机器学习之不同算法对iris,boston数据集进行建模分析
1.一元线性回归
对鸢尾花数据集中petal_length和petal_width两列数据进行一元线性回归分析。对上述两列数据进行预处理并进行回归分析,画出散点图和回归线。打印回归方程的截距和斜率。根据回归模型,给定花萼长度为4.0的花,预测其花萼宽度
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.linear_model import LinearRegression
iris = load_iris()
data = pd.DataFrame(iris.data)
data.columns = ["sepal_length","sepal_width","petal_length","petal_width"]
x = data["petal_length"].values
y = data["petal_width"].values
x = x.reshape(len(x),1)
y = y.reshape(len(y),1)
lmodel = LinearRegression()
lmodel.fit(x,y)
plt.scatter(x,y)
pre_y = lmodel.predict(x)
plt.plot(x,pre_y,'r-',linewidth=2)
print("截距:",lmodel.intercept_)
print("斜率:",lmodel.coef_)
print("predict petal_length=4.0:",lmodel.predict([[4.0]]))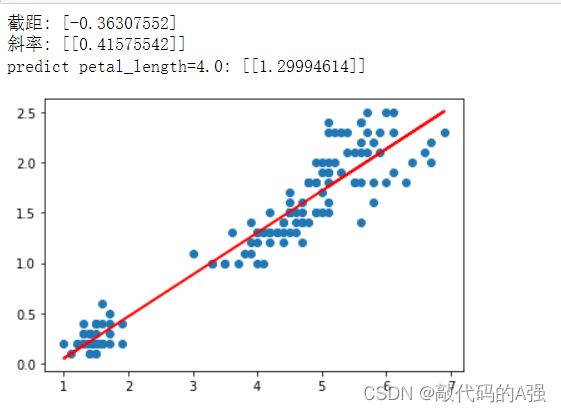
2.多元线性回归
引入boston房价数据集,建立多元线性回归模型,建模时将数据集随机分为训练集和测试集。使用训练集训练模型,使用测试集测试,并打印测试集的均方误差。
import numpy as np
import pandas as pd
from sklearn.datasets import load_boston
d=load_boston()
data=pd.DataFrame(d.data)
data['price']=d.target
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
lmodel2=LinearRegression()
x_train,x_test,y_train,y_test=train_test_split(d.data,d.target,random_state=666)
lmodel2.fit(x_train,y_train)
y_predict=lmodel2.predict(x_test)
from sklearn.metrics import mean_squared_error
print('预测值的均方误差:', mean_squared_error(y_test,y_predict))
print(lmodel2.score(x_test,y_test))

3.Kmeans聚类
利用Kmeans算法实现对iris数据集的聚类分析。打印混淆矩阵,输出模型的准确率,查准率,召回率和F1值
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics import confusion_matrix
iris = load_iris()
X = iris.data
kmModel = KMeans(n_clusters = 3)
kmModel.fit(X)
label_km = kmModel.labels_
#print(label_km)
#print(iris.target)
print("混淆矩阵:\n",confusion_matrix(iris.target,label_km))
classreport = metrics.classification_report(iris.target,label_km)
print(classreport)
4.支持向量机
利用SVM对iris数据集进行分类,自定义合理的训练集和测试集比例。打印混淆矩阵,输出模型在三分类上的的准确率,召回率,查准率和F1score的值
import numpy as np
from sklearn import svm
from sklearn.datasets import load_iris
from sklearn import metrics
from sklearn.model_selection import train_test_split
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state = 1, test_size = 0.2)
svmModel=svm.SVC(kernel='linear', C=0.1)
svmModel.fit(x_train, y_train)
print("SVM-输出训练集的准确率为:", svmModel.score(x_train, y_train))
print("SVM-输出测试集的准确率为:", svmModel.score(x_test, y_test))
y_predict = svmModel.predict(x_test)
print(metrics.confusion_matrix(y_test,y_predict)) #混淆矩阵
classreport = metrics.classification_report(y_test,y_predict,target_names=['setosa','versicolor','verginica'])
print(classreport)