Redis高级篇
文章目录
- 面试题库
-
- redis有哪些用法?
- redis单线程时代性能依然很快的原因?
- 主线程和IO线程怎么协作完成请求处理的
- BigKey(重要)
-
- 什么算是BigKey?
- 怎么发现BigKey?
- 怎么删除bigkey?
- bigkey生产调优
- 缓存双写一致性问题
-
- 四大更新策略:
- canal
- 大数据统计
-
- 基数统计
- 案例实战
- 地理位置计算
-
- 代码实例
- 布隆过滤器
-
- golang简单手写布隆过滤器
- 打卡签到
- redis四大问题
-
- 缓存预热
- 缓存雪崩
- 缓存穿透
- 缓存击穿
- 聚划算案例
- redis分布式锁
-
- 锁的可重入性
- 锁的续期
- Lua脚本
- Redlock算法
- redis的缓存过期淘汰策略
- Redis源码解读
-
- String类型
-
- SDS简单字符串
- Hash类型
-
- Ziplist&Listpack
- List
- Set和Zset
- 跳表
- IO多路复用
-
- BIO
- NIO
- IO多路复用
- Select
- Poll
- epoll
面试题库
redis有哪些用法?
1.数据共享,分布式session
2.分布式锁
3.全局ID
4.计算器,点赞
5.位统计
6.购物车
7.轻量级消息队列
8.抽奖
9.点赞、签到、打卡
10.差集并集交集,用户关注、可能认识的人,推荐模型
11.热点新闻、热搜排行榜
redis单线程时代性能依然很快的原因?
1.基于内存操作:Redis的所有数据都存在内存中,因此所有的运算都是内存级别的,所以它的性能比较高
2.数据结构简单:Redis的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是O(1),因此性能比较高
3.多路复用和非阻塞I/O:Redis使用I/O多路复用功能来监听多个socket连接客户端,这样就可以用一个线程连接来处理多个请求,减少线程切换所带来的开销,同时也避免了I/O阻塞操作
4.避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的产生
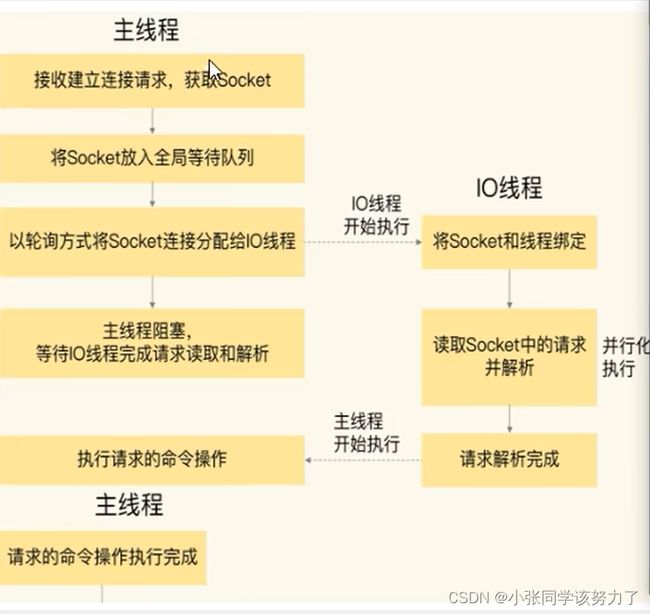
主线程和IO线程怎么协作完成请求处理的
阶段一:服务端和客户端建立Socket连接,并分配处理线程
首先,主线程负责接收建立连接请求。当有客户端请求和实例建立Socket连接时,主线程会创建和客户端的连接,并把Socket 放入全局等待队列中。紧接着,主线程通过轮询方法把Socket连接分配给IO线程。
阶段二:IO线程读取并解析请求
主线程一旦把Socket分配给IO线程,就会进入阻塞状态,等待IO线程完成客户端请求读取和解析。因为有多个IO线程在并行处理,所以,这个过程很快就可以完成。
阶段三:主线程执行请求操作
等到IO线程解析完请求,主线程还是会以单线程的方式执行这些命令操作。
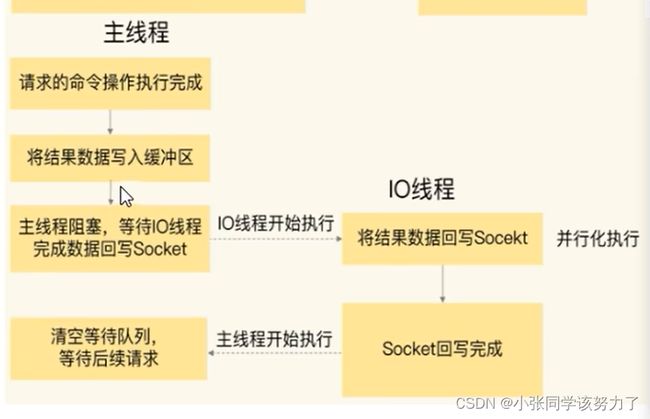
阶段四:IO线程回写Socket和主线程清空全局队列
当主线程执行完请求操作后,会把需要返回的结果写入缓冲区,然后,主线程会阻塞等待IO线程,把这些结果回写到Socket中,并返回给客户端。和IO线程读取和解析请求一样,IO线程回写Socke时,也是有多个线程在并发执行,所以回写Socket的速度也很快。等到IO线程回写Socket完毕,主线程会清空全局队列,等待客户端的后续请求。
redis是默认关闭多线程的,如果发现Redis实例的CPU开销不大但吞吐量却没有提升,那么我们可以选择开启Redis多线程:需要修改redis.conf的两个设置
io-threads 4 //加强io的线程支持
io-threads-do-redis yes //表示启动多线程
BigKey(重要)
生产上一般禁用keys *的,因为数据量一大就能非常占用CPU,禁用keys 命令和一些危险命令,需要修改redis.conf文件
rename-command keys ""
rename-command flushdb ""
rename-command flushall ""
scan命令可以代替keys *进行查询,类似于mysql的limit但不完全相同
SCAN cursor [MATCH pattern] [COUNT count]
基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程
以0作为游标开始一次新的迭代,直到命令返回游标0完成一次遍历
不保证每次执行都返回某个给定数量的元素,支持模糊查询
一次返回的数量不可控,只能是大概率符合count参数
SCAN命令是一个基于游标的迭代器,每次被调用之后,都会向用户返回一个新的游标
用户在下次迭代时需要使用这个新游标作为SCAN命令的
游标参数,以此来延续之前的迭代过程。
SCAN返回一个包含两个元素的数组
第一个元素是用于进行下一次迭代的新游标,
第二个元素则是一个数组,这个数组中包含了所有被迭代的元素。如果新游标返回零表示迭代已结束。
SCAN的遍历顺序
非常特别,它不是从第一维数组的第零位一直遍历到末尾,而是采用了高位进位加法来遍历。之所以使用这样特殊的方式进行遍历,是考虑到字典的扩容和缩容时避免槽位的遍历重复和遗漏。
MSET k1 v1 k2 v2 k3 v3
SCAN 0 match k* count 15
什么算是BigKey?
String类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000,超过就是bigkey
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除
怎么发现BigKey?
redis-cli --bigkeys
给出每种数据结构Top 1 bigkey,同时给出每种数据结构的键值个数和平均大小
如果想查询大于10kb的所有key,--bigkeys参数就无能为力了,需要用到memory usage
计算每个键值的字节数
redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys
MEMORY USAGE 键
MEMORY USAGE k100 //具体某个key占多少字节
怎么删除bigkey?
String类型一般是可以通过del删除的,特别大的建议使用unlink删除
Hash类型使用hscan每次获取少量field-value,再使用hdel删除每个field
List使用Ltrim渐进式逐步删除,直到全部删除完成
Set使用sscan每次获取部分元素,再使用srem命令删除每个元素
ZSet使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK命令删除每个元素
bigkey生产调优
修改redis.conf文件
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no //改为Yes,惰性释放删除改为Yes就变成了异步的
replica-lazy-flush no //改为Yes
lazyfree-lazy-user-del no //改为Yes
缓存双写一致性问题
读写缓存:
同步直写策略:
写数据库后也同步写redis缓存,缓存和数据库中的数据库中的数据一致性
对于读写缓存来说,要想保证缓存和数据库中的数据一致,就要采用同步直写策略
异步缓写策略:
正常业务运行中,mysql数据变动了,但是可以在业务上容许出现一定时间后才作用于redis,
比如仓库、物流系统。
异常情况出现了,不得不将失败的动作重新修补,有可能需要借助kafka或者RabbitMQ等消
息中间件,实现重试重写
双检加锁策略:
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个互斥锁来锁
住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程
进来发现已经有缓存了,就直接走缓存。
给缓存设置过期时间,定期清理缓存并回写,是保证最终一致性的解决方案。
我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即
可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数
据库中读取新值然后回填缓存,达到一致性,切记,要以mysql的数据库写入库为准。
四大更新策略:
-
先更新数据库,再更新缓存
异常问题1:回写出错 1先更新mysql的某商品的库存,当前商品的库存是100,更新为99个。 2先更新mysql修改为99成功,然后更新redis。 3此时假设异常出现,更新redis失败了,这导致mysql里面的库存是99而redis里面的还是100。 4上述发生,会让数据库里面和缓存redis里面数据不一致,读到redis脏数据 异常问题2:A、B两个线程有快有慢,有前有后有并行,会有写入覆盖 1 A update mysql 100 3 B update mysql 80 4 B update redis 80 2 A update redis 100 这样redis最后是100,mysql里是80,数据不一致
2.写更新缓存,再更新数据库
不太推荐:业务上一般把mysql作为底单数据库,保证最后解释
异常状况:
1 A update redis100
3 B update redis 80
4 B update mysql 80
2 A update mysql 100
这样redis最后是80,mysql里是100,数据不一致
3.先删除缓存,再更新数据库
异常问题1:A线程先成功删除了redis里面的数据,然后去更新mysql,此时mysql正在更新中,还没
有结束。(比如网络延时)B突然出现要来读取缓存数据。
B从mysql获得了旧值:B线程发现redis里没有(缓存缺失)马上去mysql里面读取,从数据库里
面读取来的是旧值
B会把获得的旧值写回redis:获得旧值数据后返回前台并回写进redis(刚被A线程删除的旧数据
又极大可能又被写回了)。
解决方案:延迟双删,在更新完mysql后sleep一段时间再进行一次redis删除
加上sleep的这段时间,就是为了让线程B能够先从数据库读取数据再把缺失的数据写入缓存,然后,
线程A再进行删除。所以,线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间。这样一
来,其它线程读取数据时,会发现缓存缺失,所以会从数据库中读取最新值。因为这个方案会在第一欠
删除缓存值后,延迟一段时间再次进行删除,所以我们也把它叫做“延迟双删”。
也可以将第二次删除作为异步的。自己起一个线程,异步删除。
这样,写的请求就不用沉睡一段时间后了再返回了。这么做,可以加大吞吐量。
延时双删面试题?
1.这个删除该休眠多久呢?
线程A sleep的时间,就需要大于线程B读取数据再写入缓存的时间
2.这种同步淘汰策略,吞吐量降低怎么办?
也可以将第二次删除作为异步的。自己起一个线程,异步删除。
4.先更新数据库,再删除缓存
异常问题:

假如缓存删除失败或者来不及,导致请求再次访问redis时缓存命中,读到的是缓存旧值。
1.可以把要删除的缓存值或者是要更新的数据库值暂存到消息队列中(例如使用Kafka/RabbitM等)。
2.当程序没有能够成功地删除缓存值或者是更新数据库值时,可以从消息队列中重新读取这些值,然后
再次进行删除或更新。
3.如果能够成功地删除或更新,我们就要把这些值从消息队列中去除,以免重复操作,此时,我们也可
以保证数据库和缓存的数据一致了,否则还需要再次进行重试
4.如果重试超过的一定次数后还是没有成功,我们就需要向业务层发送报错信息了,通知运维人员。
1.先动mysql,再动redis,两害相衡取其轻,避免redis业务key突然消失,多线程请求集火打满mysql
2.动,写操作:先更新数据库,再删除缓存。尝试使用双检加锁机制lock住mysql,只让一个请求线程回写redis,完成数据一致性
3.面试题提问:我想mysql有记录改动了(有增删改写操作),立刻同步反应到redis? ? ?该如何做?
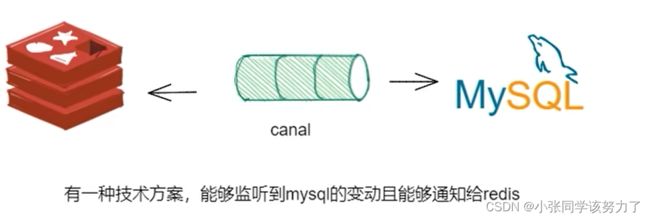
canal能够监听到mysql的变动且能够通知给redis
canal
工作原理:
1.canal模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master 发送 dump 协议
2.MySQL master 收到 dump请求,开始推送binary log 给slave (即canal )
3.canal解析 binary log对象(原始为byte流)
canal配置:
1.mysql的配置,修改my.ini,添加以下内容:
[mysqld]
log-bin=mysql-bin //开启binlog
binlog-format=ROW //选择ROW模式
//ROW模式:除了记录sql语句之外,还会记录每个字段的变化情况,能够清楚的记录每行数据的变化历史
但会占用较多的空间。
//STATEMENT模式:只记录了sql语句,但是没有记录上下文信息,在进行数据恢复的时候可能会导致数据的丢失情况;
//MIX模式:比较灵活的记录,理论上说当遇到了表结构变更的时候,就会记录为statement模式。当遇到了数据更新或者删除情况下就会变为row模式;
server_id=1 //配置MySQL replaction需要定义,不要和canal的slaveId重复
2.重启mysql
3.再次查看SHOW VARIABLES LIKE ‘log_bin’;
4.授权canal连接MYSQL账号
mysql默认的用户在mysql库的user表里
默认没有canal账户,此处新建+授权
DROP USER IF EXISTS 'canal'@'%';
CREATE USER 'canal'@'%'IDENTIFIED BY 'canal';
GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%'IDENTIFIED BY 'canal';
FLUSH PRIVILEGES;
SELECT * FROM mysql.user;
5.下载canal
地址:https://github.com/alibaba/canal/releases/tag/canal-1.1.7-alpha-2
下载:canal.deployer-1.1.7-SNAPSHOT.tar.gz
然后解压
配置:
修改/mycanal/conf/example路径下instance.properties文件
canal.instance.master.address=mysql的ip:mysql的端口号
canal.instance.dbUsername=mysql的canal用户
canal.instance.dbPassword=mysql的canal密码
canal.instance.filter.regex=.*\\..* //白名单
canal.instance.filter.black.regex=mysql\\.slave_.*//黑名单
启动:
回退到bin目录,执行命令:
./startup.sh
查看:
判断canal是否启动成功:
查看server日志
查看样例example的日志
大数据统计
四种统计:
1.聚合统计:
统计多个集合元素的聚合结果,就是前面讲解过的交差并等集合统计。可以用Set实现
2.排序统计:
抖音短视频最新评论留言的场景,设计一个展现列表。可以用Zset实现
3.二值统计
集合的取值就只有0和1两种。比如钉钉打卡上班,我们只用记录有签到和没签到。可以使用bitmap实现
4.基数统计
指统计一个集合中不重复的元素个数
基数统计
基本术语:
UV(Unique View):多少个用户点击
PV(Page View):页面浏览量(不用去重)
DAU((Daily Active User):日活跃用户量(登陆或使用了某个产品的用户数)
MAU(Monthly Active User):月活跃用户量
基数:是一种数据集,去重后的真实个数
需求:
很多计数类场景,比如每日注册IP数、每日访问IP数、页面实时访问数PV、访问用户数UV等。因为主要的目标高效、巨量地进行计数,所以对存储的数据的内容并不太关心。
也就是说它只能用于统计巨量数量,不太涉及具体的统计对象的内容和精准性。
统计单日一个页面的访问量(PV),单次访问就算一次。
统计单日一个页面的用户访问量(UV),即按照用户维度计算,单个用户一天内多次访问也只算一次。多个key的合并统计,某个门户网站的所有模块的PV聚合统计就是整个网站的总PV。
hyperloglog基本命令:
| 命令 | 作用 |
|---|---|
| pfadd key element… | 将所有元素添加到key中 |
| pfcount key | 统计key的估算值 |
| pgmerge new_key key1 key2… | 合并key至新key |
概率算法:通过牺牲准确率来换取空间,对于不要求绝对准确率的场景下可以使用,因为概率算法不直接存储数据本身,通过一定的概率统计方法预估基数值,同时保证误差在一定范围内,由于又不储存数据故此可以大大节约内存。
HyperLogLog就是一种概率算法的实现,误差仅仅只是0.81%左右
Redis使用了214=16384个桶,按照上面的标准差,误差为0.81%,精度相当高。Redis使用一个long型哈希值的前14个比特用来确定桶编号,剩下的50个比特用来做基数估计。而26=64,所以只需要用6个比特表示下标值,在一般情况下,一个HLL数据结构占用内存的大小为16384*6/8= 12kB,Redis将这种情况称为密集(dense)存储。
案例实战
UV的统计需要去重,一个用户一天内的多次访问只能算作一次
淘宝、天猫首页的UV,平均每天是1~1.5个亿左右
每天存1.5个亿的IP,访问者来了后先去查是否存在,不存在加入
代码实现:
var rdb *redis.Client
func initIp(n int) {
rand.Seed(time.Now().Unix())
for i := 0; i < n; i++ {
ip := strconv.Itoa(rand.Intn(256)) + "." + strconv.Itoa(rand.Intn(256)) + "." + strconv.Itoa(rand.Intn(256)) + "." + strconv.Itoa(rand.Intn(256))
rdb.PFAdd("count", ip)
}
}
func UV() {
result, err := rdb.PFCount("count").Result()
if err != nil {
panic(err)
}
fmt.Println(result)
}
func main() {
rdb = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:6379",
DB: 0,
})
if err := rdb.Ping().Err(); err != nil {
panic(err)
}
go initIp(1000)
for {
UV()
}
}
地理位置计算
GEO相关命令:
redis-cli --raw解决中文乱码问题
| 命令 | 作用 |
|---|---|
| GEOADD key longitude latitude member [longitude latitude member …] | GEOADD 添加位置坐标 |
| GEOPOS key member [member …] | 获取指定位置的坐标 |
| GEOHASH key member [member …] | 返回坐标的geohash表示 |
| GEODIST key member1 member2 [m\km\ft\mi] | 两个位置之间的距离 |
| GEORADIUS key longitude latitude dist [m\km\ft\mi] withcoord count 10 desc | 以半径为中心,查找附近的XXX |
| GEORADIUSbymember key member dist [m\km\ft\mi] withlist withcoord count 10 withhash | 找出给定指定范围内的元素,中心点是由给定的位置元素决定 |
代码实例
package main
import (
"fmt"
"github.com/go-redis/redis"
)
var rds *redis.Client
var key = "city"
func GEOAdd(name string, x, y float64) {
pos := &redis.GeoLocation{
Name: name,
Longitude: x,
Latitude: y,
}
rds.GeoAdd(key, pos)
}
func GetPosition(member string) (float64, float64) {
result, err := rds.GeoPos(key, member).Result()
if err != nil {
panic(err)
}
return result[0].Longitude, result[0].Latitude
}
func HashPosition(member string) string {
result, err := rds.GeoHash(key, member).Result()
if err != nil {
panic(err)
}
return result[0]
}
func DistPosition(member1 string, member2 string) float64 {
result, err := rds.GeoDist(key, member1, member2, "km").Result()
if err != nil {
panic(err)
}
return result
}
func RediusPosition(member string, dist float64) []redis.GeoLocation {
query := &redis.GeoRadiusQuery{
Count: 50,
WithDist: true,
Radius: dist,
Sort: "ASC",
}
result, err := rds.GeoRadiusByMember(key, member, query).Result()
if err != nil {
panic(err)
}
return result
}
func main() {
rds = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
})
if err := rds.Ping().Err(); err != nil {
panic(err)
}
GEOAdd("天安门", 116.403963, 39.915119)
GEOAdd("故宫", 116.403414, 39.924091)
GEOAdd("长城", 116.024067, 40.362639)
fmt.Println(GetPosition("天安门"))
fmt.Println(HashPosition("天安门"))
fmt.Println(DistPosition("天安门", "故宫"))
fmt.Println(RediusPosition("天安门", 1))
}
布隆过滤器
面试题:
现有50亿个电话号码,现有10万个电话号码,如何要快速准确的判断这些电话号码是否已经存在?
判断是否存在,布隆过滤器了解过吗?
安全连接网址,全球数10亿的网址判断
黑名单校验,识别垃圾邮件
白名单校验,识别出合法用户进行后续处理
布隆过滤器是什么?
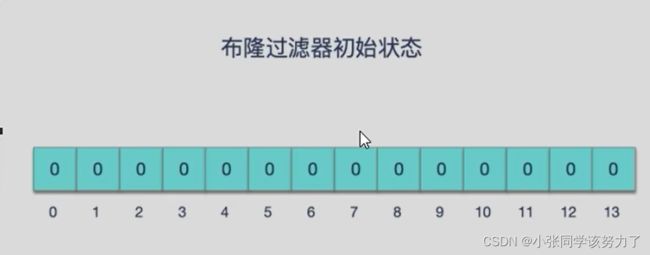
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
设计思想:本质就是判断具体数据是否存在于一个大的集合中
布隆过滤器是一种类似于set的数据结构,只是统计结果在巨量数据下有些小瑕疵,不够完美
重点:因为可能多个不同值通过哈希函数映射到同一位。所以,可能出现一个元素判断结果存在时,元素不一定存在,但是判断结果为不存在时,则一定不存在。
布隆过滤器可以添加元素,但是不能删除元素,由于涉及hashcode判断依据,删掉元素会导致误判率增加。(因为可能多个元素映射到同一个位置,修改了这个位置,就会导致其它元素判断错误)
实现原理:
添加key时
使用多个hash函数对key进行hash运算得到一个整数索引值,对位数组长度进行取模运算得到一个位
置,每个hash函数都会得到一个不同的位置,将这几个位置都置1就完成了add操作。
当我们向布隆过滤器中添加数据时,为了尽量地址不冲突,会使用多个 hash函数对 key进行运算,算得一个下标索引值,然后对位数组长度进行取模运算得到一个位置,每个 hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为1就完成了add操作。
例如,我们添加一个字符串wmyskxz,对字符串进行多次hash(key)→取模运行→得到坑位

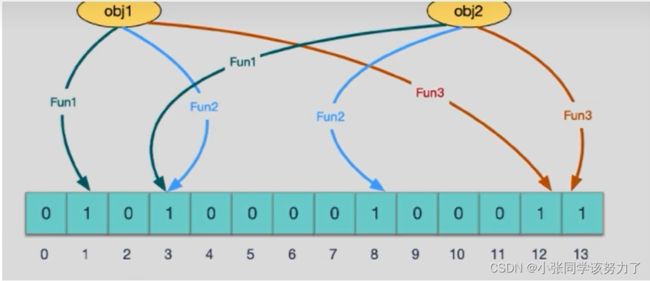
查询key时
向布隆过滤器查询某个key是否存在时,先把这个 key通过相同的多个 hash函数进行运算,查看对应的
位置是否都为1.只要有一个位为零,那么说明布隆过滤器中这个key不存在;
如果这几个位置全都是1,那么说明极有可能存在;
因为这些位置的1可能是因为其他的key存在导致的,也就是前面说过的hash冲突。
就比如我们在 add了字符串wmyskxz数据之后,很明显下面1/3/5这几个位置的1是因为第一次添加的 wmyskxz而导致的;此时我们查询一个没添加过的不存在的字符串inexistent-key,它有可能计算后坑位也是1/3/5,这就是误判了…笔记见最下面
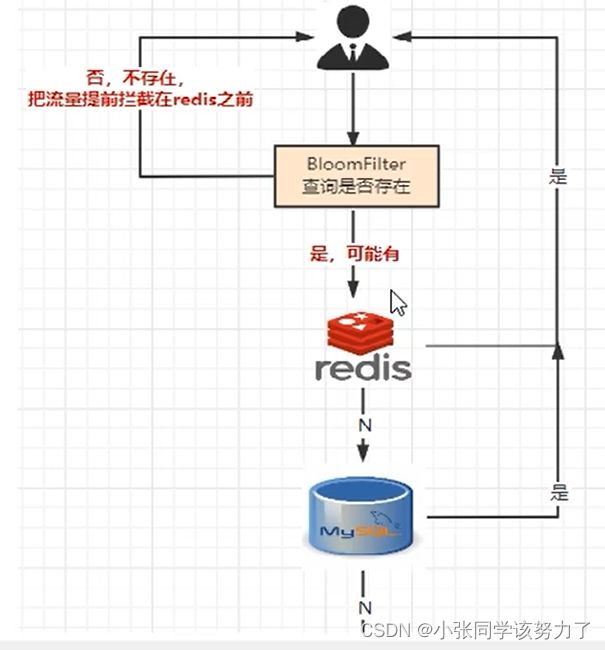
正是基于布隆过滤器的快速检测特性,我们可以在把数据写入数据库时,使用布隆过滤器做个标记。当缓存缺失后,应用查询数据库时,可以通过查询布隆过滤器快速判断数据是否存在。如果不存在,就不用再去数据库中查询了。这样一来,即使发生缓存穿透了,大量请求只会查询Redis和布隆过滤器,而不会积压到数据库,也就不会影响数据库的正常运行。布隆过滤器可以使用Redis实现,本身就能承担较大的并发访问压力。
使用3步骤:
1.初始化bitmap
2.添加占坑位
3.判断是否存在
总结:
是否存在:
有,是很可能有
无,是肯定无,100%无
使用时最好不要让实际元素数量远大于初始化数量,一次给够避免扩容
当实际元素数量超过初始化数量时,应该对布隆过滤器进行重建,
重新分配一个size更大的过滤器,再将所有的历史元素批量add进行
布隆过滤器的使用场景:
1.解决缓存穿透的问题,和redis结合bitmap使用
2.黑名单校验,识别垃圾邮件
发现存在黑名单中的,就执行特定操作。比如:识别垃圾邮件,只要是邮箱在黑名单中的邮件,就识别为
垃圾邮件。
假设黑名单的数量是数以亿计的,存放起来就是非常耗费存储空间的,布隆过滤器则是一个较好的解决
方案。
把所有黑名单都放在布隆过滤器中,在收到邮件时,判断邮件地址是否在布隆过滤器中即可。
3.安全连接网址,全球上10亿的网址判断
golang简单手写布隆过滤器
package main
import (
"fmt"
"math"
"github.com/go-redis/redis"
"github.com/spaolacci/murmur3"
)
var rds *redis.Client
var salt = "Yogen"
func Hash(val string) (int64, int64) {
hasher := murmur3.New128()
hasher.Write([]byte(val))
v1, v2 := hasher.Sum128()
base := uint64(math.Pow(2, 32))
v1, v2 = v1%base, v2%base
int_v1, int_v2 := int64(v1), int64(v2)
if int_v1 < 0 {
int_v1 = -int_v1
}
if int_v2 < 0 {
int_v2 = -int_v2
}
return int_v1, int_v2
}
func PushHash(val string) {
v1, v2 := Hash(val)
v3, v4 := Hash(val + salt)
rds.SetBit("bloom", v1, 1)
rds.SetBit("bloom", v2, 1)
rds.SetBit("bloom", v3, 1)
rds.SetBit("bloom", v4, 1)
}
func CheckHash(val string) bool {
v1, v2 := Hash(val)
v3, v4 := Hash(val + salt)
result := rds.GetBit("bloom", v1).Val()
result2 := rds.GetBit("bloom", v2).Val()
result3 := rds.GetBit("bloom", v3).Val()
result4 := rds.GetBit("bloom", v4).Val()
return result != 0 && result2 != 0 && result3 != 0 && result4 != 0
}
func main() {
rds = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
})
if err := rds.Ping().Err(); err != nil {
panic(err)
}
PushHash("hello world")
fmt.Println(CheckHash("hello world"))
}
打卡签到
面试题案例:
日活统计
连续签到打卡
最近一周的活跃用户
统计指定用户一年之中的登陆天数
某用户按照一年365天,哪几天登陆过?哪几天没有登陆?全年中登录的天数共计多少?
Bitmap:用String类型作为底层数据结构实现的一种统计二值状态的数据类型
位图本质是数组,它是基于String数据类型的按位的操作。该数组由多个二进制位组成,
每个二进制位都对应一个偏移量(我们可以称之为一个索引或者位格)。Bitmap支持的最大位数是232位,它可以极大的节约存储空间,使用512M内存就可以存储多大42.9亿的字节信息(232=4294967296)
redis四大问题
面试题:
1.缓存预热、雪崩、穿透、击穿分别是什么?你遇到过那几个情况?
2.缓存预热你是怎么做的?
3.如何避免或者减少缓存雪崩?
4.穿透和击穿有什么区别?他两是一个意思还是截然不同?
5.穿透和击穿你有什么解决方案?如何避免?
6.假如出现了缓存不一致,你有哪些修补方案?
缓存预热
什么是缓存预热?
msyql假如新增100条记录,一般默认以mysql为准作为底单数据,如何同步给redis(布隆过滤器),这100条合法数据???
为什么需发预热
mysql有100条新记录,redis无
1.比较懒,什么都不做,之对mysql做了数据新增,利用redis的回写机制,让它逐步实现100条新增记录的同步,最好提前晚上部署发布的时候,由自己人提前做一次,让redis同步了,不要把这个问题留给客户
2.通过中间件或者程序自行完成
缓存雪崩
发生:
1.redis主机挂了,Redis全盘崩溃,偏硬件运维
2.redis中有大量key同时过期大面积失效,偏软件开发
预防+解决:
1.redis中key设置为永不过期or 过期时间错开
2.redis缓存集群实现高可用
主从+哨兵
Redis Cluster
开启Redis持久化机制AOF/RDB,尽快恢复缓存集群
3.多缓存结合预防雪崩
ehcache本地缓存+redis缓存
4.服务降级
Hystrix或者阿里sentinel限流&降级
5.人民币玩家
阿里云-云数据库Redis版
缓存穿透
请求去查询一条记录,先查redis无,后查mysql无,都查询不到该条记录但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,
这种现象我们称为缓存穿透,这个redis变成一个摆设。。。
简单说就是
本来无一物,两库都没有。
既不在Redis缓存库,也不在mysql,数据库存在被多次暴击风险
解决方案:
1.空对象缓存或者缺省值
2.Google布隆过滤器Guava解决缓存穿透
缓存击穿
正常,一开始redis有,mysql有
突然,出现高频访问的redis热点key的失效
1自然过期时间的,突然时间到了,没了----> mysql
2 delete老的key,换上新的key。del动作的时候,key突然失效了但又刚好被访问到。
简单说就是热点key突然失效了,暴打mysql
危害:
会造成某一时刻数据库请求量过大,压力剧增
一般技术部门需要知道热点key是哪些?做到心里有数防止击穿
解决:
1.差异失效时间,对于访问频繁的热点key,干脆就不设置过期时间
2.互斥更新,采用双检加锁策略
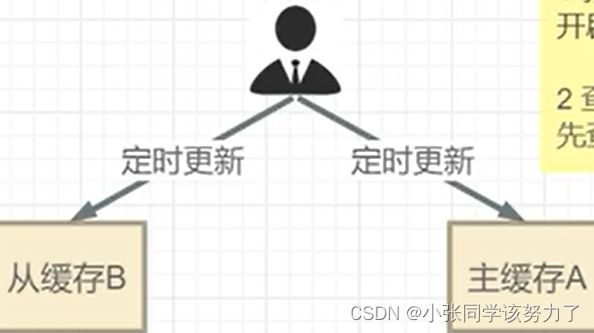
如何解决缓存击穿:
1.新建
开辟两块缓存,主A从B,先更新B再更新A,严格按照这个顺序
2.查询
先查询主缓存A,如果A没有(消失了或者失效了)再查询从缓存B
聚划算案例
package main
import (
"encoding/json"
"log"
"math/rand"
"strconv"
"sync"
"time"
"github.com/go-redis/redis"
)
type Product struct {
ID int
Name string
Price float32
Detail string
}
const preffix = "jhs"
var lock sync.WaitGroup
var rds *redis.Client
func InsertData(n int) {
//先删除原来的数据
rds.Del(preffix)
rand.Seed(time.Now().Unix())
for i := 0; i < n; i++ {
id := rand.Intn(10000)
product := &Product{
ID: id,
Name: "product" + strconv.Itoa(i),
Price: float32(i),
Detail: "detail" + strconv.Itoa(i),
}
//加入最新的数据
marshal, _ := json.Marshal(product)
if err := rds.LPush(preffix, marshal).Err(); err != nil {
panic(err)
}
}
}
func CheckData(offset int64, size int64) {
start := (offset - 1) * size
end := start + size - 1
result := rds.LRange(preffix, size, end).Val()
real_result := []Product{}
var product Product
for _, v := range result {
json.Unmarshal([]byte(v), &product)
real_result = append(real_result, product)
}
log.Println("参加活动的商家", real_result)
}
func InitJHS() {
log.Println("启动定时器天猫聚划算功能模拟开始......")
//1.用线程模拟定时任务,后台任务定时将mysql里面的参加活动的商品刷新到redis里
go func() {
for {
InsertData(30)
CheckData(2, 10)
//一分钟模拟一天更换聚划算商品
time.Sleep(10 * time.Second)
}
}()
}
func main() {
rds = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
})
if err := rds.Ping().Err(); err != nil {
panic(err)
}
lock.Add(1)
InitJHS()
lock.Wait()
}
这个案例存在着缓存击穿的问题,双缓存解决方案如下:
package main
import (
"encoding/json"
"log"
"math/rand"
"strconv"
"sync"
"time"
"github.com/go-redis/redis"
)
type Product struct {
ID int
Name string
Price float32
Detail string
}
const preffix = "jhs"
var lock sync.WaitGroup
var rds *redis.Client
var rds2 *redis.Client
func InsertData(n int) {
//先删除原来的数据
rds2.Del(preffix)
rds.Del(preffix)
rand.Seed(time.Now().Unix())
for i := 0; i < n; i++ {
id := rand.Intn(10000)
product := &Product{
ID: id,
Name: "product" + strconv.Itoa(i),
Price: float32(i),
Detail: "detail" + strconv.Itoa(i),
}
//加入最新的数据
marshal, _ := json.Marshal(product)
if err := rds.LPush(preffix, marshal).Err(); err != nil {
panic(err)
}
if err := rds2.LPush(preffix, marshal).Err(); err != nil {
panic(err)
}
//先更新B缓存让B缓存过期时间超过A缓存,如果A突然失效还有B兜底,防止击穿
rds.Expire(preffix, 24*time.Hour+10*time.Second)
rds2.Expire(preffix, 24*time.Hour)
}
}
func CheckData(offset int64, size int64) {
start := (offset - 1) * size
end := start + size - 1
result := rds.LRange(preffix, size, end).Val()
if result == nil {
result = rds2.LRange(preffix, size, end).Val()
}
real_result := []Product{}
var product Product
for _, v := range result {
json.Unmarshal([]byte(v), &product)
real_result = append(real_result, product)
}
log.Println("参加活动的商家", real_result)
}
func InitJHS() {
log.Println("启动定时器天猫聚划算功能模拟开始......")
//1.用线程模拟定时任务,后台任务定时将mysql里面的参加活动的商品刷新到redis里
go func() {
for {
InsertData(30)
CheckData(2, 10)
//一分钟模拟一天更换聚划算商品
time.Sleep(10 * time.Second)
}
}()
}
func main() {
rds = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
})
rds2 = redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9912",
DB: 0,
})
if err := rds.Ping().Err(); err != nil {
panic(err)
}
lock.Add(1)
InitJHS()
lock.Wait()
}
redis分布式锁

一个靠谱的分布式锁需要具备的条件和刚需:
1.独占性:任意时刻只能有且仅有一个线程持有
2.高可用:若redis集群环境下,不能因为某一个节点挂了而出现获取锁和释放锁失败的情况,高并发请求下,依旧性能OK
3.防死锁:杜绝死锁,必须有超时控制机制或者撤销操作,有个兜底终止跳出方案
4.不乱抢:防止张冠李戴,不能私下unlock别人的锁,只能自己加锁自己释放
5.重入性:同一个节点的同一个线程如果获得锁之后,它也可以再次获取这个锁
重点:JUC中AQS锁的规范落地参考+可重入锁考虑+Lua脚本+Redis命令一步步实现分布式锁
一个简单的分布式锁
package main
import (
"time"
"github.com/go-redis/redis"
)
type Lock struct {
rds *redis.Client
key string
}
var lock Lock
func (l Lock) lock(val string) {
for l.rds.SetNX(l.key, val, 10*time.Second).Val() == false {
time.Sleep(20 * time.Millisecond)
}
}
func (l Lock) unlock(val string) {
if l.rds.Get(l.key).Val() != val {
return
}
l.rds.Del(l.key)
}
func main() {
lock = Lock{
rds: redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
}),
key: "RedisLock",
}
lock.lock("test")
if err := lock.rds.Decr("key1").Err(); err != nil {
panic(err)
}
lock.unlock("test")
}
问题:unlock里面的判断和删除操作并不是原子性的
需要启动lua脚本编写redis分布式锁判断+删除判断代码
锁的可重入性
可重入锁:又称递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提,锁对象得是同一个对象),不会因为之前已经获取过还没释放而阻塞。
如果是1个有 synchronized修饰的递归调用方法,程序第2次进入被自己阻塞了岂不是天大的笑话,
出现了作茧自缚。所以Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点
是可一定程度避免死锁。
一句话:自己可以获取自己的内部锁
隐式锁(即synchronized关缝字使用的锁)默认是可重入锁
指的是可重复可递归调用的锁,在外层使用锁之后,在内层仍然可以使用,并且不发生死锁,这样的锁
就叫做可重入锁。
简单的来说就是:在一个synchronized修饰的方法或代码块的内部调用本类的其他synchronized修饰的方
法或代码块时,是永远可以得到锁的
与可重入锁相反,不可重入锁不可递归调用,递归调用就发生死锁。
synchronized可重入的实现机理:
每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
当执行monitorenter时,如果目标锁对象的计数器为零,那么说明它没有被其他线程所持有,Java虚拟
机会将该锁对象的持有线程设置为当前线程,并且将其计数器加1。
在目标锁对象的计数器不为零的情况下,如果锁对象的持有线程是当前线程,那么Java虚拟机可以将其
计数器加1,否则需要等待,直至持有线程释放该锁。
当执行monitorexit时,Java虚拟机则需将锁对象的计数器减1。计数器为零代表锁己被释放。
如果想要使redis可重入,则需要使用redis当中的hash结构
EXISTS RedisLock //有没有分布式锁
HSET RedisLock 线程id等一些信息 1 //没有则新建一个自己的锁,加锁数为1
HINCRBY RedisLock 线程id等一些信息 -1 //退出时将引用数减1
DEL RedisLock //整个使用完之后删除锁
HEXISTS RedisLock 线程id等一些信息 //如果锁是自己的
HINCRBY RedisLock 线程id等一些信息 1//如果存在该线程的锁则加锁数加1
锁的续期
自动续期:
1.确保redisLock过期时间大于业务执行时间的问题
2.CAP
3.加个钟
Lua脚本
Lua是—种经量小巧的脚本语言,用标住C语言编写并以源代码形式开放,其设计目的是为了嵌入应用程序中,
从而为应用程序提供灵活的扩展和定制功能。
Lua是巴西里约热内卢天主教大学(Pontifical catholic University of Rio de Janeiro)里的一个研究小组于1993年开发的,该小组成员有:Roberto lerusalimschy、waldemar Celes和Luiz Hennique de Figuelredo.
设计目的:
其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Lua特性:
轻量级:它用标准C语言编写并以源代码形式开放,编译后仅仅一百余K,可以很方便的嵌入别的程序里。
可扩展: Lua提供了非常易于使用的扩展接口和机制:由宿主语言(通常是C或C++)提供这些功能,Lua可以使用它们,就像是本来内置的功能一样。
Redis调用Lua脚本通过eval命令保证代码执行的原子性,直接用return返回脚本执行后的结果值
eval luascript numkeys [key [key …]][arg [arg …]]
EVAL "return'hello lua'" 0
EVAL "redis.call('set','k1','v1') redis.call('expire','k1','30') return redis.call('get','k1')" 0
//三条命令一块执行,redis.call()就是把这个命令当作一行执行
EVAL "return redis.call('mset',KEYS[1],ARGV[1],KEYS[2],ARGV[2])" 2 k1 k2 lua1 lua2
分布式锁原子查询和删除
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
lua脚本改进分布式锁实现检索和删锁的可重入性
package main
import (
"time"
"github.com/go-redis/redis"
)
type Lock struct {
rds *redis.Client
key string
}
var lock Lock
func (l Lock) lock(val string) {
for l.rds.SetNX(l.key, val, 10*time.Second).Val() == false {
time.Sleep(20 * time.Millisecond)
}
}
func (l Lock) unlock(val string) {
script := `if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end`
if err := l.rds.Eval(script, []string{l.key}, val).Err(); err != nil {
panic(err)
}
}
func main() {
lock = Lock{
rds: redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
}),
key: "RedisLock",
}
lock.lock("test")
if err := lock.rds.Decr("key1").Err(); err != nil {
panic(err)
}
lock.unlock("test")
}
lua脚本改进分布式锁实现可重入性
加锁lua脚本
if redis.call('exists',KEYS[1])==0 or redis.call('hexists',KEYS[1],ARGV[1])==1 then
redis.call('hincrby',KEYS[1],ARGV[1],1)
redis.call('expire',KEYS[1],ARGV[2])
return 1
else
return 0
end
EVAL "if redis.call('exists',KEYS[1])==0 or redis.call('hexists',KEYS[1],ARGV[1])==1 then redis.call('hincrby',KEYS[1],ARGV[1],1) redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end" 1 test 1 50
解锁lua脚本
if redis.call('hexists',KEYS[1],ARGV[1])==0 then
return nil
elseif redis.call('hincrby',KEYS[1],ARGV[1],-1)==0 then
return redis.call('del',KEYS[1])
else
return 0
end
EVAL "if redis.call('hexists',KEYS[1],ARGV[1])==0 then return nil elseif redis.call('hincrby',KEYS[1],ARGV[1],-1)==0 then return redis.call('del',KEYS[1]) else return 0 end" 1 test 1
package main
import (
"fmt"
"time"
"github.com/go-redis/redis"
)
type RedisLock struct {
rds *redis.Client
key string
}
type Lock interface {
lock(string)
unlock(string)
}
var lock Lock
func NewRedisLock(key string) *RedisLock {
return &RedisLock{
rds: redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
}),
key: key,
}
}
func (l RedisLock) lock(val string) {
script := `if redis.call('exists',KEYS[1])==0 or redis.call('hexists',KEYS[1],ARGV[1])==1 then redis.call('hincrby',KEYS[1],ARGV[1],1) redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end`
for l.rds.Eval(script, []string{l.key}, val, 50).Val() != 1 {
time.Sleep(20 * time.Millisecond)
}
}
func (l RedisLock) unlock(val string) {
script := `if redis.call('hexists',KEYS[1],ARGV[1])==0 then return nil elseif redis.call('hincrby',KEYS[1],ARGV[1],-1)==0 then return redis.call('del',KEYS[1]) else return 0 end`
if err := l.rds.Eval(script, []string{l.key}, val).Err(); err != nil {
panic(err)
}
}
func main() {
lock = NewRedisLock("testLock")
lock.lock("test")
fmt.Println("123")
lock.unlock("test")
}
自动续期:
if redis.call('HEXISTS',KEYS[1],ARGV[1])==1 then
return redis.call('expire',KEYS[1],ARGV[2])
else
return 0
end
EVAL "if redis.call('HEXISTS',KEYS[1],ARGV[1])==1 then return redis.call('expire',KEYS[1],ARGV[2]) else return 0 end" 1 test 1 50
package main
import (
"fmt"
"time"
"github.com/go-redis/redis"
)
type RedisLock struct {
rds *redis.Client
key string
}
type Lock interface {
lock(string, int)
unlock(string)
renewlock(string, int, *time.Timer) int
}
var lock Lock
func NewRedisLock(key string) *RedisLock {
return &RedisLock{
rds: redis.NewClient(&redis.Options{
Addr: "127.0.0.1:9911",
DB: 0,
}),
key: key,
}
}
func (l RedisLock) lock(val string, t int) {
script := `if redis.call('exists',KEYS[1])==0 or redis.call('hexists',KEYS[1],ARGV[1])==1 then redis.call('hincrby',KEYS[1],ARGV[1],1) redis.call('expire',KEYS[1],ARGV[2]) return 1 else return 0 end`
for l.rds.Eval(script, []string{l.key}, val, t).Val() != 1 {
time.Sleep(20 * time.Millisecond)
}
}
func (l RedisLock) unlock(val string) {
script := `if redis.call('hexists',KEYS[1],ARGV[1])==0 then return nil elseif redis.call('hincrby',KEYS[1],ARGV[1],-1)==0 then return redis.call('del',KEYS[1]) else return 0 end`
if err := l.rds.Eval(script, []string{l.key}, val).Err(); err != nil {
panic(err)
}
}
func (l RedisLock) renewlock(val string, t int, myT *time.Timer) int {
script := `if redis.call('HEXISTS',KEYS[1],ARGV[1])==1 then return redis.call('expire',KEYS[1],ARGV[2]) else return 0 end`
<-myT.C
return l.rds.Eval(script, []string{l.key}, val, t).Val().(int)
}
func main() {
lock = NewRedisLock("testLock")
lock.lock("test", 50)
fmt.Println("123")
go func() {
myT := time.NewTimer(30 * time.Second)
for lock.renewlock("test", 50, myT) != 0 {
}
}()
lock.unlock("test")
}
Redlock算法
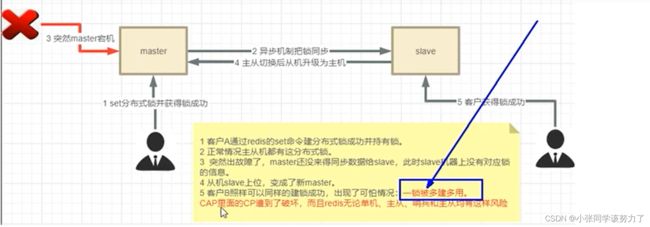
之前的锁存在的问题:
红锁算法:
在算法的分布式版本中,我们假设我们有N个Redis 主节点,这些节点是完全独文的,所以我们不使用复制或任何其他隐式协调系统。我们已经描述了如何在单个实例中安全地获取和释放锁。我们想当然地认为算法会使用这个方法在单个实例中获取和释放锁。在我们的示例中,我们设置N=5,这是一个合理的值,因此我们需要在不同的计算机或虚拟机上运行5个Redis master,以确保它们以几乎独立的方式发生故障。
为了获取锁,客户端执行以下操作:
1.它以毫秒为单位获取当前时问。
2.它尝试在所有N个实例中顺序获取锁,在所有实例中使用相同的键名和随机值。在步骤2中,在每个
实例中设置锁时,客户端使用与总锁自动释放时间相比较小的超时来获取琐。例如,如果自动释放时间
为10秒,则超时可能在~5-50毫秒范围内,这可以防止客户端在尝试与已关闭的Redis 节点通信时长时
问处于阻塞状态:如果一个实例不可用,我们应该尽快尝试与下一个实例通信。
3.客户端通过从当前时问减去步骤1中获得的时问戳来计算获得锁所用的时间。当且仅当客户端能够在
大多数实例(至少3个)中获得锁时,并且获得锁的总时间小于锁有效期,则认为获得了锁.
4.如果获得了锁,则其有效时问被认为是初始有效时间减去经过的时间,如步骤3中计算的那样。
5.如果客户端由于某种原因未能获得锁(要么无法锁定N/2+1个实例,要么有效期为负),它将尝试解
锁所有实例(即使是它认为不能锁定的实例)可以锁定)
该方案为了解决数据不一致的问题,直接舍弃了异步复制只使用master节点,同时由于舍弃了 slave,为了保证可用性,引入了N个节点
package main
import (
"github.com/go-redis/redis"
"github.com/go-redsync/redsync/v4"
"github.com/go-redsync/redsync/v4/redis/goredis/v8"
)
func main() {
// Create a pool with go-redis (or redigo) which is the pool redisync will
// use while communicating with Redis. This can also be any pool that
// implements the `redis.Pool` interface.
client := redis.NewClusterClient(&redis.ClusterOptions{
Addrs: []string{"0.0.0.0:6379", "0.0.0.0:6380"},
})
pool := goredis.NewPool(client) // or, pool := redigo.NewPool(...)
// Create an instance of redisync to be used to obtain a mutual exclusion
// lock.
rs := redsync.New(pool)
// Obtain a new mutex by using the same name for all instances wanting the
// same lock.
mutexname := "my-global-mutex"
mutex := rs.NewMutex(mutexname)
// Obtain a lock for our given mutex. After this is successful, no one else
// can obtain the same lock (the same mutex name) until we unlock it.
if err := mutex.Lock(); err != nil {
panic(err)
}
// Do your work that requires the lock.
// Release the lock so other processes or threads can obtain a lock.
if ok, err := mutex.Unlock(); !ok || err != nil {
panic("unlock failed")
}
}
redis的缓存过期淘汰策略
生产上你们的redis内存设置多少?
如何配置、修改redis的内存大小?
如果内存满了你怎么办?
redis清理内存的方式?定期删除和惰性删除了解过吗?
redis缓存淘汰策略有哪些?分别是什么?你用那个?
redis的LRU了解过吗?请手写LRU
lru和lfu算法的区别是什么
redis的内存大小是由redis.conf中的maxmemory 决定,单位是字节数,默认是0代表不限制redis内存的使用
maxmemory <bytes>
生产上推荐Redis设置内存为最大物理内存的四分之三
如何修改redis内存设置:
1.通过修改文件配置
maxmemory 1048576
2.通过命令修改
config get maxmemory
config set maxmemory 1048576
查看redis内存使用情况?
info memory
config get maxmemory
Redis不可能时时刻刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。
立即删除:
能保证内存中数据的最大新鲜度,因为它保证过期键值会在过期后马上被删除,其所占用的内存也会随
之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙
的时候,比如正在做交集或排序等计算的时候,就会给cpu造成额外的压力,让CPU心累,时时需要删
除,忙死。
总结:对CPU不友好,用处理器性能换取存储空间
惰性删除:
数据到达过期时间,不做处理。等下次访问该数据时:
如果未过期,返回数据;
发现已过期,删除,返回不存在。
总结:对内存不友好,用存储空间换取处理器性能
开启懒性淘汰:
lazyfree-lazy-eviction yes
定期删除:
定期删除策略每隔一段时间执行一次删除过期键操作并通过限制删除操作执行时长和频率来减少删除操
作对CPU时间的影响。
周期性轮询redis库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频度
特点1:CPU性能占用设置有峰值,检测频度可自定义设置
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理
总结:周期性抽查存储空间(随机抽查,重点抽查)
缺点:有漏网之鱼
LRU:最近最少使用页面置换算法,淘冰最长时间未被使用的页面,看页面最后
一次被使用到发生调度的时间长短,首先淘汰最长时间未被使用的页面。
LFU:最近最不常用页面置换算法,淘汰一定时期内被访问次数最少的页,看一定时间段内页面被使用的频率,淘汰一定时期内被访问次数最少的页
缓存淘汰策略:
1.noeviction:不会驱逐任何key,表示即使内存达到上限也不进行置换,所有能引起内存增加的命令都会
返回error
2. allkeys-lru:对所有key使用LRU算法进行删除,优先删除掉最近最不经常使用的key,用以保存新数据
3. volatile-lru:对所有设置了过期时间的key使用LRU算法进行删除
4.allkeys-random:对所有key随机删除
5.volatile-random:对所有设置了过期时间的key随机删除
6.volatile-ttl:删除马上要过期的key
7.allkeys-lfu:对所有key使用LFU算法进行删除
8.volatile-lfu:对所有设置了过期时间的key使用LFU算法进行删除
如何选择:
1.在所有的 key都是最近最经常使用,那么就需要选择 allkeys-Iru进行置换最近最不经常使用的key,如
果你不确定使用哪种策略,那么推荐使用allkeys-lru
2.如果所有的 key 的访问概率都是差不多的,那么可以选用allkeys-random 策略去置换数据
3.如果对数据有足够的了解,能够为key 指定 hint(通过expire/ttl指定),那么可以选择volatile-ttl进行置换
Redis源码解读
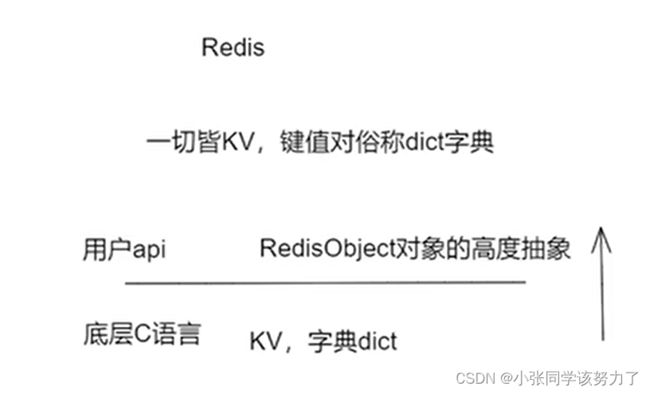
redis当中的object
struct type_name{
member_type1 member_name1;
member_type2 member_name2;
member_type3 member_name3;
……
}object_names;
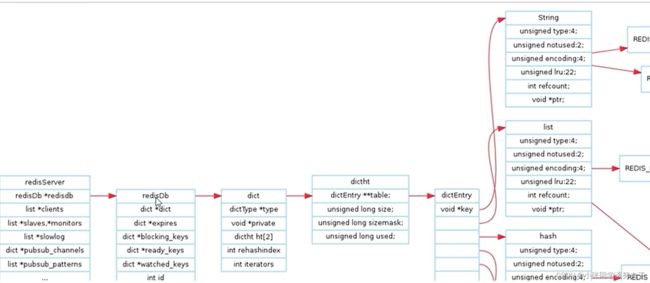
每个键值对都会有一个dictEntry
typedef struct dictEntry{
void *key; //指向String对象
union{
void *val;
uint64_t u64;
int64_t s64;
double d
}v;//既能指向String对象,也能指向集合类型的对象(比如List+Hash+Set+Zset对象)
struct dictEntry *next;
void *metadata[];
}dictEntry;
redisObject
typedef struct redisObject{
unsigned type:4;//当前值对象的数据类型
unsigned encoding:4;//当前值对象底层存储的编码类型,4位encoding物理编码,同一种数据类型可能有不同的编码方式
unsigned lru:LRU:BITS;//采用LRU算法清除内存中的对象
/*LRU time (relative to global lru_clock) or LFU
data (least significant 8 bits frequency and most significant 16 bits
access time).*/
int refcount;//记录对象引用次数
void *ptr;//指向真正的底层的数据结构的指针
}robj;
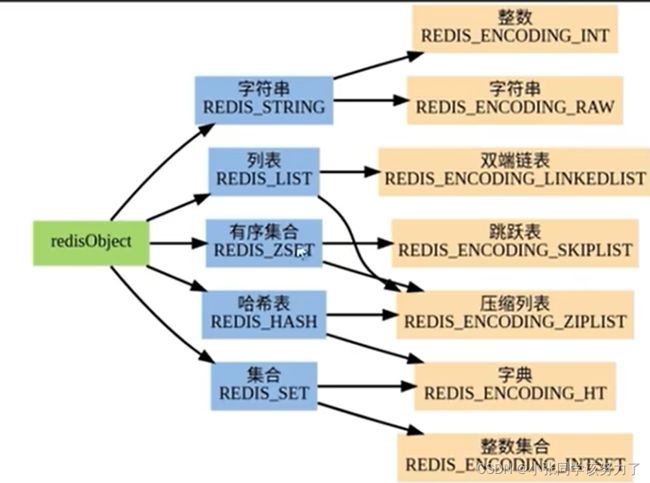
redis6:

String=SDS
Set=intset+hashtable
ZSet=skipList+zipList
List=quickList+zipList
Hash=hashtable+zipList
redis7:

String=SDS
Set=intset+hashtable
ZSet=skipList+listpack
List=quickList
Hash=hashtable+listpack
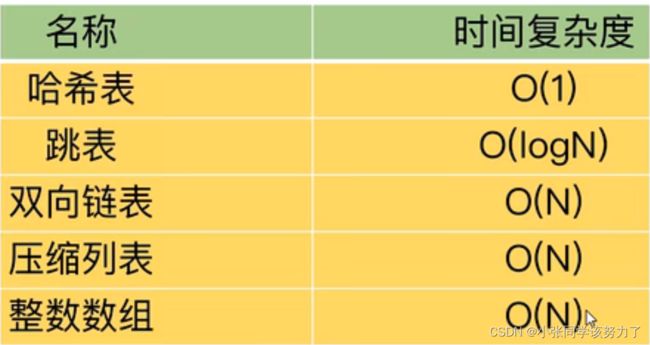
OBJECT ENCODING key //查看key的具体类型
DEBUG OBJECT key //需要修改conf文件中的enable-debug-command local
String类型
String三大物理编码方式:
1.int:保存long(长整型)的64位有符号整数
补充:只有整数才会使用int,如果是浮点数,redis内部其实先将浮点数转化为字符串
值,然后再保存
2.embstr:代表embstr格式的SDS(Simple Dynamic String:简单动态字符串),保存长度小
于44字节的字符串
EMBSTR顾名思义:表示嵌入式的String
3.raw:保存长度大于44字节的字符串
SDS简单字符串
struct _attribute_((_packed_))sdshdr8{
uint8_t len; //字符串长度
uint8_t alloc; //分配的空间长度
unsigned char flags; //sds类型
char buf[]; //字节数组
};
一个字符串最大512MB
Redis中字符串的实现,SDS有多种结构((sds.h) :
sdshdr5、(2^5=32byte)
sdshdr8、(2 ^8=256byte)
sdshdr16、(2^16=65536byte=64KB)
sdshdr32、(2^32byte=4GB)
sdshdr64,2的64次方byte=17179869184G用于存储不同的长度的字符串。
len表示SDS的长度,使我们在获取字符串长度的时候可以在О(1)情况下拿到,而不是像C
那样需要遍历一遍字符串。
alloc 可以用来计算. free就是字符串已经分配的未使用的空间,有了这个值就可以引入预分
配空间的算法了,而不用去考虑内存分配的问题。
buf表示字符串数组,真实存储数据

当字符串键值的内容可以用一个64位有符号整形来表示时,Redis会将健值转化为long型来进行存储,此时即对应0BJ_ENCODING_INT编码类型。内部的内存结构表示如下:
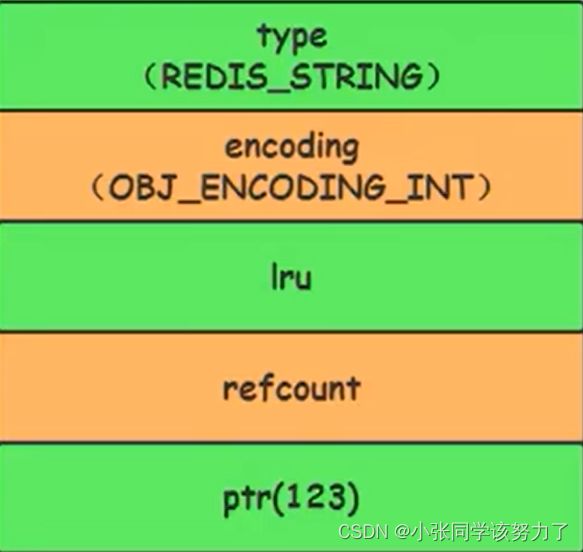
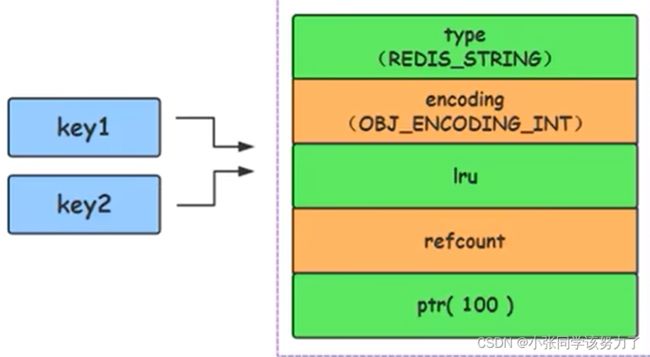
Redis启动时会预先建立.10000个分别存储0~9999 的 redisObject变量作为共享对象,这就意味着如果 set字符串的键值在0~10000之间的话,则可以直接指向共享对象而不需要再建立新对象,只需要指向共享对象,此时键值不占空间!
set k1 123
set k2 123
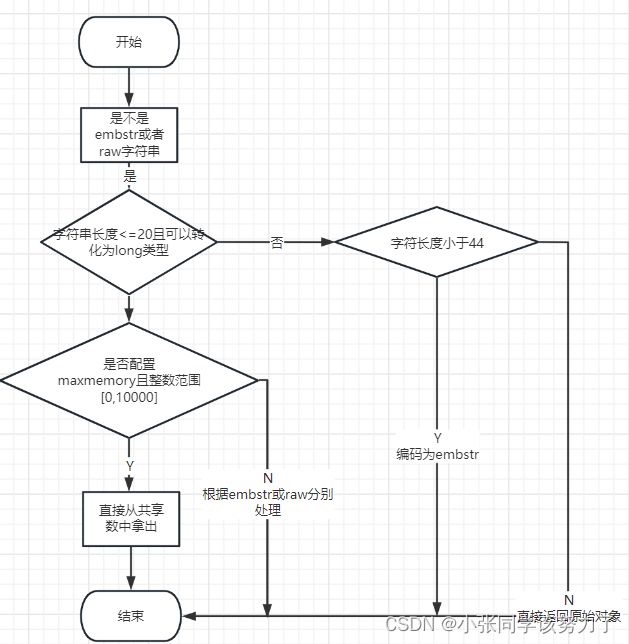
对于长度小于44的字符串,Redis对键值采用OBJ_ENCODING_EMBSTR方式,EMBSTR顾名思义即: embedded string,表示嵌入式的String。从内存结构上来讲即字符串sds结构体与其对应的 redisObject对象分配在同一块连续的内存空间,字符串sds嵌入在redisObject对象之中一样。
超过44超长字符串时,以OBJ_ENCODING_RAW编码方式存储,这与OBJ_ENCODING_EMBSTR编码方式的不同之处在于,此时动态字符串sds的内存与其依赖的redisObject的内存不再连续了
有时候没有超过44字节也会变成embstr?
对于embstr,由于其实现是只读的,因此在对embstr对象进行修改时,都会先转化为raw再进行修改。因此,只要是修改新embstr对象,修改后的对象一定是raw的,无论是否达到了44个字节。
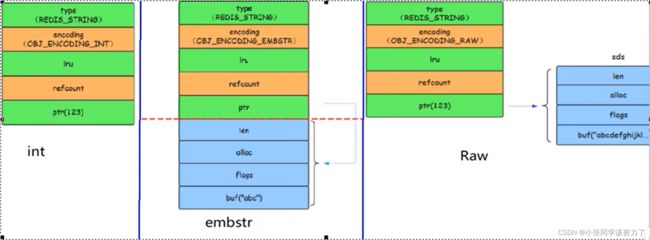
| 类型 | 描述 |
|---|---|
| int | Long类型整数时,RedisObject中的ptr指针直接赋值为整数数据,不再额外的指针再指向整数了,节省了指针的空间开销 |
| embstr | 当保存的是字符串数据且字符串小于等于44字节时,embstr类型将会调用内存分配函数,只分配一块连续的内存空间,空间中依次包含redisObject与sdshdr两个数据结构,让元数据、指针和SDS是一块连续的内存区域,这样就可以避免内存碎片 |
| raw | 当字符串大于44字节时,SDS的数据量变多变大了,SDS何RedisObject布局分家各自过,会给SDS分配多的空间并用指针指向SDS结构,raw类型将会调用两次内存分配函数,分配两块内存空间,一块用于包含redisObject结构,而另一块用于包含sdshdr结构 |
Hash类型
Hash的两种编码格式:
1.redis6:ziplist+hashtable
2.redis7:listpack+hashtable
hash当中的config
hash-max-ziplist-entries:使用压缩列表保存时哈希集合中的最大元素个数
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度
Hash类型键的字段个数小于hash-max-ziplist-entries 并且每个字段名和字段值的长度小于 hash-max-ziplist-value时:
Redis才会使用OBl_ENCODING_ZIPLIST来存储该键,前述条件任意一个不满足则会转换为OBJ_ENCODING_HT的编码方式
一旦从压缩列表转成了哈希表,Hash类型就会一直用哈希表进行保存而不会再转回压缩列表了。
在节省内存空间方面哈希表就没有压缩列表高效了。
在Redis中,hashtable被称为字典,它是一个数组+链表的结构
OBJ_ENCODING_HT 编码分析——每个键值对应一个dictEntry
typedef struct dictEntry{
void *key; //指向String对象
union{
void *val;
uint64_t u64;
int64_t s64;
double d;
}v;//既能指向String对象,也能指向集合类型的对象(比如List+Hash+Set+Zset对象)
struct dictEntry *next;
}dictEntry;
typedef struct dictType{
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdate,const void *key);
...
}
typedef struct dictht{
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
}dictht;
typedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx;
unsigned long iterators;
}dict;
Ziplist&Listpack
Ziplist:
Ziplist压缩列表是一种紧凑编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,因此只会用于字段个数少,且字段值也较小的场景。压缩列表内存利用率极高的原因与其连续内存的特性是分不开的。
为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组
ziplist是一个经过特殊编码的双向链表、它不存储指向前一个链表节点prev和指向下一个链表节点的指针next而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,米换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面
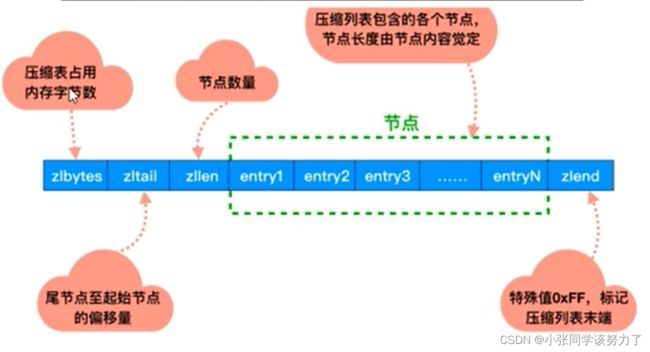
| 字段 | 长度 | 用途 |
|---|---|---|
| zlbytes | 4B | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配,或者计算zlend的位置时使用 |
| zltail | 4B | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节:通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址 |
| zllen | 2B | 记录了压缩列表包含的节点数量,当这个的值大于UINT16_MAX(65535)时,就需要遍历整个压缩列表才能知道真实 的节点数量 |
| entryX | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定 |
| zlend | 1B | 特殊值0xFF(十进制255),用于标记压缩列表的末端 |
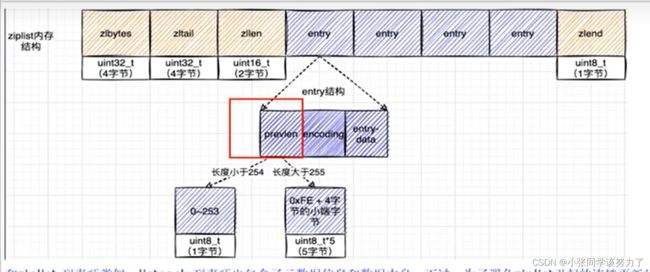
typedef struct zlentry{
unsigned int prevrawlensize;//上一个链表节点占用的长度
unsigned int prevrawlen;//上一个链表节点的长度数值所需要的字节数
unsigned int lensize;//存储当前链表节点长度数值需要的字节数
unsigned int len;//当前链表节点占用的长度
unsigned int headersize;//当前链表节点的头部大小,即非数据域的大小
unsigned char encoding;//编码方式
unsigned char *p//压缩链表以字符串的形式保存,该指针指向当前节点起始位置
}zlentry;
为什么entry这么设计?记录前一个节点的长度?
链表在内存中,一般是不连续的,遍历相对比较慢,而ziplist可以很好的解决这个问题
如果知道了当前的起始地址,因为entry是连续的,entry后一定是另一个entry,想知道下一个entry的地
址,只要将当前的起始地址加上当前entry总长度。如果还想遍历下一个entry,只要继续同样的操作。
如果想知道上一个entry,只需要减去上一个的总长度
明明有链表了,为什么出来一个压缩链表?
1.普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指
针占用的内存大,得不偿失。ziplist 是一个特殊的双向链表没有维护双向指针:previous、next;而是存
储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获得
高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的“时间换空
间”。
2.链表在内存中一般是不连续的,遍历相对比较慢而ziplist可以很好的解决这个问题,普通数组的遍历是
根据数组里存储的数据类型找到下一个元素的(例如int类型的数组访问下一个元素时解次只需要移动一个
sizeof(int)就行),但是ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能
直接sizeof(entry),所以ziplist只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个
节点或下一个节点。备注:sizeof实际上是获取了数据在内存中所占用的存储空间,以字节为单位来计
数。
3.头节点里有头节点里同时还有一个参数len,和string类型提到的 SDS类似,这里是用来记录链表长度
的。因此读取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是O(1)。
ziplist总结:
1.ziplist为了节省内存,采用了紧凑的连续存储。
2.ziplist是一个双向链表,可以在时间复杂度为O(1)下从头部、尾部进行 pop或push。
3.新增或更新元素可能会出现连锁更新现象(致命缺点导致被listpack替换)。
4.不能保存过多的元素,否则查询效率就会降低,数量小和内容小的情况下可以使用。
Listpack:
conf文件的配置:
hash-max-listpack-entries:使用压缩列表保存时哈希集合中的最大元素个数。
hash-max-listpack-value:使用压缩列表保存时哈希集合中单个元素的最大长度
明明有ziplist了,为什么出来一个listpack紧凑列表?
压缩列表里的每个节点中的prevlen属性都记录了「前一个节点的长度」,而且prevlen属性的空间大小
跟前一个节点长度值有关,比如:
如果前一个节点的长度小于254字节,那么prevlen 属性需要用1字节的空间来保存这个长度值;
如果前一个节点的长度大于等于254字节,那么prevlen属性需要用5字节的空间来保存这个长度值;
ziplist有连锁更新的问题:
压缩列表新增某个元素或修改某个元素时,如果空间不够,压缩列表占用的内存空间就需要重新分配。
而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更
新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
案例说明:压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患
1.现在假设一个压缩列表中有多个连续的、长度在250~253之间的节点。因为这些节点长度值小于254字
节,所以prevlen属性需要用1字节的空间来保存这个长度值,一切OK, o(n_n)0哈哈~
2.这时,如果将一个长度大于等于254字节的新节点加入到压缩列表的表头节点,即新节点将成为entry1
的前置节点,因为entry1节点的prevlen属性只有1个字节大小,无法保存新节点的长度、此时就需要对压
缩列表的空间重分配操作并将entry1节点的prevlen 属性从原来的1字节大小扩展为5字节大小。
3.连续更新问题。
entry1节点原本的长度在250~253之间,因为刚才的扩展空间,此时entry1节点的长度就大于等于254,
因此原本entry2节点保存entry1节点的prevlen属性也必须从1字节扩展至5字节大小。entry1节点影响
entry2节点,entry2节点影响entry3节点...直持续到结尾。这种在特殊情况下产生的连续多次空问扩展操
作就叫做「连锁更新」
listpack就是解决了ziplist连锁更新的问题
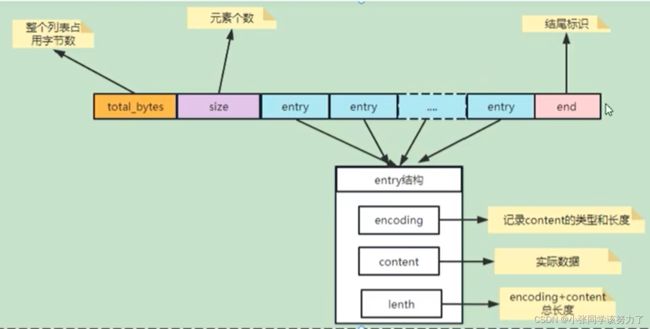
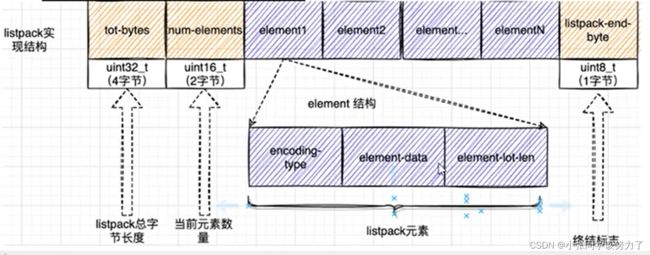
listpack的组成:
| 名称 | 说明 |
|---|---|
| Total Bytes | 为整个listpack的空间大小,占用4个字节,每个listpacl最多占用4294967295Bytes |
| num-elements | 为listpack中的元素个数,即Entry的个数占用2个字节 |
| element-1~element-N | 为每个具体的元素 |
| listpack-end-byte | 为listpack结束标志,占用1个字节,内容为0xFF |
List
redis6:quicklist+ziplist
list用quicklist(双向链表)来存储,quicklist存储一个双向链表,每个节点都是一个ziplist

redis7:quicklist+listpack
list用quicklist(双向链表)来存储,quicklist存储一个双向链表,每个节点都是一个listpack
config中的配置:
ziplist压缩配置:list-compress-depth 0
表示一个quicklist两端不被压缩的节点的个数。这里的节点是指quicklist双向链表的节点,而不是指ziplist
里面的数据项个数,参数list-compress-depth的取值含义如下:
0:是个特殊值,表示都不压缩。这是Redis的默认值
1:表示quicklist两端各有1个节点不压缩,中间的节点压缩
2:表示quicklist两端各有2个节点不压缩,中间的节点压缩
3:表示quicklist两端各有3个节点不压缩,中间的节点压缩
...
ziplist中entry配置:list-max-ziplist-size -2
当取正值的时候,表示按照数据项个数来限定每个quicklist节点上的ziplist长度。比如,当这个参数配置
成5的时候,表示每个quicklist节点的ziplist最多包含5个数据项。当取负值的时候,表示按照占用字节数
来限定每个quicklist节点上的ziplist长度。这时,它只能取-1到-5这5个值,每个值含义如下:
-5:每个quicklist节点上的ziplist大小不能超过64 Kb。(注: 1kb => 1024 bytes)
-4;每个quicklist节点上的ziplist大小不能超过32 Kb.
-3:每个quicklist节点上的ziplist大小不能超过16 Kb。
-2:每个quicklist节点上的ziplist大小不能超过8 Kb.(-2是Redis给出的默认值)
-1:每个quicklist节点上的ziplist大小不能超过4 Kb.
typedef struct quicklist{
quicklistNode *head;//指向双向列表的表头
quicklistNode *tail;//指向双向列表的表尾
unsigned long count;//所有的ziplist中一共存了多少个元素
unsigned long len; //双向链表的长度,node的数量
int fill:QL_FILE_BITS;//fill factor for individual nodes
unsigned int compress:QL_COMP_BITS;//压缩深度:0 不压缩
unsigned int bookmark_count:QL_BM_BITS;
quicklistBookmark bookmarks[];
}quicklist;
typedef struct quicklistNode{
struct quicklistNode *prev;//前一个节点
struct quicklistNode *next;//后一个节点
unsigned char *zl;//指向实际的ziplist
unsigned int sz;//当前的ziplist占用多少字节
unsigned int count:16;//当前ziplist中存储多少个元素,占16bit,最大65536个
unsigned int encoding:2;//是否采用了LZF压缩算法压缩节点,1:RAW 2:LZF
unsigned int container:2;
unsigned int recompress:1;
unsigned int attempted_compress:1;
unsigned int extra:10;
}quicklistNode;
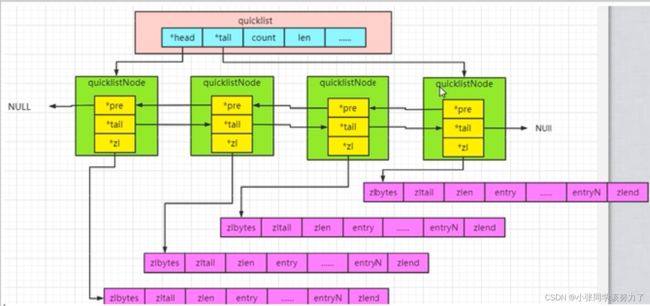
redis7就是listpack替代ziplist
Set和Zset
关于set的config配置
set-max-intset-entries 512//超过512个元素就会由intset变为hashtable(数组+链表)
ZSet的两种编码格式:
redis6:ziplist+skiplist
redis7:listpack+skiplist
关于zset的config配置
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
zset-max-listpack-entries 128
zset-max-listpack-value 64
当有序集合中包含的元素数量超过服务器属性server.zset_max_ziplist_entries 的值(默认值为128 ),或者有序集合中新添加元素的 member 的长度大于服务器属性server.zset_max_ziplist_value的值(默认值为64)时,redis会使用跳跃表作为有序集合的底层实现。
跳表
跳表:以空间换时间
由于链表,无法进行二分查找,因此借鉴数据库索引的思想,提取出链表中关键节点(索引),先在关键节点上查找,再进入下层链表查找,提取多层关键节点,就形成了跳表
可以实现二分查找的有序列表
总结来讲 跳表=链表+多级索引
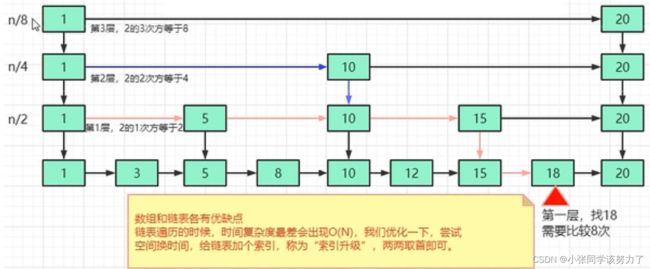
时间空间复杂度分析:
跳表的时间复杂度是O(logN)
n、n/2、n/4……2
n/2h-1=2
h=log(n)
跳表的空间复杂度是O(N)
1.首先原始链表长度为n
2.两两取首,每层索引的结点数:n/2,n/4,n/8…8,4,2每上升一级就减少一半,直到最后剩下2个节点
格外的空间为:n/2+n/4+n/8+…+8+4+2=n-2
所以跳表的空间复杂度为O(n)
优点:
跳表是一个最典型的空间换时间解决方案,而且只有在数据量较大的情况下才能体现出来优势。而且应该是读多写少的情况下才能使用,所以它的这用范围应该还是比较有限的
缺点:
维护成本相对要高,在单链表中,一旦定位好要插入的位置,插入结点的时间复杂度是很低的,就是O(1)
but
新增或者删除时需要把所有索引都更新一遍,为了保证原始链表中数据的有序性,我们需要先找到要动作的位置,这个查找操作就会比较耗时最后在新增和删除的过程中的更新,时间复杂度也是O(log n)
IO多路复用
多路复用要解决的问题?
并发多客户端连接,在多路复用之前最简单和典型的方案:同步阻塞网络IO模型。
这种模式的特点就是用一个进程来处理一个网络连接(一个用户请求)
优点:容易让人理解
缺点:性能差,每个用户请求来都得占用一个进程来处理
结论:进程在 Linux 上是一个开销不小的家伙,先不说创建,光是上下文切换一次就得几个微秒。所以
为了高效地对海量用户提供服务,必须要让一个进程能同时处理很多个tcp连接才征。现在假设一个进程
保持了10000条连接,那么如何发现哪条连接上有数据可读了、哪条连接可写了?
I/O:网络I/O
多路:多个客户端连接(连接就是套接字描述符,即socket或者channel),指的是多条TCP连接
复用:用一个进程来处理多条的连接,使用单进程就能够实现同时处理多个客户端的连接
Redis的IO多路复用:
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派
器将事件分发给事件处理器。
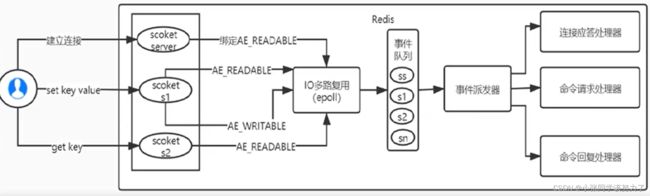
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以I/О操作在一般情况下往往不能直接返回,这会导致某一文件的I/O阻塞导致整个进程无法对其它客户提供服务,而I/O多路复用就是为了解决这个问题而出现。
所谓I/O多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。这种机制的使用需要select、poll 、epoll来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Redis服务采用Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:
1.多个套接字
2.IO多路复用程序
3.文件事件分派器
4.事件处理器
Unix网络编程中的五种IO模型:
Blocking IO -阳塞lO
NoneBlocking IO-非阻塞IO
IO multiplexing - IO多路复用
signal driven IO-信号驱动IO
asynchronous IO-异步lO
几个概念:
同步:调用者要一直等待调用结果的通知后才能进行后续的执行,现在就要,我可以等,等出结果为止
异步:指被调用方先返回应答让调用者先回去,然后再计算调用结果,计算完最终结果后再通知并返回
给调用方。异步调用要想获得结果一般通过回调
同步与异步:同步、异步的讨论对象是被调用者(服务提供者),重点在于获得调用结果的消息通知方式上
阻塞:调用方一直在等待而且别的事情什么都不做,当前进/线程会被挂起,啥都不干
非阻塞:调用在发出去后,调用方先去忙别的事情,不会阻塞当前进/线程,而会立即返回
阻塞、非阻塞:讨论对象是调用者(服务请求者),重点在于等消息时候的行为,调用者是否能干其它事
1.同步阻塞:服务员说快到你了,先别离开我后台看一眼马上通知你。客户在海底捞火锅前台干等着,啥
都不干。
2.同步非阻塞:服务员说快到你了,先别离开客户在海底捞灾银前台边刷抖音边等着叫号
3.异步阻塞:服务员说还要再等等,你先去逛逛,一会儿通知你。客户怕过号在海底捞火锅前台拿着排号
小票啥都不干,一首等着店员诵知
4.异步非阻塞:服务员说还要再等等,你先去逛逛,一会儿通知你拿着排号小票+刷着抖音,等着店员通知
BIO
BIO:当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。所以,BIO的特点就是在IO执行的两个阶段都被block 了。
缺点:
在阻塞式I/O模型中,应用程序在从调用recvfrom开始到它返回有数据报准备好这段时间
是阻塞的,recvfrom返回成功后,应用进程才能开始处理数据报。
思考:
每个线程分配一个连接,必然会产生多个,既然是多个socket连接必然需要放入进容器,纳入统一管理
NIO
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,NIO特点是用户进程需要不断的主动询问内核数据准备好了吗?一句话,用轮询替代阻塞!
在NIO模式中,一切都是非阻塞的:
accept()方法是非阻塞的,如果没有客户端连接,就返回无连接标识
read()方法是非阻塞的,如果read()方法读取不到数据就返回空闲中标识,如果读取到数据时只阻塞
read()方法读数据的时间
在NIO模式中,只有一个线程:
当一个客户端与服务端进行连接,这个socket就会加入到一个数组中,隔一段时间遍历一次,看这个
socket的read()方法能否读到数据,这样一个线程就能处理多个客户端的连接和读取了
优点:不会阻塞在内核的等待数据过程,每次发起的I/О请求可以立即返回,不用阻塞等待,实时性较好。
NIO成功的解决了BIO需要开启多线程的问题,NIO中一个线程就能解决多个socket,但是还存在2个问题。
缺点:
1.这个模型在客户端少的时候十分好用,但是客户端如果很多,比如有1万个客户端进行连接,那么每次
循环就要遍历1万个socket,如果一万个socket中只有10个socket有数据,也会遍历一万个socket,就会
做很多无用功,每次遍历遇到read返回-1时仍然是一次浪费资源的系统调用。
2.而且这个遍历过程是在用户态进行的,用户态判断socket是否有数据还是调用内核的read()方法实现
的,这就涉及到用户态和内核态的切换,每遍历一个就要切换一次,开销很大。
IO多路复用
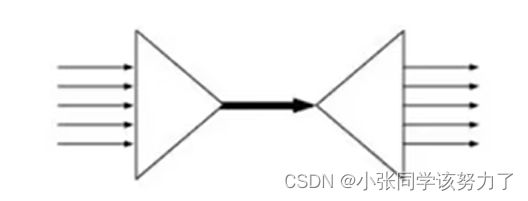
I/O multiplexing这里面的multiplexing指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流,目的是尽量多地提高服务器的吞吐能力。
I/O multiplexing就是我们说的select,poll, epoll,有些技术书籍也称这种I/O方式为event driven IO事件驱动IO。就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪〉,能够通知程序进行相应的读写操作。可以基于一个阻塞对象并同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程,每次new一个线程),这样可以大大节省系统资源。所以,I/O多路复用的特点是的过一种机制一个进程能同时等待多个文件描述符而这些文件描述符(套接字拙述符)其中的任意一个进入读就绪状态, select,poll,epoll等函数就可以返回。
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
Reactor模式:
Reactor模式,是指通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式。服务端
程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor模式也叫 Dispatcher模式。
即I/O多了复用统一监听事件,收到事件后分发(Dispatch给某进程),是编写高性能网络服务器的必备技
术。
Reactor模式有2个关键组成:
1)Reactor:Reactor在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对IO事件
做出反应。它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人;
2)Handlers:处理程序执行I/O事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际办理
人。Reactor通过调度适当的处理程序来响应I/O事件,处理程序执行非阻塞操作。
Select
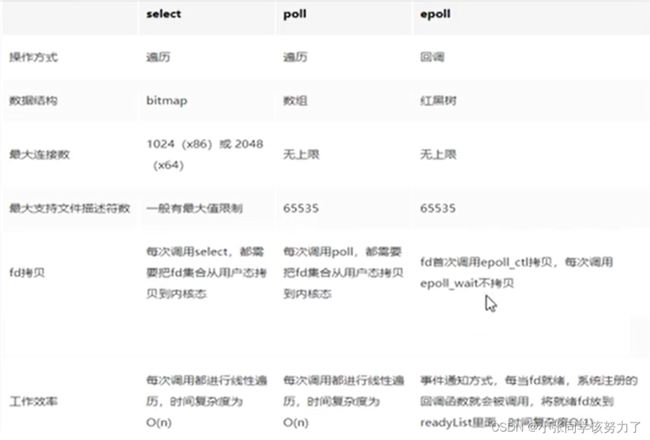
Select方法:
函数监视的文件描述符分3类,分别是readfds、writefds和exceptfds,将用户传入的数组拷贝到内核空间
调用后select函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有except)或超时(timeout指定等
待时间,如果立即返回设为null即可)、函数返回。
当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
select 其实就是把NIO中用户态要遍历的Fd数组(我们的每一个socket链接,安装进ArrayList里面的那个)
拷贝到了内核态,让内核态来遍历,因为用户态判断socket是否有数据还是要调用内核态的,所以拷贝
到内核态后,这样遍历判断的时候就不用一直用户态和内核态频繁切换了
select函数的执行流程:
1.select是一个阻塞函效,当没有数据时,会一直阻塞在select那一行。
2.当有数据时会将rset中对应的那一位置为1
3.select函数返回,不再阻塞
4.遍历文件描述符数组,判断哪个fd被置位了
5.读取数据,然后处理
代码:
sockfd = socket(AF_INET,SOCK_STREAM,0);
memset(&addr,0,sizeof (addr));
addr.sin_family = AF_INET;
addr.sin_port = htons (2000);
addr.sin_addr.s_addr = INADDR_ANY;
bind(sockfd, (struct sockaddr* )&addr ,sizeof(addr));
listen (sockfd,5);
for (i=0;i<5;i++)//模拟5个客户端连接
{
memset(&client,0,sizeof (client));
addrlen = sizeof(client);
fds[i] = accept(sockfd,(struct sockaddr* )&client,&addrlen);
if(fds[i] > max)
max = fds[i];//找到一个最大的文件描述符
}
while(1){
FD_ZERO(&rset);
for (i = 0; i< 5; i++ ) {
FD_SET(fds[i],&rset);//&rset是个bitmao.如果5个文件描述符分别是0,1,2,4,5,7,那么这个bitmap为01101101
}
puts( " round again");
//select()是一个系统调用,它会堵塞直到有数据发送到socket,select会把&rset相应的位置置位,但并不会返回哪个socket有数据
select(max+1,&rset,NULL,NULL,NULL);
for(i=0;i<5;i++) {
if (FD_ISSET(fds[i],&rset)){
memset(buffer ,0,MAXBUF);//用户态只要遍历&rset,看哪一位被置位了,不需要每次调用系统调用来判断了,效率有很大提升,遍历到被置位的文件描述符就进行读取
read( fds[i],buffer,MAXBUF);
puts(buffer);
}
}
}
select函数的缺点:
1.bitmap默认大小为1024,虽然可以调整但还是有限度的
2.rset每次循环都必须重新置位为0,不可重复使用
3.尽管将rset从用户态拷贝到内核态由内核态判断是否有数据,但是还是有拷贝的开销
4.当有数据时select就会返回,但是select函数并不知道哪个文件描述符有数据了,后面还需要再次对文
件描述符数组进行遍历。效率比较低
Poll
int poll(struct pollfd *fds,nfds_t nfds,int timeout);
struct pollfd{
int fd;//文件描述符
short events;//关系的事件,比如读事件或写事件
short revents;//如果该文件描述符有事件发生则置1
};
for (i=0; i<5;i++)//模拟5个客户端连接
{
memset(&client,0,sizeof (client));
addrlen = sizeof(client);
pollfds[i].fd = accept(sockfd,(struct sockaddr*)&client,&addrlen)
pollfds[i].events = POLLIN;//这5个socket只关系读事件
}
sleep(1);
while(1){
puts( "round again");
poll(pollfds,5,50000); //poll中传入pollfds数组,交给内核判断是否有事件发生,如果哪个发生事件则revents置1
for(i=0; i<5;i++){//遍历数组,找到哪个pollfd有事件发生
if (pollfds[i].revents & POLLIN){
pollfds[i].revents = 0;//找到后revents置0
memset(buffer ,0,MAXBUF);
read(pollfds[i].fd,buffer,MAXBUF);//读取数据
puts(buffer);
}
}
poll的执行流程:
1.将五个fd从用户态拷贝到内核态
2.poll为阻塞方法,执行poll方法,如果有数据会将fd对应的revents置为POLLIN
3. poll方法返回
4.循环遍历,查找哪个fd被置位为POLLIN了
5.将revents重置为0便于复用
6.对置位的fd进行读取和处理
解决的问题:
1.解决了bitmap大小限制
2.解决了rset不可重用的情况
后面由于二者原理相同,所以没能解决:
1.pollfds数组拷贝到了内核态,仍然有开销
2.poll并没有通知用户态哪一个socket有数据,仍然需要O(n)的遍历
epoll
int epoll_create(int size);//类似于make([]int,size),返回epfd
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event);
//表示op操作,用3个宏来表示;添加POLL_CTL_ADD,删除EPOLL_CTL_DEL,修改EPOll_CTL_MOD,三操作对fd的监听,epoll_event告诉内核要监听什么事
int epoll_wait(int epfd,struct epoll_event *events,int maxevents,int timeout);
//等待epfd上的io事件,最多返回maxevents个事件。参数events用来从内核得到事件的集合,maxevents告之内核这个events有多大
struct epoll_event{
__uint32_t events;
epoll_data_t data;
}
//events可以是以下几个宏的集合;
EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭)
EPOLLOUT:表示对应的文件描述符可以写
epoll是非阻塞的是非阻塞的!!!
epoll的执行流程:
1.当有数据的时候,会把相应的文件描述符“置位”,但是epool没有reevent标志位,所以并不是真正的置
位。这时候会把有数据的文件描述符放到队首。
2.epoll会返回有效据的文件描述符的个数
3.根据返回的个数读取前N个文件描述符即可
4.读取、处理
struct epoll_event events[5];
int epfd = epoll_create(10);//epoll create(在内核开辟一块内存空间,用来存放epoll中fd的数据结构
for (i=0;i<5;i++)//模拟5个客户端连接
{
static struct epoll_event ev;//epoll中fd的数据结构和poll中的差不多,只是没有了revents
memset(&client,0,sizeof (client));
addrlen = sizeof(client);
ev.data.fd = accept(sockfd,(struct sockaddr*)&client,&adev. events = EPOLLIN;
epoll_ctl(epfd,EPOLL_CTL_ADD,ev.data. fd,&ev) ; //epoll_ctl()把每
个socket的fd数据结构放到epoll_create()创建的内存空间中
while(1){
puts( "round again");
nfds = epoll_wait(epfd,events,5,10000); //epoll wait阻塞,只有当epoll create()中创建的内存空问中的fd有事件发生,才会把这些fd放入就绪链表中,返回就绪fd的个数
多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while循环里多次系统调用,变成了一次系统调用+内核层遍历这些文件描述符。
epoll是现在最先进的IO多路复用器,Redis、Nginx. linux中的Java NIO都使用的是epoll。这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。
1、一个socket的生命周期中只有一次从用户态拷贝到内核态的过程,开销小
2、使用event事件通知机制,每次socket中有数据会主动通知内核,并加入到就绪链表中,不需要遍历
所有的socket
在多路复用IO模型中,会有一个内核线程不断地去轮询多个socket的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。多路T/O复用模型是利用select、poll、 epoll可以同时监察多个流的I/O事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/О事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。采用多路I/О复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络I/O的时间消耗),且Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈