简单快捷的人工智能相关小工具集合~

简单快捷的人工智能相关小工具集合~
目录
-
一,语料冲突检测工具
-
二,通过文本相似关系进行聚类
-
三,AI服务的线上埋点数据反馈
-
四,AI服务“堵塞守护”工具
-
五,AI服务压力测试工具
-
六,快速发送邮件
-
七,绘制多折线对比图
一,语料冲突检测工具
1, 什么是语料冲突?
- 在很多情况下,语料来源是多样的。尤其在NLP领域,可能引入样本内容相同,但是标签却不同的情况,如果存在这样的冲突语料将会导致模型很难收敛。
2, 快速使用:
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.6
pip install pyaitools==1.4.6 -i https://pypi.org/simple/
- 使用:
from pyaitools import detect
# 需要进行检测的训练数据路径
sample_path = "./train.csv"
# 检测完后需要写入的新文件路径
deconflict_sample_path = "./new_train.csv"
detect.corpus_conflict_detect(sample_path, deconflict_sample_path)
- 输出:
去重后Y标签数量: 3
去重后N标签数量: 3
去重后冲突样本数量:2
冲突样本已写入路径:./conflict_sample.txt
去冲突+去重复后Y标签数量: 1
去冲突+去重复后N标签数量: 3
- 参数:
- sample_path: 需要检测的训练数据路径,训练数据格式为csv,详细要求看下面介绍,无默认值,必须写
- deconflict_sample_path: 去除冲突后,新训练数据的路径, 无默认值,必须写
- sep: 需要检测的csv文件中使用什么作为分隔符, 默认为",“, 也可以选择”\t"
- label_list: 标签列表,该列表只有两个元素,默认为[“Y”, “N”],需要按照自己定义的标签进行修改
- choiceDeleteLabel: 当样本发生冲突时,选择删除哪一类标签后生成新数据,默认为"Y",需要按照自己定义的标签进行修改
- csample_path: 冲突数据写入的文件路径,默认为./conflict_sample.txt
- 训练数据格式要求:
- 训练数据例子:
sentence1,sentence2,relation
镀锌钢管水冲洗调和漆一道,镀锌钢管室内水dn50,N
镀锌钢管水冲洗调和漆一道,镀锌钢管国标螺纹连接水压试验,Y
镀锌钢管,镀锌钢管室内水dn50,N
镀锌钢管室内水dn50螺纹连接水压试验,镀锌钢管螺纹连接水压试验,N
镀锌钢管,镀锌钢管室内水dn50,Y
镀锌钢管水冲洗调和漆一道,镀锌钢管室内水dn50,Y
- 1,训练数据由内容列+标签列构成,其中内容列可以是任意多列(例子中是两列sent1和sent2)
- 2,标签列必须是最后一列,而且该检测只针对二分类,标签必须只有两种
- 3,内容列+标签列的列名随意
二,通过文本相似关系进行聚类
1, 背景
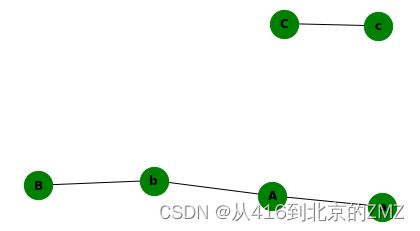
- 对于任意多段文本,已知他们之间所有相似关系(是否相似),希望输出具有相似关系的N个类,N由具体相似关系决定;假设我们只有三条文本A,B,C,其中只有A,B是相似的,那么输出则为[{A, B}, {C}]两个类,若不止A,B是相似的,A,C也是相似的,那么输出为[{A, B, C}]只有一个类。
2, 快速使用:
- 依赖:
pip install numpy==1.21.6
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.24
- 使用:
from pyaitools import similar
# 任意一组文本
input_list = ["A","B","C","A"]
# 与input_list具有1vs1相似关系的文本
# 如:"A"与"a"是相似的,"B"与"b"是相似的等等
similar_input_list = ["a","b","c","b"]
# 我们把它们做成集合-列表的形式[{"A", "a"}, {"B", "b"}, {"C", "c"}, ...]
list_set = list(zip(input_list, similar_input_list))
list_set = list(map(lambda x: set(x), list_set))
# connected_area_min_num: 输出连通区域(集合)中最少的文本数量,为了避免输出内容过多,可以通过该参数进行过滤,少于该长度的集合将不会输出,默认为0
c_list = similar.find_connected_area(list_set, connected_area_min_num=2)
print(c_list)
- 输出:
[{'a', 'A', 'b', 'B'}, {'c', 'C'}]
三,AI服务的线上埋点数据反馈
1, 背景:
- 当你的AI服务上线之后,真实用户开始请求他们来完成工作,我们希望整个使用流程对AI工程师是透明的,并且准确记录用户使用过程中的修改行为(因为用户进行修改大概率意味着你推荐的内容存在问题),这里的数据能够帮助我们发现真实用户使用过程中的问题,获取比线下指标更加具有代表性的线上指标,最终也会成为更有力的优化途径。
2, 该怎么做?
我们把这个流程总结为以下几步,为了最终能够复用我们的工具,我们还希望遵循一些统一的规则:
- Step1: 记录数据
- 通过埋点的方式,记录每天AI功能被触发时的相关数据
- 第一层为每天的时间(文件夹)
- 第二层为包括"功能代号"的csv文件(文件)
- csv文件包括触发时的具体内容,至少包括:
- 工程id(工程/任务的唯一标识)
- 分母数(假如用户修改一次,那么你需要用这个1除以谁,才能够计算修改率)
- 原始内容
- 推荐内容
- 修改内容

- Step2: 计算修改率
- 对于每一个功能的埋点表(一张表)来讲,我们通过埋点名解析对应功能的修改率
- 首先获取工程粒度的修改表:
- 聚合当前工程id
- 计算该工程总修改数:工程id出现的次数=用户对该工程的修改次数(每次埋点触发)
- 实际修改数 = 总修改数 - 误修改数
- 误修改数:是指虽然做了修改操作但实际上并不需要修改的情况出现的次数
- 计算分母数:分母数的计算不同项目之间可能存在差异,这里默认取最大值
- 当日实际修改率:当日所有工程实际修改数之和 / 当日所有分母数之和
- 实际修改率:每日实际修改数之和 / 每日分母数之和
- Step3: 获取修改数据进行badcase分析
3, 快速使用
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.10
- 使用:
- 在pyaitools/feedback/是示例文件夹,里面有一组数据可以用来实验!
from pyaitools import feedback
# 埋点数据文件夹
ori_path = "./feedback/"
# 埋点功能代号列表
buried_point_number_list = ["1104127", "1104128"]
# 理论上存在一些不可以为空的列,一旦他们的值为空,说明数据存在一定的问题
# 为了避免影响计算,在这里可以删除其为空的所在行内容
non_empty_column = ["projectid", "curdescription"]
# 埋点表中每一行代表一次修改,需要将这些修改聚合到各自的工程上,所以每条数据需要工程id进行辨识
projectID = "projectid"
# 修改率的分母列
xlbqnumber = "xlbqnumber"
# 内容间隔标志
content_interval_mark = "@"
# 原始内容相关的列
origin_content_columns = ["curdescription", "curspec"]
# 推荐内容相关的列
recommend_content_columns = ["matcheddescription", "matchedspec"]
# 修改内容相关的列
modify_content_columns = ["matchdescription", "matchspec"]
# 因为推荐内容不一定存在,埋点中可能缺失对应的列,需要指定内容标识
recommend_content_substitute = "error"
(
modify_content,
modification_rate,
pid_num,
total_number,
error_number,
max_num,
) = feedback.get_modification_rate_and_content(
ori_path,
buried_point_number_list,
projectID,
xlbqnumber,
origin_content_columns,
recommend_content_columns,
modify_content_columns,
non_empty_column,
content_interval_mark,
recommend_content_substitute,
)
print(f"修改内容:{modify_content}")
print(f"实际修改率:{modification_rate}")
print(f"触发工程数: {pid_num}")
print(f"总修改数:{total_number}")
print(f"误修改数:{error_number}")
print(f"分母数:{max_num}")
- 输出:
修改内容:[['混凝土垫层@商品砼C15;混凝土坍落度、石子粒径、运距、泵送高度、距离、泵送方式综合', '混凝土垫层@商品砼C15;混凝土坍落度、石子粒径、运距、泵送高度、距离、泵送方式综合', '混凝土垫层@商品砼C15;混凝土坍落度、石子粒径、运距、泵送高度、距离、泵送方式综合']]
修改率:0.0
触发工程数: 1
总修改数:1
误修改数:1
最大分母数:3248
- 参数:
- ori_path: 必须写,埋点数据文件夹
- buried_point_number_list: 必须写,埋点功能代号列表,程序将解析其中带有该代号的csv文件,一同计算修改率
- projectID: 必须写,工程/任务的唯一标识
- xlbqnumber: 必须写,分母数,本次修改率计算的分母
- origin_content_columns: 必须写,原始内容的相关列
- recommend_content_columns: 必须写,推荐内容的相关列
- modify_content_columns: 必须写,修改内容的相关列
- non_empty_column: 一定不可以为空值的列,若出现空值则删除改行,默认为[]
- content_interval_mark: 若内容为多个列时,文本使用该标识进行分割,默认为"@"
- recommend_content_substitute: 因为推荐内容不一定存在,埋点中可能缺失对应的列,需要指定内容标识,默认为"error"
四,AI服务“堵塞守护”工具
1, 背景
- 在生产中,AI功能往往作为一个独立的服务进行部署,作为pythoner,我们经常使用Flask + Gunicorn进行http服务部署,再使用supervisor等监控工具守护服务,不过很多监控工具都是进程守护,如果你的服务因为请求异常报错导致进程失败,那么supervisor等工具可以进行服务重启(进程重启),但是!一旦服务是因为过多的请求导致堵塞,用户端一样无法获得及时响应,此时进程守护模式的工具也无法重启服务,那么就需要“堵塞守护”工具!
2, 该怎么做?
-
在使用我们的守护工具前, 需要在你的服务里添加一个简单的侦测接口, 我们的工具将会每隔一段时间请求一次该接口,来判断你的整体服务是否异常(由于堵塞或者其他任何原因导致的)
-
不建议将业务接口作为侦测接口,因为业务接口往往请求的数据体更大,响应时间更长,侦测后有可能影响到正常用户使用该接口。
-
如果你正在使用flask服务,那么侦测接口可以写成下面的样子:
@app.route("/test/", methods=["GET"])
def test():
return "OK"
3, 快速使用
- 依赖:
pip install apscheduler==3.9.1
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.13
- 使用:
- 当你下载完这个工具包之后,你将得到shell命令:god
# --uri/-u 侦测的服务接口请求地址
# --comm/-c 侦测失败后服务重启的shell命令
# --sec/-s 侦测的时间间隔, 单位为秒, 默认为5s
# --timeout/-t 侦测的服务接口超时时间, 单位为秒, 默认为10s
# --res/-r 服务接口返回的结果(字符串), 默认为None
god -u "http://8.142.6.226/test/" -c "supvisorctl restart all"
- 关于“堵塞守护”工具的守护
- 如果你正在使用supervisor,可以使用它来守护该工具的进程
- 在你的supervisor中添加如下配置即可
[program:choke_monitor]
command=god -u "http://8.142.6.226/test/" -c "supvisorctl restart all"
- 输出:
2023-03-17 17:41:39
服务正常运行...
2023-03-17 17:41:44
服务正常运行...
- 参数:
- –uri/-u 侦测的服务接口请求地址
- –comm/-c 侦测失败后服务重启的shell命令
- –sec/-s 侦测的时间间隔, 单位为秒, 默认为5s
- –timeout/-t 侦测的服务接口超时时间, 单位为秒, 默认为10s
- –res/-r 服务接口返回的结果(字符串), 默认为None, 若存在,则会判断真实返回结果是否与其一致,如果不一致,也会执行服务重启命令
- 相关工具:
- superlance
五,AI服务压力测试工具
1,背景
- AI服务上线前都需要对服务进行压力测试,获取服务的RPS(QPS)和RT的指标,以免影响线上稳定。在python中我们一般使用Locust进行压测,但还是需要有一定的开发量,该工具对Locust进行封装,一行启动代码后,便可以监控压力测试效果。
2, 快速使用
- 依赖:
pip install locust==2.15.1
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.23
- 使用:
- 当你下载完这个工具包之后,你将得到shell命令:luc
# -c/--config: 压测服务的配置文件路径
luc -c stress_config.py
# -d/--dynamic: 是否使用动态请求体,若使用需要配置动态类
luc -c stress_config.py --dynamic
- stress_config.py(配置文件名字可以更改)
# 导入测试用例
from sample import sample
# 目标服务的请求地址
url = "http://8.142.6.226/lp/text_compare/"
# 请求体可以包含以下参数:(参考requests)method,url,headers,files,data,params,auth,cookies,hooks,json
request_body = {"method": "POST", "url": url, "json": sample}
# 设置最大用户数
max_user = 8
# 攀升时间
spawn_time = 10
# 总体时间
time_limit = 300
# 带宽报警阈值, 单位字节,默认为0(不报警)
bandwidth = 2000000
## 注意:不要修改url,request_body,time_limit,RequestBody,dynamic等这些名字,只需要更改值就可以了
- 如果你的请求体是动态的(一些参数是变化的,比如token),在配置中使用下面的类
from sample import sample
url = "http://8.142.6.226/lp/text_compare/"
import time
class RequestBody():
def __init__(self):
"""静态部分在初始化函数中设置即可"""
self.url = url
self.method = "POST"
self.json = sample
def dynamic(self):
"""动态部分通过函数表达"""
self.json["time"] = int(time.time())
return {"method": self.method, "url": self.url, "json": self.json}
- 输出:
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 0 0(0.00%) | 0 0 0 0 | 0.00 0.00
[2023-03-23 18:19:37,885] iZ8vbgeaa0ig6ufzdwoucpZ/INFO/locust.runners: Ramping to 10 users at a rate of 0.50 per second
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /lp/text_compare/ 3 0(0.00%) | 199 197 204 200 | 0.00 0.00
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 3 0(0.00%) | 199 197 204 200 | 0.00 0.00
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /lp/text_compare/ 9 0(0.00%) | 217 196 297 200 | 1.00 0.00
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 9 0(0.00%) | 217 196 297 200 | 1.00 0.00
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /lp/text_compare/ 18 0(0.00%) | 213 194 297 200 | 1.75 0.00
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 18 0(0.00%) | 213 194 297 200 | 1.75 0.00
Type Name # reqs # fails | Avg Min Max Med | req/s failures/s
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
POST /lp/text_compare/ 28 0(0.00%) | 239 194 326 200 | 2.33 0.00
--------|--------------------------------------------------------------------------|-------|-------------|-------|-------|-------|-------|--------|-----------
Aggregated 28 0(0.00%) | 239 194 326 200 | 2.33 0.00
六,快速发送邮件
1, 快速使用
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.21
- 使用:
- 当你下载完这个工具包之后,你将得到shell命令:sm
# -c/--config: 压测服务的配置文件路径
sm -c mail_config.py
- mail_config.py(配置文件名字可以更改)
# 使用哪个邮箱发送邮件,可以是163/qq等
sender_dict = {
'host': 'smtp.163.com',
'port': '465',
'user': '[email protected]',
'passwd': '********'
}
# 把邮件发送给谁,这是一个列表,可以添加多个邮箱
mailto_list = ['[email protected]']
# 邮件的标题,默认为【测试邮件】
title = '【测试邮件】'
# 邮件内容,默认为空值
content = '请查看附件中的数据'
# 邮件的附件路径,如果没有附件可以删掉此参数
attachment = ['./xxx.png', './xxx.txt']
# 内容格式,当你需要更丰富的格式时可以使用html,否则可以删掉此参数
content_type = 'html'
七,绘制多折线对比图
1, 快速使用
- 依赖:
pip install matplotlib==3.1.0
- 下载:
- 至少下载以下版本才有该功能!
pip install pyaitools==1.4.26
- 使用:
from pyaitools import plot
# 配置信息如下:
# Y轴的数据列表,嵌套列表形式,分别对应第N条线
y_axis_data = [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]]
leng = len(y_axis_data)
# X轴的数据列表,注意它并不是嵌套列表,因为多折现对比图要求其横坐标内容一致
x_axis_data = ["V1", "V2", "V3"]
# X轴名字
x_axis_name = ""
# Y轴名字
y_axis_name = "Price"
# x轴内容旋转角度,只有当其内容为字符串时才会旋转
x_axis_rotation = 30
# y轴内容旋转角度,只有当其内容为字符串时才会旋转
y_axis_rotation = 0
# 线宽
line_width = [2] * leng
# 线颜色
line_color = ["b", "r"]
# 线名字
line_name = ["line1", "line2"]
# 线透明度
line_alpha = [0.5] * leng
# 折点样式
marker = [""] * leng
# 线盒子的位置
legend_loc = "upper left"
# 是否使用表格线, 默认为True
is_grid = True
# 是否在折点处显示Y坐标, 默认为True
show_Y = True
# 是否在折点处显示X坐标, 默认为False
show_X = False
# 保存图片路径
save_path = "multiline.png"
plot.multiline_plot(
x_axis_data,
y_axis_data,
x_axis_name,
y_axis_name,
x_axis_rotation,
y_axis_rotation,
line_width,
line_color,
line_name,
line_alpha,
marker,
legend_loc,
save_path
)
- 输出(指定路径下):