Java并发编程synchronized详解
一、关于临界区、临界资源、竞态条件和解决方法
首先看如下代码,thread1对变量i++做500次运算,thread2对i--做500次运算,但是最终的结果却可能为是正数,负数,0不一样的结果。
package com.spj.synch;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class Synch1 {
//临界资源
private static int i=0;
//临界区
public static void increase(){
i++;
}
//临界区
public static void decrease(){
i--;
}
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
for (int j = 0; j < 500; j++) {
increase();
}
}, "Thread1");
Thread thread2 = new Thread(() -> {
for (int j = 0; j < 500; j++) {
decrease();
}
}, "Thread2");
thread1.start();;
thread2.start();
thread1.join();
thread2.join();
log.info("{}", i);
}
}
在单线程情况下,上面的代码最终结果为0,但是多线程共享资源时就会出现问题。
临界区、临界资源、竞态条件:
在一个代码块中,如果存在多线程对共享资源的读写操作,那么这块代码就称为临界区,该资源称为临界资源。上面代码中i就是临界资源,对i加减操作的代码块就是临界区。threa1,thread2在临界区内执行,由于代码的执行序列不同而导致结果无法预测,这样就发生了所谓的竞态条件。
而解决这种线程安全的问题,就有两种解决方法:
一是阻塞式的,二是非阻塞式的,而Sychronized就是阻塞式的解决方法。
sychronized加锁方式有两种:一种是加在方法上:
public static synchronized void increase(){
i++;
}
public static synchronized void decrease(){
i--;
}另外一种是加在代码块中,被锁住的是对象:
private static String lock="";
public static void increase(){
synchronized(lock){
i++;
}
}
public static void decrease(){
synchronized(lock){
i--;
}
}将原来代码加上锁后就不会出现上面的线程安全问题,运行结果为0:

二、synchronized的实现
synchronized是JVM内置锁,它是基于monitor管程来实现的。Java中synchronized参考了管程MESA模型:

就是当有一个线程获取资源时,会加锁使其他线程不能获取资源,从而陷入阻塞等待状态,这些线程就放入阻塞等待队列里面,直到获取资源的线程释放资源,调用wait()/notify()方法才将其他线程唤醒,然后获取资源。
由于synchronized是基于monitor机制实现的,而monitor又是基于Object对象实现的,在Object类中定义了 wait(),notify(),notifyAll() 方法,这些方法的实现基于ObjectMonitor类实现,ObjectMonitor主要数据结构有_cxp(单向链表组成的栈结构),_waitSet队列(等待线程组成的双向循环链表结构),_EntryList队列(存放竞争锁失败的线程),_header 对象头等。该机制大致流程可如下:

线程竞争锁时,是将当前线程插入_cxq头部,释放锁时,如果_EntryList为空,则将_cxq栈中元素安装原有顺序插入_EntryList队列中,然后唤醒第一个线程(默认情况下),由此可知synchronized为不公平锁;而若_EntryList不为空则其内部线程直接获取锁。
synchronized中的锁状态有如下四种状态:
1.无锁(001):没有加锁的状态
2. 偏向锁(101):引入偏向锁的原因是有的情况下锁不存在多线程之间的竞争,引入偏向锁可以消除数据在无竞争的情况下进行的CAS锁重入的开销。JVM启动后会有一个默认的偏向锁延迟机制操作,就是启动4s后默认开启偏向锁模式。
3.轻量级锁(00):在某些情况下,存在轻微的竞争,但是竞争并不强烈的情况下,偏向锁不会立即升级为重量级锁,而是轻量级锁,该锁适用于存在线程交替执行但是并不激烈的场合。
4.重量级锁(10):当高并发线程间竞争激烈的场景下,偏向锁,轻量级锁或者是无所状态都会变为重量级锁,此时会生成一个monitor对象,从而转换到内核态。
那么synchronized中是如何记录锁状态的呢,这就涉及到对象在内存中的布局如下图:
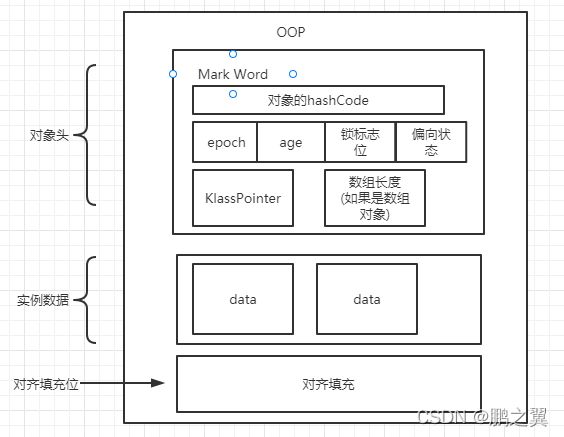
也就是说,对象在内存中可分为三部分:
对象头:存放对象的hashCode,分代年龄,锁状态标志,偏向锁ID等
实例数据:存放对象的属性信息
对齐填充位置:保证对象的起始地址是8的整数倍,不是的时候会自动填充,确保是8的整数倍。
对于对象在内存中占的内存大小:
1.Mark word占8字节
2.KlassPointer指针开启指针压缩后占4字节(默认),关闭的话则占8字节
3.如果是数组对象则数组长度占8字节
4.除了上面三点外,还要加上对象属性占的内存。
5.最终加起来的结果如果不是8的整数倍,则要对齐填充,确保使结果是8的整数倍。
比如下面的对象:
package com.spj.synch;
import org.openjdk.jol.info.ClassLayout;
public class spj {
public static void main(String[] args) {
System.out.println(ClassLayout.parseInstance(new A()).toPrintable());
}
public static class A {
private boolean flag;
}
}
该对象不是数组对象,故算上上面讲的1、2两点就占了12个字节,Boolean类型占1个字节一共是13个字节,此时不是8的整数倍,则对齐填充后在内存中占16个字节。
我们可以引入如下依赖来查看对象在内存中的布局
org.openjdk.jol
jol‐core
1.0
运行的结果如下

讲完了对象布局,接下来是锁的状态如何存放的。
synchronized中,锁的状态存放在Mark Word中,其中用101表示偏向锁,001表示无锁,00表示轻量级锁,10表示重量级锁。

那么,对于这四种锁的状态,他们之间的转换关系是怎样的呢?可如下图所示

最后,对于偏向锁撤销而言,会花费很多的开销,在高并发竞争激烈的情况下,开销大,因此JVM中对synchronized锁进行了优化 ,即偏向锁批量重偏向、批量撤销以及自旋优化,即使用epoch计数,每次偏向锁撤销时该计数器都会+1。
1.偏向锁批量重偏向:当有大量的线程竞争锁,假设这些锁分为左边和右边部分,开始的时候偏向锁偏向的是左边的线程,当计数器值达到20(默认值)时,JVM会认为偏向左边线程不是出了问题,会重新进行偏向右边的线程。
2.批量撤销:当epoch值达到40(默认值)时,JVM会直接将后面的偏向锁置为无锁状态,这样就减少了偏向锁撤销的开销。
3.自旋优化:在重量级锁竞争中,如果某线程竞争锁失败开始膨胀,则可以让它再次尝试去获取锁,再失败再尝试,这就是自旋的优化。假设这个过程中直接获得了锁,此时就可以直接避免阻塞。