_discuz(wb,str_user,str_pwd)
time.sleep(2)
search(wb,'最漂亮的模版')技术解释:登录discuz后,用webdriver的driver.find_element_by_name方法定位到页面搜索框元素,该函数的参数name是HTML代码中的input的name属性。打开的discuz首页鼠标点选要获得的元素搜索框元素右键,出现菜单点击“使用filebug查看该元素”,得到HTML代码,元素name属性值为srchtxt,把它作为参数传给webdriver脚本find_element_by_name。
find_element_by_class_name()作用:通过标签的class属性查找元素
实例: 获得当前网站的在线用户数据
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
# get_webdriver代码实现在本书第一个webdriver脚本中
def login_discuz(driver,str_user,str_pwd):
#登录代码的实现在本书第一个webdriver脚本
def get_online_data(driver):
online_data = driver.find_element_by_class_name('xs1')
print(online_data.text)
str_data = online_data.text
data_list = str_data.split(',')
online_user = data_list[0].split('-')
online_user_start = online_user[1].index(' ')
online_user_end = online_user[1].index('人')
online_user_data = online_user[1][online_user_start + 1:online_user_end - 1]
print('在线用户:' + online_user_data)
member_start = online_user[2].index(' ')
member_end = online_user[2].index('会')
member_data = online_user[2][member_start + 1:member_end - 1]
print('会员用户:' + member_data)
visitor_list = data_list[1].split('-')
visitor_start = data_list[1].index(' ')
visitor_end = data_list[1].index('位')
visitor_data = visitor_list[0][visitor_start + 1:visitor_end - 1]
print('有游客:' + visitor_data)
if __name__ == '__main__':
#用变量存储用户名,密码
str_user="admin"
str_pwd="admin"
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
login_discuz(wb,str_user,str_pwd)
time.sleep(2)
get_online_data(wb)技术解释:online_data = driver.find_element_by_class_name('xs1')主要是获取discuz论坛下方的在线用户信息。通过firebug获得HTML展示信息用的页面标签是,该标签属性只有一个class,值是xs1,获得的信息字符串是str_data =['- 1 人在线 - 1 会员(0 隐身)', ' 0 位游客 - 最高记录是 4 于 2017-11-12.'],用data_list = str_data.split(',')代码把字符串按照逗号分开成一个列表,用online_user分别保存'- 1 人在线 - 1 会员(0 隐身)'和' 0 位游客 - 最高记录是 4 于 2017-11-12.'。再次用slipit按照‘-’字符分解online_user[0]和online_user[1]。online_user[0]保存列表['', ' 1 人在线 ', ' 1 会员(0 隐身)'],分别截取字符online_user[0][1], online_user[0][2]中的在线人数和在会员人数。同理截取online_user[1]中要获得的数据。
find_element_by_tag_name()作用:通过标签名tagname查找元素,find_element_by_tag_name查找到的是第一个标签的tag_name
实例:获取discuz站点会员统计数据(只有管理员才能见到站点统计链接)
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
# get_webdriver代码实现在本书第一个webdriver脚本中
def login_discuz(driver,str_user,str_pwd):
#登录代码的实现在本书第一个webdriver脚本
def get_member_statistics(driver):
link_site_statistics = driver.find_element_by_link_text('站点统计')
link_site_statistics.click()
time.sleep(2)
table_site_statistics = driver.find_element_by_class_name('dt') # 获得会员统计表格元素
# print(table_site_statistics)
table_rows = table_site_statistics.find_elements_by_tag_name('tr') # 获得会员统计表格元素中的tr元素,tr标签代表的是行
for irow in range(0, len(table_rows)):
table_cols_head = table_rows[irow].find_elements_by_tag_name('th')
table_cols_content = table_rows[irow].find_elements_by_tag_name('td')
for icol in range(0, len(table_cols_content)):
print(table_cols_head[icol].text + ':' + table_cols_content[icol].text)技术解释:登陆discuz论坛后点击页面下方的站点统计链接,打开站点统计页面,在站点统计页面右侧是两个表格,分别是会员统计和站点统计:
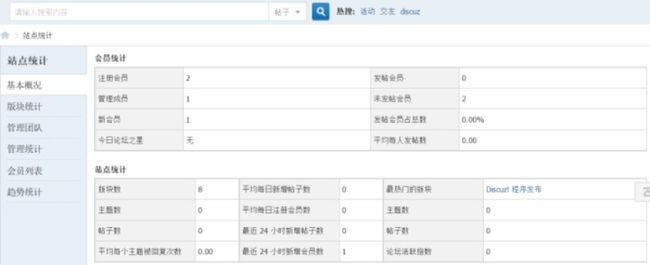
代码解析会员统计表格,先执行代码wb.find_element_by_class_name('dt')获得会员表格元素,通过firebug得到会员统计表格元素的HTML代码是

| 第一 | 第二 | 第三 |
获取td标签中第一个Webelement,可以用CSS结构性伪类选择器中的:first-child,获取表格标签
find_element_by_css_selector("td:first-child")获取td标签中的第三个webelement,用CSS结构性伪类选择器:nth-child(3),口号中传入索引值,就会获取到
find_element_by_css_selector("td:nth-child(3)")实例七:
最后用不同的CSS选择器来抓取同一个Webelement,对比下,HTML代码如下:
我們欲抓取第 2 行的 input element,可以透過下列方法抓取到 input element,使用者根據不同的結構選擇不同的定位方式。
find_element_by_css_selector("#testinput")
find_element_by_css_selector("input")
find_element_by_css_selector("div input")
find_element_by_css_selector("div input#testinput")
find_element_by_css_selector("div.dgl input")
find_element_by_css_selector("div.dgl input#testinput")
find_element_by_css_selector("div input[value='sohu']")
find_element_by_css_selector("div[class='testdiv'] input[value='sohu']
find_element()作用: 通过参数传递,结合By方法查找元素,声明find_element(self, by, value=None)
实例:用find_element方法改写discuz论坛登陆代码
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
from selenium.webdriver.common.by import By
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
def login_discuz(driver,str_user,str_pwd):
ctxt_user=driver.find_element(By.ID,'ls_username') #用find_element_by_name方法找到用户名输入框
ctxt_user.clear()#清空用户名输入框内容
ctxt_user.send_keys(str_user) #输入用户名
ctxt_pwd=driver.find_element(By.CSS_SELECTOR, '#ls_password') #用find_element_by_name方法找到密码名输入框
ctxt_pwd.clear()#清空密码输入框内容
ctxt_pwd.send_keys(str_pwd) #输入密码
cbtn_submit=driver.find_element(By.XPATH,'.//*[@id='lsform']/div/div/table/tbody/tr[2]/td[3]/button')
cbtn_submit.submit()
if __name__ == '__main__':
#用变量存储用户名,密码
str_user="admin"
str_pwd="admin"
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
time.sleep(2)
login_discuz(wb,str_user,str_pwd)技术解释:find_element()有两个参数第一个参数是By类,第二个参数是选择器字符串,Webdriver在调用find_element定位元素主要是根据By类调用的类型来传递第二个选择器字符串参数。在跟踪find_element_by_xxx方法的实现过程,追踪find_element_by_id源码:
def find_element_by_id(self, id_):
"""Finds an element by id.
:Args:
- id_ - The id of the element to be found.
:Usage:
driver.find_element_by_id('foo')
"""
return self.find_element(by=By.ID, value=id_)
调用的就是find_element方法,只是传入的By类属性为ID,追踪By类查看源码:
class By(object):
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"通过以上追踪,发现find_element就是find_element_by_xxx等方法的最终实现。
在上面脚本中乃至前面的实例脚本都多次看到time.sleep方法的出现,这是因为学习过程中多次发现SeleniumWebdriver自动化测试脚本运行并不是很稳定。经常会遇到系统明明正常运行,但是测试却失败的情况。在实际工作中,例如测试CRM系统,有一个修改用户拜访信息功能,测试场景是任一销售人员搜索最近一个月拜访的客户,找到最近一次拜访的客户信息,然后修改。在开发这个脚本过程中,脚本经常会失败,出现问题在测试脚本执行每次以销售人员登陆系统后,点击搜索用户信息按钮后,执行失败。因为每次搜索的用户信息结果没有展现在页面之前,Webdriver自动化脚本就开始执行下一步,因为元素定位不到,脚本就会报错,即使加上了除错处理,但是因为找不到元素,导致业务脚本没办法测试该业务功能,也是脚本运行失败。
出现前面问题的原因有可能是服务器响应速度慢,在页面内容从服务器端返回到客户端的时候,Webdriver就执行了下一行脚本,从而导致测试失败。测试脚本开发人员可能会加上time.sleep方法等待几秒,但是在搜索客户信息的场景中,如果服务器反馈的信息超过了睡眠时间,脚本仍然会报错。因为服务器后台数据处理速度,会因为数据量的规模大小而时间长短不同。后台数据越大,使用的用户越多如更多的销售人员同时检索,服务器端的负载就会越高,造成服务器的响应速度会更慢。所以测试脚本即使用睡眠等待的方法,仍然会有执行失败的情况出现。
自动化测试工具为了解决脚本执行速度和被测试系统执行速度相匹配的功能提供了同步点的解决办法。Selenium Webdriver提供了处理该类型场景问题的解决办法有两类:一种是隐式等待,一种是显示等待:
- 隐式等待:
如果因某种原因,被测试对象没有出现,Webdriver将等待指定的时间,在等待时间内,它不会去找被测试对象。一旦超过指定的等待时间限制,webdriver将再次在页面中搜索该元素。如果成功,将继续进行执行后续的脚本,但如果失败,它会抛出异常。
- 方法一:
import time
time.sleep(2) #默认等待2秒
- 方法二:
通过下面代码来设置selenium内置的智能等待时间
from selenium import webdriver #导入浏览器驱动
wb.get('http://www.discuz.net/forum.php') #打开bbs项目首页地址
wb.implicitly_wait(10) #设置智能等待10秒
time.sleep方法是固定等待时间,该行代码放在需要等待的时间,它的作用是局部的,而implicitly_wait(n秒)方法的功能是不论脚本运行在那一步,webdriver都需要等待xx秒,它是全局的。如果在等待的xx秒内被测试系统完成了Webdriver对应的脚本操作,则webdriver脚本正常继续执行;如果超出了xx秒,被测试系统没有完成Webdriver对应的脚本操作,因为脚本继续执行导致找不到后续的被测试对象,Webdriver会因为脚本运行失败抛出异常。该方法起等待的作用是全局性的,意思是在整个脚本的执行过程中都起作用。这种方式的缺点是,对象有可能在你等待的时间内出现,而你因为要满足隐含的等待时间而延长自动化脚本的执行时间。
- 显式等待:
是一种明确的等待方式,当满足条件后再进一步处理后续的脚本。可以真正做到测试脚本和被测试软件执行的速度相匹配,避免了隐性等待缺点。Webdriver是用WebDriverWait类,辅以until()或until_not()方法来实现,它是根据判断条件进行灵活的同步。如:
from selenium.webdriver.support.wait import WebDriverWait
# 使用selenium提供的WebDriverWait方法,每0.5秒检查一次定位的元素,超时设置是2秒
WebDriverWait(browser, 2).until( lambda driver: driver.find_element_by_tag_name('input'))
基于以上知识,我们修改搜索功能脚本,添加智能等待:
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
from selenium.webdriver.support.ui import WebDriverWait
def get_webdriver(url):
# get_webdriver代码实现在本书第一个webdriver脚本中
def login_discuz(driver,str_user,str_pwd):
#登录代码的实现在本书第一个webdriver脚本
def open_my_prompt(dirver):
time.sleep(2)
my_prompt=dirver.find_element_by_id('myprompt')
print(my_prompt)
my_prompt.click()
def search(driver,kkeyword):
ctxt_search = driver.find_element_by_name('srchtxt')
ctxt_search.clear()
ctxt_search.send_keys(kkeyword)
btn_sumbit_search = driver.find_element_by_name('searchsubmit')
btn_sumbit_search.click()
search_winhadle=driver.window_handles[1]
driver.switch_to.window(search_winhadle)
WebDriverWait(driver, 2).until(lambda driver: driver.find_element_by_class_name('emfont'))
print('窗体标题:'+driver.title)
if driver.title=='搜索 - Discuz! Board - Powered by Discuz!':
print('搜索页面窗口打开正确')
else:
print('搜索页面窗口打开错误')
if __name__ == '__main__':
#用变量存储用户名,密码
str_user="admin"
str_pwd="admin"
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
login_discuz(wb,str_user,str_pwd)
time.sleep(2)
search(wb,'最漂亮的模版')元素操作
在自动化测试过程中要控制元素动作,输入相应数据,验证元素执行结果,这才是完整的测试。Selenium Webdriver有提供了element接口帮助测试人员实现相应的功能。
- element.属性值:
- element.size:获取元素的尺寸。
实例:获得discuz论坛官方论坛的logo图标尺寸
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
img_forum=wb.find_element_by_xpath('.//*[@id='category_lk']/ul[1]/li/img')
print(img_forum.size)运行结果:
{'height': 31.0, 'width': 88.0}- element.text:获取元素的文本。
实例:获取导航栏上的所有外部链接地址的文本内容
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url = r'http://192.168.0.110/discuz/forum.php'
wb = get_webdriver(discuz_url)
for i in range(1,7):
link=wb.find_element_by_xpath('.//*[@id='mn_P'+str(i)+'']/a')
print(link.text)运行结果:
腾讯云主机
Discuz!实验室
服务购买
应用中心
微社区
在线体验
- element.tag_name:获取标签名称。
实例:获得主页面的搜索按钮的tagname
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) '
return driver
if __name__ == '__main__':
discuz_url = r'http://192.168.0.110/discuz/forum.php'
wb = get_webdriver(discuz_url)
link=wb.find_element_by_xpath('.//*[@id='scbar_btn']')
print(link.tag_name)- 方法:
- element.clear():清除文本。
实例:打开discuz论坛,在搜索输入框输入“模板”,并清空搜索文本框
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
ctxt_search = wb.find_element_by_name('srchtxt')
ctxt_search.send_keys('模板')
ctxt_search.clear()- element.send_keys(value):输入文字或键盘按键(需导入Keys模块)。
实例:设置搜索类型为用户类型。就是首页搜索框旁边的下拉列表,选择用户
import time
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
link = wb.find_element_by_xpath('.//*[@id='scbar_type']')
link.click()
time.sleep(1)
user = wb.find_element_by_xpath('.//*[@id='scbar_type_menu']/li[2]/a')
user.click()- element.click():单击元素。
实例:打开discuz论坛最新回复链接
from selenium import webdriver #加载selenium库
from selenium.webdriver.common.keys import Keys #加载selenium键盘定义库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
link = wb.find_element_by_xpath('.//*[@id='chart']/div/a')
link.click()- element.get_attribute(name):获取对象的内容和属性
实例:获取论坛板块Discuz! 程序发布的链接
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
bbs_forum=wb.find_element_by_link_text('Discuz! 程序发布')
str_href=bbs_forum.get_attribute('href')
print('论坛链接是:'+str_href)- element.is_displayed():返回元素结果是否可见(True 或 False)
实例:检查discuz论坛logo是否正常显示
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url=r'http://192.168.0.110/discuz/forum.php'
wb=get_webdriver(discuz_url)
img_logo=wb.find_element_by_xpath('.//*[@id='hd']/div/div[1]/h2/a/img')
if img_logo.is_displayed():
print('logo图片显示正常')
else:
print('logo图片没有显示')- element.is_selected():返回元素结果是否被选中(True 或 False)
实例:选中自动登录选项
from selenium import webdriver #加载selenium库
def get_webdriver(url):
driver=webdriver.Firefox()#创建webdriver的firefox实例
driver.get(url) #打开bbs项目首页地址:r'http://192.168.0.110/discuz/forum.php'
return driver
if __name__ == '__main__':
discuz_url = r'http://192.168.0.110/discuz/forum.php'
wb = get_webdriver(discuz_url)
select=wb.find_element_by_xpath('.//*[@id='lsform']/div/div/table/tbody/tr[1]/td[3]/label')
select.click()
if select.is_selected():
print('自动登录已经选中')
else:
print('自动登录已经选中')