Elasticsearch:保留字段名称

作为 Elasticsearch 用户,我们从许多不同的位置收集数据。 我们使用 Logstash、Beats 和其他工具来抓取数据并将它们发送到 Elasticsearch。 有时,我们无法控制数据本身,我们需要管理数据的结构,甚至需要在摄取数据时处理字段名称。
Elasticsearch 有一些保留的字段名称,你不能在文档中使用这些名称。
如果文档具有这些字段之一,则无法为该文档编制索引。 但是,这并不意味着你不能在文档中的任何地方使用这些字段名称。 该限制仅对根节点(root node)有效。 因此,你无法索引以下文档:
PUT twitter/_doc/1
{
"_id": 1
}你会得到如下错误:
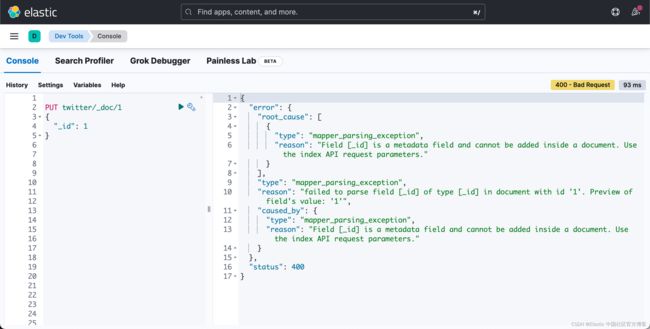
但是你可以成功地写入如下的文档:
PUT twitter/_doc/1
{
"user": {
"_id": 1,
"name": "liuxg"
}
}究其原因,在上面的 _id 它不是在 root node 下的字段。
因此,正如你在上面看到的 _id 字段,你不能在文档中使用以下字段名称作为 root 字段名称:
_id
_field_names
_index
_seq_no
_nested_path
_ignored
_routing
_data_stream_timestamp
_tier
_version
_feature
_source
_primary_term *
_type *注意:上面用 * 标注的字段对于老版本的 elasticsearch 这个字段也是保留关键字
这意味着如果你有将这些字段名称作为根字段的文档。 你会得到一个错误。 例如,你想使用 Logstash 移动该数据。 你有一个包含如下内容的文件:
{
"ImdbId": "tt0030629",
"_id": "tt0030629",
"name": "Prison Without Bars",
"year": "1938",
"certificate": "Approved",
"runtime": "72 min",
"genre": ["Crime", " Drama", " Romance"],
"ratingValue": "6.2",
"summary_text": "Suzanne, Renee, Nina and Marta all hate being in prison, being slapped and treated badly, and so all the girls are trying to escape. Madame Appel just causes chaos all the time, with her ... See full summary\u00a0\u00bb",
"ratingCount": "66"
}
{
"ImdbId": "tt0030528",
"_id": "tt0030528",
"name": "Orage",
"year": "1938",
"certificate": "",
"runtime": "98 min",
"genre": ["Drama"],
"ratingValue": "5.7",
"summary_text": "Orage is a 1938 French drama film directed by Marc All\u00e9gret. The screenplay was written by Marcel Achard and H.G. Lustig, based on play \"Le venin\" by Henri Bernstein. The films stars ... See full summary\u00a0\u00bb",
"ratingCount": "66"
} 因此,当你尝试使用 Logstash 摄取它时,你将收到以下错误。 即使你在单独索引这些文档时也会遇到上述错误。比如我们使用如下的一个例子:
sample.log
{"_id":1,"timestamp":"2019-09-12T13:43:42Z","paymentType":"Amex","name":"Merrill Duffield","gender":"Female","ip_address":"132.150.218.21","purpose":"Toys","country":"United Arab Emirates","age":33}
{"_id":2,"timestamp":"2019-08-11T17:55:56Z","paymentType":"Visa","name":"Darby Dacks","gender":"Female","ip_address":"77.72.239.47","purpose":"Shoes","country":"Poland","age":55}
{"_id":3,"timestamp":"2019-07-14T04:48:25Z","paymentType":"Visa","name":"Harri Cayette","gender":"Female","ip_address":"227.6.210.146","purpose":"Sports","country":"Canada","age":27}
{"_id":4,"timestamp":"2020-02-29T12:41:59Z","paymentType":"Mastercard","name":"Regan Stockman","gender":"Male","ip_address":"139.224.15.154","purpose":"Home","country":"Indonesia","age":34}
{"_id":5,"timestamp":"2019-08-03T19:37:51Z","paymentType":"Mastercard","name":"Wilhelmina Polle","gender":"Female","ip_address":"252.254.68.68","purpose":"Health","country":"Ukraine","age":51}logstash_input.conf
input {
file {
path => "//Users/liuxg/elastic/logstash-8.6.2/sample.log"
type => "applog"
codec => "json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["localhost:9200"]
index => "json-%{+YYYY.MM.dd}"
}
}我们使用如下的命令来启动对数据的采集:
$ pwd
/Users/liuxg/elastic/logstash-8.6.2
$ ls sample.log logstash_input.conf
logstash_input.conf sample.log./bin/logstash -f logstash_input.conf 如你所见,错误与我们上面得到的错误相同。 那么,我们需要做什么? 有一些解决方案可以处理这些类型的数据操作。 你可以在源上修复文档,也可以使用 mutate 过滤器在 Logstash 中管理它们:
logstash_input.conf
input {
file {
path => "//Users/liuxg/elastic/logstash-8.6.2/sample.log"
type => "applog"
codec => "json"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
mutate {
rename => {"_id" => "id"}
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
hosts => ["localhost:9200"]
index => "json-%{+YYYY.MM.dd}"
}
}我们再次运行 Logstash:
./bin/logstash -f logstash_input.conf 我们可以看到这次数据被成功地写入,并且我们可以在 Kibana 中进行查看:
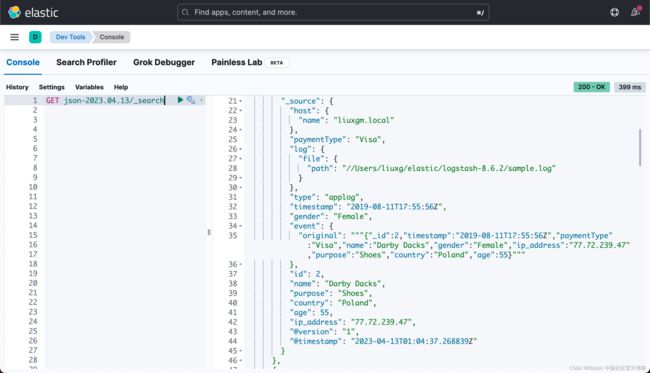
当您重新运行 logstash 时,您将看到文档将被正确索引。 另一方面,我试图解决摄取管道的问题。 一开始我认为这对我来说可能是一个更好的解决方案。 但有趣的是,我对摄取管道尝试了很多不同的方法,但我找不到解决方案。 这是我尝试使用摄取管道的方法:
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"rename": {
"field": "_id",
"target_field": "id"
}
}
]
},
"docs": [
{
"_index": "myindex",
"_id": 1,
"_source": {
"_id": "2"
}
}
]
}我收到以下错误:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "unexpected metadata [_id:1] in source"
}
],
"type": "illegal_argument_exception",
"reason": "unexpected metadata [_id:1] in source"
},
"status": 400
}