【飞桨PaddleSpeech语音技术课程】— 语音识别-Transformer
使用 Transformer 进行语音识别
0. 视频理解与字幕
# 下载demo视频
!test -f work/source/subtitle_demo1.mp4 || wget -c https://paddlespeech.bj.bcebos.com/demos/asr_demos/subtitle_demo1.mp4 -P work/source/
import IPython.display as dp
from IPython.display import HTML
html_str = '''
'''.format("work/source/subtitle_demo1.mp4 ")
dp.display(HTML(html_str))
print ("ASR结果为:当我说我可以把三十年的经验变成一个准确的算法他们说不可能当我说我们十个人就能实现对十九个城市变电站七乘二十四小时的实时监管他们说不可能")
Demo实现:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/automatic_video_subtitiles/
1. 前言
1.1 背景知识
语音识别(Automatic Speech Recognition, ASR) 是一项从一段音频中提取出语言文字内容的任务。
目前该技术已经广泛应用于我们的工作和生活当中,包括生活中使用手机的语音转写,工作上使用的会议记录等等。
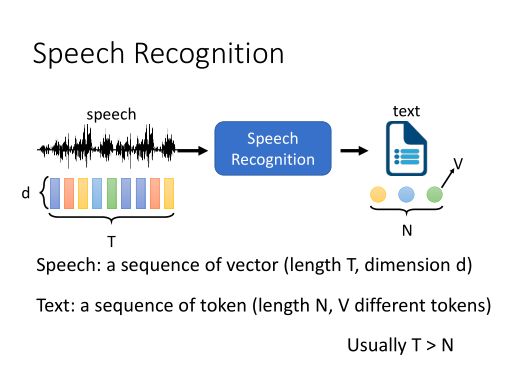
(出处:DLHLP 李宏毅 语音识别课程PPT)
1.2 发展历史
- 早期,生成模型流行阶段:GMM-HMM (上世纪90年代)
- 深度学习爆发初期: DNN,CTC[1] (2006)
- RNN 流行,Attention 提出初期: RNN-T[2](2013), DeepSpeech[3] (2014), DeepSpeech2 [4] (2016), LAS[5](2016)
- Attetion is all you need 提出开始[6]: Transformer[6](2017),Transformer-transducer[7](2020) Conformer[8] (2020)
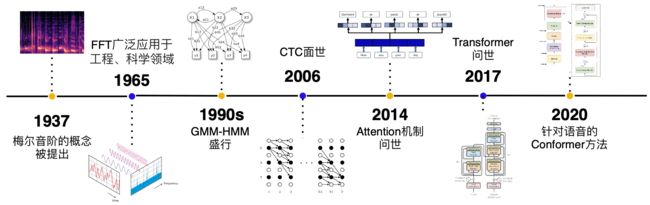
目前 Transformer 和 Conformer 是语音识别领域的主流模型,因此本教程采用了 Transformer 作为讲解的主要内容,并在课后作业中步骤了 Conformer 的相关练习。
2. 实战:使用Transformer进行语音识别的流程
CTC 的输出之间相互独立 P ( Y ∣ X ) P(Y \mid X) P(Y∣X),每一帧利用上下文的信息的能力不足。
而 seq2seq(Transformer,Conformer) 的模型采用自回归的解码方式 P ( Y n ∣ X , Y < n ) P(Y_n \mid X, Y_{
对于Transformer模型,它的Encoder可以有效对语音特征的上下文进行建模。而它的Decoder具有语言模型的能力,能够将语言模型融合进整个模型中,是真正意义上的端到端模型。

下面简单介绍下 Transformer 语音识别模型,其主要分为 2 个部分:
- Encoder:输入语音特征,产生高层特征编码。
- Decoder:Decoder 利用 Encoder 输出的特征,前一时刻的输出和状态,解码得到预测结果。
2.1 准备工作
2.1.1 安装 paddlespeech
!pip install paddlespeech==1.2.0
2.1.2 准备工作目录
!mkdir -p ./work/workspace_asr
%cd ./work/workspace_asr
2.1.3 获取预训练模型和音频文件
# 获取模型
!test -f transformer.model.tar.gz || wget -nc https://paddlespeech.bj.bcebos.com/s2t/aishell/asr1/transformer.model.tar.gz
!tar xzvf transformer.model.tar.gz
# 获取用于预测的音频文件
!test -f ./data/demo_01_03.wav || wget -nc https://paddlespeech.bj.bcebos.com/datasets/single_wav/zh/demo_01_03.wav -P ./data/
import IPython
IPython.display.Audio('./data/demo_01_03.wav')
# 快速体验识别结果
!paddlespeech asr --input ./data/demo_01_03.wav
2.1.4 导入python包
import paddle
import soundfile
import warnings
warnings.filterwarnings('ignore')
from yacs.config import CfgNode
from paddlespeech.audio.transform.spectrogram import LogMelSpectrogramKaldi
from paddlespeech.audio.transform.cmvn import GlobalCMVN
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
from paddlespeech.s2t.models.u2 import U2Model
from matplotlib import pyplot as plt
%matplotlib inline
2.1.5 设置预训练模型的路径
checkpoint_path = "./exp/transformer/checkpoints/avg_20.pdparams"
audio_file = "data/demo_01_03.wav"
# 读取 conf 文件并结构化
transformer_config = CfgNode(new_allowed=True)
transformer_config.merge_from_file("conf/transformer.yaml")
transformer_config.decoding.decoding_method = "attention"
print(transformer_config)
2.2 获取特征
2.2.1 音频特征 logfbank
2.2.1.1 语音特征提取整体流程图
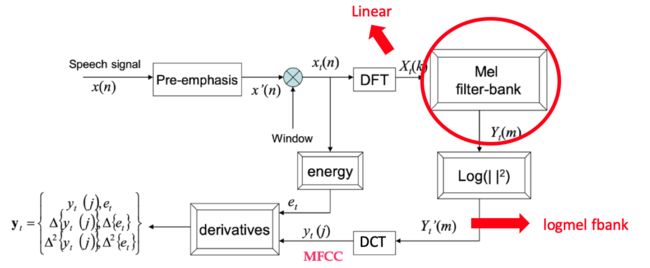
由"莊永松、柯上優 DLHLP - HW1 End-to-end Speech Recognition PPT" 修改得
2.2.1.2 logfbank 提取过程简化图
logfbank 特征提取大致可以分为 3 个步骤:
-
语音时域信号经过预加重(信号高频分量补偿),然后进行分帧。
-
每一帧数据加窗后经过离散傅立叶变换(DFT)得到频谱图。
-
将频谱图的特征经过 Mel 滤波器得到 logmel fbank 特征。
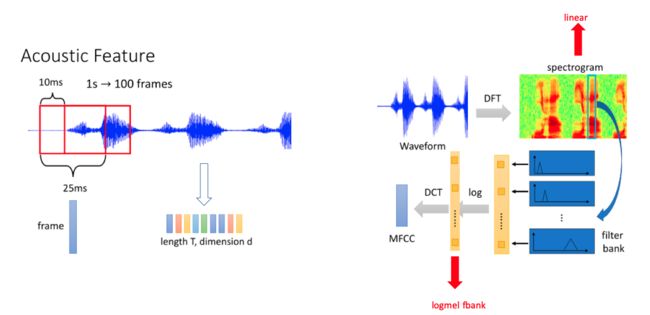
由"DLHLP 李宏毅 语音识别课程 PPT" 修改得
2.2.1.3 CMVN 计算过程
对于所有获取的特征,模型在使用前会使用 CMVN 的方式进行归一化。

通常通信的信道会有一些固定的噪声,比如麦克风的频域响应可能不是均匀的。这些信道的噪声的效果一般是对于频域的信号做一个乘法(放大或者缩小某些频率的信号),对应到时域就是信号的卷积。
信道的频率响应等于观察log系数的平均值,因此对于每个信号,我们减去它就可以得到原始信号的log系数。
2.2.2 构建音频特征提取对象
# 构建 logmel 特征
logmel_kaldi= LogMelSpectrogramKaldi(
fs= 16000,
n_mels= 80,
n_shift= 160,
win_length= 400,
dither= True)
# 特征减均值除以方差
cmvn = GlobalCMVN(
cmvn_path="data/mean_std.json"
)
2.2.3 提取音频的特征
array, _ = soundfile.read(audio_file, dtype="int16")
array = logmel_kaldi(array, train=False)
audio_feature_i = cmvn(array)
audio_len = audio_feature_i.shape[0]
audio_len = paddle.to_tensor(audio_len)
audio_feature = paddle.to_tensor(audio_feature_i, dtype='float32')
# (B, T, D)
audio_feature = paddle.unsqueeze(audio_feature, axis=0)
print (audio_feature.shape)
plt.figure()
plt.imshow(audio_feature_i.T, origin='lower')
plt.show()
2.3 使用模型获得结果
2.3.1 Transofomer 语音识别模型的结构
Transformer 模型主要由 2 个部分组成,包括 Transformer Encoder 和 Transformer Decoder。

2.3.2 Transformer Encoder
Transformer encoder 主要是对音频的原始特征(这里原始特征使用的是 80 维 logfbank)进行特征编码,其输入是 logfbank,输出是特征编码。包含:
- 位置编码(position encoding)
- 降采样模块(subsampling embedding): 由2层降采样的 CNN 构成。
- Transformer Encoder Layer :
- self-attention: 主要特点是Q(query), K(key)和V(value)都是用了相同的值
- Feed forward Layer: 由两层全连接层构建,其特点是保持了输入和输出的特征维度是一致的。
2.3.2.1 Self-Attention


其主要步骤可以分为三步:
-
Q和K的向量通过求内积的方式计算相似度,经过 scale 和 softmax 后,获得每个Q和所有K之间的 score。 -
将每个
Q和所有K之间的 score 和V进行相乘,再将相乘后的结果求和,得到 self-attetion 的输出向量。 -
使用多个 Attetion 模块均进行第一步和第二步,并将最后的输出向量进行合并,得到最终 Multi-Head Self-Attention 的输出。
2.3.3 Transformer Decoder
Transformer 的 Decoder 用于获取最后的输出结果。其结构和 Encoder 有一定的相似性,也具有 Attention 模块和 Feed forward layer。
主要的不同点有 2 个:
- Decoder 采用的是一种自回归的方式进行解码。
- Decoder 在 Multi-head self-attention 和 Feed forward layer 模块之间增加了一层 Multi-head cross-attention 层用于获取 Encoder 得到的特征编码。
2.3.3.1 Masked Multi-head Self-Attention
细心的同学可能发现了,Decoder 的一个 Multi-head self-attention 前面有一个 mask 。增加了这个 mask 的原因在于进行 Decoder 训练的时候,Decoder 的输入是一句完整的句子,而不是像预测这样一步步输入句子的前缀。
为了模拟预测的过程,Decoder 训练的时候需要用 mask 遮住句子。 例如 T=1 时,就要 mask 输入中除第一个字符以外其他的字符,T=2 的时候则需要 mask 除前两个字符以外的其余字符。
2.3.3.2 Cross Attention
Decoder 在每一步的解码过程中,都会利用 Encoder 的输出的特征编码进行 cross-attention。
其中Decoder会将自回结果的编码作为 Attention 中的 Q ,而 Encoder 输出的特征编码作为 K 和 V 来完成 attetion 计算,从而利用 Encoder 提取的音频信息。
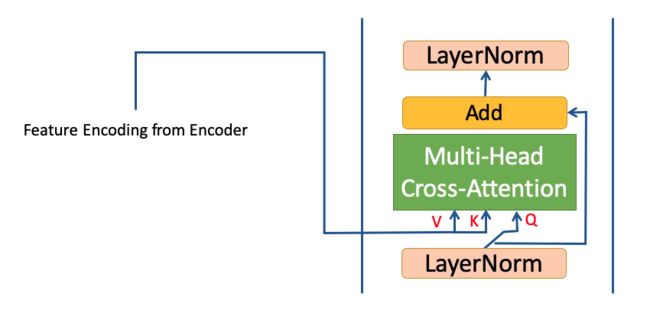
2.3.3.3 Decoder的自回归解码
其采用了一种自回归的结构,即 Decoder 的上一个时间点的输出会作为下一个时间点的输入。 另外,计算的过程中,Decoder 会利用 Encoder 的输出信息。
- greedy
如果使用贪心(greedy)的方式,Decoder 的解码过程如下:

- beam search
使用 greedy 模式解码比较简单,但是很有可能会在解码过程中丢失整体上效果更好的解码结果。 因此我们实际使用的是 beam search 方式的解码,beam search 模式下的 decoder 的解码过程如下:

2.3.4 模型训练
模型训练同时使用了 CTC 损失和 cross entropy 交叉熵损失进行损失函数的计算。
其中 Encoder 输出的特征直接进入 CTC Decoder 得到 CTC 损失。
而 Decoder 的输出使用 cross entropy 损失。

(由"莊永松、柯上優 DLHLP - HW1 End-to-end Speech Recognition PPT" 修改得)
2.3.5 构建Transformer模型
model_conf = transformer_config.model
# input_dim 存储的是特征的纬度
model_conf.input_dim = 80
# output_dim 存储的字表的长度
model_conf.output_dim = 4233
print ("model_conf", model_conf)
model = U2Model.from_config(model_conf)
2.3.6 加载预训练的模型
model_dict = paddle.load(checkpoint_path)
model.set_state_dict(model_dict)
2.3.7 进行预测
decoding_config = transformer_config.decoding
text_feature = TextFeaturizer(unit_type='char',
vocab=transformer_config.collator.vocab_filepath)
result_transcripts = model.decode(
audio_feature,
audio_len,
text_feature=text_feature,
decoding_method=decoding_config.decoding_method,
beam_size=decoding_config.beam_size,
ctc_weight=decoding_config.ctc_weight,
decoding_chunk_size=decoding_config.decoding_chunk_size,
num_decoding_left_chunks=decoding_config.num_decoding_left_chunks,
simulate_streaming=decoding_config.simulate_streaming)
print ("预测结果对应的token id为:")
print (result_transcripts[1][0])
print ("预测结果为:")
print (result_transcripts[0][0])
3. 作业
-
使用开发模式安装 PaddleSpeech
环境要求:docker, Ubuntu 16.04,root user。
参考安装方法:使用Docker安装paddlespeech -
跑通 example/aishell/asr1 中的 conformer 模型,完成训练和预测。
-
按照 example 的格式使用自己的数据集训练 ASR 模型。
4. 关注 PaddleSpeech
5. 参考文献
[1] Graves A, Fernández S, Gomez F, et al. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks[C]//Proceedings of the 23rd international conference on Machine learning. 2006: 369-376.
[2] Graves A, Mohamed A, Hinton G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE international conference on acoustics, speech and signal processing. Ieee, 2013: 6645-6649.
[3] Hannun A, Case C, Casper J, et al. Deep speech: Scaling up end-to-end speech recognition[J]. arXiv preprint arXiv:1412.5567, 2014.
[4] Amodei D, Ananthanarayanan S, Anubhai R, et al. Deep speech 2: End-to-end speech recognition in english and mandarin[C]//International conference on machine learning. PMLR, 2016: 173-182.
[5] Chan W, Jaitly N, Le Q, et al. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition[C]//2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016: 4960-4964.
[6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[7] Zhang Q, Lu H, Sak H, et al. Transformer transducer: A streamable speech recognition model with transformer encoders and rnn-t loss[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 7829-7833.
[8] Gulati A, Qin J, Chiu C C, et al. Conformer: Convolution-augmented transformer for speech recognition[J]. arXiv preprint arXiv:2005.08100, 2020.