基于via的课堂学生行为数据标注 与yolov7目标检测与自动标注系统
目录
- 0 相关链接
- 1. 总体功能描述
- 2.软件安装说明
-
- 2.1. 环境搭建
- 2.2. 激活环境
- 2.3. 退出环境
- 2.4. 删除环境
- 2.5. 安装opencv
- 3.标注数据处理
-
- 3.1. 收集
- 3.2.via对标注举手
- 3.3. via 举手标注转化yolo格式
- 3.4. via动作标注扩展
- 3.5. via 举手看书写字标注转化yolo格式
- 4. 标注数据检查与可视化
-
- 4.1. 检查via框与yolo框是否一致
- 4.2. 检查小点
- 4.3. 可视化数据
- 5. yolov7 训练与测试
-
- 5.1. GPU平台搭建yolov7
- 5.2. yolov7训练
- 5.3. yolov7测试
- 6. yolov7自动标注
-
- 6.1. yolov7检测图片
- 6.2. yolo检测结果转via
0 相关链接
b站操作视频:https://www.bilibili.com/video/BV1cT411e7Rr/
文档:https://docs.qq.com/s/GmsJlEbZPL2QqvUMarbfxG
github:https://github.com/Whiffe/via2yolo
1. 总体功能描述
本系统基于via进行学生行为标注,将标注数据处理为yolo数据集格式。
- 行为标注:将via中标注的数据转化为yolo格式数据集。
- 数据可视化:对yolo格式的数据集进行可视化,可以直观看到标注状态。
- 数据检查:包括数量上的检查和小点的检查
- 动作扩展:对标注动作进行扩展。
- 行为检测:并采用yolov7对数据集进行训练测试。
2.软件安装说明
本系统代码发布在github中,可在:https://github.com/Whiffe/via2yolo下载
图 2-1 github 中via2yolo项目
2.1. 环境搭建
conda create --name via2yolo python=3.8 -y
2.2. 激活环境
conda activate via2yolo
2.3. 退出环境
conda deactivate
2.4. 删除环境
conda remove -n via2yolo -all
2.5. 安装opencv
pip install opencv-python-headless==4.1.2.30
3.标注数据处理
3.1. 收集
每个文件夹中存放着截图的行为图片
图 3-3视频截图
3.2.via对标注举手
使用via在线标注工具,对收集的学生行为图片进行标注
在线标注的链接: https://yu-xiangdongg.gitee.io/via/via_image_annotator.html

图 5-4 via在线标注举手
标注完成后,保存json文件:

图 5-5 标注文件
3.3. via 举手标注转化yolo格式
via2yolo1.py是将via转化为yolo格式
注意这是 via 中只框选了举手这个动作,就是将框转化为yolo格式,行为默认为 0
首先需要将via标注的图片(riseHand_via_dataset)放在via2yolo文件夹下
图 3-6 via2yolo 文件夹下的riseHand_via_dataset
执行的命令如下:
python via2yolo1.py --riseHand_via_dataset ./riseHand_via_dataset --riseHand_Dataset ./riseHand_Dataset --tain_r 0.8

图 5-7 via 举手标注转化yolo 命令
yolo格式数据集存放在riseHand_Dataset文件夹中
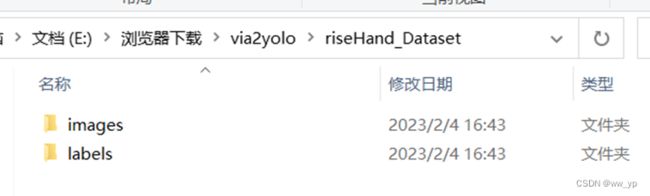
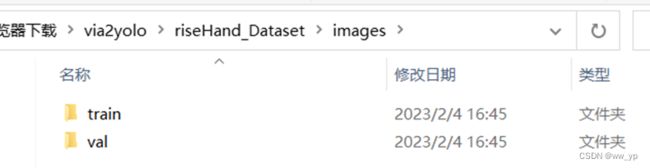
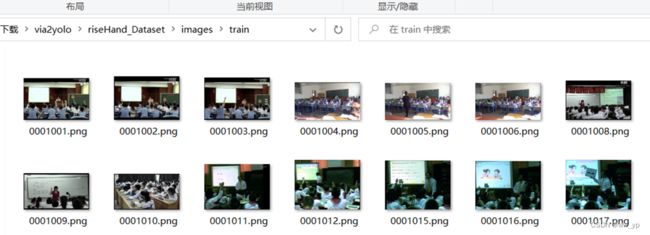
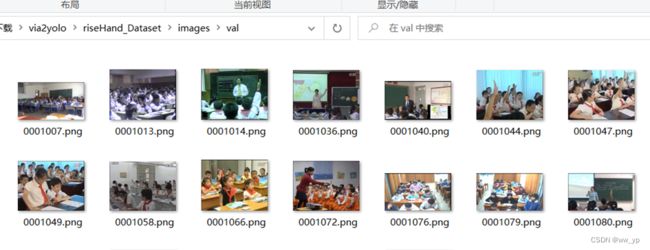

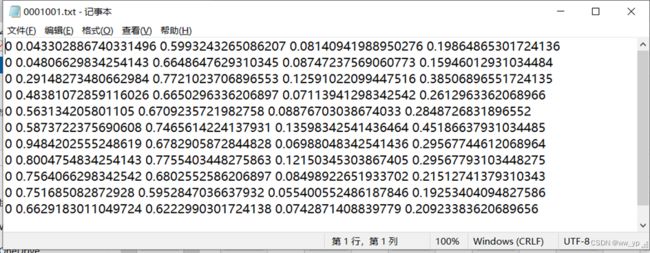
图 3-8 riseHand_Dataset 结构
3.4. via动作标注扩展
对学生行为标注的动作进行扩展
扩展动作添加到如下代码中:
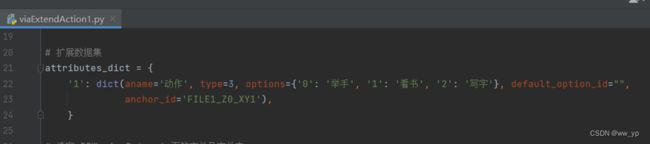
图 3-9 扩展动作代码
执行命令如下:
python viaExtendAction1.py --riseHand_via_dataset ./riseHand_via_dataset --RRW_via_Dataset ./RRW_via_Dataset
![]()
图 3-10 扩展动作命令
扩展后的动作数据集存放在RRW_via_Dataset文件夹中

图 3-11 RRW_via_Dataset文件夹结构
在via在线标注

图 3-12 via在线标注举手、看书、鞋子
对看书写字进行标注
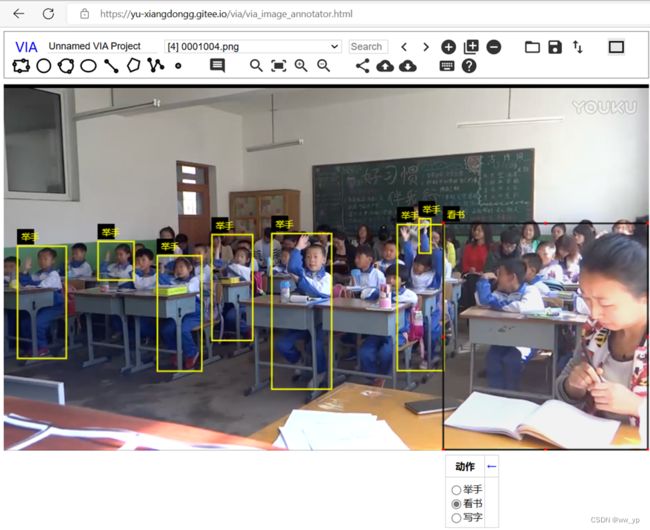
图 3-13 via在线标注 看书
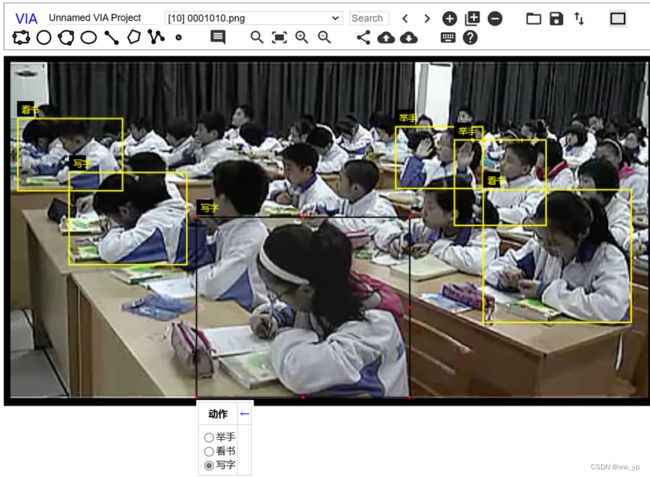
图 3-14 via在线标注 写字
3.5. via 举手看书写字标注转化yolo格式
via2yolo2.py是将via举手看书写字标注转化为yolo格式
注意这是 via 中多个动作转化为yolo格式
并且可以检查没有标注的框,并给出没有标注的图片名字
python via2yolo2.py --RRW_via_Dataset ./RRW_via_Dataset --RRW_Dataset ./RRW_Dataset --tain_r 0.8
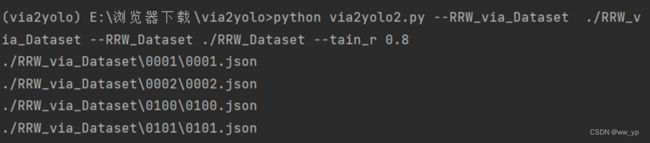
图 3-15 via 举手看书写字标注转化yolo格式命令
yolo格式数据集存放在RRW_Dataset文件夹中

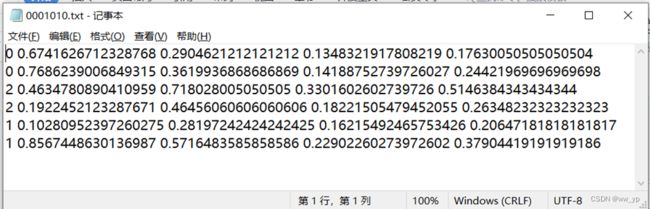
图 3-16 RRW_Dataset文件夹结构
4. 标注数据检查与可视化
4.1. 检查via框与yolo框是否一致
check.py的作用就是是检查via中的框的数量和yolo格式数据集的框的数量是否一致
执行命令如下:
python check.py --via_Dataset ./riseHand_via_dataset --yolo_Dataset ./riseHand_Dataset
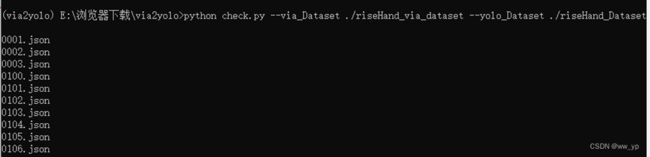
图 4-1 检查via框与yolo框是否一致 命令
如果出现不匹配的情况,程序会暂停,输出错误。如果程序正常结束,那么via的标注框与yolo的框是匹配的
4.2. 检查小点
check_dot.py是将找到小点对应的图片名字(图片名字中包含路径信息)
执行命令如下:
python check_dot.py --dot_size 15 --via_Dataset ./riseHand_via_dataset

图 4-2 检查小点命令
如上图所示,找到有小点的图片,然后用去除小点的via在线标注网站: https://yu-xiangdongg.gitee.io/via/via_image_annotator2.html
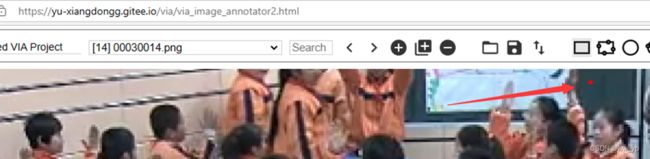
图 4-3 via在线标注中小点展示
再次执行检查小点的程序
![]()
图 4-4 检查小点命令,无小点结果
如果dot_num输出为0,就代表没有小点了。
4.3. 可视化数据
visual.py的作用可视化yolo数据集
执行命令如下:
python visual.py --yolo_Dataset ./riseHand_Dataset --Visual_dir ./Visual
执行结束后,会生成Visual文件夹:

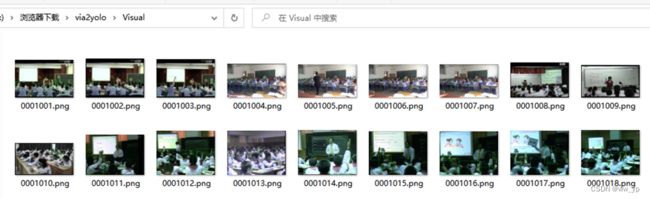
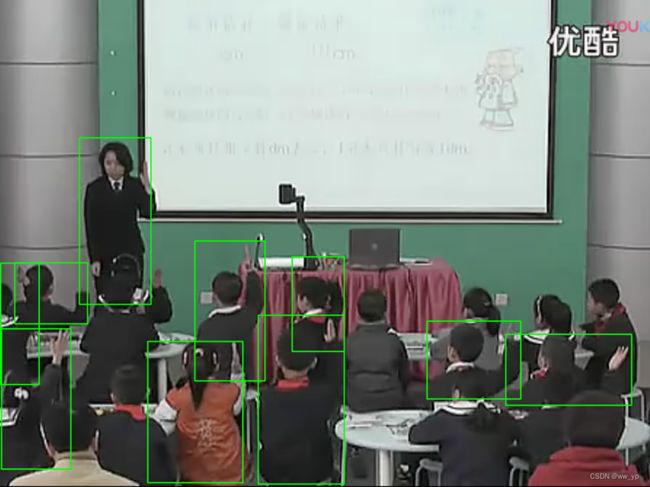
图 4-5 Visual文件夹结构
5. yolov7 训练与测试
5.1. GPU平台搭建yolov7
在 autodl平台中搭建yolov7
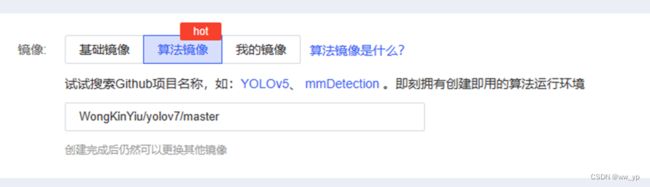
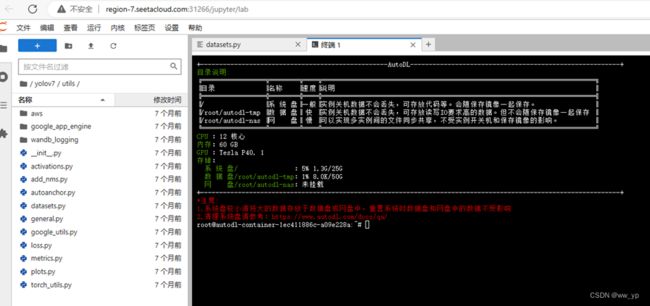
图 5-1 autodl平台中搭建yolov7
数据集放在/root/autodl-tmp/riseHand_Dataset
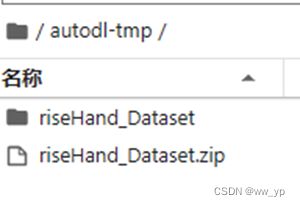
图 5-2 数据集位置
在http://root/yolov7/data/下创建risehand.yaml
内容如下:

图 7-3 risehand.yaml内容
然后修改/root/yolov7/cfg/training/文件下的yolov7.yaml
将其中的nc: 80 修改为nc: 1
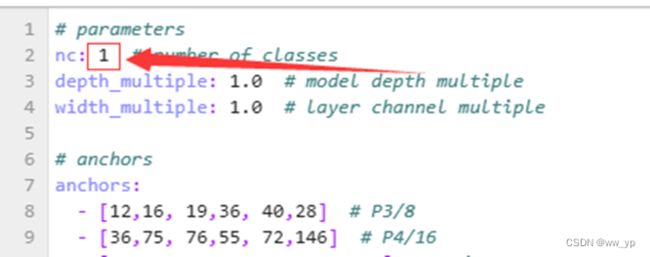
图 5-4 修改yolov7.yaml内容
5.2. yolov7训练
在/root/yolov7目录下,执行命令。
训练命令如下:
python train.py --data risehand.yaml --cfg cfg/training/yolov7.yaml --weights yolov7.pt --epoch 100 --batch-size 8
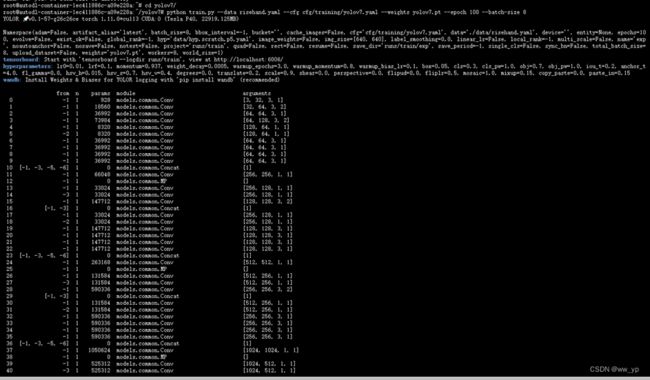
图 5-5 yolov7训练命令
训练后,最后结果位于/root/yolov7/runs/train/exp/:
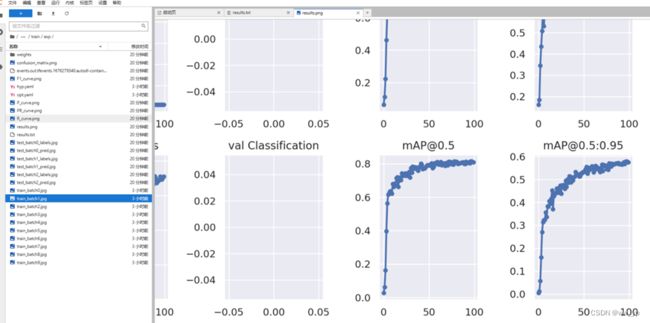
图 5-6 yolov7训练结果图
5.3. yolov7测试
测试命令:
python detect.py --weights runs/train/exp/weights/best.pt --source /root/autodl-tmp/riseHand_Dataset/images/val/0401061.png
测试结果:

图 5-7 yolov7测试结果
6. yolov7自动标注
经过了一定数量图片数据的标注(2.7k张),再经过yolov7的训练,就可以使用训练的权重对未标注的图片进行自动标注,然后人工检测微调标注框。
6.1. yolov7检测图片
首先,对未标注的文件夹进行压缩。

图 6-1 对待标注文件进行压缩
然后将数据上传到autodl平台中的/root/autodl-tmp/,并解压
图 6-2 对待标注文件上传平台并解压
接下来使用yolov7对待标注文件进行检测,命令如下:
python detect.py --weights runs/train/exp/weights/best.pt --source /root/autodl-tmp/1302 --save-txt --save-conf --name ./1302

图 6-3 yolov7对待标注文件进行检测
检测结果位于:/rootyolov7/runs/detect/1302/下:
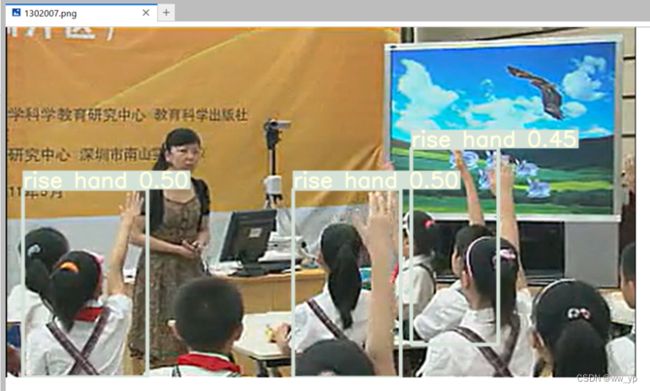
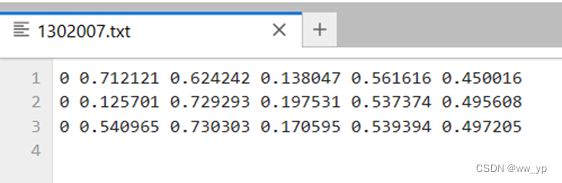
图 6-4 yolov7训练后对举手图片的检测结果
6.2. yolo检测结果转via
将https://github.com/Whiffe/via2yolo/blob/main/via3_tool.py, https://github.com/Whiffe/via2yolo/blob/main/via2yolo.py这两个文件上传到autodl平台中的/root/yolov7。

图 6-5 via3_tool.py与yolo2via.py上传autodl平台
将yolov7检测结果转化为via标注格式的json文件,输入如下命令
python yolo2via.py --img_path /root/autodl-tmp/1302 --label_path ./runs/detect/1302/labels --json_path ./1302.json
运行结束后,再/root/yolov7目录下产生1302.json的文件

图 6-6 yolov7检测结果转via格式的json文件
然后将生成的json文件下载到待标注的文件夹下:
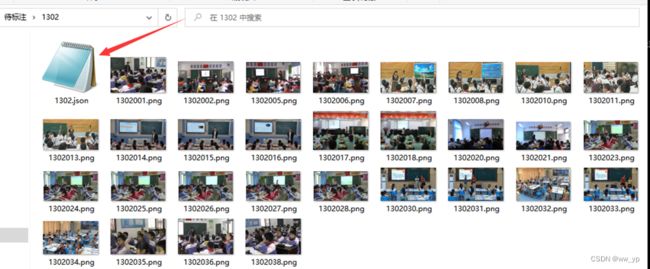
图 6-7 下载json文件到待标注文件夹下
打开在线标注的链接:https://yu-xiangdongg.gitee.io/via/via_image_annotator.html,导入图片与json文件,进行标注。
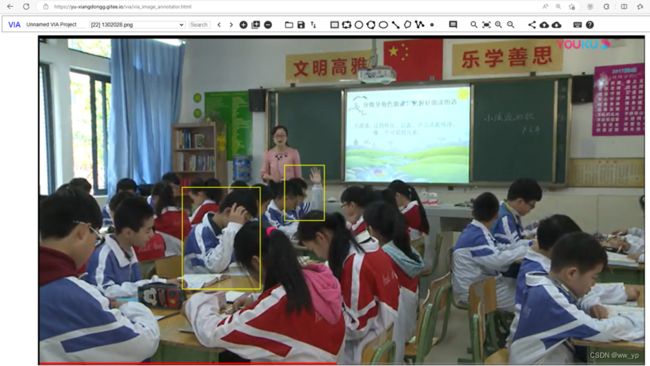
图 6-8 via中导入图片与json文件