为什么80%的码农都做不了架构师?>>> 
作者:Patrick Lester, 译者:Panic
译者序:很久以前就知道了A*算法,但是从未认真读过相关的文章,也没有看过代码,只是脑子里有个模糊的概念。这次决定从头开始,研究一下这个被人推崇备至的简单方法,作为学习人工智能的开始。 这篇文章非常知名,国内应该有不少人翻译过它,我没有查找,觉得翻译本身也是对自身英文水平的锻炼。经过努力,终于完成了文档,也明白的A*算法的原理。毫无疑问,作者用形象的描述,简洁诙谐的语言由浅入深的讲述了这一神奇的算法,相信每个读过的人都会对此有所认识(如果没有,那就是偶的翻译太差了--b)。
原文链接:http://www.gamedev.net/reference/articles/article2003.asp
原作者文章链接:http://www.policyalmanac.org/games/aStarTutorial.htm
以下是翻译的正文。
会者不难,A*(念作A星)算法对初学者来说的确有些难度。
这篇文章并不试图对这个话题作权威的陈述。取而代之的是,它只是描述算法的原理,使你可以在进一步的阅读中理解其他相关的资料。
最后,这篇文章没有程序细节。你尽可以用任意的计算机程序语言实现它。如你所愿,我在文章的末尾包含了一个指向例子程序的链接。 压缩包包括C++和Blitz Basic两个语言的版本,如果你只是想看看它的运行效果,里面还包含了可执行文件。
我们正在提高自己。让我们从头开始。。。
搜索区域:
假设有人想从A点移动到一墙之隔的B点,如下图,绿色的是起点A,红色是终点B,蓝色方块是中间的墙。

你首先注意到,搜索区域被我们划分成了方形网格。像这样,简化搜索区域,是寻路的第一步。这一方法把搜索区域简化成了一个二维数组。数组的每一个元素是网格的一个方块,方块被标记为可通过的和不可通过的。路径被描述为从A到B我们经过的方块的集合。一旦路径被找到,我们的人就从一个方格的中心走向另一个,直到到达目的地。
这些中点被称为“节点”。当你阅读其他的寻路资料时,你将经常会看到人们讨论节点。为什么不把他们描述为方格呢?因为有可能你的路径被分割成其他不是方格的结构。他们完全可以是矩形,六角形,或者其他任意形状。节点能够被放置在形状的任意位置-可以在中心,或者沿着边界,或其他什么地方。我们使用这种系统,无论如何,因为它是最简单的。
开始搜索
正如我们处理上图网格的方法,一旦搜索区域被转化为容易处理的节点,下一步就是去引导一次找到最短路径的搜索。在A*寻路算法中,我们通过从点A开始,检查相邻方格的方式,向外扩展直到找到目标。
我们做如下操作开始搜索:
1,从点A开始,并且把它作为待处理点存入一个“开启列表”。开启列表就像一张购物清单。尽管现在列表里只有一个元素,但以后就会多起来。你的路径可能会通过它包含的方格,也可能不会。基本上,这是一个待检查方格的列表。
2,寻找起点周围所有可到达或者可通过的方格,跳过有墙,水,或其他无法通过地形的方格。可到达或者可通过的方格加入开启列表。为所有这些方格保存点A作为“父方格”。当我们想描述路径的时候,父方格的资料是十分重要的。后面会解释它的具体用途。
3,从开启列表中删除点A,把它加入到一个“关闭列表”,列表中保存所有不需要再次检查的方格。
在这一点,你应该形成如图的结构。在图中,暗绿色方格是你起始方格的中心。它被用浅蓝色描边,以表示它被加入到关闭列表中了。所有的相邻格现在都在开启列表中,它们被用浅绿色描边。每个方格都有一个灰色指针反指他们的父方格,也就是开始的方格。

接着,我们选择开启列表中的临近方格,大致重复前面的过程,如下。但是,哪个方格是我们要选择的呢?是那个F值最低的。
路径评分
选择路径中经过哪个方格的关键是下面这个等式:
F = G + H
这里:
* G = 从起点A,沿着产生的路径,移动到网格上指定方格的移动耗费。
* H = 从网格上那个方格移动到终点B的预估移动耗费。这经常被称为启发式的,可能会让你有点迷惑。这样叫的原因是因为它只是个猜测。我们没办法事先知道路径的长度,因为路上可能存在各种障碍(墙,水,等等)。虽然本文只提供了一种计算H的方法,但是你可以在网上找到很多其他的方法。
我们的路径是通过反复遍历开启列表并且选择具有最低F值的方格来生成的。文章将对这个过程做更详细的描述。首先,我们更深入的看看如何计算这个方程。
正如上面所说,G表示沿路径从起点到当前点的移动耗费。在这个例子里,我们令水平或者垂直移动的耗费为10,对角线方向耗费为14。我们取这些值是因为沿对角线的距离是沿水平或垂直移动耗费的的根号2(别怕),或者约1.414倍。为了简化,我们用10和14近似。比例基本正确,同时我们避免了求根运算和小数。这不是只因为我们怕麻烦或者不喜欢数学。使用这样的整数对计算机来说也更快捷。你不久就会发现,如果你不使用这些简化方法,寻路会变得很慢。
既然我们在计算沿特定路径通往某个方格的G值,求值的方法就是取它父节点的G值,然后依照它相对父节点是对角线方向或者直角方向(非对角线),分别增加14和10。(某个方格的G值=父节点的G值+10或者+14)例子中这个方法的需求会变得更多,因为我们从起点方格以外获取了不止一个方格。
H值可以用不同的方法估算。我们这里使用的方法被称为曼哈顿方法,它计算从当前格到目的格之间水平和垂直的方格的数量总和,忽略对角线方向。然后把结果乘以10。这被成为曼哈顿方法是因为它看起来像计算城市中从一个地方到另外一个地方的街区数,在那里你不能沿对角线方向穿过街区。很重要的一点,我们忽略了一切障碍物。这是对剩余距离的一个估算,而非实际值,这也是这一方法被称为启发式的原因。
F的值是G和H的和。第一步搜索的结果可以在下面的图表中看到。F,G和H的评分被写在每个方格里。正如在紧挨起始格右侧的方格所表示的,F被打印在左上角,G在左下角,H则在右下角。
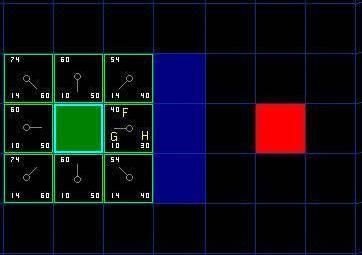
现在我们来看看这些方格。写字母的方格里,G = 10。这是因为它只在水平方向偏离起始格一个格距。紧邻起始格的上方,下方和左边的方格的G值都等于10。对角线方向的方格的G值是14。
H值通过求解到红色目标格的曼哈顿距离(|x2-x1|+|y2-y1|)*10得到,其中只在水平和垂直方向移动,并且忽略中间的墙。用这种方法,起点右侧紧邻的方格离红色方格有3格距离,H值就是30。这块方格上方的方格有4格距离(记住,只能在水平和垂直方向移动),H值是40。你大致应该知道如何计算其他方格的H值了~。
每个格子的F值,还是简单的由G和H相加得到。
继续搜索
为了继续搜索,我们简单的从开启列表中选择F值最低的方格。然后,对选中的方格做如下处理:
4,把它从开启列表中删除,然后添加到关闭列表中。
5,检查所有相邻格子。跳过那些已经在关闭列表中的或者不可通过的(有墙,水的地形,或者其他无法通过的地形),把他们添加进开启列表,如果他们还不在里面的话。把选中的方格作为新的方格的父节点。
6,如果某个相邻格已经在开启列表里了,检查现在的这条路径是否更好。换句话说,检查如果我们用新的路径到达它的话,G值是否会更低一些。如果不是,那就什么都不做。
另一方面,如果新的G值更低,那就把相邻方格的父节点改为目前选中的方格(在上面的图表中,把箭头的方向改为指向这个方格)。最后,重新计算F和G的值。如果这看起来不够清晰,你可以看下面的图示。
好了,让我们看看它是怎么运作的。我们最初的9格方格中,在起点被切换到关闭列表中后,还剩8格留在开启列表中。这里面,F值最低的那个是起始格右侧紧邻的格子,它的F值是40。因此我们选择这一格作为下一个要处理的方格。在紧随的图中,它被用蓝色突出显示。

首先,我们把它从开启列表中取出,放入关闭列表(这就是他被蓝色突出显示的原因)。然后我们检查相邻的格子。哦,右侧的三个格子是墙,所以我们略过。左侧的一个格子是起始格。它在关闭列表里,所以我们也跳过它。
其他4格已经在开启列表里了,于是我们检查G值来判定,如果通过这一格到达那里,路径是否更好。我们来看选中格子下面的方格。它的G值是14。如果我们从当前格移动到那里,G值就会等于20(到达当前格的G值是10,移动到上面的格子将使得G值增加10)。因为G值20大于14,所以这不是更好的路径。如果你看图,就能理解。与其通过先水平移动一格,再垂直移动一格,还不如直接沿对角线方向移动一格来得简单。
当我们对已经存在于开启列表中的4个临近格重复这一过程的时候,我们发现没有一条路径可以通过使用当前格子得到改善,所以我们不做任何改变。既然我们已经检查过了所有邻近格,那么就可以移动到下一格了。
于是我们检索开启列表,现在里面只有7格了,我们仍然选择其中F值最低的。有趣的是,这次,有两个格子的数值都是54。我们如何选择?这并不麻烦。从速度上考虑,选择最后添加进列表的格子会更快捷。这种导致了寻路过程中,在靠近目标的时候,优先使用新找到的格子的偏好。但这无关紧要。(对相同数值的不同对待,导致不同版本的A*算法找到等长的不同路径。)
那我们就选择起始格右下方的格子,如图。

这次,当我们检查相邻格的时候,发现右侧是墙,于是略过。上面一格也被略过。我们也略过了墙下面的格子。为什么呢?因为你不能在不穿越墙角的情况下直接到达那个格子。你的确需要先往下走然后到达那一格,按部就班的走过那个拐角。(注解:穿越拐角的规则是可选的。它取决于你的节点是如何放置的。)
这样一来,就剩下了其他5格。当前格下面的另外两个格子目前不在开启列表中,于是我们添加他们,并且把当前格指定为他们的父节点。其余3格,两个已经在关闭列表中(起始格,和当前格上方的格子,在表格中蓝色高亮显示),于是我们略过它们。最后一格,在当前格的左侧,将被检查通过这条路径,G值是否更低。不必担心,我们已经准备好检查开启列表中的下一格了。
我们重复这个过程,直到目标格被添加进关闭列表(注解),就如在下面的图中所看到的。

注意,起始格下方格子的父节点已经和前面不同的。之前它的G值是28,并且指向右上方的格子。现在它的G值是20,指向它上方的格子。这在寻路过程中的某处发生,当应用新路径时,G值经过检查变得低了-于是父节点被重新指定,G和F值被重新计算。尽管这一变化在这个例子中并不重要,在很多场合,这种变化会导致寻路结果的巨大变化。
那么,我们怎么确定这条路径呢?很简单,从红色的目标格开始,按箭头的方向朝父节点移动。这最终会引导你回到起始格,这就是你的路径!看起来应该像图中那样。从起始格A移动到目标格B只是简单的从每个格子(节点)的中点沿路径移动到下一个,直到你到达目标点。就这么简单。

这里先给出下一个JAVA版的代码:
A星算法步骤:
1.起点先添加到开启列表中
2.开启列表中有节点的话,取出第一个节点,即最小F值的节点,
判断此节点是否是目标点,是则找到了,跳出;
根据此节点取得八个方向的节点,求出G,H,F值;
判断每个节点在地图中是否能通过,不能通过则加入关闭列表中,跳出;
判断每个节点是否在关闭列表中,在则跳出;
判断每个节点是否在开启列表中,在则更新G值,F值,还更新其父节点;不在则将其添加到开启列表中,计算G值,H值,F值,添加其节点。
3.把此节点从开启列表中删除,再添加到关闭列表中;
4.把开启列表中按照F值最小的节点进行排序,最小的F值在第一个;
5.重复2,3,4步骤,直到目标点在开启列表中,即找到了;目标点不在开启列表中,开启列表为空,即没找到
import java.util.*;
public class Test {
public static void main(String[] args){
int[][] map=new int[][]{// 地图数组
{1,1,1,1,1,1,1,1,1,1},
{1,1,1,1,0,1,1,1,1,1},
{1,1,1,1,0,1,1,1,1,1},
{1,1,1,1,0,1,1,1,1,1},
{1,1,1,1,0,1,1,1,1,1},
{1,1,1,1,0,1,1,1,1,1}
};
AStar aStar=new AStar(map, 6, 10);
int flag=aStar.search(3, 2, 3, 8);
if(flag==-1){
System.out.println("传输数据有误!");
}else if(flag==0){
System.out.println("没找到!");
}else{
for(int x=0;x< 6;x++){
for(int y=0;y< 10;y++){
if(map[x][y]==1){
System.out.print(" ");
}else if(map[x][y]==0){
System.out.print("〓");
}else if(map[x][y]==2){//输出搜索路径
System.out.print("※");
}
}
System.out.println();
}
}
}
}运行结果:
import java.util.*;
//A*算法
public class AStar {
private int[][] map;//地图(1可通过 0不可通过)
private List< Node> openList;//开启列表
private List< Node> closeList;//关闭列表
private final int COST_STRAIGHT = 10;//垂直方向或水平方向移动的路径评分
private final int COST_DIAGONAL = 14;//斜方向移动的路径评分
private int row;//行
private int column;//列
public AStar(int[][] map,int row,int column){
this.map=map;
this.row=row;
this.column=column;
openList=new ArrayList< Node>();
closeList=new ArrayList< Node>();
}
//查找坐标(-1:错误,0:没找到,1:找到了)
public int search(int x1,int y1,int x2,int y2){
if(x1< 0||x1>=row||x2< 0||x2>=row||y1< 0||y1>=column||y2< 0||y2>=column){
return -1;
}
if(map[x1][y1]==0||map[x2][y2]==0){
return -1;
}
Node sNode=new Node(x1,y1,null);
Node eNode=new Node(x2,y2,null);
openList.add(sNode);
List< Node> resultList=search(sNode, eNode);
if(resultList.size()==0){
return 0;
}
for(Node node:resultList){
map[node.getX()][node.getY()]=2;
}
return 1;
}
//查找核心算法
private List< Node> search(Node sNode,Node eNode){
List< Node> resultList=new ArrayList< Node>();
boolean isFind=false;
Node node=null;
while(openList.size()>0){
// System.out.println(openList);
//取出开启列表中最低F值,即第一个存储的值的F为最低的
node=openList.get(0);
//判断是否找到目标点
if(node.getX()==eNode.getX()&&node.getY()==eNode.getY()){
isFind=true;
break;
}
//上
if((node.getY()-1)>=0){
checkPath(node.getX(),node.getY()-1,node, eNode, COST_STRAIGHT);
}
//下
if((node.getY()+1)< column){
checkPath(node.getX(),node.getY()+1,node, eNode, COST_STRAIGHT);
}
//左
if((node.getX()-1)>=0){
checkPath(node.getX()-1,node.getY(),node, eNode, COST_STRAIGHT);
}
//右
if((node.getX()+1)< row){
checkPath(node.getX()+1,node.getY(),node, eNode, COST_STRAIGHT);
}
//左上
if((node.getX()-1)>=0&&(node.getY()-1)>=0){
checkPath(node.getX()-1,node.getY()-1,node, eNode, COST_DIAGONAL);
}
//左下
if((node.getX()-1)>=0&&(node.getY()+1)< column){
checkPath(node.getX()-1,node.getY()+1,node, eNode, COST_DIAGONAL);
}
//右上
if((node.getX()+1)< row&&(node.getY()-1)>=0){
checkPath(node.getX()+1,node.getY()-1,node, eNode, COST_DIAGONAL);
}
//右下
if((node.getX()+1)< row&&(node.getY()+1)< column){
checkPath(node.getX()+1,node.getY()+1,node, eNode, COST_DIAGONAL);
}
//从开启列表中删除
//添加到关闭列表中
closeList.add(openList.remove(0));
//开启列表中排序,把F值最低的放到最底端
Collections.sort(openList, new NodeFComparator());
//System.out.println(openList);
}
if(isFind){
getPath(resultList, node);
}
return resultList;
}
//查询此路是否能走通
private boolean checkPath(int x,int y,Node parentNode,Node eNode,int cost){
Node node=new Node(x, y, parentNode);
//查找地图中是否能通过
if(map[x][y]==0){
closeList.add(node);
return false;
}
//查找关闭列表中是否存在
if(isListContains(closeList, x, y)!=-1){
return false;
}
//查找开启列表中是否存在
int index=-1;
if((index=isListContains(openList, x, y))!=-1){
//G值是否更小,即是否更新G,F值
if((parentNode.getG()+cost)< openList.get(index).getG()){
node.setParentNode(parentNode);
countG(node, eNode, cost);
countF(node);
openList.set(index, node);
}
}else{
//添加到开启列表中
node.setParentNode(parentNode);
count(node, eNode, cost);
openList.add(node);
}
return true;
}
//集合中是否包含某个元素(-1:没有找到,否则返回所在的索引)
private int isListContains(List< Node> list,int x,int y){
for(int i=0;i< list.size();i++){
Node node=list.get(i);
if(node.getX()==x&&node.getY()==y){
return i;
}
}
return -1;
}
//从终点往返回到起点
private void getPath(List< Node> resultList,Node node){
if(node.getParentNode()!=null){
getPath(resultList, node.getParentNode());
}
resultList.add(node);
}
//计算G,H,F值
private void count(Node node,Node eNode,int cost){
countG(node, eNode, cost);
countH(node, eNode);
countF(node);
}
//计算G值
private void countG(Node node,Node eNode,int cost){
if(node.getParentNode()==null){
node.setG(cost);
}else{
node.setG(node.getParentNode().getG()+cost);
}
}
//计算H值
private void countH(Node node,Node eNode){
node.setF((Math.abs(node.getX()-eNode.getX())+Math.abs(node.getY()-eNode.getY()))*10);
}
//计算F值
private void countF(Node node){
node.setF(node.getG()+node.getH());
}
}
//节点类
class Node {
private int x;//X坐标
private int y;//Y坐标
private Node parentNode;//父类节点
private int g;//当前点到起点的移动耗费
private int h;//当前点到终点的移动耗费,即曼哈顿距离|x1-x2|+|y1-y2|(忽略障碍物)
private int f;//f=g+h
public Node(int x,int y,Node parentNode){
this.x=x;
this.y=y;
this.parentNode=parentNode;
}
public int getX() {
return x;
}
public void setX(int x) {
this.x = x;
}
public int getY() {
return y;
}
public void setY(int y) {
this.y = y;
}
public Node getParentNode() {
return parentNode;
}
public void setParentNode(Node parentNode) {
this.parentNode = parentNode;
}
public int getG() {
return g;
}
public void setG(int g) {
this.g = g;
}
public int getH() {
return h;
}
public void setH(int h) {
this.h = h;
}
public int getF() {
return f;
}
public void setF(int f) {
this.f = f;
}
public String toString(){
return "("+x+","+y+","+f+")";
}
}
//节点比较类
class NodeFComparator implements Comparator< Node>{
@Override
public int compare(Node o1, Node o2) {
return o1.getF()-o2.getF();
}
}