Go语言精修(尚硅谷笔记)第十六章
十六、goroutine和channel
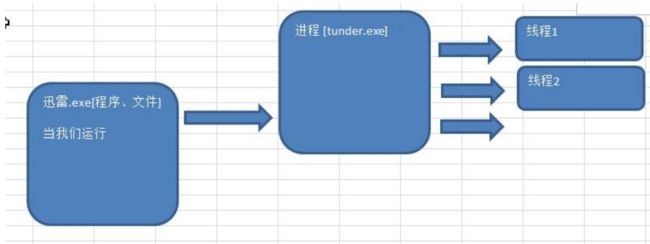
16.1 goroutine线程-基本介绍
- 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
- 一个进程可以创建销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少一个进程,一个进程至少一个线程
- 并发和并行
1 ) 多线程程序在单核上运行,就是并发
2 ) 多线程程序在多核上运行,就是并行

并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
并行:因为是在多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同cpu上执行),从人的角度看,这10个线程都在运行,但是从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行。
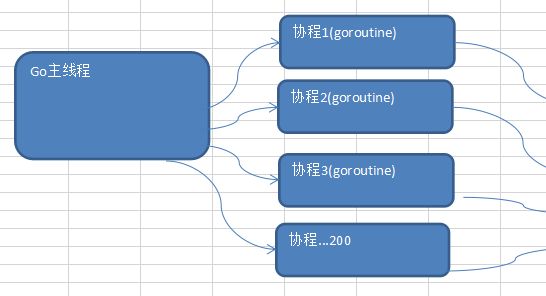
16.2 Go协程和Go主线程
-
Go主线程(有程序员直接称为线程/也可以理解成进程): 一个Go线程上,可以起多个协程,你可以 这样理解,协程是轻量级的线程[编译器做优化]。
-
Go协程的特点
1 ) 有独立的栈空间
2 ) 共享程序堆空间
3 ) 调度由用户控制
4 ) 协程是轻量级的线程
-
一个示意图
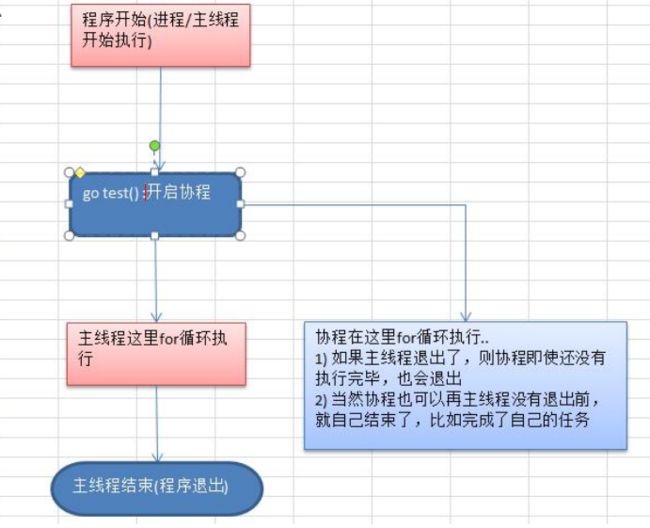
- 请编写一个程序,完成如下功能:
1 ) 在主线程(可以理解成进程)中,开启一个goroutine, 该协程每隔 1 秒输出 “hello,world”
2 ) 在主线程中也每隔一秒输出"hello,golang", 输出 10 次后,退出程序
3 ) 要求主线程和goroutine同时执行
4 ) 画出主线程和协程执行流程图
package main
import (
"fmt"
"strconv"
"time"
)
// 在主线程(可以理解成进程)中,开启一个goroutine, 该协程每隔1秒输出 "hello,world"
// 在主线程中也每隔一秒输出"hello,golang", 输出10次后,退出程序
// 要求主线程和goroutine同时执行
//编写一个函数,每隔1秒输出 "hello,world"
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("tesst () hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
go test() // 开启了一个协程
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
输出的效果说明,main这个主线程和 test 协程同时执行
main() hello,golang1
tesst () hello,world 1
main() hello,golang2
tesst () hello,world 2
main() hello,golang3
tesst () hello,world 3
main() hello,golang4
tesst () hello,world 4
main() hello,golang5
tesst () hello,world 5
main() hello,golang6
tesst () hello,world 6
main() hello,golang7
tesst () hello,world 7
main() hello,golang8
tesst () hello,world 8
main() hello,golang9
tesst () hello,world 9
main() hello,golang10
tesst () hello,world 10
- 协程特点
1 ) 主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
2 ) 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
3 ) Golang的协程机制是重要的特点,可以轻松的开启上万个协程。其它编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang在并发上的优势了
16.3 MPG模式基本介绍

- M:操作系统的主线程(是物理线程)
- P:协程执行需要的上下文
- G:协程
16.3.1 MPG模式运行的状态 1
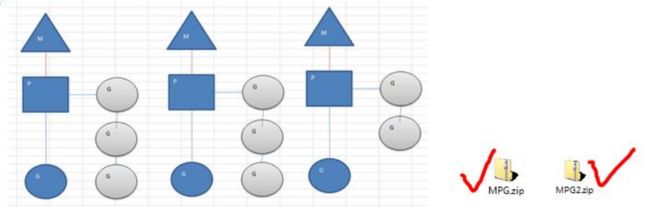
- 当前程序有三个M,如果三个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行
- M1,M2,M3正在执行一个G,M1的协程队列有三个,M2的协程队列有3个,M3协程队列有2个
- 从上图可以看到:Go的协程是轻量级的线程,是逻辑态的,Go可以容易的起上万个协程。
- 其他程序c/java的多线程,往往是内核态的,比较重量级,几千个线程可能耗光cpu
16.3.2 MPG模式运行的状态 2

-
设置GOLANG运行的CPU数
-
为了充分了利用多cpu的优势,在Golang程序中,设置运行的cpu数目
package main
import (
"runtime"
"fmt"
)
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("ok")
}
- go1.8后,默认让程序运行在多个核上,可以不用设置了
- go1.8前,还是要设置以下,可以更高效的利用cpu
16.4 channel管道介绍
-
使用goroutine 来完成,效率高,但是会出现并发/并行安全问题
package main import ( "fmt" "time" ) // 需求:现在要计算 1-200 的各个数的阶乘,并且把各个数的阶乘放入到map中。 // 最后显示出来。要求使用goroutine完成 // 思路 // 1. 编写一个函数,来计算各个数的阶乘,并放入到 map中. // 2. 我们启动的协程多个,统计的将结果放入到 map中 // 3. map 应该做出一个全局的. var ( myMap = make(map[int]int, 10) ) // test 函数就是计算 n!, 让将这个结果放入到 myMap func test(n int) { res := 1 for i := 1; i <= n; i++ { res *= i } //这里我们将 res 放入到myMap myMap[n] = res //concurrent map writes? } func main() { // 我们这里开启多个协程完成这个任务[200个] for i := 1; i <= 200; i++ { go test(i) } //休眠10秒钟【第二个问题 】 time.Sleep(time.Second * 10) //这里我们输出结果,变量这个结果 for i, v := range myMap { fmt.Printf("map[%d]=%d\n", i, v) } }
-
这里就提出了不同goroutine如何通信的问题
- 1 ) 全局变量的互斥锁
- 2 ) 使用管道channel来解决
16.4.1 全局变量加锁同步改进程序
- 因为没有对全局变量 m 加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
- 解决方案:加入互斥锁
- 我们的数的阶乘很大,结果会越界,可以将求阶乘改成 sum+=uint 64 (i)
package main
import (
"fmt"
_ "time"
"sync"
)
// 需求:现在要计算 1-200 的各个数的阶乘,并且把各个数的阶乘放入到map中。
// 最后显示出来。要求使用goroutine完成
// 思路
// 1. 编写一个函数,来计算各个数的阶乘,并放入到 map中.
// 2. 我们启动的协程多个,统计的将结果放入到 map中
// 3. map 应该做出一个全局的.
var (
myMap = make(map[int]int, 10)
//声明一个全局的互斥锁
//lock 是一个全局的互斥锁,
//sync 是包: synchornized 同步
//Mutex : 是互斥
lock sync.Mutex
)
// test 函数就是计算 n!, 让将这个结果放入到 myMap
func test(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
//这里我们将 res 放入到myMap
//加锁
lock.Lock()
myMap[n] = res //concurrent map writes?
//解锁
lock.Unlock()
}
func main() {
// 我们这里开启多个协程完成这个任务[200个]
for i := 1; i <= 20; i++ {
go test(i)
}
//休眠10秒钟【第二个问题 】
//time.Sleep(time.Second * 5)
//这里我们输出结果,变量这个结果
lock.Lock()
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
lock.Unlock()
}
16.4.2 为什么需要channel
- 前面使用全局变量加锁同步来解决goroutine的通讯,但不完美
- 主线程在等待所有goroutine全部完成的时间很难确定,我们这里设置 10 秒,仅仅是估算。
- 如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有goroutine处于工作状态,这时也会随主线程的退出而销毁
- 通过全局变量加锁同步来实现通讯,也并不利用多个协程对全局变量的读写操作。
- 上面种种分析都在呼唤一个新的通讯机制-channel
16.4.3 channel介绍
- channle本质就是一个数据结构-队列【示意图】
- 数据是先进先出【FIFO:firstinfirstout】
- 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的
- channel有类型的,一个string的channel只能存放string类型数据。
- 示意图:
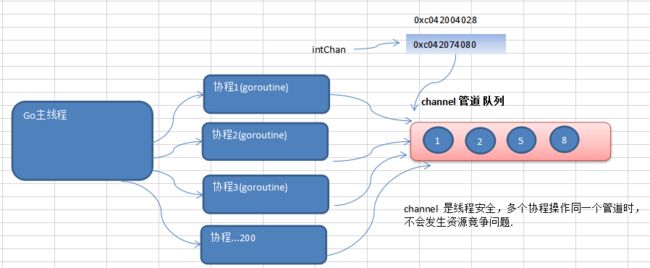
-
定义声明channel
var 变量名 chan 数据类型- 举例:
var intChan chan int(intChan用于存放int数据) var mapChan chan map[int]string(mapChan用于存放map[int]string类型) var perChan chan Person var perChan2 chan *Person
说明
- channel是引用类型
- channel必须初始化才能写入数据, 即make后才能使用
- 管道是有类型的,intChan 只能写入 整数 int
16.5 管道初始化写入数据读出数据
package main
import (
"fmt"
)
func main() {
//演示一下管道的使用
//1. 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
//2. 看看intChan是什么
fmt.Printf("intChan 的值=%v intChan本身的地址=%p\n", intChan, &intChan)
//3. 向管道写入数据
intChan<- 10
num := 211
intChan<- num
intChan<- 50
// //如果从channel取出数据后,可以继续放入
<-intChan
intChan<- 98//注意点, 当我们给管写入数据时,不能超过其容量
//4. 看看管道的长度和cap(容量)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 3, 3
//5. 从管道中读取数据
var num2 int
num2 = <-intChan
fmt.Println("num2=", num2)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 2, 3
//6. 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告 deadlock
num3 := <-intChan
num4 := <-intChan
//num5 := <-intChan
fmt.Println("num3=", num3, "num4=", num4/*, "num5=", num5*/)
}
16.6 管道阻塞
什么时候阻塞
- 向一个值为nil的管道写或读数据
- 无缓冲区时单独的写或读数据
- 缓冲区为空时进行读数据
- 缓冲区满时进行写数据
常见错误
- 关闭值为nil的管道
- 关闭已经关闭的管道
- 往已经close的管道发送数据会panic
**注意:
从已关闭的通道接收数据时将不会发生阻塞
由此可见通道如果不主动close掉,读出通道全部数据后该协程就会阻塞
从已经关闭的通道接收数据或者正在接收数据时,将会接收到通道类型的零值,然后停止阻塞并返回。
16.7 注意事项
- channel中只能存放指定的数据类型
- channle的数据放满后,就不能再放入了
- 如果从channel取出数据后,可以继续放入
- 在没有使用协程的情况下,如果channel数据取完了,再取,就会报deadlock
- 使用例子
1)创建一个intChan,最多可以存放3个int,演示存3数据到intChan,然后再取出这三个int
package main
import (
"fmt"
)
func main() {
var intChan chan int
intChan = make(chan int, 3)
intChan <- 10
intChan <- 20
intChan <- 10
//因为intChan 的容量为3,再存放会报deadlock
//intChan <- 50
num1 := <-intChan
num2 := <-intChan
num3 := <-intChan
//因为intChan 这时已经没有数据了,再取就会报deadlock
//num3 := <- intChan
fmt.Printf("num1=%v num2=%v num3=%v", num1, num2, num3)
}
2)创建一个mapChan,最多可以存放10个map[string]string的key-val,演示写入和读取
package main
import (
"fmt"
)
func main() {
var mapChan chan map[string]string
mapChan = make(chan map[string]string, 10)
m1 := make(map[string]string, 20)
m1["city1"] = "北京"
m1["city2"] = "天津"
m2 := make(map[string]string, 20)
m2["hero1"] = "宋江"
m2["hero2"] = "武松"
mapChan <- m1
mapChan <- m2
m11 := <-mapChan
m22 := <-mapChan
fmt.Println(m11, m22)
}
3)创建一个catChan,最多可以存放10个Cat结构体变量
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var catChan chan Cat
catChan = make(chan Cat, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
catChan <- cat1
catChan <- cat2
//取出
cat11 := <-catChan
cat22 := <-catChan
fmt.Println(cat11, cat22)
}
4)创建一个catChan2,最多可以存放10个*Cat变量,演示写入和读取的方法
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var catChan chan *Cat
catChan = make(chan *Cat, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
catChan <- &cat1
catChan <- &cat2
//取出
cat11 := <-catChan
cat22 := <-catChan
fmt.Println(cat11, cat22)
}
5)创建一个allChan,最多可以存放10个任意数据类型变量,演示写入和读取的用法
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var allChan chan interface{}
allChan = make(chan interface{}, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
allChan <- cat1
allChan <- cat2
allChan <- 10
allChan <- "jack"
//取出
cat11 := <-allChan
cat22 := <-allChan
v1 := <-allChan
v2 := <-allChan
fmt.Println(cat11, cat22, v1, v2)
}
6)看下面代码,会输出什么?
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var allChan chan interface{}
allChan = make(chan interface{}, 10)
cat1 := Cat{Name: "tom", Age: 18}
allChan <- cat1
//取出
newCat := <-allChan //从管道中取出的cat是什么?
fmt.Printf("newCat=%T,newCat=%v\n", newCat, newCat)
//下面的写法是错误的!编译不通过
//fmt.Printf("newCat.Name=%v",newCat.Name)
//使用类型断言
a := newCat.(Cat)
fmt.Printf("newCat.Name=%v", a.Name)
}
-
channel可以声明为只读,或者只写性质
package main import ( "fmt" ) func main() { //管道可以声明为只读或者只写 //1. 在默认情况下下,管道是双向 //var chan1 chan int //可读可写 //2 声明为只写 var chan2 chan<- int chan2 = make(chan int, 3) chan2<- 20 //num := <-chan2 //error fmt.Println("chan2=", chan2) //3. 声明为只读 var chan3 <-chan int num2 := <-chan3 //chan3<- 30 //err fmt.Println("num2", num2) }channel只读和只写的最佳实践案例
package main import ( "fmt" ) // ch chan<- int,这样ch就只能写操作 func send(ch chan<- int, exitChan chan struct{}) { for i := 0; i < 10; i++ { ch <- i } close(ch) var a struct{} exitChan <- a } // ch <-chan int,这样ch就只能读操作 func recv(ch <-chan int, exitChan chan struct{}) { for { v, ok := <-ch if !ok { break } fmt.Println(v) } var a struct{} exitChan <- a } func main() { var ch chan int ch = make(chan int, 10) exitChan := make(chan struct{}, 2) go send(ch, exitChan) go recv(ch, exitChan) var total = 0 for _ = range exitChan { total++ if total == 2 { break } } fmt.Println("结束。。。") }
16.7.8 select:可以解决从管道取数据的阻塞问题
select是go语言当中提供的一个选择语句。select的语法类似switch语句,也属于控制语句。
那为什么select语句我们没有放在和if、switch语句一起?
因为select是配合channel通道使用的。每个 case 必须是一个通信操作,要么是发送要么是接收。
select特性
-
select只能用于channel操作,每个case都必须是一个channel;
-
如果有多个case可以允许(channel没有阻塞),则随机选择一条case语句执行;
-
如果没有case语句可以执行(channel发生阻塞),切没有default语句,则select语句会阻塞;
-
如果没有case语句可以执行(channel发生阻塞),有default语句,则执行default语句;
-
一般使用超时语句代替default语句;
func main() { ch1 := make(chan int) ch2 := make(chan int) select { case num1 := <-ch1: fmt.Println("ch1中的数据是:", num1) case num2 := <-ch2: fmt.Println("ch2中的数据是:", num2) case <-time.After(3 * time.Second): fmt.Println("timeout...") } } -
如果case语句中的channel为nil,则忽略该分支,相当于从select中删除了该分支;
-
如果select语句在for循环中,一般不使用default语句,因为会引起CPU占用过高问题。
select语法格式
select {
case communication clause :
statement(s);
case communication clause :
statement(s);
/* 你可以定义任意数量的 case */
default : /* 可选 */
statement(s);
}
例子:
package main
import (
"fmt"
"time"
)
func main() {
//使用select可以解决从管道取数据的阻塞问题
//1.定义一个管道 10个数据int
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan<- i
}
//2.定义一个管道 5个数据string
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
//传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
//问题,在实际开发中,可能我们不好确定什么关闭该管道.
//可以使用select 方式可以解决
//label:
for {
select {
//注意: 这里,如果intChan一直没有关闭,不会一直阻塞而deadlock
//,会自动到下一个case匹配
case v := <-intChan :
fmt.Printf("从intChan读取的数据%d\n", v)
time.Sleep(time.Second)
case v := <-stringChan :
fmt.Printf("从stringChan读取的数据%s\n", v)
time.Sleep(time.Second)
default :
fmt.Printf("都取不到了,不玩了, 程序员可以加入逻辑\n")
time.Sleep(time.Second)
return
//break label
}
}
}
9 ) goroutine中使用recover,解决协程中出现panic,导致程序崩溃问题

package main
import (
"fmt"
"time"
)
//函数
func sayHello() {
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
fmt.Println("hello,world")
}
}
//函数
func test() {
//这里我们可以使用defer + recover
defer func() {
//捕获test抛出的panic
if err := recover(); err != nil {
fmt.Println("test() 发生错误", err)
}
}()
//定义了一个map
var myMap map[int]string
myMap[0] = "golang" //error
}
func main() {
go sayHello()
go test()
for i := 0; i < 10; i++ {
fmt.Println("main() ok=", i)
time.Sleep(time.Second)
}
}
16.8 channel关闭与遍历
使用内置函数close可以关闭channel, 当channel关闭后,就不能再向channel写数据了,但是仍然 可以从该channel读取数据
案例演示:
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel
//intChan<- 300
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
}
channel支持for–range的方式进行遍历,被关闭的信道会禁止数据流入, 是只读的。我们仍然可以从关闭的信道中取出数据,但是不能再写入数据了。
请注意两个细节
1 ) 在遍历时,如果channel没有关闭,则会出现deadlock的错误
2 ) 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel
//intChan<- 300
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
//遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2<- i * 2 //放入100个数据到管道
}
//遍历管道不能使用普通的 for 循环
// for i := 0; i < len(intChan2); i++ {
// }
//在遍历时,如果channel没有关闭,则会出现deadlock的错误
//在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
close(intChan2)
for v := range intChan2 {
fmt.Println("v=", v)
}
}
16.8.1 使用 channel 关闭 goroutine
func main() {
ch := make(chan string, 6)
go func() {
for {
v, ok := <-ch
if !ok {
fmt.Println("结束")
return
}
fmt.Println(v)
}
}()
ch <- "煎鱼还没进锅里..."
ch <- "煎鱼进脑子里了!"
close(ch)
time.Sleep(time.Second)
}
在 Go 语言的 channel 中,channel 接受数据有两种方法:
msg := <-ch
msg, ok := <-ch //通道关闭后ok=false
这两种方式对应着不同的 runtime 方法,我们可以利用其第二个参数进行判别,当关闭 channel 时,就根据其返回结果跳出。
在知道通道的一些阻塞情况后,为了防止deadlock ,可以使用更友好的方式从通道中读取数据
if i, ok := <-ch1 ;ok{
...
}
16.8.2 select轮询channel关闭goroutine
select如果没有case语句可以执行(channel发生阻塞),有default语句,则执行default语句;
通道如果不主动close掉,读出通道全部数据即通道无数据后该协程就会阻塞
从已经关闭的通道接收数据或者正在接收数据时,将会接收到通道类型的零值,然后停止阻塞并返回。
func main() {
val := make(chan interface{})
i := 0
go func() {
for {
select {
case <-val:
return
default:
i++
fmt.Println(i)
}
}
}()
time.Sleep(time.Second)
close(val)
}
16.8.3 context关闭goroutine
可以借助 Go 语言的上下文(context)来做 goroutine 的控制和关闭。
func main() {
ch := make(chan struct{})
ctx, cancel := context.WithCancel(context.Background())
go func(ctx context.Context) {
for {
select {
case <-ctx.Done():
ch <- struct{}{}
return
default:
fmt.Println("煎鱼还没到锅里...")
}
time.Sleep(500 * time.Millisecond)
}
}(ctx)
go func() {
time.Sleep(3 * time.Second)
cancel()
}()
<-ch
fmt.Println("结束")
}
在 context 中,我们可以借助 ctx.Done 获取一个只读的 channel,类型为结构体。可用于识别当前 channel 是否已经被关闭,其原因可能是到期,也可能是被取消了。
因此 context 对于跨 goroutine 控制有自己的灵活之处,可以调用 context.WithTimeout 来根据时间控制,也可以自己主动地调用 cancel 方法来手动关闭。
16.9 waitgroup
WaitGroup在go语言中,用于线程同步,单从字面意思理解,wait等待的意思,group组、团队的意思,WaitGroup就是指等待一组,等待一个系列执行完成后才会继续向下执行。
- WaitGroup能够一直等到所有的goroutine执行完成,并且阻塞主线程的执行,直到所有的goroutine执行完成。
- WaitGroup总共有三个方法:Add(delta int),Done(),Wait()。简单的说一下这三个方法的作用。
- Add:添加或者减少等待goroutine的数量;
- Done:相当于Add(-1);
- Wait:执行阻塞,直到所有的WaitGroup数量变成 0;
如图:WatiGroup的定义
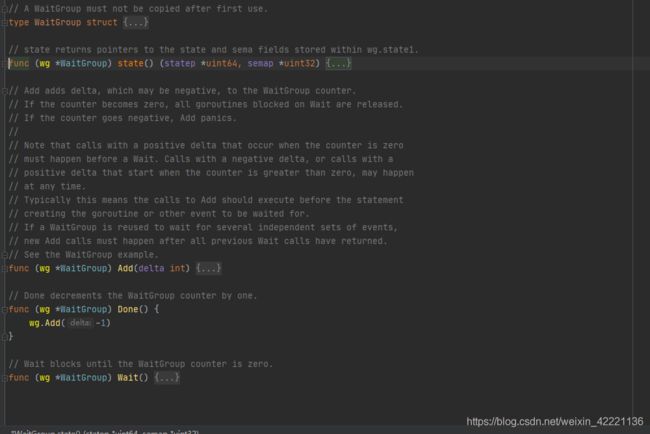
google官方示例:
package main
import (
"fmt"
"sync"
"net/http"
)
func main() {
var wg sync.WaitGroup
var urls = []string{
"http://www.golang.org/",
"http://www.google.com/",
"http://www.baiyuxiong.com/",
}
for _, url := range urls {
// Increment the WaitGroup counter.
wg.Add(1)
// Launch a goroutine to fetch the URL.
go func(url string) {
// Decrement the counter when the goroutine completes.
defer wg.Done()
// Fetch the URL.
http.Get(url)
fmt.Println(url);
}(url)
}
// Wait for all HTTP fetches to complete.
wg.Wait()
fmt.Println("over");
}
代码执行结果为:
http://www.baiyuxiong.com/
http://www.google.com/
http://www.golang.org/
over
从执行结果可看出:
1、取三个网址信息的时候,结果显示顺序与for循环的顺序没有必然关系。
2、三个goroutine全部执行完成后,wg.Wait()才停止等待,继续执行并打印出over字符。
16.10 锁
Go程序可以使用通道进行多个goroutine间的数据交换,但是这仅仅是数据同步中的一种方法。Go语言与其他语言如C、Java一样,也提供了同步机制,在某些轻量级的场合,原子访问(sync/atomic包),互斥锁(sync.Mutex)以及等待组(sync.WaitGroup)能最大程度满足需求。
贴士:利用通道优雅的实现了并发通信,但是其内部的实现依然使用了各种锁,因此优雅代码的代价是性能的损失。
16.10.1 互斥锁 sync.Mutex
互斥锁是传统并发程序进行共享资源访问控制的主要方法。Go中由结构体sync.Mutex表示互斥锁,保证同时只有一个 goroutine 可以访问共享资源。
示例一,普通数据加锁:
package main
import (
"fmt"
"sync"
//"sync"
"time"
)
func main() {
var mutex sync.Mutex
num := 0
// 开启10个协程,每个协程都让共享数据 num + 1
for i := 0; i < 1000; i++ {
go func() {
mutex.Lock() // 加锁,阻塞其他协程获取锁
num += 1
mutex.Unlock() // 解锁
}()
}
// 大致模拟协程结束 等待5秒
time.Sleep(time.Second * 5)
// 输出1000,如果没有加锁,则输出的数据很大可能不是1000
fmt.Println("num = ", num)
}
一旦发生加锁,如果另外一个 goroutine 尝试继续加锁时将会发生阻塞,直到这个 goroutine 被解锁,所以在使用互斥锁时应该注意一些常见情况:
对同一个互斥量的锁定和解锁应该成对出现,对一个已经锁定的互斥量进行重复锁定,会造成goroutine阻塞,直到解锁
对未加锁的互斥锁解锁,会引发运行时崩溃,1.8版本之前可以使用defer可以有效避免该情况,但是重复解锁容易引起goroutine永久阻塞,1.8版本之后无法利用defer+recover恢复
示例二:对象加锁
// 账户对象,对象内置了金额与锁,对象拥有读取金额、添加金额方法
package main
import (
"fmt"
"sync"
"time"
)
type Account struct {
money int
lock *sync.Mutex
}
func (a *Account)Query() {
fmt.Println("当前金额为:", a.money)
}
func (a *Account)Add(num int) {
a.lock.Lock()
a.money += num
a.lock.Unlock()
}
func main() {
a := &Account{
0,
&sync.Mutex{},
}
for i := 0; i < 100; i++ {
go func(num int){
a.Add(num)
}(10)
}
time.Sleep(time.Second * 2)
a.Query() // 不加锁会打印不到1000的数值,加锁后打印 1000
}
16.10.2 读写锁 sync.RWMutex
在开发场景中,经常遇到多处并发读取,一次并发写入的情况,Go为了方便这些操作,在互斥锁基础上,提供了读写锁操作。
读写锁即针对读写操作的互斥锁,简单来说,就是将数据设定为 写模式(只写)或者读模式(只读)。使用读写锁可以分别针对读操作和写操作进行锁定和解锁操作。
读写锁的访问控制规则与互斥锁有所不同:
写操作与读操作之间也是互斥的
读写锁控制下的多个写操作之间是互斥的,即一路写
多个读操作之间不存在互斥关系,即多路读
在Go中,读写锁由结构体sync.RWMutex表示,包含两对方法:
// 设定为写模式:与互斥锁使用方式一致,一路只写
func (*RWMutex) Lock() // 锁定写
func (*RWMutex) Unlock() // 解锁写
// 设定为读模式:对读执行加锁解锁,即多路只读
func (*RWMutex) RLock()
func (*RWMutex) RUnlock()
注意:
Mutex和RWMutex都不关联goroutine,但RWMutex显然更适用于读多写少的场景。仅针对读的性能来说,RWMutex要高于Mutex,因为rwmutex的多个读可以并存。
所有被读锁定的goroutine会在写解锁时唤醒
读解锁只会在没有任何读锁定时,唤醒一个要进行写锁定而被阻塞的goroutine
对未被锁定的读写锁进行写解锁或读解锁,都会引发运行时崩溃
对同一个读写锁来说,读锁定可以有多个,所以需要进行等量的读解锁,才能让某一个写锁获得机会,否则该goroutine一直处于阻塞,但是sync.RWMutext没有提供获取读锁数量方法,这里需要使用defer避免,如下案例所示。
import (
"fmt"
"sync"
"time"
)
func main() {
var rwm sync.RWMutex
for i := 0; i < 3; i++ {
go func(i int) {
fmt.Println("Try Lock reading i:", i)
rwm.RLock()
fmt.Println("Ready Lock reading i:", i)
time.Sleep(time.Second * 2)
fmt.Println("Try Unlock reading i: ", i)
rwm.RUnlock()
fmt.Println("Ready Unlock reading i:", i)
}(i)
}
time.Sleep(time.Millisecond * 100)
fmt.Println("Try Lock writing ")
rwm.Lock()
fmt.Println("Ready Locked writing ")
}
上述案例中,只有循环结束,才会执行写锁,所以输出如下:
...
Ready Locked writing // 总在最后一行
16.10.3 读写锁补充 RLocker方法
sync.RWMutex类型还有一个指针方法RLocker:
func (rw *RWMutex) RLocker() Locker
返回值Locker是实现了接口sync.Lokcer的值,该接口同样被 sync.Mutex和sync.RWMutex实现,包含方法:Lock和Unlock。
当调用读写锁的RLocker方法后,获得的结果是读写锁本身,该结果可以调用Lock和Unlock方法,和RLock,RUnlock使用一致。
2.4 最后的说明
读写锁的内部其实使用了互斥锁来实现,他们都使用了同步机制:信号量。
3、死锁
常见会出现死锁的场景:
两个协程互相要求对方先操作,如:AB相互要求对方先发红包,然后自己再发
读写双方相互要求对方先执行,自己后执行
模拟死锁:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var rwm sync.RWMutex
ch := make(chan int)
go func() {
rwm.RLock() // 加读锁
x := <- ch // 如果不写入,则无法读取
fmt.Println("读取到的x:", x)
rwm.RUnlock()
}()
go func() {
rwm.Lock() // 加入写锁
ch <- 10 // 管道无缓存,没人读走,则无法写入
fmt.Println("写入:", 10)
rwm.Unlock()
}()
time.Sleep(time.Second * 5)
}