Activity的启动模式及应用
1:standard:standard模式是默认的启动模式
2:singleTop:寻找是否有一个MainActivity实例正位于栈顶,如果有则不再生成新的,而是直接使用。没有的话会再生产一个新的:
例如,某个新闻客户端的新闻内容页面,如果收到10个新闻推送,每次都打开一个新闻内容页面是很烦人的。
3:singleTask:改属性的页面的序列号是不变的,说明新打开的页面,没有生成新的实例,但是从MainActivity跳转到SecondActivity时生成了新的实例。
适合作为程序入口点。例如浏览器的主界面。不管从多少个应用启动浏览器,只会启动主界面一次,
4:singleInstance:重新启用了一个新的栈结构,来放置该属性的页面实例
比如:A -> B (singleInstance) -> C,完全退出后,在此启动,首先打开的是B。
2:Activity和Fragment数据交互
1:我们在Activity创建Fragment同时可以把一些数据通过setArgument()传递到Fragment。这是最基本的传值方式了,示例代码如下:
testFragment = new SimpleFragment();
Bundle sendBundle = new Bundle();
sendBundle.putString("sendMessage","来自Activity首次创建Fragment传来的数据");
testFragment.setArguments(sendBundle);
然后在 接收:
Bundle b = getArgument();if(null != b){
String message = b.getString("sendMessage");
}
2:在Fragment 创建之后在传值的话需要 接口 来实现 : void onTypeClick(String message); 然后在在fragment 去实现 他 最后在activity 中去调用这个接口 mFragmentListener.onTypeClick("来自Activity的实时数据"+tapCounts);
3:fragment传值到activity,同样的使用接口的方式,只不过跟前面反着来就是了
3:线程间交互的方法:
1::wait()、notify()、notifyaAl(),它们是多线程通信的基础,而这种实现方式的思想自然是线程间通信。
注意: wait和 notify必须配合synchronized使用,wait方法释放锁,notify方法不释放锁
2:基于 volatile 关键字来实现线程间相互通信是使用共享内存的思想
// 定义一个共享变量来实现通信,它需要是volatile修饰,否则线程不能及时感知
static volatile boolean notice = false;
4进程间交互
这又分成两种情况:
1 主线程->主线程 发送消息:在主线程中通过创建好的handler调用sendMessage()方法发送消息即可。
2 子线程->主线程 发送消息:在子线程中通过创建好的handler调用sendMessage()方法发送消息即可。
2 子线程->子线程 发送消息:在子线程中通过创建好的HnadlerThread是Thread的子类,是专门向子线程发送消息使用的 调用sendMessage()方法发送消息即可。最好runOnUiThread(() 更新
5:事件分发机制
一张图慢慢去理解 说多了也晕 总结一句话 :事件先传递到Activity中,Activity通过它的dispatchTouchEvent将事件分发到DecorView又会调用dispatchTouchEvent去进行事件分发,如果不拦截事件,那么就会继续下传到rootview,rootview中的操作是一样的,同样在dispatchTouchEvent内部调用onInterceptTouchEvent去判断是否拦截,不拦截就会把事件分发给下一个viewgroupA,拦截就直接在onTouchEvent返回true,viewgroupA中做的判断也是一样,最后事件传递到view1,view1是最底层控件,不会有onInterceptTouchEvent,它的选择就只有处理后不处理,处理就在onTouchEvent进行处理并返回true,不处理的话事件也不会被销毁,view1这时会把事件回传,经过上述流程后回传给activity,如果Activity还不处理,那么这个事件才会被销毁;
6:Handler、Looper、MessageQueue的关系
Message: 消息对象
MessageQueen: 存储消息对象的队列
Looper:负责循环读取MessageQueen中的消息,读到消息之后就把消息交给Handler去处理。
Handler:发送消息和处理消息
7:StringBuilder和StringBuffer的区别,StringBuffer的实现原理
1、StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,
2、只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,
而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
3、在单线程程序下,StringBuilder效率更快,因为它不需要加锁,不具备多线程安全
而StringBuffer则每次都需要判断锁,效率相对更低
7:View的绘制流程
View 绘制中主要流程分为measure,layout, draw 三个阶段。
measure :根据父 view 传递的 MeasureSpec 进行计算大小。onMeasure() 方法去测量设置 View 的大小。
layout :根据 measure 子 View 所得到的布局大小和布局参数,将子View放在合适的位置上。layout()
draw :把 View 对象绘制到屏幕上。onDraw(canvas) :绘制 View 的内容。View 的内容是根据自己需求自己绘制的,所以方法是一个空方法,View的继承类自己复写实现绘制内容。
8:MVC MVP MVVM的区别
mvvm模式将Presener改名为View Model,基本上与MVP模式完全一致,唯一的区别是,它采用双向绑定(data-binding): View的 变动,自动反映在View Model,反之亦然。这样开发者就不用处理接收事件和View更新的工作,框架已经帮你做好了。
9:Handler内存泄露:
原因:非静态的内部类持有了外部类的对象
①先说handler导致activity内存泄露的原因:
handler发送的消息在当前handler的消息队列中,如果此时activity finish掉了,那么消息队列的消息依旧会由handler进行处理,若此时handler声明为内部类(非静态内部类),我们知道内部类天然持有外部类的实例引用,这样在GC垃圾回收机制进行回收时发现这个Activity居然还有其他引用存在,因而就不会去回收这个Activity,进而导致activity泄露。
②为何handler要定义为static?
因为静态内部类不持有外部类的引用,所以使用静态的handler不会导致activity的泄露
③为何handler要定义为static的同时,还要用WeakReference 包裹外部类的对象?
这是因为我们需要使用外部类的成员,可以通过"activity. "获取变量方法等,如果直接使用强引用,显然会导致activity泄露。:
10:多线程机制
介绍:多个线程共享同一个进程的资源,但是栈内存是独立的,一个线程一个栈。所以他们仍然是在抢CPU的资源执行。一个时间点上只有能有一个线程执行。而且谁抢到,这个不一定,所以,造成了线程运行的随机性。其中的某一个进程如果执行路径比较多的话,就会有更高的几率抢到CPU的执行权。
实现:1:自定义类继承Thread类:
public class FirstThread extends Thread{
public void run(){
for(inti=0;i<100;i++){
System.out.println("Thread1\t"+i);
}}}
Thread t1=newFirstThread();t1.start();
2:该子类重写子类的run()方法
Threadt1=newThread(newRunnable(){@Overridepublicvoidrun(){for(inti=0;i<100;i++){System.out.println("thread1"+i);}}});
11:Service 类两种启动方法:
1. Context.startService():
在同一个应用任何地方调用 startService() 方法就能启动 Service 了,然后系统会回调 Service 类的 onCreate() 以及 onStart() 方法。这样启动的 Service 会一直运行在后台,直到 Context.stopService() 或者 selfStop() 方法被调用。
另外如果一个 Service 已经被启动,其他代码再试图调用 startService() 方法,是不会执行 onCreate() 的,但会重新执行一次 onStart() 。
2. Context.bindService() :
将 Service 和调用 Service 的客户类绑起来,如果调用这个客户类被销毁,Service 也会被销毁。用这个方法的一个好处是,bindService() 方法执行后 Service 会回调上边提到的 onBind() 方发,你可以从这里返回一个实现了 IBind 接口的类,在客户端操作这个类就能和这个服务通信了,比如得到 Service 运行的状态或其他操作。如果 Service 还没有运行,使用这个方法启动 Service 就会 onCreate() 方法而不会调用 onStart()。
12:Binder机制的原理
很多进程之间的底层通信都会用到Binder IPC机制,当activity 需要传递数据到servise中,及时通过Binder 来传递通信
Binder原理
Binder通信采用C/S架构,从组件视角来说,包含Client、Server、ServiceManager以及binder驱动,其中ServiceManager用于管理系统中的各种服务。架构图如下所示:
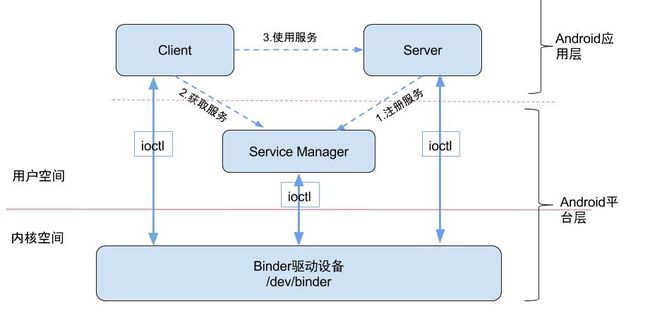
Binder通信的四个角色
Client进程:使用服务的进程。
Server进程:提供服务的进程。
ServiceManager进程:ServiceManager的作用是将字符形式的Binder名字转化成Client中对该Binder的引用,使得Client能够通过Binder名字获得对Server中Binder实体的引用。
Binder驱动:驱动负责进程之间Binder通信的建立,Binder在进程之间的传递,Binder引用计数管理,数据包在进程之间的传递和交互等一系列底层支持。
11:线程池
四种线程池
Java通过Executors提供四种线程池,分别为:
1、newSingleThreadExecutor ::一个任务一个任务执行的场景
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
2、newFixedThreadPool :执行长期的任务,性能好很多
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
3、newScheduledThreadPool :周期性的线程
创建一个可定期或者延时执行任务的定长线程池,支持定时及周期性任务执行。
4、newCachedThreadPoo l:执行很多短期异步的小程序或者负载较轻的服务器
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
12:java 堆和栈
堆:一般存放 实例化对象,和数组 有java 虚拟机来分配内存 数据是可以共享的
栈 一般存放 定义的局部的变量和对象的引用变量,每个线程都会有一个栈单独来管理 所以数据不是共享的
优缺点: 堆的内存都是动态的划分。所有jvm 会自动回收那些没用的数据,缺点就是 运行时动态分配内存所有读取慢 栈相对快一点,存在栈中间的数据大小和周期必须固定,所以灵活性小, 但是栈中的数据可以共享:
13:内存优化
1.先解决程序中内存占用较大的业务模块中的内存泄漏,
2.移除程序中多余的代码和引用,这里使用默认的lint检测再配合shrinkResources来删除无效资源
3.优化图片,保证图片放置在合理的文件夹,根据View大小加载合适的图片大小,根据手机状态配置bitmap和回收策略
4.优化对象创建,比如string,使用对象池等
14:ClassLoader机制
可以参考这篇文章可以参考这篇类加载器
15:说说你了解的第三方网络架构和实现原理:0khttp ,Retrofit
17:HashMap的哈希散列实现,线程安全吗,为什么?:
什么是HashMap
1.HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry。
这些个键值对(Entry)分散存储在一个数组当中,这个数组就是HashMap的主干。
HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
18:ArrayList和Vector扩容的区别 具体的源码和区别详细
Vector是线程安全的(用来syncronized 关键字),但是性能比ArrayList要低。
ArrayList,Vector主要区别为以下几点:
(1):Vector是线程安全的,源码中有很多的synchronized可以看出,而ArrayList不是。导致Vector效率无法和ArrayList相比;
(2):ArrayList和Vector都采用线性连续存储空间,当存储空间不足的时候,ArrayList默认增加为原来的50%,Vector默认增加为原来的一倍(* 2);
(3):Vector可以设置capacityIncrement,而ArrayList不可以,从字面理解就是capacity容量,Increment增加,容量增长的参数。
19:HashMap、Hashtable、ConcurrentHashMap的原理与区别
20:jvm内存模型,新生代和老年代的比例?
在 Java 中,堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。
这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
堆的内存模型大致为:
从图中可以看出: 堆大小 = 新生代 + 老年代。其中,堆的大小可以通过参数 –Xms、-Xmx 来指定。
默认的,新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 ),即:新生代 ( Young ) = 1/3 的堆空间大小。老年代 ( Old ) = 2/3 的堆空间大小。其中,新生代 ( Young ) 被细分为 Eden 和 两个 Survivor 区域,这两个 Survivor 区域分别被命名为 from 和 to,以示区分。
默认的,Eden : from : to = 8 : 1 : 1 ( 可以通过参数 –XX:SurvivorRatio 来设定 ),即: Eden = 8/10 的新生代空间大小,from = to = 1/10 的新生代空间大小。
JVM 每次只会使用 Eden 和其中的一块 Survivor 区域来为对象服务,所以无论什么时候,总是有一块 Survivor 区域是空闲着的。
因此,新生代实际可用的内存空间为 9/10 ( 即90% )的新生代空间。
21熟悉哪些数据结构?数据结构补充
线性表:还可细分为顺序表、链表、栈和队列;
树结构:包括普通树,二叉树,线索二叉树等;