黑马java基础_Java基础学习:Java无锁并发
无锁并发
1. 问题提出
有如下需求,保证 account.withdraw 取款方法的线程安全

原有实现并不是线程安全的

执行测试代码

某次的执行结果
330 cost: 306 ms
1.1 为什么不安全
withdraw 方法
publicvoidwithdraw(Integer amount){ balance -= amount;}
对应的字节码

多线程执行流程

单核的指令交错
多核的指令交错
1.2 解决思路-锁
首先想到的是给 Account 对象加锁

结果为
0 cost: 399 ms
1.3 解决思路-无锁

执行测试代码
publicstaticvoidmain(String[] args){ Account.demo(newAccountSafe(10000));}
某次的执行结果
0 cost: 302 ms
2. volatile 与 CAS

其中的关键是 compareAndSet,它就是 CAS 的简称(也有 Compare And Swap 的说法),它必须是原子操作。
注意 其实 CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核 CPU 和多核 CPU 下都能够保证【比较-交换】的原子性。
在多核状态下,某个核执行到带 lock 的指令时,CPU 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。2.1 慢动作分析

输出结果

2.2 为什么无锁效率高
无锁情况下,即使重试失败,线程始终在高速运行,没有停歇,而 synchronized 会让线程在没有获得锁的时候,发生上下文切换,进入阻塞。打个比喻线程就好像高速跑道上的赛车,高速运行时,速度超快,一旦发生上下文切换,就好比赛车要减速、熄火,等被唤醒又得重新打火、启动、加速... 恢复到高速运行,代价比较大但无锁情况下,因为线程要保持运行,需要额外 CPU 的支持,CPU 在这里就好比高速跑道,没有额外的跑道,线程想高速运行也无从谈起,虽然不会进入阻塞,但由于没有分到时间片,仍然会进入可运行状态,还是会导致上下文切换。
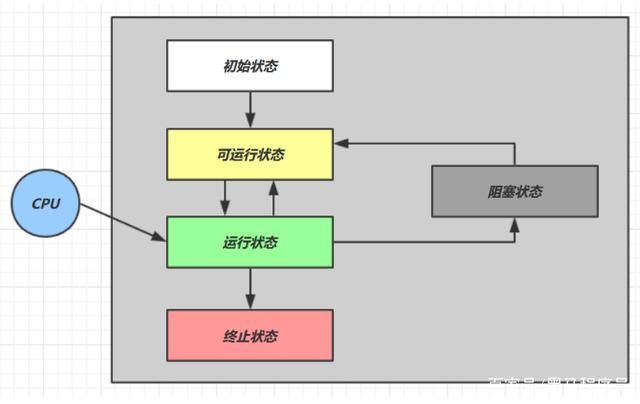
【可运行状态】指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度执行【运行状态】指获取了 CPU 时间片运行中的状态当 CPU 时间片用完,会从【运行状态】转换至【可运行状态】,会导致线程的上下文切换【阻塞状态】如果调用了阻塞 API,如 BIO 读写文件,这时该线程实际不会用到 CPU,会导致线程上下文切换,进入【阻塞状态】等 BIO 操作完毕,会由操作系统唤醒阻塞的线程,转换至【可运行状态】与【可运行状态】的区别是,对【阻塞状态】的线程来说只要它们一直不唤醒,调度器就一直不会考虑调度它们

RUNNABLE 当调用了 start() 方法之后,注意,Java API 层面的 RUNNABLE 状态涵盖了 操作系统 层面的【可运行状态】、【运行状态】和【阻塞状态】(由于 BIO 导致的线程阻塞,在 Java 里无法区分,仍然认为是可运行)BLOCKED,WAITING,TIMED_WAITING 都是 Java API 层面对【阻塞状态】的细分,后面会在状态转换一节详述2.3 volatile
获取共享变量时,为了保证该变量的可见性,需要使用 volatile 修饰。
为什么需要 volatile?
先来看一个现象,main 线程对 run 变量的修改对于 t 线程不可见,导致了 t 线程无法停止:

为什么呢?分析一下:
初始状态, t 线程刚开始从主内存读取了 run 的值到工作内存。
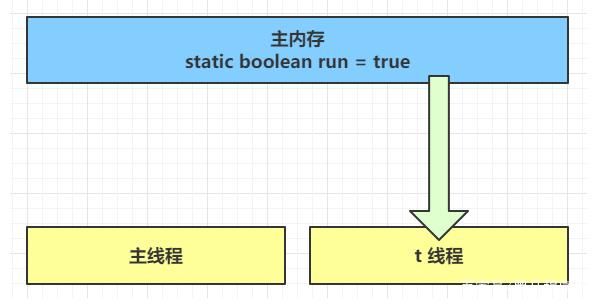
因为 t 线程要频繁从主内存中读取 run 的值,JIT 编译器会将 run 的值缓存至自己工作内存中的高速缓存中,减少对主存中 run 的访问,提高效率

1 秒之后,main 线程修改了 run 的值,并同步至主存,而 t 是从自己工作内存中的高速缓存中读取这个变量的值,结果永远是旧值

可见性
volatile(易变关键字)
它可以用来修饰成员变量和静态成员变量,他可以避免线程从自己的工作缓存中查找变量的值,必须到主存中获取它的值,线程操作 volatile 变量都是直接操作主存。即一个线程对 volatile 变量的修改,对另一个线程可见。
注意 volatile 仅仅保证了共享变量的可见性,让其它线程能够看到最新值,但不能解决指令交错问题(不能保证原子性)
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现【比较并交换】的效果
2.4 CAS 的特点
结合 CAS 和 volatile 可以实现无锁并发,适用于竞争不激烈、多核 CPU 的场景下。
CAS 是基于乐观锁的思想:最乐观的估计,不怕别的线程来修改共享变量,就算改了也没关系,我吃亏点再重试呗。synchronized 是基于悲观锁的思想:最悲观的估计,得防着其它线程来修改共享变量,我上了锁你们都别想改,我改完了解开锁,你们才有机会。CAS 体现的是无锁并发、无阻塞并发,请仔细体会这两句话的意思因为没有使用 synchronized,所以线程不会陷入阻塞,这是效率提升的因素之一但如果竞争激烈,可以想到重试必然频繁发生,反而效率会受影响3. 原子整数
JUC 并发包提供了:
AtomicBooleanAtomicIntegerAtomicLong以 AtomicInteger 为例

4. 原子引用
为什么需要引用类型?
AtomicReferenceAtomicMarkableReferenceAtomicStampedReference有如下方法

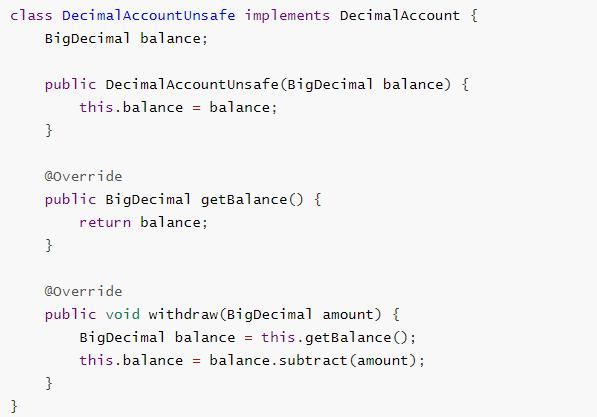
试着提供不同的 DecimalAccount 实现,实现安全的取款操作
4.1 不安全实现
4.2 安全实现-使用锁

4.3 安全实现-使用 CAS

测试代码

运行结果
4310 cost: 425 ms0 cost: 285 ms0 cost: 274 ms
4.4 ABA 问题及解决
ABA 问题

输出

总的解决思路是,使用 CAS 修改前想办法检查,别人动过没 ? 修改失败 : 修改成功,怎么检查别人动过没呢?不能光比较 A,还要进行一个额外的检查
AtomicStampedReference

输出为

AtomicStampedReference 可以给引用加上版本号,追踪引用的整个变化过程,如: A -> B -> A -> C,通过AtomicStampedReference,我们可以知道,引用变量中途被更改了几次。
但是有时候,并不关心引用变量更改了几次,只是单纯的关心是否更改过,所以就有了 AtomicMarkableReference
AtomicMarkableReference


输出

可以注释掉打扫卫生线程代码,再观察输出
5. 原子累加器
5.1 累加器性能比较

比较 AtomicLong 与 LongAdder

输出

性能提升的原因很简单,就是在有竞争时,设置多个累加单元,Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1]... 最后将结果汇总。这样它们在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能。
5.2 LongAdder 原理分析
LongAdder 是并发大师 @author Doug Lea 的作品,设计的非常精巧
LongAdder 类有几个关键域

其中 Cell 即为累加单元

伪共享问题
速度比较


因为 CPU 与 内存的速度差异很大,需要靠预读数据至缓存来提升效率。
而缓存以缓存行为单位,每个缓存行对应着一块内存,一般是 64 byte(8 个 long)
缓存的加入会造成数据副本的产生,即同一份数据会缓存在不同核心的缓存行中
CPU 要保证数据的一致性,如果某个 CPU 核心更改了数据,其它 CPU 核心对应的整个缓存行必须失效

因为 Cell 是数组形式,在内存中是连续存储的,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),因此缓存行可以存下 2 个的 Cell 对象。这样问题来了:
Core-0 要修改 Cell[0]Core-1 要修改 Cell[1]无论谁修改成功,都会导致对方 Core 的缓存行失效,比如 Core-0 中 Cell[0]=6000, Cell[1]=8000 要累加 Cell[0]=6001, Cell[1]=8000,这时会让 Core-1 的缓存行失效
@sun.misc.Contended 用来解决这个问题,它的原理是在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,从而让 CPU 将对象预读至缓存时占用不同的缓存行,这样,不会造成对方缓存行的失效

累加主要调用下面的方法

add 流程图



longAccumulate 流程图
每个线程刚进入 longAccumulate 时,会尝试对应一个 cell 对象(找到一个坑位)

获取最终结果通过 sum 方法

6. Unsafe
6.1 概述
Unsafe 对象提供了非常底层的,操作内存、线程的方法,Unsafe 对象不能直接调用,只能通过反射获得

6.2 Unsafe CAS 操作
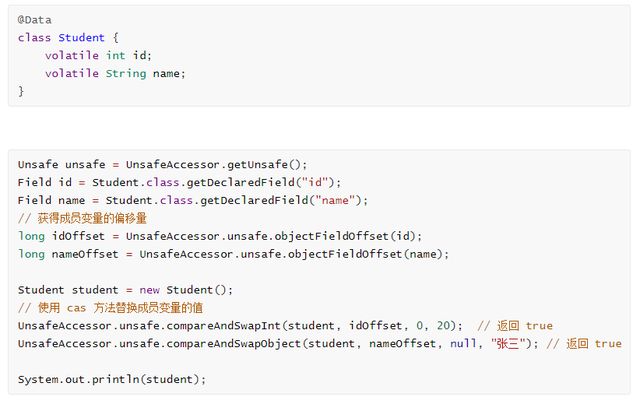
输出
Student(id=20, name=张三)
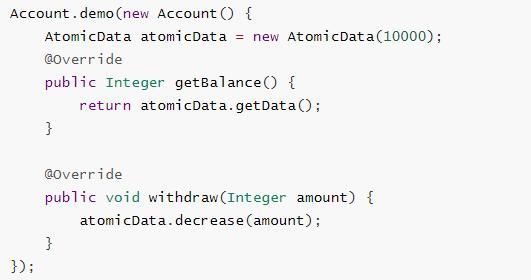
使用自定义的 AtomicData 实现之前线程安全的原子整数 Account 实现

Account 实现