bitset的用法
bitset的用法
bitset介绍
C++的 bitset 在 bitset 头文件中,它是一种类似数组的结构,它的每一个元素只能是0或1,每个元素仅用1bit空间,相当于一个char元素所占空间的八分之一。
bitset中的每个元素都能单独被访问,例如对于一个叫做foo的bitset,表达式foo[3]访问了它的第4个元素,就像数组一样。
bitset有一个特性:整数类型和布尔数组都能转化成bitset。
bitset的大小在编译时就需要确定。如果你想要不确定长度的bitset,请使用vector。
bitset构造函数
用字符串构造时,字符串只能包含 ‘0’ 或 ‘1’ ,否则会抛出异常。
构造时,需在<>中表明bitset 的大小(即size)。
bitset的大小在编译时就需要确定。
#include
std::bitset<4> foo; //创建一个4位的位集,每一位默认为0,当整数的大小小于位数时,高位填充为0
std::bitset<4> foo(5); //用整数初始化 5二进制位:101 foo值:0101 当整数的大小超过位数时,从整数二进制的低位开始赋值,高位被舍弃
std::bitset<4> foo(19); //用整数初始化,19二进制位:10011 foo值:0011
std::bitset<4> foo(std::string("0101")); //字符串初始化,字符串中必须只能含有‘0’/‘1’
在进行有参构造时,若参数的二进制表示比bitset的size小,则在前面用0补充(如上面的栗子);
若比bitsize大,参数为整数时取后面部分,参数为字符串时取前面部分(如下面栗子):
bitset<2> bitset1(12); //12的二进制为1100(长度为4),但bitset1的size=2,只取后面部分,即00
string s = "100101";
bitset<4> bitset2(s); //s的size=6,而bitset的size=4,只取前面部分,即1001
char s2[] = "11101";
bitset<4> bitset3(s2); //与bitset2同理,只取前面部分,即1110
cout << bitset1 << endl; //00
cout << bitset2 << endl; //1001
cout << bitset3 << endl; //1110
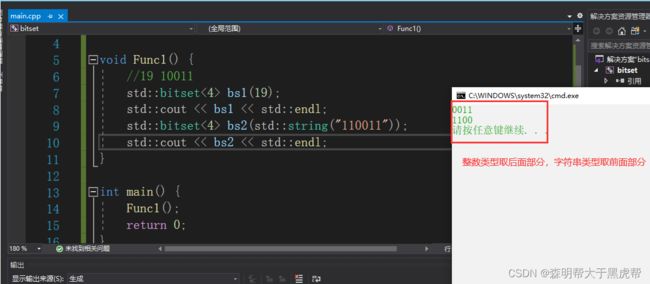
void Func1() {
//19 10011
std::bitset<4> bs1(19);
std::cout << bs1 << std::endl;
std::bitset<4> bs2(std::string("110011"));
std::cout << bs2 << std::endl;
}
bitset常用函数
位运算都可以用: 与、或、非、异或,左移,右移
foo&foo2
foo|foo2
~foo
foo^foo2
foo<<=2
foo>>=2
foo.size() 返回大小(位数)
foo.count() 返回1的个数
foo.any() 返回是否有1
foo.none() 返回是否没有1
foo.set() 全都变成1
foo.set(p) 将第p + 1位变成1
foo.set(p, x) 将第p + 1位变成x
foo.reset() 全都变成0
foo.reset(p) 将第p + 1位变成0
foo.flip() 全都取反
foo.flip(p) 将第p + 1位取反
foo.to_ulong() 返回它转换为unsigned long的结果,如果超出范围则报错
foo.to_ullong() 返回它转换为unsigned long long的结果,如果超出范围则报错
foo.to_string() 返回它转换为string的结果
bitset可用操作符
bitset<4> foo (string("1001"));
bitset<4> bar (string("0011"));
cout << (foo^=bar) << endl; // 1010 (foo对bar按位异或后赋值给foo)
cout << (foo&=bar) << endl; // 0010 (按位与后赋值给foo)
cout << (foo|=bar) << endl; // 0011 (按位或后赋值给foo)
cout << (foo<<=2) << endl; // 1100 (左移2位,低位补0,有自身赋值)
cout << (foo>>=1) << endl; // 0110 (右移1位,高位补0,有自身赋值)
cout << (~bar) << endl; // 1100 (按位取反)
cout << (bar<<1) << endl; // 0110 (左移,不赋值)
cout << (bar>>1) << endl; // 0001 (右移,不赋值)
cout << (foo==bar) << endl; // false (0110==0011为false)
cout << (foo!=bar) << endl; // true (0110!=0011为true)
cout << (foo&bar) << endl; // 0010 (按位与,不赋值)
cout << (foo|bar) << endl; // 0111 (按位或,不赋值)
cout << (foo^bar) << endl; // 0101 (按位异或,不赋值)
bitset可用函数
bitset<8> foo ("10011011");
cout << foo.count() << endl; //5 (count函数用来求bitset中1的位数,foo中共有5个1
cout << foo.size() << endl; //8 (size函数用来求bitset的大小,一共有8位
cout << foo.test(0) << endl; //true (test函数用来查下标处的元素是0还是1,并返回false或true,此处foo[0]为1,返回true
cout << foo.test(2) << endl; //false (同理,foo[2]为0,返回false
cout << foo.any() << endl; //true (any函数检查bitset中是否有1
cout << foo.none() << endl; //false (none函数检查bitset中是否没有1
cout << foo.all() << endl; //false (all函数检查bitset中是全部为1
此外,可以通过 [ ] 访问元素(类似数组),注意最低位下标为0,当然,通过这种方式对某一位元素赋值也是可以的,栗子就不放了。如下:
bitset<4> foo ("1011");
cout << foo[0] << endl; //1
cout << foo[1] << endl; //1
cout << foo[2] << endl; //0
补充说明一下:test函数会对下标越界作出检查,而通过 [ ] 访问元素却不会经过下标检查,所以,在两种方式通用的情况下,选择test函数更安全一些。
最后,还有一些类型转换的函数,如下:
bitset<8> foo ("10011011");
string s = foo.to_string(); //将bitset转换成string类型
unsigned long a = foo.to_ulong(); //将bitset转换成unsigned long类型
unsigned long long b = foo.to_ullong(); //将bitset转换成unsigned long long类型
cout << s << endl; //10011011
cout << a << endl; //155
cout << b << endl; //155
std::string的函数:

对于find和rfind:
- 匹配的是整个被查找串。 找到了返回下标,找不到返回string::npos(最大值)。
对于find_first_of,find_first_not_of,find_last_of,find_last_not_of:
- 匹配的是被查找串中的任意字符。
#include
#include
#include
#include
#include
#include 输出结果:
2
std::string::npos
2
3
结果中4294967295即string::npos,代表没有找到。而在find_first_of(str2)的时候返回的是3,即字符’e’,d代表查找某个字符,证明了我们之前的说法。
字符串插入和删除
string& insert(int pos,const char* p)
string& insert(int pos,string& str)
string& erase(int pos,int n) 从pos位置删除n个字符
截取子串
string substr(int pos,int n) 从pos位置截取n个字符
int find_first_of(char c, int start = 0):
查找字符串中第1个出现的c,由位置start开始。 如果有匹配,则返回匹配下标位置;否则,返回-1.默认情况下,start为0,函数搜索整个字符串。
int find_last_of(char c):
查找字符串中最后一个出现的c。有匹配,则返回匹配位置;否则返回-1。 该搜索在字符末尾查找匹配,所以没有提供起始位置。
字符串拼接
string& operator+=(const char* p)
string& operator+=(const string& str)
string& operator+=(const char c)
string& append(const char* p)
string& append(const char*p,int n) //const char* p 默认从位置0到n拼接
string& append(const string& str)
string& append(const string& str,int start,int end)
string& append(int n,char c)
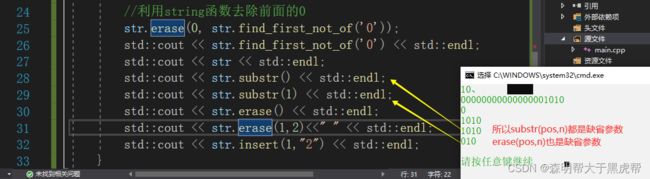
获取输入整数的二进制位:

while (std::cin >> n)
{
//把十进制n放到bitset中进行自动转化;
std::bitset<100> b(n);
//将其转化为string
std::string str = b.to_string();
//利用string函数去除前面的0
str.erase(0, str.find_first_not_of('0'));
std::cout << str.find_first_not_of('0') << std::endl;
std::cout << str << std::endl;
}
字符符串中提取连续字符序列,既子串。 这个操作假定位置 start 和 字符数 count。
string substr(int start=0,int count= -1);
从起始位置开始复制字符串中的count 个字符,并返回这些字符作为子串。
如果字符串尾部小于count字符或者count 为-1,则字符串尾停止复制。
如果不使用参数调用只包括位置start,则substr()返回从位置开始到字符串尾部的子串。
find()函数在字符串中查找指定模式。该函数将字符串s和位置start作为参数,并查找 s的匹配作为子串。
int find(const string& s,int start = 0):
该搜索获得字符串s和位置start,并查找s的匹配作为子串。 如果有匹配,则返回匹配的位置;否则返回-1。默认情况下, start为0,函数搜索整个字符串。
-
std::length(),取得字符串的长度。
-
std::substr(),从字符串中取出一个子串。
-
std::at()/operator [],取得字符串中指定位置的字符。
-
std::find/rfind(),从前往后/从后往前在字符串中查找一个子串的位置。 强调字符串
-
std::find_first_of(),在字符串中找到第一个在指定字符集中的字符位置。 强调字符
-
std::find_first_not_of(),在字符串中找到第一次不在指定字符集中的字符位置。强调字符
-
std::find_last_of(),在字符串中找到最后一个在指定字符集中的字符位置。
-
std::find_last_not_of(),在字符串中找到最后一个不在字符集中的字符位置。
-
std::transform(str.begin(), str.end(), str.begin(), tolower);将字符串转换为小写。
-
std::transform(str.begin(), str.end(), str.begin(), toupper);将字符串转换为大写。、
-
str.erase(0, str.find_first_not_of(" \t\n\r")); 去掉头部空格
-
str.erase(str.find_last_not_of(" \t\n\r") + 1); 去掉尾部空格
1 void trim(string &s) 2 { 3 /* 4 if( !s.empty() ) 5 { 6 s.erase(0,s.find_first_not_of(" ")); 7 s.erase(s.find_last_not_of(" ") + 1); //找到不是空格的位置,然后加1 就是空格位置 8 } 9 */ 10 int index = 0; 11 if( !s.empty()) 12 { 13 while( (index = s.find(' ',index)) != string::npos) 14 { 15 s.erase(index,1); 16 } 17 } 18 19 }