Linux文本处理三剑客之sed实战MongoDB数据批量导入
概述
在使用关系型数据库或非关系型数据库时,一个很常见的操作就是数据的导入导出。
参考文章Kafka系列之消息重新消费里提到的背景。接手烂摊子项目,因前人需求未实现,消息消费逻辑未完成;故而需要重新消费消息,但由于消息日志文件,即*.log文件未备份存储,只能重新消费最近1天的消息,而更久远的消息无法重新消费。
于是转而考虑从EFK入手,从ES里捞日志数据。关于Kibana如何导出数据,参考EFK实战Kibana查询语法、导出数据、安装插件。
总之,我现在已经拿到一份csv文件(实际上,文件后缀名并不重要)。注意到这个文件里面有一个我们并不需要的字段,即timestamp字段,在Kibana里面尝试过去掉这个字段,没有成功。也就是说导出的数据肯定有这个字段信息。
"@timestamp",msg
"March 31st 2023, 00:37:41.278","topic_event---tp_aba_collect_data_business_service--消费消息:{""os"":""iOS"",""osv"":""iOS 16.3.1"",""band"":""Apple"",""vn"":""ABA健康"",""mid"":""E6DB7194-725C-4160-9E70-414FF927D712"",""vc"":""2.3.0"",""ts"":1680223055532,""env"":""prod"",""carrier"":{""_1"":0,""_2"":1,""_3"":""中国联通""},""ip"":""192.168.50.215"",""network"":{""type"":""none"",""isConnected"":false,""details"":{},""isInternetReachable"":false},""src"":""aba_health_app"",""hw"":""812,375"",""lang"":""zh-Hans-CN"",""fit"":-1,""lut"":-1,""eventType"":""login"",""et"":{""sort"":""wechat""}} "
"March 31st 2023, 00:37:38.278","topic_event---tp_aba_collect_data_business_service--消费消息:-{""os"":""iOS"",""osv"":""iOS 16.3.1"",""band"":""Apple"",""vn"":""ABA健康"",""mid"":""E6DB7194-725C-4160-9E70-414FF927D712"",""vc"":""2.3.0"",""ts"":1680223055532,""env"":""prod"",""carrier"":{""_1"":0,""_2"":1,""_3"":""中国联通""},""ip"":""192.168.50.215"",""network"":{""type"":""none"",""isConnected"":false,""details"":{},""isInternetReachable"":false},""src"":""aba_health_app"",""hw"":""812,375"",""lang"":""zh-Hans-CN"",""fit"":-1,""lut"":-1,""eventType"":""app"",""et"":{""sort"":""isCheckAppUpgrade""}} "
如上所示,文件经过删减,只有3行,第一行是EFK里看到的column name,其余行就是导出的数据。注意:这里文件是否有第一行column name很关键。
需求
将如上这样的CSV文件导入到MongoDB数据库中。
DataGrip
个人极度推崇JetBrains系列的IDE工具,但很可惜使用的DataGrip 2022.1.5版本时并没有找到手动导入CSV文件到MongoDB数据库的入口:

其他数据库如MySQL则有Import Data From File入口:

参考官方文档DataGrip-ImportExport。
续:
后来得知DataGrip可以打开一个CSV文件,然后右键选择Import to Database
Navicat Premium
既然DataGrip无法实现,就转战Navicat Premium。不得不说,Navicat Premium拥有大批忠实用户还是有其成功之处的。
选中某个集合collection后,右键:

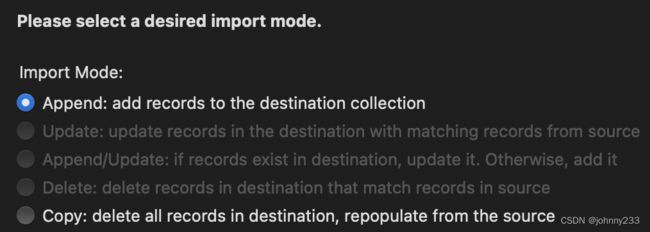
看到Import Wizard,就知道这个可以实现我们的需求。按照提示一步步往下走即可,需要注意的地方:

如果文件有第一行column name,则需要勾选Field Name Row;否则取消勾选,直接处理Data Row。
另外一个需要注意的地方,默认追加Append即可,谨慎选择其他方式,导致数据被覆盖。
但是不幸的是,出现报错:

于是我们需要借助于sed来处理一下原始数据。
sed
前两个可视化工具【初步】【看起来】都不能实现数据导入,必须要借助于sed等工具加工处理一下原始CSV文件。
上面一个截图里面的数据是测试单个文档导入到MongoDB里,我们可以手动截取想要的数据。去掉timestamp,然后截取msg字段想要的内容。
那遇到几万条数据呢?如何通过sed来批量编辑文件?
测试sed脚本时,还是以一两条记录,即1~2个MongoDB文档为例测试。
参考sed教程,如下步骤:
- 去掉
消费消息:{(含)之前的内容,替换为空字符串:sed -ie 's/^.*消费消息:{//g' 1.csv - 去掉
} "之后的内容,替换为空字符串:sed -ie 's/} ".*$//g' 1.txt - 双引号改成单引号:
sed -ie 's/""/"/g' 1.txt
sed命令当然也支持管道操作符,尝试把上面三个命令组合在一起执行,失败。那就一条条执行。
三条命令执行下来得到的文件(首先手动去掉第一行的Field Name Row):
"os":"iOS","osv":"iOS 16.3.1","band":"Apple","vn":"爱达健康","mid":"E6DB7194-725C-4160-9E70-414FF927D712","vc":"2.3.0","ts":1680223055532,"env":"prod","carrier":{"_1":0,"_2":1,"_3":"中国联通"},"ip":"192.168.50.215","network":{"type":"none","isConnected":false,"details":{},"isInternetReachable":false},"src":"ada_health_app","hw":"812,375","lang":"zh-Hans-CN","fit":-1,"lut":-1,"eventType":"login","et":{"sort":"wechat"}
拿着处理好的CSV文件再次通过Navicat的Import Wizard操作步骤,数据成功insert!
等等,MongoDB该集合还有两个字段是CSV文件里面没有的:
_id字段,通过Import Wizard会自动生成一个主键;_class字段,即对应的Java实体类完整包路径名:com.aba.collect.data.api.common.CollectDataV2Content。此字段的数据是固定的,通过Java应用程序,具体来说是使用Spring Data MongoDB提供的mongoTemplate时,就会自动添加这个字段,也可以通过设置取消插入此字段。数据库集合里现在已经有此字段,那就保持一致性。
另外,也发现Navicat的Import Wizard功能实际上是在执行SQL语句:
db.getCollection("aa").insert([{}])
也就是说,经过sed处理的文件,可以直接做成SQL脚本文件,然后执行脚本文件。
上面是在测试阶段,所以使用insert方法插入单条数据。
Navicat Premium的写法是:db.getCollection("aa").insert([{}])
而DataGrip的写法是:
db.getSiblingDB("collectdata").getCollection("collect_data_content").insert({
name: "Johnny", age: 11
});
此处多提一句。一般而言,绝大多数的MongoDB文档和blog都在告诉你,使用
db.products.insert({})
语法来操作集合,完全没有问题。作为一名研发人员,记住常用的快捷键,或使用一些小技巧来提高效率是非常值得推荐的。
一般而言,DBA会针对特定的数据库,即某个schema生成一个特定的用户,这个用户只能操作(查询或更新)这个指定的schema。但是假如我们有一个能操作多个数据库schema的用户时,在可视化工具的console里就会有多个数据库的SQL片段,执行某个SQL时需要切换一下数据库,即点击如下截图的Switch current schema:

最后,我们需要继续研究MongoDB批量插入语法,并且新增一个数据固定的_class字段:
db.getSiblingDB("collectdata").getCollection("collect_data_content").insertMany([
{name: "Alice", age: 22},
{name: "Steve", age: 33},
]);
优化Step 1里的sed命令如下,即每一行数据增加一个{:
sed -ie 's/^.*消费消息:{/{/g' 1.csv
优化Step 2里的sed命令如下,即每一行数据后面新增一个字段及},:
sed -ie 's/} ".*$/,"_class":"com.aba.collect.data.api.common.CollectDataV2Content"},/g' 1.csv
Step 3命令保持不变。
将处理好的CSV文件复制到代码块:
db.getSiblingDB("collectdata").getCollection("collect_data_content").insertMany([
]);