Java多线程入门学习
进程(process)和线程(thread)是操作系统的基本概念,一个程序在windows或Linux操作系统上运行都会产生一个进程,而一个进程又至少包括一个或多个线程。我们学习多线程需要先了解进程与线程的关系和区别,而这需要了解一定的操作系统基础知识。
进程: 进程是程序运行时的一个实例,是操作系统进行管理和资源分配的基本单位,有自己独立的代码和数据空间,不被其他进程所共享。
线程:线程是进程的一个实体,是CPU调度和分派的基本单位。它可与同属一个进程的其他的线程共享进程所拥有的全部资源,是比进程更小的能独立运行的基本单位。
1. Java实现多线程的方式
1.1 继承Thread类
Thread类是在java.lang包中定义的,一个类只要继承了Thread类,这个类就称之为多线程操作类,而我们只需要重写父类中的run()方法,在方法内编写需要被多线程执行的业务代码即可
package com.example.thread;
/**
* @author: gjm
* @date: 2021/11/17 16:27
* @description: 多线程实现方式一,继承Thread类
*/
public class MainThread {
public static void main(String[] args) {
//线程实例化
Thread t = new MyThread();
//启动线程
t.start();
//执行主线程代码
for (int i = 0; i < 10 ; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
}
}
class MyThread extends Thread{
@Override
public void run() {
for (int i = 0; i < 10 ; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
}
}
执行结果:

我们调用线程类Thread的start() 方法就能启动一个线程(Thread-0)来异步执行我们编写在run() 方法中的业务代码,从执行结果我们可以看出Thread-0线程和main线程是交替执行。其实这里我们还能发现main也是一个线程,这就和我们前面所说的一个进程至少包含一个线程对应上了,我们学习Java的时候知道main() 方法是程序的入口方法,而main()方法执行其实会创建一个main主线程来执行里面的代码。
这里我们思考一下如果直接调用多线程操作类的run()方法可以启动多线程吗?
答案是不行的,大家可以尝试一下,因为在主线程中调用run()方法的话其实就被主线程执行了里面的代码,和调用普通方法没有区别。我们要的是Thread-0线程来执行run()方法里面的代码,所以一定要使用Thread类的start()方法才能启动一个新线程,并且只能调用一次start()方法,否则会抛出非法的线程状态异常,我们查看一下源码就知道为什么了。

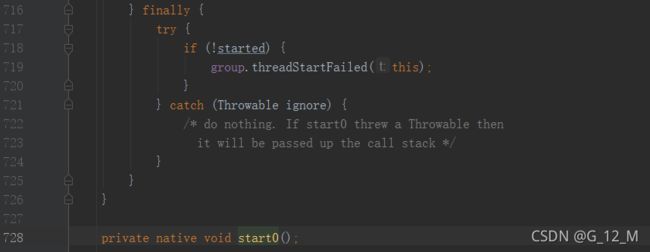
从源码我们可以看出start()方法内部开始做了一个threadStatus是否等于0的判断,如果不等于0则抛出线程状态不合法异常,threadStatus等于0表示线程没有被启动过的,如果重复启动则会抛出异常。还有从源码中我们也可以发现start()最后调了一个标识为native关键字的start0()方法,这个关键字表示调用本机的操作系统函数,这个函数才是操作底层操作系统实现多线程的根本点,这个函数是采用其它语言开发的。
1.2 实现Runnable接口
Runnable接口也是在java.lang包中定义的,接口中只定义了一个抽象的run()方法,我们可以通过实现Runnable接口,实现run() 方法的方式来实现多线程。编程方式和实现Thread类一模一样,我们无需关心里面的内部细节,对开发者来讲比较简单和友好。这里的Runnable还是一个Java8中定义的@FunctionalInterface函数式编程接口,所以我们可以用Lambda表达式简化代码开发。
package com.example.thread;
import java.util.Date;
/**
* @author: gjm
* @date: 2021/11/17 16:41
* @description: 多线程实现方式二,实现Runnable接口
*/
public class MainThread {
public static void main(String[] args) {
//实例化Thread对象
Thread t = new MyThread(new MyRunnable(),"runnable");
//启动线程
t.start();
//执行主线程代码
for (int i = 0; i < 10 ; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
}
}
class MyRunnable implements Runnable{
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
}
}
package com.example.thread;
import java.util.Date;
/**
* @author: gjm
* @date: 2021/11/17 16:41
* @description: 多线程实现方式二,实现Runnable接口
*/
public class MainThread {
public static void main(String[] args) {
//线程实例化并启动
new Thread(()->{
for (int i = 0; i < 5 ; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
},"runnable").start();
//执行主线程代码
for (int i = 0; i < 5 ; i++) {
System.out.println(Thread.currentThread().getName()+"打印了:"+ i);
}
}
}执行结果:

执行结果也同样实现了我们想要的异步效果,而唯一有区别的就是我们启动线程的方式变的复杂一点了,这也很好理解,我们前面说过Runnable里面只有一个简单的抽象方法run(), 里面是没有线程的启动方法start()的,那我们该如何启动线程呢?
记住,Thread类才是实现多线程开发最重要的类,我们需要把Runnable的子类对象通过Thread的构造方法传入Thread类中,这样我们就能通过Thread的start()方法启动线程时,通过Runnable的子类对象能够调用我们重写的run()方法。我们在源码Thread类中找到了如下run方法,这里的target对象就是Runnable的子类实例化对象,当有传入Runnable的子类对象时,就调用该类的run()方法,就是我们重写的需要多线程执行的业务代码


这里还有一个问题就是实现了Runnable接口的MyRunnable类能算是一个多线程操作类吗?
答案是肯定的,因为Thread类也是Runnable接口的子类,MyRunnable继承了Runnable接口就隐式的表示它也是一个多线程类,子类对象会继承父类对象的一切。但是MyRunnable只有一个run()方法它好像又没有Thread类对多线程操作的强大。这里对代理设计模式熟悉的朋友可能已经发现了这有点像代理设计模式,Thread类和MyRunnable都实现了Runnable接口,之后又将MyRunnable的子类实例放到了Thread类之中。开发人员只关心如何编写多线程的业务代码,至于内部如何实现的交给代理主题(Thread)就好,代理主题操作真实主题(MyRunnable)实现多线程,代理主题负责线程的启动,停止,优先级设置等。

1.3 实现Callable接口
Callable接口是在Java 5的时候发行的,它和Runnable一样也是只声明了一个方法,但是Callable是一个泛型接口,使得它的call() 方法可以返回一个你想要的返回类型结果,同时call()也增加了支持抛出checked Exception, 就是实现了Callable接口的子类中的call()方法也能够把checked Exception直接throws 抛出处理。Runnable中的run()方法因为没有声明 throws Exception导致子类重写run()方法时也无法对checked Exception进行throws 抛出处理,只能try-catch处理异常后才能正常编译。
package com.example.thread;
import java.util.Date;
import java.util.concurrent.Callable;
/**
* @author: gjm
* @date: 2021/11/17 16:52
* @description: 多线程实现方式三,实现Callable接口和FutureTask类
*/
public class MainThread1 {
public static void main(String[] args) {
//创建FutureTask实例,传入MyCallable实例
FutureTask task = new FutureTask(new MyCallable());
//创建Thread实例
Thread thread = new Thread(task, "MyCallable");
//启动线程
thread.start();
String result = null;
//执行主线程代码
for (int i = 0; i < 5 ; i++) {
System.out.println("主线程:"+Thread.currentThread().getName()+" -->" + "time="+new Date().getTime()+ " -->i="+i);
result = task.get();
}
System.out.println(result);
}
}
class MyCallable implements Callable {
public String call() throws Exception {
for (int i = 0; i < 5; i++) {
System.out.println("Callable线程: "+Thread.currentThread().getName()+" -->" + "time="+new Date().getTime()+ " -->i="+i);
}
return "MyCallable线程执行完成";
}
}
执行结果:

从运行结果可以发现,我们通过调用FeatureTask类的get()方法可以获取到Callable接口实现类的call()方法的返回结果,但这会造成main主线程被阻塞,直到Callable线程执行完成返回结果主线程才能继续执行下去。
那为什么要把FeatureTask的对象通过Thread的构造方法传入Thread内部呢? 其实通过查看源码我们可以发现FeatureTask其实也间接属于Runnable的子类,FeatureTask实现了RunnableFeature接口,而RunnableFeature接口又实现了Runnable接口,这还是我们前面说的代理设计模式的体现。我们可以猜出FeatureTask也有属于自己的run()方法在Thread类内部被调用,而我们编写的call()方法则在FeatureTask的run()方法中被调用,这和直接在run()方法中编写多线程代码是一样的。
1.4 三种创建线程方式比较
1. 直接继承Thread类体现了面向对象编程的优点,继承了Thread类使得子类获得了父类的行为和属性,让编程变得简单,我们只需重写run()方法,调用父类的start()线程启动方法即可实现多线程开发,缺点是类有单继承的限制,不能再继承其它类。
2. 实现Runnable接口实现多线程可以弥补Java类单继承的带来的局限性,Runnable接口的子类由于本身并不存在操作多线程的复杂方法,所以采用了代理设计模式让Thread类成为(代理主题)来操作Runnable接口的子类(真实主题)实现具体的多线程任务,这种方式也非常适合多个线程去处理同一种资源的情况(如:多机器售票)
3. 实现Callable接口这种方式最为复杂,需要依靠FeatureTask这个类,因为这个类也是Runnable接口的间接子类,所以本质也是采用了第2种方式来实现的,只不过FeatureTask还实现了Feature接口支持更为丰富的对线程任务的操作,比如一个线程可以通过FeatureTask的get()方法获取到它的线程任务的执行结果,使用calcel()方法取消线程任务等高级操作。
2. 多线程操作的相关方法
2.1 sleep()方法
我们学习一个新方法时不用死记硬背,先根据方法名称猜测其大概的作用,sleep的含义是睡眠、休眠的意思,所以这个方法其实就是线程的休眠方法,我们可以让正在执行的线程休眠一段时间。
package com.example.thread;
import java.util.Date;
/**
* @author: gjm
* @date: 2021/11/17 16:27
* @description: 测试sleep()方法
*/
public class MainThread {
public static void main(String[] args) {
//线程实例化
Thread myThread = new MyThread();
//启动线程
myThread.start();
//执行主线程代码
for (int i = 0; i < 5 ; i++) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String time = sdf.format(new Date());
System.out.println(Thread.currentThread().getName()+" --> i="+ i +" --> time="+time);
}
}
}
class MyThread extends Thread{
@Override
public void run() {
for (int i = 0; i < 5 ; i++) {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
System.out.println(Thread.currentThread().getName()+" --> i="+ i +" --> time="+sdf.format(new Date()) );
try {
System.out.println("开始睡眠1s");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
执行结果:

从结果分析得知Thread-0先执行输出 i=0,然后休眠1s进入一个线程阻塞状态,再然后主线程在1s不到的时间快速执行完自己的代码,等过了1s后Thread-0再执行一次输出i,又休眠等待1s再执行代码。我们需要重点关注的是sleep()方法是一个静态方法,在哪个线程的执行代码中使用就代表休眠哪个线程。为了不用获取Thread的对象后再调用sleep()方法,所以被设计成一个类的静态方法。
2.2 join()方法
join是加入的意思,所以这个方法也代表了有特殊情况需要插队的意思。其实这个方法的作用是让一个线程优先强制运行完成的意思,在这个加入的线程没有执行完成前,另一个线程也会处于阻塞状态。
package com.example.methods;
/**
* @author: gjm
* @date: 2021/11/17 16:27
* @description: 测试join()方法
*/
public class ThreadJoin {
public static void main(String[] args) {
//线程实例化
Thread t = new Thread(new ThreadJoinDemo());
//启动线程
t.start();
//执行主线程代码
for (int i = 0; i < 5 ; i++) {
//主线程执行到i=3时需等待t线程执行完成后才能继续执行
if(i == 3){
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName()+" --> i="+ i);
}
}
}
class ThreadJoinDemo implements Runnable{
@Override
public void run() {
for (int i = 0; i < 5 ; i++) {
System.out.println(Thread.currentThread().getName()+" --> i="+ i);
}
}
}
执行结果:

其实join()方法还可以设置时间,这样就表示当前的线程需要等待新加入的线程执行指定的时间后,当前线程才能继续执行,如果不给join()设置时间就默认是让当前线程永久等待,直至新加入的线程执行完成。这里的join()方法实现的内部原理是Object对象的wait()方法。
2.3 interrupt()方法
interrupt代表中断的意思,所以我们可以使用interrupt()中断或者打断一个线程的运行,但是这个中断并非让线程直接停止的意思,而是一种其它线程的打断通知,会使线程的打断标记置为true,最终是否停止线程的运行还需要你根据线程的打断标记决定。我们一般使用两阶段终止模式来更好地终止一个线程的运行而不是直接使用线程的stop()方法简单粗暴地停止线程,stop()方法已经被官方标记为过时方法,我们一般不建议使用。
package com.example.methods;
/**
* @author: guojm
* @date: 2021/11/17 10:03
* @description: 两阶段终止模式
*/
public class MainThread {
public static void main(String[] args) {
//初始化线程
Thread t = new Thread(new MyRunnable(),"Thread-t");
t.start();
//主线程先睡眠1s
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//执行主线程代码
System.out.println("------- 开始执行main线程任务 --------");
//主线程想要中断t线程执行
t.interrupt();
}
}
class MyRunnable implements Runnable{
public void run() {
while(true){
Thread current = Thread.currentThread();
//如果打断标记为true,则让t线程自己结束任务
if(Thread.interrupted()){
break;
}
//t线程每隔2s执行一次线程任务
System.out.println("------- 开始执行t线程任务 --------");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
current.interrupt();
}
}
}
}执行结果:

为什么要使用两阶段终止模式来终止一个线程呢?这是因为interrupt()这个方法如果打断的是正在正常运行的线程那么就会将打断标记置为true,但是如果被打断的线程处于sleep阻塞状态,那么打断标记将会被清除置为false,并且会抛出InterruptException的异常,因此我们需要在catch块再调用interrupt()方法二次打断,将打断标记置为true,让线程能退出死循环终止执行。