【深度学习】MTCNN总结
目录
MTCNN总结
1、网络结构及思想
1.1 总体流程
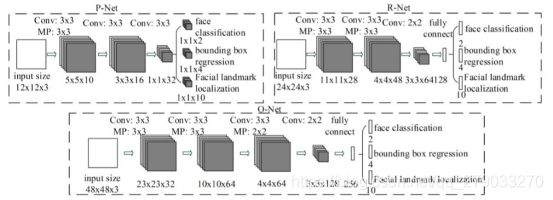
1.2 整体网络结构
1.3 P网络
1.4 R网络
1.5 O网络
1.6 级联思想
1.7 MTCNN优缺点
2 整体流程
2.1 生成样本
2.2 编写网络结构
2.3 训练网络
2.4 使用过程
3 问题及解决方法
4、模型效果
5 其他拓展
MTCNN总结
1、网络结构及思想
1.1 总体流程
由仿生学启发,侦测时从左至右、从上至下一个个的数人脸。
生成样本(检查生成)——》复现模型——》处理数据——》开始训练——》编写前向过程代码——》测试
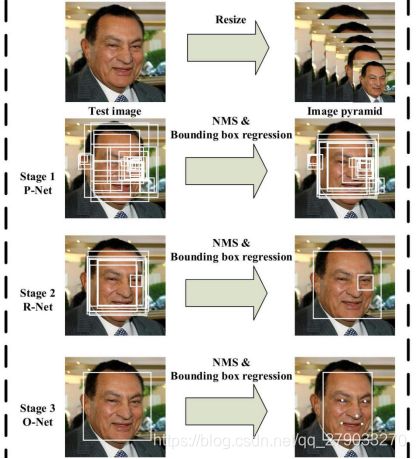
1.2 整体网络结构
采用级联的思想,对每层网络设置不同的置信度阈值、IOU阈值,三层网络层层筛选。每个网络处理问题复杂度不同网络结构不同。
1.3 P网络
1.3.1 P网络结构
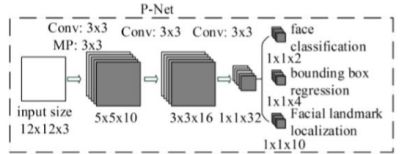
1.3.2 P网络思想
由于P网络未知一张图片含有多少人脸,所以使用全卷积网络接收任意大小的图片,将通道数作为输出特征数,使用图像金字塔缩放图片(最短边长大于12),并设卷积核步长为1不放过任何一个可能性。
采用12x12的大核决定网络侦测到的最小人脸。以固定大小框切取同样大小图片(输出固定)。
使用卷积网络实现切割12x12图片,通过多层小卷积核神经网络的特征提取等价于大核单层神经网络(感受野相同),抽象能力更强,特征提取更精细,参数更少,网络运行更快。
使用偏移量的大小作为训练损失,使得网络计算更方便更有利于训练。
对不同任务设置不同的损失函数,增强学习的针对性。增加人脸五官特征任务,增加网络学习任务的复杂性,清晰网络学习的方向。每增加一个损失,会提升神经网络特征提取的能力,促进网络模型优化。
1.4 R网络
1.4.1 R网络结构
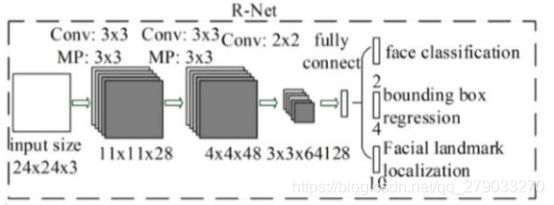
1.4.2 R网络设计思想
通过多层小卷积核神经网络的特征提取等价于大核单层神经网络(感受野相同)。
由于输入为24 x 24固定大小的图片,输出则可使用全连接提取特征(在此处使用卷积核提取特征相同)。
1.5 O网络
1.5.1 O网络结构
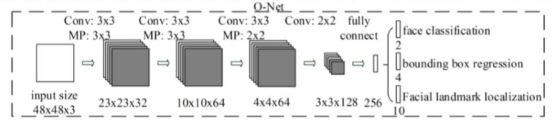
1.5.2 O网络设计思想
通过多层小卷积核神经网络的特征提取等价于大核单层神经网络(感受野相同)。
由于输入为48 x 28固定大小的图片,输出则可使用全连接提取特征(在此处使用卷积核提取特征相同)。
1.6 级联思想

逐级增加任务的难度进行筛选,逐步减少噪声对网络训练的影响。
首先对一整张图片先输入P网络进行粗定位,先定位出人脸的大体的位置(bouding box)。然后对bouding box进行补全、裁剪和Resize,使网络侦测的图片范围变小,输入的数据的噪声就会减少,然后我们在把裁剪后的图片,作为R、O网络的输入,有利于网络训练提高精度。
1.7 MTCNN优缺点
优点:
1、 采用级联的思想一步步筛选出符合标准的样本。将一个大的网络拆解成3个小型网络,比单个网络多出2个置信度损害函数、人脸位置偏移量损失函数和五官偏移量损失函数,增加了2倍的损失函数量。使得整体参数量减少,运算更快。
2、使用小的卷积核代替大的卷积核,使其感受野相同,但参数量更少,运算更快。
3、采用相对坐标(偏移量)
缺点:
P网络需要做图像金字塔然后再传入网络计算需要较长时间。使用过程时,P网络大概占85%左右的时间。
2 整体流程
2.1 生成样本
2.1.1 样本参考信息
数据集:
1)WIDER FACE:泛化性强,召回率高
2)CelebA:精度高,准确率高
首先使用训练好的MTCNN或采用手工标注,以及CelebA数据集制作出原始数据,。
样本参考占比:(样本IOU范围需依据实际样本进行调整)
| IOU范围 |
样本类型 |
标签 |
| 0 ~ 0.3 |
非人脸 |
置信度为0(不参与计算偏移量损失) |
| 0.3 ~ 0.4 |
地标(缓冲区,防止误判) |
|
| 0.4 ~ 0.65 |
Part人脸 |
置信度为2(不参与计算置信度损失) |
| 0.65 ~ 1 |
人脸 |
置信度为1 |
2.1.2 生成样本注意点
1、生成48x48、24x24、12x12正方形样本,采用中心点偏移的方式,偏移量为0.2倍的w和h;样本框原始大小为0.8*min(w,h)~1.25*max(w,h)的边长。
2、在生成负样本时,原始会出现代码会使负样本出现部分人脸的情况,加入IOU_MIN(IOU计算时isMin=True)判定便回剔除这种情况。
3、文件的读取应按照实际情况进行调整。抠图可放在if-else判断句里面,对于不必要的图片不保存,稍微减少文件操作。
4、负样本的生成则可使用while 循环强制生成足量的负样本。
5、每次调整代码后,要使用1000张原始数据生成各类样本进行查看,确保比例和样本的正确性。
6、样本生成还得保持异常数据和越界,生成后保存在json文件中。
7、对于文件操作最好使用try-catch进行异常处理。
2.2 编写网络结构
在编写代码时,一步步查看网络输出形状是否和上图相同再做出相应调整。主要在于步长、卷积核和池化核大小。
编写TrainSet(封装训练)原因:1)数据集无相关性 2)过程大致相同。在其中使用reshape将P网络输出的结构变成R、O网络相似的输出结构。
2.3 训练网络
MTCNN模型训练简单,直接使用P、R、O网络对应大小的人脸图片进行训练。
2.4 使用过程
任意大小的图片传入P网络先使用12x12的卷积核对原图初次特征提取;在将图片等比缩放至原图的0.7倍,传入网络进行特征提取直至图片的最小边长小于12。将P网络所得到的框进行NMS(IOU的isMin=False)处理剔除框在的框,然后将剩余的框进行反算、补全(为保证图像Resize时特征不变形,采用最大边长以原框中心点对图片进行填充)、抠图(切片)、Resize传入R网络。R网络结构接收到P网络输出的一批同等大小的图片,进行特征提取、NMS(IOU的isMin=False)、反算。O网络接收R网络输出的一批同等大小的图片,进行特征提取、NMS(IOU的isMin=True)、反算。
3 问题及解决方法
1、在实际生成时,对中心点使用了0.5倍w的,导致部分样本生成过多、比例过大或生成的负样本包含部分人脸
原因:偏移范围过大,IOU值主要在Part人脸的范围内;IOU只计算了一种,没有计算最小IOU值。
解决方法:使用两种IOU进行筛选,同时满足条件时进行保存样本。最后大致保持了14:3:3的负样本:部分人脸样本:正样本比例。
2、预测框一直在非人脸区域

原因:测试阶段加载数据集的时候,读取图片使用了CV2读取图片,CV2读取读片默认是BGR格式的,而训练使用的RGB格式图片
解决方法:使用了cv2读取一定要转换成和训练时相同的通道排序RGB。
3、单张人脸存在多个置信度为1的框
原因:在生成样本时,我们将偏移框的置信度视为1来代替实际框所在的位置;
解决方法:增大IOU值,将正样本的偏移量减小,使其尽量的靠近于实际框的位置。
4、文件夹中的总体数量对dataloader存在一定的影响,超过20w之后会变得很慢 (刘同学)
原因:应该框架问题
解决方法:使用多个文件夹存储数据
5、MTCNN中P网络添加BN层,训练很快(大概15分钟一轮,100w张),但会出现大量无效框,期间测试P网络做NMS后出现11w候选框的情况
原因:在测试时为添加net.eval()函数
解决方法:剔除BN层或在测试时添加net.eval()函数
6、P网络运行速度对整个模型的影响较大;R、O网络抠图文件操作耗费时间;for循环串行耗费时间;硬件问题加剧模型耗时
原因:图像金字塔需要耗费很多时间,反算没使用Tensor和矩阵进行计算;抠图未使用切片完成;一般越高级的语言运行越慢。
解决方法:根据实际需要调整缩放比;使用tensor和矩阵运算优化代码。
硬件问题:
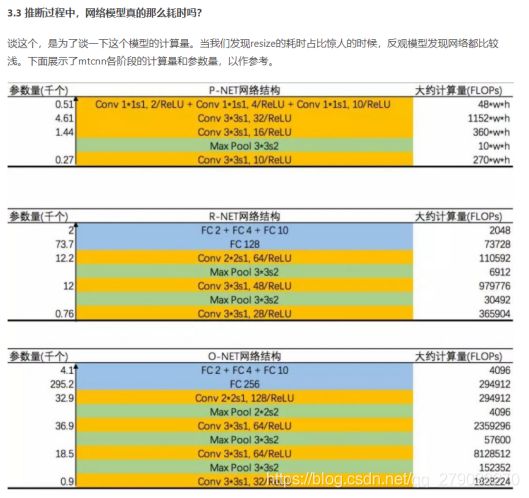
MTCNN的第一阶段,图像金字塔会反反复复地很多次调用一个很浅层的P-NET网络,导致数据会反反复复地从内存COPY到显存,又从显存COPY到内存,而这个复制操作消耗很大,甚至比计算本身耗时。
7、PIL和cv2的resize的插值法不同,对网络模型也存在一定影响(王同学)
解决方法:一直使用同一种框架进行实现。或者查明训练时图片resize所用插值法,同步使用就行。
8、缩放比例为什么选择0.709(刘同学)
原因:比例较大时,可能会导致部分人脸缺失;比例较小时,会导致P网络速度变慢,使得模型性能较差。
缩放比例0.709 ≈ sqrt(2)/2,这样宽高变为原来的sqrt(2)/2,面积就变为原来的1/2。并且从比MTCNN更早提出的级联人脸检测CVPR2015_cascade CNN(http://users.eecs.northwestern.edu/~xsh835/assets/cvpr2015_cascnn.pdf)的实现中也能找到端倪。
9、为啥使用相对坐标?(刘同学)
原因:归一化偏移量;放大R、O网络候选区域;猜测:若使用绝对坐标会使输出范围变大,不利于梯度传播,而且我们期望在网络中传输的量值属于[-1, 1]之间。

边框回归:边框回归(Bounding Box Regression)详解
对于窗口一般使用四维向量(x,y,w,h) 来表示,分别表示窗口的中心点坐标和宽高。 对于下图, 红色的框 P 代表原始的Proposal, 绿色的框 G 代表目标的 Ground Truth, 我们的目标是寻找一种关系使得输入原始的窗口 P 经过映射得到一个跟真实窗口 G 更接近的回归窗口
10、MTCNN为什么使用PReLU做激活函数,而不是ReLU?
原因:ReLU函数会将负半轴特征直接丢弃,对网络来讲数据归一化至在 [-1, 1] 更有利于训练。
11、损失函数的选择
原因:对于分类任务使用y=sigmoid输出函数和交叉熵损失函数进行优化。Pytorch框架交叉熵损失函数最多接收二维数据进行计算。
对于回归任务使用y=x和MSE(均方差损失)函数进行优化。
分类任务由于均方差对参数的偏导的结果都乘了sigmoid的导数,而sigmoid导数在其变量值很大或很小时趋近于0,所以偏导数很有可能接近于0。而交叉熵对参数的偏导就没有sigmoid导数,就不像MSE那么容易出现梯度消失的问题。
12、困难样本的训练
解决方法:部分博客中提到采用损失排前70%进行网络训练。
13、原代码为什么把图片输入模型的时候要对每个元素做(x – 127.5)/128的操作?(刘同学)
原因:归一化操作,加快收敛速度。由于图片每个像素点上是[0, 255]的数,都是非负数,对每个像素点做(x – 127.5)/128,可以把[0, 255]映射为(-1, 1)。具体的理论原因可以自行搜索,但实践中发现,有正有负的输入,收敛速度更快。
训练时候输入的图片需要先做这样的预处理,推断的时候也需要做这样的预处理才行。
猜测:是因为PReLU特性导致网络加快的吗?
14、级联思想解决问题
1)P网络过于简单的问题 2) 排序冗余数据
15、回归损失比分类难训练
原因:输出比分类多,任务更复杂
解决方法:对损失可以进行加权,使某一损失优化力度更大,各损失权重和为1。
16、对于某些可能出现异常的区域如:网络输出为空、坐标越界等,要加入处理语句
17、因为P网络侦测出来的框太多,导致整个侦测速度变慢,现在继续训练提高精度,P网络损失为0.005时侦测一张图片有200个候选框,但是损失为0.01的时候有4000候选框,大量的框运算较慢拖慢了速度,所以继续训练提高精度尝试(刘同学)
原因:P网络没有训练好
解决方法:训练网络出来效果之后,发现和同学的速度差别较大,最后定位到是因为P网络返回了4000多个候选框,而同学只是返回了200多候选框,预测可能是因为P
网络损失没有下去导致的预测框过多
18、图坐标在左上角,计算时需要减一
19、P网络反算后的框直接resize会导致人物变形——>对图像进行填充(使原图形区域在正中),区域越完整信息越多,可能更准确
20、错误检察步骤错误检察步骤
1)反算:(w, h)——>(h, w)
2)观察样本
3)标签:偏移量反算查看是否正确
4)保留resize前的样本坐标进行绘制矩形查看
5)在训练时传入网络的图片是否正确
21、想要通过将IOU计算迁移到GPU上面实现加速,但是测试没有效果,反而会变慢,无效(刘同学,黄同学)
| Gpu之前 |
Gpu之后 |
| p_net:0.15590357780456543 |
p_net:0.31 |
可以看到时间没有减少反而还有增加。
原因:可能是因为NMS内部需要大量循环操作,而循环操作是在cpu上,频繁的将cpu的数据迁移到gpu上面,导致数据频繁在cpu和gpu空间之间切换,加长了耗时,因而增加了时间。
22、img = cv2.imread(img_path, cv2.COLOR_BGR2RGB);不会报错,但图片转不了RGB。(黄同学)
解决方法:使用cvtcolour函数进行转换。
23、iou计算时,只判断面积小于0为0,没有考虑边长都为0的情况,导致nms时框变少(彭同学)
解决方法:添加边长和0判断取较大值。
24、pytorch的排序方法会出现问题,使用numpy进行排序。numpy的argsort对于值相等的会保留原先的顺序而pytorch不会。
25、对于某些实际应用可以先resize在进行侦测。
4、模型效果
原始图片:

P网络输出:

R网络输出:

O网络输出:

共检测:8个人脸
总耗时:0.23秒 P网络耗时:0.12秒 R网络耗时:0.096秒 O网络耗时:0.012秒
5 其他拓展
PC端使用手机摄像头作为摄像头,使用cv2读取视频流,然后每4帧检测一次效果比较流畅,如何配置:
1、安卓手机下载IP摄像头app 
2、第二部打开应用,点击下面的“打开IP摄像头服务器”
第二幅图中有个用户名和密码 默认admin admin
第三幅图中有个地址 http://192.168.0.189:8081/video
《等会直接在浏览器输入这个网址测试》
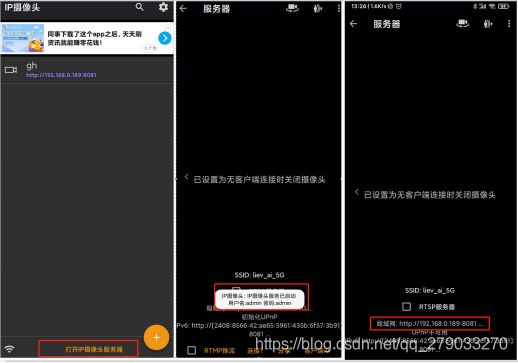
3、此时app内设置完毕,开始去手机设置里面设置
4、然后手机使用usb连接电脑,打开手机设置,打开共享网络,通过usb共享网络
5、开启之后,代码中通过cv2调用上一步在浏览器中输入的地址
前面加上用户名和密码类似下面这样:http://admin:[email protected]:8081/video
![]()
6、运行即可
作者:阳一子
本文地址:https://blog.csdn.net/qq_279033270/article/details/109298658