【Python】爬虫数据提取
目录
一、xpath提取数据
二、爬虫爬取图片资源
三、爬虫爬取视频资源
四、FLV文件转码为MP4文件
一、xpath提取数据
cook book
David Beazley
2022
53.20
The Lord of the Rings
J.R.R.托尔金
2005
29.99
Learning XML
Erik T. Ray
2013
40.05
xpath(XML Path Language)是在HTML\XML中查找信息的语句,可在HTML\XML文档中对元素和属性进行遍历
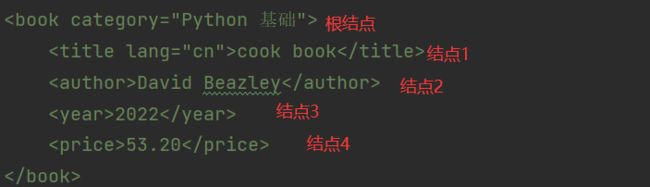
在根结点下面的节点是并列的,如一个树结构,我们也可以像访问文件一样来获得这个元素
xpath插件的安装:
- 自备梯子(能直接找到国内的.crx插件也可以不挂梯子)
- google浏览器搜索xpath_helper,进入谷歌应用商店下载得到一个.crx后缀的文件
- 打开浏览器的设置,找到拓展(拓展程序),进入开发者模式
- 直接下载得到的.crx文件用鼠标拖入浏览器,选择安装拓展
- 点击浏览器右上角拓展程序图标,可将xpath插件锁定
 点击xpath图标,出现这个黑框代表xpath插件安装成功
点击xpath图标,出现这个黑框代表xpath插件安装成功
xpath节点选取:
- nodename :选中该元素
- / :元素间的层级过度
- // :匹配选择,可省略中间节点而不考虑位置
- @ :选取属性
- text() :选取文本
lxml模块:
lxml模块是Python的第三方库,配合path,利用etree.HTML,将获取的网页字符串转化成Element对象,Element对象通过xpath的方法调用,以列表形式返回数据,再进行数据提取
import requests
from lxml import etree
text = """
cook book
David Beazley
2022
53.20
The Lord of the Rings
J.R.R.托尔金
2005
29.99
Learning XML
Erik T. Ray
2013
40.05
"""
html = etree.HTML(text)
print(type(html)) #
html_str = etree.tostring(html).decode()
print(type(html_str)) #
# 获取书名
book_name = html.xpath("/html/body/bookstore/book/title/text()") # 绝对路径
print(book_name) # ['cook book', 'The Lord of the Rings', 'Learning XML']
book_name = html.xpath("//title/text()")
print(book_name) # ['cook book', 'The Lord of the Rings', 'Learning XML']
# 数据提取列表元素
for i in book_name:
print(i, end="\t")
# cook book The Lord of the Rings Learning XML
# 获取作者
book_author = html.xpath("//author/text()")
print("\n", book_author) # ['David Beazley', 'J.R.R.托尔金', 'Erik T. Ray']
# 获取参数
category = html.xpath("//book/@category")
print(category) # ['Python 基础', 'story book', 'WEB']
lang = html.xpath("//book/title/@lang")
print(lang) # ['cn', 'en', 'en']
book = html.xpath("//book")
for i in book:
category = i.xpath("@category")[0]
book_info = dict()
book_info[category] = dict()
book_info[category]['name'] = i.xpath("title/text()")[0]
book_info[category]['author'] = i.xpath("author/text()")[0]
book_info[category]['year'] = i.xpath("year/text()")[0]
book_info[category]['price'] = i.xpath("price/text()")[0]
print(book_info)
"""
{'Python 基础': {'name': 'cook book', 'author': 'David Beazley', 'year': '2022', 'price': '53.20'}}
{'story book': {'name': 'The Lord of the Rings', 'author': 'J.R.R.托尔金', 'year': '2005', 'price': '29.99'}}
{'WEB': {'name': 'Learning XML', 'author': 'Erik T. Ray', 'year': '2013', 'price': '40.05'}}
""" 二、爬虫爬取图片资源
注:本代码爬取的图片皆无任何商业目的,仅供爬虫技术学习使用
示例:王者荣耀全英雄皮肤图片
import requests
from lxml import etree
import re
url = "https://pvp.qq.com/web201605/herolist.shtml"
response = requests.get(url)
response.encoding = "gbk"
html = response.text
# print(html)
html = etree.HTML(html)
# li_list = html.xpath("/html/body/div[3]/div/div/div[2]/div[2]/ul")
li_list = html.xpath('//ul[@class="herolist clearfix"]/li/a')
# xpath_helper拿到的xpath是已经被前端渲染过了的,不一定可用
# 如果xpath拿到的xpath不能直接用,就通过标签和属性手动选择数据
print(len(li_list)) # 93,英雄数量
for i in li_list:
href = i.xpath('./@href')[0]
name = i.xpath('./img/@alt')[0]
# print(href, name)
pattern = r'herodetail/(\d*)\.shtml'
id = re.search(pattern, href).group(1)
# print(name, id)
cnt = 1
while True:
try:
url = f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{cnt}.jpg"
resp = requests.get(url)
if resp.status_code != 200:
break
with open(f"./skins/{name}{cnt}.jpg", "wb") as f:
f.write(resp.content)
cnt += 1
except:
print(Exception)
break三、爬虫爬取视频资源
注:本代码爬取的视频无任何商业目的,仅供爬虫技术学习使用
示例:B站李知恩视频
1. 对网页发送网络请求
import requests
from lxml import etree
url = "https://search.bilibili.com/all?" \
"vt=16780856&keyword=李知恩&from_source=webtop_search&spm_id_from=333.1007&search_source=5"
response = requests.get(url)
print(response.text)
观察响应结果,请求发送成功,但是并未拿到想要的前端代码, 提示需要验证码(登录)
登录信息在请求头里面,我们要获取请求头信息
2. 获取视频链接
import requests
from lxml import etree
url = "https://search.bilibili.com/all?" \
"vt=16780856&keyword=李知恩&from_source=webtop_search&spm_id_from=333.1007&search_source=5"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'referer': 'https://search.bilibili.com/all?keyword=%E6%9D%8E%E7%9F%A5%E6%81%A9&from_source=webtop_search&spm_id_from=333.1007&search_source=5',
'cookie': "buvid3=EE26C87B-4D71-DDB1-E3EF-7C231D141FDE66254infoc; b_nut=1676099166; i-wanna-go-back=-1; _uuid=EEA6D79B-8E44-283C-4B1A-F63391023FC41071505infoc; buvid4=8BD6A57D-1756-0D2F-2D58-824CE069B0CF82025-023021115-3r0csnyFmYTJnqj7nA8pAw%3D%3D; DedeUserID=703170552; DedeUserID__ckMd5=921efa783160cc40; rpdid=|(YumR|Yk)|0J'uY~Y|mmklY; b_ut=5; nostalgia_conf=-1; header_theme_version=CLOSE; buvid_fp_plain=undefined; hit-dyn-v2=1; CURRENT_BLACKGAP=0; CURRENT_FNVAL=4048; CURRENT_QUALITY=116; LIVE_BUVID=AUTO5716781015889927; hit-new-style-dyn=1; CURRENT_PID=114c35b0-cd23-11ed-a99d-39a1565dc8a4; fingerprint=07652cefeee9b3af116a4e8892842b91; home_feed_column=5; FEED_LIVE_VERSION=V8; SESSDATA=4afb5a37%2C1696835970%2Cf0b52%2A42; bili_jct=00e8099da712cb9a9738ad46d90f6d21; sid=8tpyjca9; bp_video_offset_703170552=783637244587016200; is-2022-channel=1; buvid_fp=07652cefeee9b3af116a4e8892842b91; PVID=2; innersign=1; b_lsid=326DE875_18776328C0A"
}
response = requests.get(url, headers=header)
# print(response.text)
html = etree.HTML(response.text)
div_list = html.xpath('//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div/div[1]/div/div')
print(len(div_list))
for i in div_list:
i_url = i.xpath('./div/div[2]/a/@href')[0]
i_url = "https:" + i_url
print(i_url)3. 下载第三方包you-get
pip install you-get4. 用操作系统调用you-get包下载视频资源
import requests
from lxml import etree
import sys
import os
from you_get import common as you_get
import time
import ffmpy
url = "https://search.bilibili.com/all?keyword=%E6%9D%8E%E7%9F%A5%E6%81%A9&from_source=webtop_search&spm_id_from=333.1007&search_source=5"
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
'referer': 'https://search.bilibili.com/all?keyword=%E6%9D%8E%E7%9F%A5%E6%81%A9&from_source=webtop_search&spm_id_from=333.1007&search_source=5',
'cookie': "buvid3=EE26C87B-4D71-DDB1-E3EF-7C231D141FDE66254infoc; b_nut=1676099166; i-wanna-go-back=-1; _uuid=EEA6D79B-8E44-283C-4B1A-F63391023FC41071505infoc; buvid4=8BD6A57D-1756-0D2F-2D58-824CE069B0CF82025-023021115-3r0csnyFmYTJnqj7nA8pAw%3D%3D; DedeUserID=703170552; DedeUserID__ckMd5=921efa783160cc40; rpdid=|(YumR|Yk)|0J'uY~Y|mmklY; b_ut=5; nostalgia_conf=-1; header_theme_version=CLOSE; buvid_fp_plain=undefined; hit-dyn-v2=1; CURRENT_BLACKGAP=0; CURRENT_FNVAL=4048; CURRENT_QUALITY=116; LIVE_BUVID=AUTO5716781015889927; hit-new-style-dyn=1; CURRENT_PID=114c35b0-cd23-11ed-a99d-39a1565dc8a4; fingerprint=07652cefeee9b3af116a4e8892842b91; home_feed_column=5; FEED_LIVE_VERSION=V8; SESSDATA=4afb5a37%2C1696835970%2Cf0b52%2A42; bili_jct=00e8099da712cb9a9738ad46d90f6d21; sid=8tpyjca9; bp_video_offset_703170552=783637244587016200; is-2022-channel=1; buvid_fp=07652cefeee9b3af116a4e8892842b91; PVID=2; b_lsid=D3D108210E_1877853C1F0; innersign=0"
}
response = requests.get(url, headers=header)
# print(response.text)
html = etree.HTML(response.text)
div_list = html.xpath('//*[@id="i_cecream"]/div/div[2]/div[2]/div/div/div/div[1]/div/div')
print(len(div_list))
path = "iu_video/"
for i in div_list[:5]:
v_url = i.xpath('.//a/@href')[0]
v_url = "https:" + v_url
# print(v_url)
# v_title = i.xpath('./div/div[2]/a/div/div[1]/picture/img/@alt')
v_title = (i.xpath('.//a/div/div[1]/picture//@alt')[0])
print(v_url, v_title)
try:
# sys.argv = ['you-get', '-o', path, v_url]
# you_get.main()
os.system(f'you-get -o {path} {v_url}')
print(v_url, "下载成功")
except:
print(Exception)
print(v_url, v_title, "下载失败")
else:
time.sleep(2)爬取到的资源包括XML类型文件和FLV类型文件,XML类型文件是弹幕文件,FLY类型文件是视频文件,特定播放器可以直接播放,我们也可以将其转换为mp4文件
四、FLV文件转码为MP4文件
安装ffmpy资源包,找到ffmgep.exe将视频文件转码为mp4文件
pip install ffmpyimport ffmpy
import os
folder_path = "./iu_video/"
for filename in os.listdir(folder_path):
try:
if ".flv" in filename:
filename = folder_path + filename
sink_file = filename[:-3] + "mp4"
ff = ffmpy.FFmpeg(
executable="C:\\Program Files (x86)\\Common Files\DVDVideoSoft\\lib\\ffmpeg.exe",
inputs={filename: None},
outputs={sink_file: None}
)
ff.run()
print(filename, "转码成功")
except:
print(Exception)
print(filename, "转码失败")