ClickHouse 创建数据库建表视图字典 SQL

1.1. ClickHouseSQL之****数据定义语言 DDL
本节介绍 ClickHouse 中进行数据库、表结构的定义和管理。
1.1.1.概述
在SQL中,数据定义语言( DDL ) 用来创建和修改数据库Schema,例如表、索引和用户等。其中数据库的Schema描述了用户数据模型、字段和数据类型。DDL 语句类似于用于定义数据结构的计算机编程语言。常见DDL 语句包括CREATE、ALTER、DROP等。
ClickHouse SQL中的DDL,除了可以定义数据库、表、索引和视图等之外,还可以定义函数和字典等。
1.1.2.创建数据库
语法
CREATE DATABASE [IF NOT EXISTS] db_name
[ON CLUSTER cluster]
[ENGINE = db_engine(...)]
[COMMENT 'Comment']
功能说明
1. 创建名称为db_name的数据库。
2. 如果指定了ON CLUSTER cluster 子句,那么在指定集群 cluster 的所有服务器上创建 db_name 数据库。
3. ENGINE = db_engine(…), 数据库引擎。ClickHouse 默认使用 Atomic 数据库引擎,即有默认值 ENGINE = Atomic。Atomic 引擎提供了可配置的 table engines 和 SQL dialect,它支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的表交换查询命令 EXCHANGE TABLES t1 AND t2。Atomic 中的所有表都有持久的 UUID,数据存储在/clickhouse_path/store/xxx/xxxyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy/路径下。其中,xxxyyyyy-yyyy-yyyy-yyyy-yyyyyyyyyyyy是表 UUID,支持在不更改 UUID 和移动表数据的情况下执行重命名。可以使用DatabaseCatalog,通过 UUID访问 Atomic 数据库中的表。执行DROP TABLE 命令,不会删除任何数据,Atomic 数据库只是通过将元数据移动到 /clickhouse_path/metadata_dropped/,并将表标记为已删除,并通知 DatabaseCatalog。
在 20.5 版本中(可以使用SELECT version() 查看 ClickHouse版本),ClickHouse 首次引入了数据库引擎Atomic。从 20.10 版开始,它是默认数据库引擎(之前默认使用 engine=Ordinary )。SQL 如下:
SELECT version()
Query id: 45ca90b4-5e17-4106-a92f-f8fed8822286
┌─version()────┐
│ 21.12.1.8808 │
└──────────────┘
SHOW CREATE DATABASE system
FORMAT TSVRaw
Query id: 19d3e06d-dfaf-45b4-a67d-156199098bc4
CREATE DATABASE system
ENGINE = Atomic
这两个数据库引擎在文件系统上存储数据的方式有所不同(Ordinary引擎的文件系统布局更简单),Atomic 引擎解决了Ordinary引擎中存在的一些问题。
Atomic 引擎支持非阻塞删除表/重命名表、异步表删除和分离(delete&detach)(等待查询完成,但对新查询不可见)、原子删除表(删除所有文件/文件夹)、原子表交换(通过“EXCHANGE TABLES t1 AND t2”进行表交换)、重命名字典/重命名数据库、
在FS和ZK 中自动生成唯一UUID 路径用于复制。ClickHouse 支持的数据库引擎可以在 源码目录src/Databases 下面找到。例如在DatabaseFactory.cpp(112行)中,可以看到 ClickHouse数据库引擎集合:
database_engines {"Ordinary", "Atomic", "Memory","Dictionary", "Lazy", "Replicated", "MySQL", "MaterializeMySQL", "MaterializedMySQL", "PostgreSQL", "MaterializedPostgreSQL","SQLite"}
4.COMMENT ‘Comment’,添加数据库注释。所有数据库引擎都支持该注释。
数据库引擎Atomic与Ordinary对比
数据库引擎
Ordinary
Atomic
文件系统布局
简单
复杂
外部工具支持,如 clickhouse-backup等
好/成熟
有限/测试版
一些 DDL 查询(DROP / RENAME)可能要挂起等待很长时间
是的
没有
支持交换 2 张表操作
renamea to a_old,b to a,a_old to b;操作不是原子的,并且 可以在中间突破(虽然机会很低)。
EXCHANGE TABLES t1 AND t2;原子操作,没有中间状态。
使用 zookeeper路径中的 uuid
无法使用。典型的模式是需要创建同一张表的新版本的时候,给zookeeper路径加上版本后缀。
可以在 zookeeper 路径中使用 uuid。可以在 zookeeper 路径中使用 uuid。但是,当扩展集群时,这需要格外小心。Zookeeper 路径更难以映射到真实表。允许对表进行任何类型的操作(重命名、使用相同名称重新创建等)。
物化视图,建议始终使用 TO 语法。
.inner.mv_name, 名字可读。
.inner_id.{uuid},名字不可读。
创建一个使用 Atomic引擎的数据库
CREATE DATABASE if not exists clickhouse_tutorial ENGINE = Atomic;
查看数据库列表
使用命令show databases可以看到数据库列表如下。
SHOW DATABASES
Query id: 08c13dfb-0f5c-4aea-815a-68ec95eaa037
┌─name────────────────┐
│ INFORMATION_SCHEMA │
│ clickhouse_tutorial │
│ default │
│ information_schema │
│ mydb │
│ system │
│ tutorial │
└─────────────────────┘
如果想要看当前ClickHouseServer 进程实例下更加详细的数据库列表信息,可以使用select * from system.databases命令。为了可读性,输出结果整理成表格如下。
name
engine
data_path
metadata_path
uuid
comment
database
INFORMATION_SCHEMA
Memory
./
00000000-0000-0000-0000-000000000000
clickhouse_tutorial
Atomic
./store/
/Users/chenguangjian/store/3c0/3c0b76c0-1dac-4f88-bc0b-76c01dac3f88/
3c0b76c0-1dac-4f88-bc0b-76c01dac3f88
default
Atomic
./store/
/Users/chenguangjian/store/d62/d62015e0-b943-4090-9620-15e0b9432090/
d62015e0-b943-4090-9620-15e0b9432090
information_schema
Memory
./
00000000-0000-0000-0000-000000000000
mydb
Ordinary
./data/mydb/
/Users/chenguangjian/metadata/mydb/
00000000-0000-0000-0000-000000000000
mydb
system
Atomic
./store/
/Users/chenguangjian/store/268/2682f921-c33f-4278-a682-f921c33f9278/
2682f921-c33f-4278-a682-f921c33f9278
tutorial
Atomic
./store/
/Users/chenguangjian/store/d34/d34824fa-e714-43e8-9348-24fae71403e8/
d34824fa-e714-43e8-9348-24fae71403e8
可以看出,使用Atomic引擎的元数据路径上都带有 UUID,而使用Ordinary引擎的路径使用的是数据库名字,Memory引擎则没有元数据存储到磁盘文件上。
可以使用命令show create database system查看system数据库建库命令:
CREATE DATABASE system
ENGINE = Atomic
可见,system使用的是Atomic引擎。
1.1.3.删除数据库
使用 DROP命令删除数据库,SQL实例如下:
drop DATABASE if exists clickhouse_tutorial;
使用select * from system.databases 查看数据库列表里面,clickhouse_tutorial已经被删掉。
1.1.4.创建****MergeTree表
语法
ClickHouse 中最强大的表引擎是*MergeTree家族系列,也是使用最多的表引擎。
创建MergeTree表SQL语法如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster_name]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT [GROUP BY] [ORDER BY]),
PROJECTION projection_name_2 (SELECT [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
功能说明
1. ON CLUSTER cluster_name,在ClickHouse集群cluster_name上建表。默认情况下,表仅在当前服务器上创建。如果是在ClickHouse集群cluster_name的所有服务节点上建表,使用分布式 DDL 查询子句ON CLUSTER 实现。
2. ENGINE = table_engine,指定表引擎。可以通过SQL查询system.table_engines表内容,获得ClickHouse支持的表引擎。如下所示。
SELECT
name,
supports_ttl
FROM system.table_engines
Query id: f219cd4d-dd2b-4490-a9aa-e66f29cec9ac
┌─name───────────────────────────────────┬─supports_ttl─┐
│ PostgreSQL │ 0 │
│ RabbitMQ │ 0 │
│ Kafka │ 0 │
│ S3 │ 0 │
│ ExecutablePool │ 0 │
│ MaterializedView │ 0 │
│ MaterializedPostgreSQL │ 0 │
│ EmbeddedRocksDB │ 0 │
│ View │ 0 │
│ JDBC │ 0 │
│ Join │ 0 │
│ ExternalDistributed │ 0 │
│ Executable │ 0 │
│ Set │ 0 │
│ Dictionary │ 0 │
│ GenerateRandom │ 0 │
│ LiveView │ 0 │
│ MergeTree │ 1 │
│ Memory │ 0 │
│ Buffer │ 0 │
│ MongoDB │ 0 │
│ URL │ 0 │
│ ReplicatedVersionedCollapsingMergeTree │ 1 │
│ ReplacingMergeTree │ 1 │
│ ReplicatedSummingMergeTree │ 1 │
│ COSN │ 0 │
│ ReplicatedAggregatingMergeTree │ 1 │
│ ReplicatedCollapsingMergeTree │ 1 │
│ File │ 0 │
│ ReplicatedGraphiteMergeTree │ 1 │
│ ReplicatedMergeTree │ 1 │
│ ReplicatedReplacingMergeTree │ 1 │
│ VersionedCollapsingMergeTree │ 1 │
│ SummingMergeTree │ 1 │
│ Distributed │ 0 │
│ TinyLog │ 0 │
│ GraphiteMergeTree │ 1 │
│ SQLite │ 0 │
│ CollapsingMergeTree │ 1 │
│ Merge │ 0 │
│ AggregatingMergeTree │ 1 │
│ ODBC │ 0 │
│ Null │ 0 │
│ StripeLog │ 0 │
│ Log │ 0 │
└────────────────────────────────────────┴──────────────┘
45 rows in set. Elapsed: 0.001 sec.
3.(name1 [type1], … ),指定表字段名和字段数据类型。
4.NULL|NOT NULL,字段是否可空。
5.DEFAULT,指定字段默认值。字段可以通过表达式 DEFAULT expr指定默认值。如果 INSERT 查询没有指定对应的列,则通过计算对应的表达式来填充。例如:`URLDomain String DEFAULT domain(URL)`。如果未定义默认值的表达式,则默认值将设置为数字为零,字符串为空字符串,数组为空数组,日期为 1970-01-01,DateTime unix时间戳为零,NULL为空。
6.MATERIALIZED,物化字段列。这样的字段不能在 INSERT 语句中指定值插入,因为这样的字段总是通过使用其他字段计算出来的。
7.EPHEMERAL,临时字段列。这样的列不存储在表中,不能被SELECT 查询,但可以在 CREATE 语句的默认值中引用。
8.ALIAS,字段别名。该别名值不会存储在表中,SELECT 查询中使用星号时不会被替换。如果在查询解析期间扩展了别名,则可以在 SELECT 中使用它。
9.INDEX index_name1 expr1 TYPE type1(…) GRANULARITY value1,指定索引字段和索引粒度。
10.PROJECTION projection_name_1,指定物化投影字段创建一个 Projection,为当前字段Where查询加速。Projection 思想源自 《C-Store: A Column-oriented DBMS》这篇论文,作者是2015年图灵奖获得者、Vertica 之父,Mike Stonebraker。Projection 意指一组列的组合,可以按照与原表不同的排序存储,并且支持聚合函数的查询。相当于传统意义上的物化视图,用空间换时间。它借鉴 MOLAP 预聚合的思想,在数据写入的时候,根据 PROJECTION定义的表达式,计算写入数据的聚合数据同原始数据一并写入。数据查询的过程中,如果查询SQL通过分析可以通过聚合数据得出,直接查询聚合数据减少计算的开销,解决了由于数据量导致的内存问题。Projection主要分为两种:normal与aggregate。相关源码参阅MergeTreeDataWriter.cpp(574行)MergeTreeDataWriter::TemporaryPart MergeTreeDataWriter::writeProjectionPart()。
11.ORDER BYexpr,指定排序字段元组,也即索引列(ClickHouse中的索引列即排序列)。从左到右顺序,建立稀疏索引组合键。合理设计排序键,对查询性能会有很大提升。一般选择查询条件中,筛选条件频繁的列。可以是单一维度,也可以是组合维度的索引。另外,基数特别大的不适合做索引列,如用户标签表的user_id字段。通常筛选后的数据量在百万级别,性能表现较好。
12.PARTITION BYexpr,指定分区字段元组。分区字段数据存储到独立的文件夹目录下。
13.SAMPLE BYexpr,指定采样字段。
14.compression_codec,指定压缩算法。通用编解码器有NONE(无压缩)、LZ4、LZ4HC、ZSTD。ClickHouse 默认使用 LZ4压缩算法CODEC(LZ4)。专用编解码器有Delta(delta_bytes)、DoubleDelta(适用于时间序列数据)、Gorilla、T64等。另外,使用CODEC(‘AES-128-GCM-SIV’)、CODEC(‘AES-256-GCM-SIV’)等可以加密磁盘上的数据。
15.TTL expr,表数据存活时间表达式。到期数据ClickHouse 会自动清理,对于数据 Part移动或重新压缩,数据的所有行都必须满足“TTL”表达式条件。只能为 MergeTree 系列表指定。TTL 子句不能用于主键列。例如,根据 date字段判断哪些数据到期, TTL表达式为:TTL date + INTERVAL 7DAY,其中 date 为日期字段。那么,date=20220301的数据将会在 7天后,也就是 20220308零点日期被清理。
16.PRIMARY KEY,索引主键。
17.SETTINGS name=value, …,指定配置项name=value,多个配置项之间用逗号分隔。例如,指定表的索引粒度:SETTINGS index_granularity = 8192。
实例讲解
创建MergeTree表
create table if not exists clickhouse_tutorial.user_tag
(
user_id UInt64 DEFAULT 0,
gender String DEFAULT 'NA',
age String DEFAULT 'NA',
active_level String DEFAULT 'NA',
date Date
) engine = MergeTree()
order by (user_id, active_level)
primary key (user_id)
partition by (date);
使用show create table clickhouse_tutorial.user_tag 命令查询建表 SQL,执行结果如下:
SHOW CREATE TABLE clickhouse_tutorial.user_tag
FORMAT TSVRaw
Query id: 30ec8e45-8ead-419e-b8fc-dbce54b5939c
CREATE TABLE clickhouse_tutorial.user_tag
(
`user_id` UInt64 DEFAULT 0,
`gender` String DEFAULT 'NA',
`age` String DEFAULT 'NA',
`active_level` String DEFAULT 'NA',
`date` Date
)
ENGINE = MergeTree
PARTITION BY date
PRIMARY KEY user_id
ORDER BY (user_id, active_level)
SETTINGS index_granularity = 8192
1 rows in set. Elapsed: 0.001 sec.
其中,index_granularity = 8192是默认的稀疏索引间隔行数。
使用PROJECTION创建MergeTree 表
使用PROJECTION语句建表:
create table if not exists clickhouse_tutorial.user_tag
(
UserID UInt64,
WatchID UInt64,
EventTime DateTime,
Sex UInt8,
Age UInt8,
OS UInt8,
RegionID UInt32,
RequestNum UInt32,
EventDate Date,
PROJECTION pOS(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID(
SELECT count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
) engine = MergeTree()
order by (WatchID, UserID, EventTime)
partition by (EventDate);
ALTER TABLE****添加PROJECTION
也可以通过alter table 语句添加PROJECTION 定义:
ALTER TABLE clickhouse_tutorial.user_tag
ADD PROJECTION pRegionID(SELECT count(1),groupBitmap(UserID) GROUP BY RegionID);
插入数据:
INSERT INTO clickhouse_tutorial.user_tag
(UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate)
select UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate
from tutorial.hits_v1;
可以看到 ClickHouse 数据库表文件目录下面多了两个文件夹 pOS.proj和 pRegionID.proj:
.
├── checksums.txt
├── columns.txt
├── count.txt
├── data.bin
├── data.mrk3
├── default_compression_codec.txt
├── minmax_EventDate.idx
├── pOS.proj
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ └── primary.idx
├── pRegionID.proj
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ └── primary.idx
├── partition.dat
└── primary.idx
2 directories, 23 files
每个proj文件夹下面的数据文件有checksums.txt、columns.txt、count.txt、data.bin、data.mrk3、default_compression_codec.txt、primary.idx等(Projection Part复用表分区信息),跟一张表的数据文件基本一样(可以看出,Projection本身就是表)。其中,pOS.proj/columns.txt文件内容是:
columns format version: 1
2 columns:
`OS` UInt8
`groupBitmap(UserID)` AggregateFunction(groupBitmap, UInt64)
pRegionID.proj/columns.txt文件内容是:
columns format version: 1
2 columns:
`RegionID` UInt32
`groupBitmap(UserID)` AggregateFunction(groupBitmap, UInt64)
手动触发物化PROJECTION
注意,只有在创建 PROJECTION 之后,再被写入的数据,才会自动物化。对于历史数据,需要手动触发物化,执行如下 SQL:
alter table clickhouse_tutorial.user_tag MATERIALIZE PROJECTION pOS;
alter table clickhouse_tutorial.user_tag MATERIALIZE PROJECTION pRegionID;
MATERIALIZE PROJECTION 是一个异步的 Mutation 操作,可以通过下面的语句查询状态:
SELECT
table,
mutation_id,
command,
is_done
FROM system.mutations
Query id: b50679e1-963f-4800-9366-abc08539ca23
┌─table────┬─mutation_id──────┬─command──────────────────────────┬─is_done─┐
│ user_tag │ mutation_127.txt │ MATERIALIZE PROJECTION pOS │ 1 │
│ user_tag │ mutation_128.txt │ MATERIALIZE PROJECTION pRegionID │ 1 │
└──────────┴──────────────────┴──────────────────────────────────┴─────────┘
2 rows in set. Elapsed: 0.004 sec.
等MATERIALIZE PROJECTION 生成好了之后,分区目录如下:
.
├── Age.bin
├── Age.mrk2
├── EventDate.bin
├── EventDate.mrk2
├── EventTime.bin
├── EventTime.mrk2
├── OS.bin
├── OS.mrk2
├── RegionID.bin
├── RegionID.mrk2
├── RequestNum.bin
├── RequestNum.mrk2
├── Sex.bin
├── Sex.mrk2
├── UserID.bin
├── UserID.mrk2
├── WatchID.bin
├── WatchID.mrk2
├── checksums.txt
├── columns.txt
├── count.txt
├── default_compression_codec.txt
├── minmax_EventDate.idx
├── pOS.proj
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ └── primary.idx
├── pRegionID.proj
│ ├── checksums.txt
│ ├── columns.txt
│ ├── count.txt
│ ├── data.bin
│ ├── data.mrk3
│ ├── default_compression_codec.txt
│ └── primary.idx
├── partition.dat
└── primary.idx
2 directories, 39 files
看到在原有 MergeTree 的分区下,多了两个pOS.proj和pRegionID.proj子目录,文件存储和 MergeTree 存储格式是一样的,其中,Projection Part复用表分区信息(minmax_EventDate.idx、partition.dat)。Projection写入与原始数据写入过程一致。每一份数据part写入都会基于原始数据Block,结合Projection定义,计算好聚合数据,然后写入对应分区Part文件。
当查询命中某个 PROJECTION 的时候,就会直接用proj子目录中的数据来加速查询。
设置投影优化生效参数
有了PROJECTION 之后,想要查询时投影优化生效,需要设置allow_experimental_projection_optimization参数开启这项功能:
SET allow_experimental_projection_optimization=1;
查看SQL执行计划:
EXPLAIN actions = 1
SELECT
RegionID,
count(1)
FROM clickhouse_tutorial.user_tag
GROUP BY RegionID
Query id: d8a96bb5-c7d5-48bd-98a6-dd148618ef5d
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Actions: INPUT :: 0 -> RegionID UInt32 : 0 │
│ INPUT :: 1 -> count() UInt64 : 1 │
│ Positions: 0 1 │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromStorage (MergeTree(with Aggregate projection pRegionID)) │
└───────────────────────────────────────────────────────────────────────────┘
6 rows in set. Elapsed: 0.003 sec.
其中,ReadFromStorage (MergeTree(with Aggregate projection pRegionID)) 表示查询命中 Projection。
如果关闭投影优化,设置如下:
SET allow_experimental_projection_optimization=0;
再次查看 SQL 执行计划,可以看到:
EXPLAIN actions = 1
SELECT
RegionID,
count(1)
FROM clickhouse_tutorial.user_tag
GROUP BY RegionID
Query id: e903857a-4c30-41e6-9a15-082f98dd7cb6
┌─explain───────────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Actions: INPUT :: 0 -> RegionID UInt32 : 0 │
│ INPUT :: 1 -> count() UInt64 : 1 │
│ Positions: 0 1 │
│ Aggregating │
│ Keys: RegionID │
│ Aggregates: │
│ count() │
│ Function: count() → UInt64 │
│ Arguments: none │
│ Argument positions: none │
│ Expression (Before GROUP BY) │
│ Actions: INPUT :: 0 -> RegionID UInt32 : 0 │
│ Positions: 0 │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
│ ReadType: Default │
│ Parts: 32 │
│ Granules: 13007 │
└───────────────────────────────────────────────────────────────────────────────┘
19 rows in set. Elapsed: 0.002 sec.
可以看出,就没有命中 Projection。
关于Projection物化投影具体的使用和性能数据,参见“6.7PROJECTION高性能实践”。
1.1.5.复制表
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS [db2.]name2 [ENGINE = engine]
功能说明
使用源表db2.name2结构,创建表db.table_name表,它们具有相同结构。可以为表指定不同的引擎。如果未指定引擎,则使用与 db2.name2 表相同的引擎。
实例讲解
现有表clickhouse_tutorial.user_tag结构如下
CREATE TABLE clickhouse_tutorial.user_tag
(
`UserID` UInt64,
`WatchID` UInt64,
`EventTime` DateTime,
`Sex` UInt8,
`Age` UInt8,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date,
PROJECTION pOS
(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID
(
SELECT
count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SETTINGS index_granularity = 8192
我们基于这张表创建一张新表clickhouse_tutorial.user_tag_new,SQL 如下:
CREATE TABLE clickhouse_tutorial.user_tag_new AS clickhouse_tutorial.user_tag;
执行show create table clickhouse_tutorial.user_tag_new 命令:
CREATE TABLE clickhouse_tutorial.user_tag_new
(
`UserID` UInt64,
`WatchID` UInt64,
`EventTime` DateTime,
`Sex` UInt8,
`Age` UInt8,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date,
PROJECTION pOS
(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID
(
SELECT
count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SETTINGS index_granularity = 8192
可以看出,这两张表结构一模一样。
1.1.6.从查询语句创建****表
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name
[(name1 [type1], name2 [type2], ...)]
ENGINE = engine
AS SELECT ...
功能说明
根据SELECT查询数据结构,创建一个表结构相同的表,并把SELECT的数据插入到表中。
实例讲解
1、为了完整展示整个过程,我们先创建一个数据库tutorial,SQL 如下:
CREATE DATABASE IF NOT EXISTS tutorial;
2、然后创建表tutorial.hits_v1,SQL 如下:
CREATE TABLE tutorial.hits_v1
(
`WatchID` UInt64,
`JavaEnable` UInt8,
`Title` String,
`GoodEvent` Int16,
`EventTime` DateTime,
`EventDate` Date,
`CounterID` UInt32,
`ClientIP` UInt32,
`ClientIP6` FixedString(16),
`RegionID` UInt32,
`UserID` UInt64,
`CounterClass` Int8,
`OS` UInt8,
...
`Age` UInt8,
`Sex` UInt8,
...
`ShareURL` String,
`ShareTitle` String,
`ParsedParams` Nested(
Key1 String,
Key2 String,
Key3 String,
Key4 String,
Key5 String,
ValueDouble Float64),
`IslandID` FixedString(16),
`RequestNum` UInt32,
`RequestTry` UInt8
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID);
完整 SQL参见:https://clickhouse.com/docs/en/getting-started/tutorial/。
3、向tutorial.hits_v1表中插入数据。下载 ClickHouse 官网提供的测试数据包:
https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz
解压成.tsv数据文件,然后通过clickhouse client --query命令行导入数据:
clickhouse client
-h 127.0.0.1 --port 9009
-u default
--password 7Dv7Ib0g
--query "INSERT INTO tutorial.hits_v1 FORMAT TSV"
--max_insert_block_size=1000000 < hits_v1.tsv
导入完成之后,可以看看表中数据条数:
SELECT count()
FROM tutorial.hits_v1
Query id: d2207e4b-0dbb-4cac-b498-e009534dc98c
Connecting to 127.0.0.1:9009 as user default.
Connected to ClickHouse server version 22.4.1 revision 54455.
┌─count()─┐
│ 8873898 │
└─────────┘
1 rows in set. Elapsed: 0.067 sec.
4、现在,我们通过使用 SELECT语句基于表tutorial.hits_v1创建一张新表,并把tutorial.hits_v1表中相应字段的数据,插入到新表中。执行下面的建表并插入数据 SQL:
CREATE TABLE clickhouse_tutorial.hits_v2
(
WatchID UInt64,
UserID UInt64,
EventTime DateTime,
OS UInt8,
RegionID UInt32,
RequestNum UInt32,
EventDate Date
) ENGINE = MergeTree
partition by EventDate
order by (WatchID, UserID, EventTime)
AS
SELECT WatchID,
UserID,
EventTime,
OS,
RegionID,
RequestNum,
EventDate
from tutorial.hits_v1;
5、查看创建结果。执行下面的 SQL:
show create table clickhouse_tutorial.hits_v2;
可以看到hits_v2建表SQL 如下:
CREATE TABLE clickhouse_tutorial.hits_v2
(
`WatchID` UInt64,
`UserID` UInt64,
`EventTime` DateTime,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SETTINGS index_granularity = 8192
然后,hits_v2中也插入了数据:
SELECT count()
FROM clickhouse_tutorial.hits_v2
Query id: 4a835757-fca2-4866-bba7-27130a1444ec
┌─count()─┐
│ 8873898 │
└─────────┘
1 rows in set. Elapsed: 0.003 sec.
1.1.7.从表函数创建表
语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name AS table_function()
功能说明
创建一个与表函数返回结果相同的表。
实例讲解
ClickHouse 提供了表函数(tablefunction)来构造表。这些表函数如下:
SELECT *
FROM system.table_functions
Query id: 3b768f92-72ca-46bf-b4a3-27e993fae21e
┌─name───────────────┐
│ dictionary │
│ numbers_mt │
│ view │
│ cosn │
│ generateRandom │
│ remote │
│ input │
│ s3Cluster │
│ values │
│ s3 │
│ url │
│ remoteSecure │
│ sqlite │
│ zeros │
│ jdbc │
│ zeros_mt │
│ postgresql │
│ odbc │
│ executable │
│ clusterAllReplicas │
│ cluster │
│ merge │
│ null │
│ file │
│ numbers │
└────────────────────┘
25 rows in set. Elapsed: 0.001 sec.
下面就用实例来说明常用表函数的用法。
file表函数
使用场景
当我们需要把数据从 ClickHouse 导出到文件,或者将数据从一种格式转换为另一种格式,或者通过编辑磁盘上的文件来更新 ClickHouse 中的数据的时候,就可以使用 ClickHouse文件表引擎(FileTableEngine)。
创建文件表引擎
在clickhouse_tutorial数据库中,创建一张使用 File 引擎的表,表名为file_table_demo:
CREATE TABLE clickhouse_tutorial.file_table_demo
(
`name` String,
`value` UInt32
)
ENGINE = File(CSV)
Query id: 235acc8a-11c5-46ca-a90b-e65797d5ba79
Ok.
0 rows in set. Elapsed: 0.003 sec.
执行上面的建表 SQL,创建了文件目录:
/Users/chenguangjian/data/clickhouse_tutorial/file_table_demo
这是一个软连接,指向目录…/store/94a/94a2972d-80c6-4556-94a2-972d80c65556/。
drwxr-x--- 4 chenguangjian staff 128 3 21 22:14 .
drwxr-x--- 8 chenguangjian staff 256 3 21 03:08 ..
lrwxr-x--- 1 chenguangjian staff 64 3 21 22:14 file_table_demo -> /Users/chenguangjian/store/1b1/1b136096-58ae-40e1-9b13-609658ae90e1/
lrwxr-x--- 1 chenguangjian staff 64 3 21 13:06 user_tag -> /Users/chenguangjian/store/94a/94a2972d-80c6-4556-94a2-972d80c65556/
插入数据
手动准备数据文件data.csv,内容如下
$cat data.csv
1,a
2,b
3,c
并把data.csv复制到/Users/chenguangjian/data/clickhouse_tutorial/file_table_demo/ 目录下。这样就完成了表数据的插入。
查询数据
SELECT *
FROM clickhouse_tutorial.file_table_demo
Query id: 0ae85ab2-8188-4b32-8f24-00c5b8b4018a
┌─name─┬─value─┐
│ a │ 1 │
│ b │ 2 │
│ c │ 3 │
└──────┴───────┘
3 rows in set. Elapsed: 0.002 sec.
支持的文件格式
文件表引擎支持TabSeparated、JSON、CSV、Native 等文件格式。完整文件格式清单如下:
SELECT *
FROM system.formats
Query id: 0fde0b5f-b625-4f60-b8cf-6156b66f2ca3
┌─name───────────────────────────────────────┬─is_input─┬─is_output─┐
│ CapnProto │ 1 │ 1 │
│ PostgreSQLWire │ 0 │ 1 │
│ MySQLWire │ 0 │ 1 │
│ JSONStringsEachRowWithProgress │ 0 │ 1 │
│ JSONEachRowWithProgress │ 0 │ 1 │
│ JSONCompact │ 0 │ 1 │
│ Null │ 0 │ 1 │
│ JSONStrings │ 0 │ 1 │
│ JSON │ 0 │ 1 │
...
│ Regexp │ 1 │ 0 │
│ TSV │ 1 │ 1 │
│ Vertical │ 0 │ 1 │
│ CSV │ 1 │ 1 │
│ TSVRaw │ 1 │ 1 │
│ Values │ 1 │ 1 │
│ JSONStringsEachRow │ 1 │ 1 │
│ TabSeparatedWithNamesAndTypes │ 1 │ 1 │
│ TSVRawWithNames │ 1 │ 1 │
│ JSONCompactEachRowWithNamesAndTypes │ 1 │ 1 │
│ TabSeparatedRaw │ 1 │ 1 │
│ TSVWithNames │ 1 │ 1 │
│ JSONEachRow │ 1 │ 1 │
└────────────────────────────────────────────┴──────────┴───────────┘
68 rows in set. Elapsed: 0.002 sec.
numbers(N)表函数
返回具有单个“数字”列 (UInt64) 的表,其中包含从 0 到 N-1 的整数。类似于 system.numbers 表,它可以用于测试和生成连续值。下面 3 个查询是等价的:
SELECT * FROM numbers(10);
SELECT * FROM numbers(0, 10);
SELECT * FROM system.numbers LIMIT 10;
输出:
┌─number─┐
│ 0 │
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
└────────┘
10 rows in set. Elapsed: 0.001 sec.
remote表函数
连接远程表:
SELECT *
FROM remote('127.0.0.1:9000', clickhouse_tutorial.user_tag)
LIMIT 3
url****表函数
语法:url(URL, format, structure)
功能说明:
URL: String 类型,HTTP 或 HTTPS 服务器地址,可以接收 GET 或 POST 请求
format: String 类型,指定数据的格式
structure:String 类型,确定列名和类型。以格式’UserID UInt64, Name String’指定表结构。
例如,从返回CSV 格式的 HTTPAPI获取包含 String 和 UInt32 类型列的表的前 3 行。
SELECT * FROM url('http://127.0.0.1:8888/', CSV, 'column1 String, column2 UInt32')
LIMIT 3;
h****dfs表函数
语法:hdfs(URI, format, structure)
说明:从 HDFS 文件创建表。此表功能类似于url()表函数。
例如,从hdfs://hdfs1:9000/test查询前 2 行数据:
SELECT *
FROM hdfs('hdfs://hdfs1:9000/test', 'TSV', 'column1 UInt32, column2 UInt32, column3 UInt32')
LIMIT 2
输出:
┌─column1─┬─column2─┬─column3─┐
│ 1 │ 2 │ 3 │
│ 3 │ 2 │ 1 │
└─────────┴─────────┴─────────┘
1.1.8.创建视图
ClickHouse 视图可分为普通视图(Normal View)、物化视图(Materialized View)、实时视图(Live View)和窗口视图(Window View)等。创建视图使用CREATE VIEW命令。
普通视图
普通视图不存储任何数据,在每次访问时从源头表中读取。换句话说,普通视图只不过是保存的查询。
语法
CREATE [OR REPLACE] VIEW [IF NOT EXISTS]
[db.]table_name
[ON CLUSTER]
AS SELECT ...
功能说明
创建普通视图。从普通视图读取时,该查询会被解析替换成 FROM子句的子查询。例如,假设您已经创建了一个视图:
CREATE VIEW my_view AS
SELECT ...
然后,执行视图查询:
SELECT a, b, c FROM my_view
此查询完全等同于使用子查询:
SELECT a, b, c FROM (SELECT ...)
实例讲解
我们先创建一张表clickhouse_tutorial.user_tag,然后插入数据,然后根据这张表创建视图clickhouse_tutorial.user_tag_view。
1**、**创建源头表
CREATE TABLE clickhouse_tutorial.user_tag
(
`UserID` UInt64,
`WatchID` UInt64,
`EventTime` DateTime,
`Sex` UInt8,
`Age` UInt8,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date,
PROJECTION pOS
(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID
(
SELECT
count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SETTINGS index_granularity = 8192
2**、**插入数据
INSERT INTO clickhouse_tutorial.user_tag
(UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate)
select UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate
from tutorial.hits_v1;
3、创建普通视图
计算源头表clickhouse_tutorial.user_tag中的uniqExact(UserID) 、Age,执行如下 SQL创建普通视图user_tag_view:
CREATE VIEW clickhouse_tutorial.user_tag_view AS
SELECT
uniqExact(UserID) AS userCnt,
Age AS age
FROM clickhouse_tutorial.user_tag
GROUP BY Age
视图看起来与普通表相同。例如,视图也在“SHOW TABLES”查询的结果中。执行如下 SQL 查看视图:
USE clickhouse_tutorial
SHOW TABLES
Query id: 94bc8ce6-37e7-489b-9a98-07f0d6cc0d71
┌─name──────────┐
│ hits_v2 │
│ user_tag │
│ user_tag_new │
│ user_tag_view │
└───────────────┘
4 rows in set. Elapsed: 0.002 sec.
可以看到,视图也是作为 Table 在列表里返回。但是,我们去 ClickHouse存储表数据的文件目录/Users/data/clickhouse/data/clickhouse_tutorial 查看,并没有user_tag_view文件夹:
$ls -la | awk '{print $9 $10 $11}'
.
..
hits_v2->/Users/data/clickhouse/store/621/62181267-82f4-438d-9d1b-18437c1a86c0/
user_tag->/Users/data/clickhouse/store/daf/daf4def5-8bdc-4185-9674-3d406a37889a/
user_tag_new->/Users/data/clickhouse/store/d2c/d2c144a3-ed75-4db4-ac50-daab9b659427/
我们先记下user_tag表对应的文件目录 UUID,后面查询视图数据的时候,我们可以通过查看 ClickHouseServer 端的日志,确认查询视图数据,最终走的还是查询视图源表的数据。
4**、**查询视图数据
执行下面的 SQL 查询视图clickhouse_tutorial.user_tag_view里面的数据:
SELECT
userCnt,
age
FROM clickhouse_tutorial.user_tag_view
Query id: 96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6
┌─userCnt─┬─age─┐
│ 82404 │ 0 │
│ 21066 │ 16 │
│ 6556 │ 22 │
│ 2129 │ 26 │
│ 6282 │ 39 │
│ 8311 │ 55 │
└─────────┴─────┘
6 rows in set. Elapsed: 0.127 sec. Processed 8.87 million rows, 79.87 MB (69.64 million rows/s., 626.72 MB/s.)
我们去 ClickHouseServer 端看一下请求日志,搜索Query id关键字96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6即可搜到:
2022.03.23 03:38:36.268801 [ 2266438 ] {} TCP-Session: 39f75155-4c37-46dc-93ce-95fbabe57f61 Creating query context from session context, user_id: 94309d50-4f52-5250-31bd-74fecac179db, parent context user: default
2022.03.23 03:38:36.268938 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} executeQuery: (from 127.0.0.1:59025) select userCnt,age from clickhouse_tutorial.user_tag_view;
2022.03.23 03:38:36.269120 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} ContextAccess (default): Access granted: SELECT(userCnt, age) ON clickhouse_tutorial.user_tag_view
2022.03.23 03:38:36.269439 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} ContextAccess (default): Access granted: SELECT(UserID, Age) ON clickhouse_tutorial.user_tag
2022.03.23 03:38:36.270055 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} ContextAccess (default): Access granted: SELECT(UserID, Age) ON clickhouse_tutorial.user_tag
2022.03.23 03:38:36.270101 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} InterpreterSelectQuery: FetchColumns -> Complete
2022.03.23 03:38:36.270178 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6}
…
2022.03.23 03:38:36.270884 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) (SelectExecutor): Selected 27/27 parts by partition key, 27 parts by primary key, 1084/1084 marks by primary key, 1084 marks to read from 27 ranges
2022.03.23 03:38:36.271363 [ 2266438 ] {96bcbd61-0a4d-4d18-9e04-e3896b7e9ad6} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a)(SelectExecutor): Reading approx. 8873898 rows with 6 streams
…
2022.03.23 03:38:36.395867 [ 2266438 ] {} TCPHandler: Processed in 0.12711 sec.
从 ClickHouseServer 端的查询处理日志可以看出,查询视图 SQL 最终执行的逻辑,还是到源头表clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) 文件目录下面去读取相应的数据。
物化视图
物化视图跟普通视图的区别是,物化视图有自己的物理数据文件存储,而普通视图只是一层逻辑查询代理。
语法
CREATE MATERIALIZED VIEW [IF NOT EXISTS]
[db.]mt_table_name
[ON CLUSTER] [TO[db.]name]
[ENGINE = engine]
[POPULATE]
AS SELECT ...
功能说明
1.创建名称为mt_table_name的物化视图。
2.物化视图支持表引擎,数据的保存形式由表的引擎决定。
a)如果想把物化视图数据写入特定物理表数据文件中,可以使用TO [db].[table]。因为物化视图数据文件目录的生成规则是.inner_id.UUID,可读性比较差。
b)如果指定TO db.table,不能同时使用 POPULATE,也不需要指定表引擎ENGINE= engine(因为db.table表结构已经创建好了,表引擎也指定好了)。
c)如果没有指定TO db.table,则必须指定用于存储物化视图mt_table_name物理数据的表引擎ENGINE= engine。
3.物化视图在插入目标表期间,使用列名而不是列顺序。如果 SELECT查询结果中不存在某些列名,使用默认值。SELECT 查询可以包含DISTINCT、GROUP BY、ORDER BY、LIMIT。
4.创建完物化视图,源表被写入新数据则物化视图也会同步更新。
a)如果指定POPULATE,则在创建视图时会将现有表数据插入到视图中。
b)如果不指定POPULATE,SELECT查询结果只包含创建视图后插入表中的数据。
c)不建议使用 POPULATE,因为在创建物化视图的过程中,同时写入的数据不能被插入物化视图。
5.建议在使用物化视图时,为每一列添加别名。
6.物化视图不支持UNION。
Populate****释义
Populate,vt.居住于;生活于;构成…的人口;迁移;移居;殖民于;给文件增添数据,输入数据。
显然,物化视图里关键字POPULATE的意思是“给文件增添数据,输入数据”。
实例讲解
创建物化视图
从源表user_tag创建一个物化视图user_tag_mt_view_1,SQL 如下:
create materialized view clickhouse_tutorial.user_tag_mt_view_1
engine = MergeTree
partition by (date)
order by (age, date)
populate
as
select uniqExact(UserID) userCnt,
Age age,
EventDate date
from clickhouse_tutorial.user_tag
group by Age, EventDate;
为了方便测试,我们使用了populate同步源表user_tag中已有的数据到物化视图user_tag_mt_view_1中。
查询物化视图详细信息
创建完成之后,可以到system.tables系统表里查看物化视图表的详细信息。如下:
SELECT *
FROM system.tables
WHERE (database = 'clickhouse_tutorial') AND (name = 'user_tag_mt_view_1')
FORMAT Vertical
Query id: 84e4bdd5-5cf2-487b-8f79-512bd766e1dd
Row 1:
──────
database: clickhouse_tutorial
name: user_tag_mt_view_1
uuid: 1c93ef11-704f-4515-9596-fbdb4efdf6b8
engine: MaterializedView
is_temporary: 0
data_paths: ['/Users/data/clickhouse/store/2b4/2b4de01f-12f8-443e-97aa-53ecd1aa49a5/']
metadata_path: /Users/data/clickhouse/store/1e0/1e031223-783a-48a9-9f32-1a719033081b/user_tag_mt_view_1.sql
metadata_modification_time: 2022-03-23 15:36:51
dependencies_database: []
dependencies_table: []
create_table_query: CREATE MATERIALIZED VIEW clickhouse_tutorial.user_tag_mt_view_1 (`userCnt` UInt64, `age` UInt8, `date` Date) ENGINE = MergeTree PARTITION BY date ORDER BY (age, date) SETTINGS index_granularity = 8192 AS SELECT uniqExact(UserID) AS userCnt, Age AS age, EventDate AS date FROM clickhouse_tutorial.user_tag GROUP BY Age, EventDate
engine_full: MergeTree PARTITION BY date ORDER BY (age, date) SETTINGS index_granularity = 8192
as_select: SELECT uniqExact(UserID) AS userCnt, Age AS age, EventDate AS date FROM clickhouse_tutorial.user_tag GROUP BY Age, EventDate
partition_key:
sorting_key:
primary_key:
sampling_key:
storage_policy:
total_rows: ????
total_bytes: ????
lifetime_rows: ????
lifetime_bytes: ????
comment:
has_own_data: 0
loading_dependencies_database: []
loading_dependencies_table: []
loading_dependent_database: []
loading_dependent_table: []
1 rows in set. Elapsed: 0.004 sec.
去 ClickHouse 数据库的数据文件目录/Users/data/clickhouse/data/clickhouse_tutorial 下面,可以看到多了一个目录:
%2Einner_id%2E1c93ef11%2D704f%2D4515%2D9596%2Dfbdb4efdf6b8 -> /Users/data/clickhouse/store/2b4/2b4de01f-12f8-443e-97aa-53ecd1aa49a5/
上面的%2E,%2D是转义之后的字符,我们使用 JS脚本函数
decodeURI(‘%2Einner_id%2E1c93ef11%2D704f%2D4515%2D9596%2Dfbdb4efdf6b8’)
解码成可读的字符,就是:
.inner_id.1c93ef11-704f-4515-9596-fbdb4efdf6b8
.inner_id.后面的这一串,这个正是上面system.tables中查询结果里的uuid: 1c93ef11-704f-4515-9596-fbdb4efdf6b8。物化视图本质上也是一张内置的物理表。关于内置表名的生成规则可以在源代码StorageMaterializedView.cpp(39行) generateInnerTableName()函数中看到:
static inline String generateInnerTableName(const StorageID & view_id)
{
if (view_id.hasUUID())
return ".inner_id." + toString(view_id.uuid);
return ".inner." + view_id.getTableName();
}
查询物化视图数据
执行如下 SQL 查询物化视图数据:
SELECT
userCnt,
age,
date
FROM clickhouse_tutorial.user_tag_mt_view_1
ORDER BY
age ASC,
date ASC
Query id: 1027e983-2046-442d-aeb2-0ad770adbccc
┌─userCnt─┬─age─┬───────date─┐
│ 15578 │ 0 │ 2014-03-17 │
│ 15965 │ 0 │ 2014-03-18 │
...
│ 3339 │ 55 │ 2014-03-23 │
└─────────┴─────┴────────────┘
42 rows in set. Elapsed: 0.004 sec.
跟源表数据对比
跟源表中的数据对比一下:
SELECT
uniqExact(UserID) AS userCnt,
Age AS age,
EventDate AS date
FROM clickhouse_tutorial.user_tag
GROUP BY
Age,
EventDate
ORDER BY
Age ASC,
EventDate ASC
Query id: 4c700ac2-e5ff-420b-8a8d-5e6f870aa7c9
┌─userCnt─┬─age─┬───────date─┐
│ 15578 │ 0 │ 2014-03-17 │
│ 15965 │ 0 │ 2014-03-18 │
...
│ 3339 │ 55 │ 2014-03-23 │
└─────────┴─────┴────────────┘
42 rows in set. Elapsed: 0.124 sec. Processed 8.87 million rows, 97.61 MB (71.48 million rows/s., 786.28 MB/s.)
可以看出,物化视图跟源表数据查询结果是一致的。
性能对比
物化视图的核心思想也是预聚合、用空间换时间、数据立方体的思想,主要就是用来提升查询性能的。我们简单对比一下使用物化视图跟使用源表实时查询的性能数据。如下表。
可以看出,物化视图查询性能相对于源表聚合查询,性能上有几十数百倍的提升(由数据量大小、聚合方式、查询聚合字段基数等因素影响)。
指定物理表存储物化视图数据
可以指定用一张物理表来存储物化视图的数据。
1、先创建用来存储物化视图数据的目标表:
create table clickhouse_tutorial.user_tag_mt_view_2_table
(
date Date,
age UInt8,
userCnt UInt64
) engine = MergeTree
partition by (date)
order by (age, date);
2、然后,创建物化视图,并指定目标表存储物化视图的数据,SQL如下:
create materialized view clickhouse_tutorial.user_tag_mt_view_2
to clickhouse_tutorial.user_tag_mt_view_2_table
as
select uniqExact(UserID) userCnt,
Age age,
EventDate date
from clickhouse_tutorial.user_tag
group by Age, EventDate;
此时,指定了to clickhouse_tutorial.user_tag_mt_view_2_table,不能使用populate。
3、我们去system.tables中看一下user_tag_mt_view_2与user_tag_mt_view_2_table详情信息,执行如下 SQL:
SELECT
name,
uuid,
engine,
data_paths
FROM system.tables
WHERE (database = 'clickhouse_tutorial') AND (name IN ('user_tag_mt_view_2', 'user_tag_mt_view_2_table'))
输出结果:
name
uuid
engine
data_paths
user_tag_mt_view_2
e100e762-a590-4c49-8e3a-e9798f05458e
MaterializedView
[“/Users/data/clickhouse/store/b16/b16f114d-1423-45c0-adb2-56d0b9705c00/”]
user_tag_mt_view_2_table
b16f114d-1423-45c0-adb2-56d0b9705c00
MergeTree
[“/Users/data/clickhouse/store/b16/b16f114d-1423-45c0-adb2-56d0b9705c00/”]
可以发现,ClickHouse 维护了两份逻辑元数据(name,uuid,engine)等,但是物理数据文件是同一个,都是/Users/data/clickhouse/store/b16/b16f114d-1423-45c0-adb2-56d0b9705c00/。
另外,我们到数据库clickhouse_tutorial存储表数据的文件目录/Users/data/clickhouse/data/clickhouse_tutorial 下面可以发现,针对物化视图user_tag_mt_view_2 并没有再生成.inner_id.UUID这样的数据文件了。执行如下命令查看文件列表:
$ls -la|awk '{print $9 $10 $11}'
%2Einner_id%2E1c93ef11%2D704f%2D4515%2D9596%2Dfbdb4efdf6b8->/Users/data/clickhouse/store/2b4/2b4de01f-12f8-443e-97aa-53ecd1aa49a5/
.
..
hits_v2->/Users/data/clickhouse/store/621/62181267-82f4-438d-9d1b-18437c1a86c0/
user_tag->/Users/data/clickhouse/store/daf/daf4def5-8bdc-4185-9674-3d406a37889a/
user_tag_mt_view_2_table->/Users/data/clickhouse/store/b16/b16f114d-1423-45c0-adb2-56d0b9705c00/
user_tag_new->/Users/data/clickhouse/store/d2c/d2c144a3-ed75-4db4-ac50-daab9b659427/
4、为了测试数据查询效果,我们往源表里面插入数据
INSERT INTO clickhouse_tutorial.user_tag
(UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate)
select UserID,
WatchID,
EventTime,
Sex,
Age,
OS,
RegionID,
RequestNum,
EventDate
from tutorial.hits_v1;
5、从 Server 端的日志中,我们可以看到如下内容:
2022.03.23 16:40:41.321635 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} clickhouse_tutorial.user_tag_mt_view_2_table (b16f114d-1423-45c0-adb2-56d0b9705c00): Renaming temporary part tmp_insert_20140321_1_1_0 to 20140321_1_1_0.
2022.03.23 16:40:41.322075 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} DiskLocal: Reserving 1.00 MiB on disk `default`, having unreserved 195.81 GiB.
…
2022.03.23 16:40:41.345182 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} DiskLocal: Reserving 1.00 MiB on disk `default`, having unreserved 195.81 GiB.
2022.03.23 16:40:41.345697 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} MergedBlockOutputStream: filled checksums 20140317_14_14_0 (state Temporary)
2022.03.23 16:40:41.346478 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} clickhouse_tutorial.`.inner_id.1c93ef11-704f-4515-9596-fbdb4efdf6b8` (2b4de01f-12f8-443e-97aa-53ecd1aa49a5): Renaming temporary part tmp_insert_20140319_13_13_0 to 20140319_13_13_0.
…
2022.03.23 16:40:41.347180 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} PushingToViews: Pushing (sequentially) from clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) to clickhouse_tutorial.user_tag_mt_view_2 (e100e762-a590-4c49-8e3a-e9798f05458e) took 160 ms.
2022.03.23 16:40:41.347210 [ 2265628 ] {6e0011e2-a841-4fd8-b0f7-08d57ef764f0} PushingToViews: Pushing (sequentially) from clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) to clickhouse_tutorial.user_tag_mt_view_1 (1c93ef11-704f-4515-9596-fbdb4efdf6b8) took 145 ms.
可以发现,插入源表数据的过程中,会执行物化视图数据的计算和写入操作。
6、查询物化视图数据。执行如下 SQL 查询物化视图user_tag_mt_view_2的数据。
SELECT
userCnt,
age,
date
FROM clickhouse_tutorial.user_tag_mt_view_2
ORDER BY
age ASC,
date ASC
Query id: 665d36e3-282b-47e3-995f-bb4be479b2cb
┌─userCnt─┬─age─┬───────date─┐
│ 2549 │ 0 │ 2014-03-17 │
│ 2375 │ 0 │ 2014-03-17 │
...
│ 1379 │ 55 │ 2014-03-23 │
│ 1355 │ 55 │ 2014-03-23 │
│ 790 │ 55 │ 2014-03-23 │
└─────────┴─────┴────────────┘
378 rows in set. Elapsed: 0.005 sec.
从 Server 端的查询日志可以看出,上面查询物化视图clickhouse_tutorial.user_tag_mt_view_2的 SQL,最终路由到真正执行查询的是物理表clickhouse_tutorial.user_tag_mt_view_2_table。相关日志内容如下:
2022.03.23 17:15:54.507052 [ 3019212 ] {} TCP-Session: a1fec822-a98a-4451-8206-b4afc0d75c3a Creating query context from session context, user_id: 94309d50-4f52-5250-31bd-74fecac179db, parent context user: default
2022.03.23 17:15:54.507353 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} executeQuery: (from 127.0.0.1:64106) select userCnt, age, date from clickhouse_tutorial.user_tag_mt_view_2 order by age,date;
2022.03.23 17:15:54.507743 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} ContextAccess (default): Access granted: SELECT(userCnt, age, date) ON clickhouse_tutorial.user_tag_mt_view_2
2022.03.23 17:15:54.507901 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} InterpreterSelectQuery: FetchColumns -> Complete
2022.03.23 17:15:54.508052 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} clickhouse_tutorial.user_tag_mt_view_2_table(b16f114d-1423-45c0-adb2-56d0b9705c00) (SelectExecutor): Key condition: unknown
2022.03.23 17:15:54.508168 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} clickhouse_tutorial.user_tag_mt_view_2_table(b16f114d-1423-45c0-adb2-56d0b9705c00) (SelectExecutor): MinMax index condition: unknown
2022.03.23 17:15:54.508473 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} clickhouse_tutorial.user_tag_mt_view_2_table (b16f114d-1423-45c0-adb2-56d0b9705c00) (SelectExecutor): Selected 7/7 parts by partition key, 7 parts by primary key, 7/7 marks by primary key, 7 marks to read from 7 ranges
2022.03.23 17:15:54.508530 [ 3019212 ] {665d36e3-282b-47e3-995f-bb4be479b2cb} MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20140323_3_3_0, approx. 54 rows starting from 0
…
实时视图
实时视图表适用于以下典型场景:
1.查询结果更改提供推送通知以避免轮询。
2.缓存最频繁查询的结果以提供即时查询结果。
3.监视表更改并触发后续选择查询。
4.使用定期刷新从系统表中观察指标。
语法
创建实时视图
CREATE LIVE VIEW[IF NOT EXISTS] [db.]table_name
[
WITH [TIMEOUT [value_in_sec] [AND]]
[REFRESH [value_in_sec]]
]
AS SELECT …
实时视图查询
WATCH [db.]live_view
功能说明
实时视图把当前数据查询结果以及增量数据更新的结果存储在内存中。当使用WATCHdb.live_view监控到查询结果有更新时,实时视图提供推送通知。
实时视图不适用于需要完整数据集来计算最终结果的查询或必须保留聚合状态的聚合。
实时视图(LiveView)是一个实验性的功能,启用实时视图和开启 WATCH 查询,需要开启参数:SETallow_experimental_live_view = 1。
实例讲解
创建实时视图
执行如下 SQL 创建实时视图:
CREATE LIVE VIEW clickhouse_tutorial.user_tag_lv AS
SELECT
uniqExact(UserID) AS userCnt,
Age AS age,
EventDate AS date
FROM clickhouse_tutorial.user_tag
GROUP BY
Age,
EventDate
Query id: f630e4c1-86b9-4965-bb80-b95a8b4e8507
0 rows in set. Elapsed: 0.001 sec.
Received exception from server (version 22.4.1):
Code: 344. DB::Exception: Received from 127.0.0.1:9009. DB::Exception: Experimental LIVE VIEW feature is not enabled (the setting 'allow_experimental_live_view'). (SUPPORT_IS_DISABLED)
报错提示我们设置参数“allow_experimental_live_view”开启实时视图功能。
开启实时视图功能
执行如下命令开启实时视图功能:
SET allow_experimental_live_view = 1
查看实时视图详情
再次执行上面的创建实时视图的 SQL,执行成功。去系统表system.tables查看实时视图user_tag_lv的详细信息如下:
SELECT *
FROM system.tables
WHERE (database = 'clickhouse_tutorial') AND (name = 'user_tag_lv')
FORMAT Vertical
Query id: 79b9d7a2-d8a4-48d7-9354-431ab60089fc
Row 1:
──────
database: clickhouse_tutorial
name: user_tag_lv
uuid: 88832c4f-ca06-4f3e-b5bc-9680740e30fb
engine: LiveView
is_temporary: 0
data_paths: []
metadata_path: /Users/data/clickhouse/store/1e0/1e031223-783a-48a9-9f32-1a719033081b/user_tag_lv.sql
metadata_modification_time: 2022-03-24 01:54:05
dependencies_database: []
dependencies_table: []
create_table_query: CREATE LIVE VIEW clickhouse_tutorial.user_tag_lv (`userCnt` UInt64, `age` UInt8, `date` Date) AS SELECT uniqExact(UserID) AS userCnt, Age AS age, EventDate AS date FROM clickhouse_tutorial.user_tag GROUP BY Age, EventDate
engine_full:
as_select: SELECT uniqExact(UserID) AS userCnt, Age AS age, EventDate AS date FROM clickhouse_tutorial.user_tag GROUP BY Age, EventDate
partition_key:
sorting_key:
primary_key:
sampling_key:
storage_policy:
total_rows: ????
total_bytes: ????
lifetime_rows: ????
lifetime_bytes: ????
comment:
has_own_data: 0
loading_dependencies_database: []
loading_dependencies_table: []
loading_dependent_database: []
loading_dependent_table: []
1 rows in set. Elapsed: 0.005 sec.
可以看出,实时视图并没有 data_path,这表明实时视图也是逻辑上的视图,没有真实的物理数据文件存储。
查询实时视图数据
执行 WATCH 命令查询实时视图的结果:
WATCH clickhouse_tutorial.user_tag_lv
Query id: 19fdeea5-37ea-4f9e-be44-78e09c88370a
┌─userCnt─┬─age─┬───────date─┬─_version─┐
│ 1184 │ 26 │ 2014-03-20 │ 1 │
│ 4152 │ 55 │ 2014-03-18 │ 1 │
...
│ 1215 │ 26 │ 2014-03-17 │ 1 │
│ 3156 │ 22 │ 2014-03-23 │ 1 │
│ 2676 │ 39 │ 2014-03-22 │ 1 │
│ 14598 │ 0 │ 2014-03-22 │ 1 │
└─────────┴─────┴────────────┴──────────┘
↑ Progress: 42.00 rows, 798.00 B (119.82 rows/s., 2.28 KB/s.)
本次查询终端交互并没有结束,而是一直在等待状态。
实时视图数据查询过程
查看 Server 端 WATCH 命令执行日志。如下:
2022.03.24 01:57:47.152500 [ 3019212 ] {} TCP-Session: 1be6eef3-3954-4f71-8c2e-a8bad379a01c Creating query context from session context, user_id: 94309d50-4f52-5250-31bd-74fecac179db, parent context user: default
2022.03.24 01:57:47.153355 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} executeQuery: (from 127.0.0.1:53712) watch clickhouse_tutorial.user_tag_lv
2022.03.24 01:57:47.153505 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} ContextAccess (default): Access granted: SELECT(userCnt, age, date) ON clickhouse_tutorial.user_tag_lv
2022.03.24 01:57:47.154471 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} InterpreterSelectQuery: FetchColumns -> WithMergeableState
2022.03.24 01:57:47.154585 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) (SelectExecutor): Key condition: unknown
2022.03.24 01:57:47.154713 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) (SelectExecutor): MinMax index condition: unknown
2022.03.24 01:57:47.155447 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) (SelectExecutor): Selected 44/44 parts by partition key, 44 parts by primary key, 2169/2169 marks by primary key, 2169 marks to read from 44 ranges
2022.03.24 01:57:47.156206 [ 3019212 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} clickhouse_tutorial.user_tag (daf4def5-8bdc-4185-9674-3d406a37889a) (SelectExecutor): Reading approx. 17747796 rows with 6 streams
2022.03.24 01:57:47.162806 [ 2268693 ] {19fdeea5-37ea-4f9e-be44-78e09c88370a} AggregatingTransform: Aggregating
…
可以看出,实时视图数据查询背后走的源头表的数据查询。
插入数据查看视图更新
执行如下 INSERT 语句,向视图源头表user_tag中插入数据:
INSERT INTO clickhouse_tutorial.user_tag (UserID, WatchID, EventTime, Sex, Age, OS, RegionID, RequestNum, EventDate) VALUES (2042690798151930621, 4611692230555590277, ‘2014-03-17 12:10:17’, 0, 26, 56, 104, 2, ‘2014-03-17’)
紧接着看到 WATCH 终端输出了如下内容:
…
↘ Progress: 42.00 rows, 798.00 B (170.83 rows/s., 3.25 KB/s.)
┌─userCnt─┬─age─┬───────date─┬─_version─┐
│ 1184 │ 26 │ 2014-03-20 │ 2 │
│ 4152 │ 55 │ 2014-03-18 │ 2 │
…
│ 1216 │ 26 │ 2014-03-17 │ 2 │
│ 3156 │ 22 │ 2014-03-23 │ 2 │
│ 2676 │ 39 │ 2014-03-22 │ 2 │
│ 14598 │ 0 │ 2014-03-22 │ 2 │
└─────────┴─────┴────────────┴──────────┘
↙ Progress: 84.00 rows, 1.60 KB (0.70 rows/s., 13.34 B/s.) (0.0 CPU, 5.66 MB RAM)Exception on client:
Code: 32. DB::Exception: Attempt to read after eof: while receiving packet from 127.0.0.1:9009. (ATTEMPT_TO_READ_AFTER_EOF)
Connecting to 127.0.0.1:9009 as user default.
Code: 210. DB::NetException: Connection refused (127.0.0.1:9009). (NETWORK_ERROR)
我们注意到变更数据导致输出结果的变化,原来的数据行:
┌─userCnt─┬─age─┬───────date─┬─_version─┐
│ 1215 │ 26 │ 2014-03-17 │ 1 │
变成了新的数据行:
┌─userCnt─┬─age─┬───────date─┬─_version─┐
│ 1216 │ 26 │ 2014-03-17 │ 2 │
userCnt数字增加了 1,由 1215变成了1216,版本号version 由 1变成了 2。
不过,当前实时视图还在实验测试阶段,功能性能上都可能还存在 Bug。笔者在WATCH clickhouse_tutorial.user_tag_lv的同时,进行表数据 INSERT 操作的过程中(使用 DataGrip 客户端Console界面),发生了“Code: 32. DB::Exception: Attempt to read after eof”报错,同时也导致了 ClickHouseServer (version 22.4.1.1)端 Abort 中断了进程实例。核心报错信息如下:
ClickHouse客户端:Received exception from server (version 22.4.1):
Code: 49. DB::Exception: Received from 127.0.0.1:9009. DB::Exception: Unexpected thread state 2: void DB::ThreadStatus::setupState(const DB::ThreadGroupStatusPtr &). (LOGICAL_ERROR)
ClickHouse服务端:CurrentThread: DB::CurrentThread::QueryScope::~QueryScope(): Code: 49. DB::Exception: Unexpected thread state 2: void DB::ThreadStatus::detachQuery(bool, bool). (LOGICAL_ERROR)
重试多次依然发生,可见是一个 Bug,这里记录下 Server 端的报错信息:
2022.03.24 02:20:45.987821 [ 3184787 ] {} CurrentThread: DB::CurrentThread::QueryScope::~QueryScope(): Code: 49. DB::Exception: Unexpected thread state 2: void DB::ThreadStatus::detachQuery(bool, bool). (LOGICAL_ERROR), Stack trace (when copying this message, always include the lines below):
(version 22.4.1.1)
2022.03.24 02:20:45.988248 [ 3184787 ] {} HTTP-Session: 1b397b7b-3509-4dff-b6e7-8453a74f117a Destroying named session ‘DataGrip_de2dc84b-3fbf-47d7-ba1c-7e3e5f3b39b9’ of user 94309d50-4f52-5250-31bd-74fecac179db
2022.03.24 02:20:45.988357 [ 3183961 ] {} BaseDaemon: Received signal -1
2022.03.24 02:20:45.988436 [ 3183961 ] {} BaseDaemon: (version 22.4.1.1, no build id) (from thread 3184787) Terminate called for uncaught exception:
2022.03.24 02:20:45.988490 [ 3183961 ] {} BaseDaemon: Code: 49. DB::Exception: Unexpected thread state 2: void DB::ThreadStatus::detachQuery(bool, bool). (LOGICAL_ERROR), Stack trace (when copying this message, always include the lines below):
2022.03.24 02:20:45.988597 [ 3183961 ] {} BaseDaemon:
2022.03.24 02:20:45.988647 [ 3183961 ] {} BaseDaemon:
2022.03.24 02:20:45.988689 [ 3183961 ] {} BaseDaemon: (version 22.4.1.1)
2022.03.24 02:20:45.988733 [ 3183961 ] {} BaseDaemon: Received signal 6
2022.03.24 02:20:45.988976 [ 3185719 ] {} BaseDaemon: ########################################
2022.03.24 02:20:45.990570 [ 3185719 ] {} BaseDaemon: (version 22.4.1.1, no build id) (from thread 3184787) (no query) Received signal Abort trap: 6 (6)
2022.03.24 02:20:45.991603 [ 3185719 ] {} BaseDaemon:
2022.03.24 02:20:45.991674 [ 3185719 ] {} BaseDaemon: Stack trace: 0x7fff2049b462
2022.03.24 02:20:45.991733 [ 3185719 ] {} BaseDaemon: 0. 0x7fff2049b462
2022.03.24 02:20:52.689286 [ 3184017 ] {} DNSResolver: Updating DNS cache
2022.03.24 02:20:52.689782 [ 3184017 ] {} DNSResolver: Updated DNS cache
…
zsh: abort clickhouse server
窗口视图
窗口视图(WindowView)可以按时间窗口聚合数据,并在窗口准备启动时输出结果。窗口视图将部分聚合结果存储在内部(或指定)表中,以减少延迟,并可以使用WATCH查询将处理结果推送到指定表或推送通知。
语法
创建窗口视图
CREATE WINDOW VIEW[IF NOT EXISTS] [db.]table_name
[TO [db.]table_name]
[ENGINE = engine]
[WATERMARK = strategy]
[ALLOWED_LATENESS = interval_function]
AS SELECT …
GROUP BY time_window_function
查询窗口视图数据
WATCH [db.]window_view
功能说明
创建窗口视图类似于创建物化视图MATERIALIZED VIEW,需要内部存储引擎来存储中间数据。内部存储将使用AggregatingMergeTree作为默认引擎。
关键参数说明如下:
1.ALLOWED_LATENESS = interval_function,区间函数。
2.WATERMARK = strategy,水印策略。窗口视图提供了三种水印策略:
a.STRICTLY_ASCENDING:发出迄今为止观察到的最大时间戳的水印。时间戳小于最大时间戳的行不会延迟。
b.ASCENDING:发出迄今为止观察到的最大时间戳减1的水印。时间戳等于或小于最大时间戳的行不会延迟。
c.BOUNDED:WATERMARK=INTERVAL。发出水印,即观察到的最大时间戳减去指定的延迟。
3.time_window_function,时间窗口函数,主要有滚动函数tumble(time_attr, interval [, timezone])和跳跃函数hop(time_attr, hop_interval, window_interval [, timezone])。窗口视图需要与时间窗口函数一起使用。
适用场景
窗口视图适用于在如下典型场景:
1.监控场景:按时间聚合和计算metrics日志,并将结果输出到目标表。仪表板(dashboard)可以将目标表用作源表。
2.分析场景:在时间窗口内自动聚合和预处理数据。这在分析大量日志时很有用。预处理消除了多个查询中的重复计算,并减少了查询延迟。
窗口视图(Window View)是一个实验性的功能,启用窗口视图需要设置参数SETallow_experimental_window_view = 1。
实例讲解
创建窗口视图
设置如下参数,开启窗口视图功能:
SET allow_experimental_window_view = 1
然后,执行如下 SQL 创建窗口视图user_tag_wv:
CREATE WINDOW VIEW clickhouse_tutorial.user_tag_wv AS
SELECT
uniqExact(UserID) AS userCnt,
tumbleStart(w_id) AS window_start
FROM clickhouse_tutorial.user_tag
GROUP BY tumble(EventTime, toIntervalSecond('10')) AS w_id
同样地,去系统表system.tables查看视图user_tag_wv详情:
SELECT *
FROM system.tables
WHERE (database = 'clickhouse_tutorial') AND (name = 'user_tag_wv')
FORMAT Vertical
Query id: fbf0bd9a-e826-49d5-b0ec-511f1ef1f405
Row 1:
──────
database: clickhouse_tutorial
name: user_tag_wv
uuid: 8507f16a-adaf-43a8-8416-f9b16f82ffdf
engine: WindowView
is_temporary: 0
data_paths: []
metadata_path: /Users/data/clickhouse/store/1e0/1e031223-783a-48a9-9f32-1a719033081b/user_tag_wv.sql
metadata_modification_time: 2022-03-24 04:03:33
dependencies_database: []
dependencies_table: []
create_table_query: CREATE WINDOW VIEW clickhouse_tutorial.user_tag_wv (`userCnt` UInt64, `window_start` DateTime) AS SELECT uniqExact(UserID) AS userCnt, tumbleStart(w_id) AS window_start FROM clickhouse_tutorial.user_tag GROUP BY tumble(EventTime, toIntervalSecond('10')) AS w_id
engine_full:
as_select: SELECT uniqExact(UserID) AS userCnt, tumbleStart(w_id) AS window_start FROM clickhouse_tutorial.user_tag GROUP BY tumble(EventTime, toIntervalSecond('10')) AS w_id
partition_key:
sorting_key:
primary_key:
sampling_key:
storage_policy:
total_rows: ????
total_bytes: ????
lifetime_rows: ????
lifetime_bytes: ????
comment:
has_own_data: 0
loading_dependencies_database: []
loading_dependencies_table: []
loading_dependent_database: []
loading_dependent_table: []
1 rows in set. Elapsed: 0.004 sec.
查询窗口视图数据
执行 WATCH 查询窗口视图:
WATCH clickhouse_tutorial.user_tag_wv
WATCH 命令执行没有结束,而是在等待中。
插入数据查看视图更新
我们分别执行 2次数据插入 SQL:
INSERT INTO clickhouse_tutorial.user_tag(UserID, WatchID, EventTime, Sex, Age, OS, RegionID, RequestNum, EventDate) VALUES
(2042690798151930622, 4611692230555590278, now(), 0, 0, 56, 104, 2, toDate(now()));
INSERT INTO clickhouse_tutorial.user_tag(UserID, WatchID, EventTime, Sex, Age, OS, RegionID, RequestNum, EventDate) VALUES
(1745382628175606281, 4611703724436325474, now(), 2, 22, 42, 3, 107, toDate(now())),
(1266642432311731534, 4611720374393200609, now(), 2, 16, 42, 13962, 49, toDate(now())),
(1080523977390906965, 4611724822782888722, now(), 2, 16, 56, 15887, 13, toDate(now()));
可以看到WATCH 查询窗口视图结果的更新输出如下:
WATCH clickhouse_tutorial.user_tag_wv
Query id: ee6cd866-103f-48e9-b3fc-8216934e960c
┌─userCnt─┬────────window_start─┐
│ 1 │ 2022-03-24 04:19:20 │
└─────────┴─────────────────────┘
↗ Progress: 3.00 rows, 36.00 B (0.01 rows/s., 0.09 B/s.)
┌─userCnt─┬────────window_start─┐
│ 3 │ 2022-03-24 04:20:20 │
└─────────┴─────────────────────┘
↘ Progress: 4.00 rows, 48.00 B (0.01 rows/s., 0.10 B/s.)
1.1.9.创建函数
ClickHouse支持使用 lambda 表达式简洁方便地创建用户自定义函数。
语法
CREATE FUNCTION name AS (parameter0, …) -> expression
功能说明
使用lambda表达式创建用户定义函数(UDF,User Defined Function)。表达式可由函数参数、常量、运算符或其他函数调用等组成(不支持递归调用自己)。
函数入参(parameter0, …)支持多个参数。
另外,函数名称不能跟已有用户自定义函数和系统函数名冲突。
实例讲解
创建函数
创建一个区间范围计算函数:
CREATE FUNCTIONuserCntCalculate AS (x)-> multiIf(x > 10000, ‘high’, (x < 10000) AND (x > 8000), ‘mid’, ‘low’)
Query id: c944d3ef-ecdc-4a27-a21e-aa96887a9c7a
查看 Server 端日志,可以看到创建用户自定义函数的执行过程:
2022.03.24 14:28:15.989892 [ 3372013 ] {} TCP-Session: 872a56df-4e02-4275-8260-f15a546e8327 Creating query context from session context, user_id: 94309d50-4f52-5250-31bd-74fecac179db, parent context user: default
2022.03.24 14:28:15.990172 [ 3372013 ] {c944d3ef-ecdc-4a27-a21e-aa96887a9c7a} executeQuery: (from 127.0.0.1:53518) CREATE FUNCTION userCntCalculate AS (x) -> multiIf( x> 10000,‘high’, x<10000 and x>8000, ‘mid’, ‘low’ );
2022.03.24 14:28:15.990249 [ 3372013 ] {c944d3ef-ecdc-4a27-a21e-aa96887a9c7a} ContextAccess (default): Access granted: CREATE FUNCTION ON *.*
2022.03.24 14:28:15.990307 [ 3372013 ] {c944d3ef-ecdc-4a27-a21e-aa96887a9c7a} UserDefinedSQLObjectsLoader: Storing object `userCntCalculate` to file /Users/data/clickhouse/user_defined/function_userCntCalculate.sql
2022.03.24 14:28:15.990820 [ 3372013 ] {c944d3ef-ecdc-4a27-a21e-aa96887a9c7a} UserDefinedSQLObjectsLoader: Stored object `userCntCalculate`
2022.03.24 14:28:15.990892 [ 3372013 ] {c944d3ef-ecdc-4a27-a21e-aa96887a9c7a} MemoryTracker: Peak memory usage (for query): 0.00 B.
2022.03.24 14:28:15.990978 [ 3372013 ] {} TCPHandler: Processed in 0.001141 sec.
通过UserDefinedSQLObjectsLoader类把用户自定义函数 SQL 存储到文件/Users/data/clickhouse/user_defined/function_userCntCalculate.sql中。关于用户自定义函数的查询编译器逻辑在源代码InterpreterCreateFunctionQuery.cpp中,感兴趣的读者可以自行阅读。
验证函数名称必须唯一
我们重复执行上面的创建函数 SQL,可以看到函数名称必须唯一的报错提示:
Received exception from server (version 22.4.1):
Code: 609. DB::Exception: Received from 127.0.0.1:9009. DB::Exception: The function name ‘userCntCalculate’ is not unique. (FUNCTION_ALREADY_EXISTS)
使用函数计算结果
SELECT
uniqExact(UserID) AS userCnt,
Age,
userCntCalculate(userCnt) AS level
FROM clickhouse_tutorial.user_tag
GROUP BY Age
Query id: db00c8aa-ebac-4080-b82d-52e16faa72ac
Connecting to 127.0.0.1:9009 as user default.
Connected to ClickHouse server version 22.4.1 revision 54455.
┌─userCnt─┬─Age─┬─level─┐
│ 82405 │ 0 │ high │
│ 21066 │ 16 │ high │
│ 6556 │ 22 │ low │
│ 2130 │ 26 │ low │
│ 6282 │ 39 │ low │
│ 8311 │ 55 │ mid │
└─────────┴─────┴───────┘
6 rows in set. Elapsed: 0.148 sec. Processed 17.75 million rows, 159.73 MB (120.16 million rows/s., 1.08 GB/s.)
1.1.10.创建字典
ClickHouse 支持从数据源添加字典。字典的数据源可以是本地文本或可执行文件、HTTP(s) 资源或其他 DBMS。字典数据存储在内存RAM 中。字典数据会定期更新,支持动态加载。
语法
CREATE [OR REPLACE] DICTIONARY [IF NOT EXISTS] [db.]dictionary_name [ON CLUSTER cluster]
(
key1 type1 [DEFAULT|EXPRESSION expr1] [IS_OBJECT_ID],
key2 type2 [DEFAULT|EXPRESSION expr2],
attr1 type2 [DEFAULT|EXPRESSION expr3] [HIERARCHICAL|INJECTIVE],
attr2 type2 [DEFAULT|EXPRESSION expr4] [HIERARCHICAL|INJECTIVE]
)
PRIMARY KEY key1, key2
SOURCE(SOURCE_NAME([param1 value1 ... paramN valueN]))
LAYOUT(LAYOUT_NAME([param_name param_value]))
LIFETIME({MIN min_val MAX max_val | max_val})
SETTINGS(setting_name = setting_value, setting_name = setting_value, ...)
COMMENT 'Comment'
功能说明
根据给定的数据源(SOURCE)、数据结构布局(LAYOUT)、生命周期(LIFETIME)、参数设置(SETTINGS)等创建外部扩展字典。ON CLUSTER是在集群上创建字典。
实例讲解
创建字典源表
create table clickhouse_tutorial.user_sex_dim (
code UInt8,
name String
) engine = MergeTree
order by code
向源表中插入数据
INSERT INTO clickhouse_tutorial.user_sex_dim (code, name) VALUES (0, '未知');
INSERT INTO clickhouse_tutorial.user_sex_dim (code, name) VALUES (1, '男');
INSERT INTO clickhouse_tutorial.user_sex_dim (code, name) VALUES (2, '女');
创建字典表
CREATE DICTIONARY clickhouse_tutorial.user_sex_dict
(
`code` UInt64,
`name` String
)
PRIMARY KEY code
SOURCE(CLICKHOUSE(HOST 'localhost' PORT '9009' USER 'default' PASSWORD '7Dv7Ib0g' DB 'clickhouse_tutorial' TABLE 'user_sex_dim'))
LIFETIME(MIN 0 MAX 1000)
LAYOUT(FLAT())
COMMENT 'The user sex dictionary'
Query id: 05e8e713-1db0-4f00-a24d-c1882107ba8f
Ok.
0 rows in set. Elapsed: 0.003 sec.
其中,SOURCE中的CLICKHOUSE源表数据中配置了HOST 、PORT 、USER 、PASSWORD 、DB、TABLE 等属性值。
创建字典的Server 端日志为:
2022.03.24 18:57:55.641900 [ 3372013 ] {} TCP-Session: a8737b8c-25cc-4e7b-a927-41634b151425 Creating query context from session context, user_id: 94309d50-4f52-5250-31bd-74fecac179db, parent context user: default
2022.03.24 18:57:55.642067 [ 3372013 ] {05e8e713-1db0-4f00-a24d-c1882107ba8f} executeQuery: (from 127.0.0.1:52855) CREATE DICTIONARY clickhouse_tutorial.user_sex_dict ( code UInt64, name String ) PRIMARY KEY code SOURCE( CLICKHOUSE( HOST ‘localhost’ PORT ‘9009’ USER ‘default’ PASSWORD ‘7Dv7Ib0g’ DB ‘clickhouse_tutorial’ TABLE ‘user_sex_dim’ ) ) LAYOUT(FLAT()) LIFETIME(MIN 0 MAX 1000) COMMENT ‘The user sex dictionary’;
2022.03.24 18:57:55.642178 [ 3372013 ] {05e8e713-1db0-4f00-a24d-c1882107ba8f} ContextAccess (default): Access granted: CREATE DICTIONARY ON clickhouse_tutorial.user_sex_dict
2022.03.24 18:57:55.643007 [ 3372013 ] {05e8e713-1db0-4f00-a24d-c1882107ba8f} ExternalDictionariesLoader: Loading config file ‘44abd580-4b73-458c-b3e1-a2087ce934e8’.
2022.03.24 18:57:55.644788 [ 3372013 ] {05e8e713-1db0-4f00-a24d-c1882107ba8f} MemoryTracker: Peak memory usage (for query): 0.00 B.
2022.03.24 18:57:55.644875 [ 3372013 ] {} TCPHandler: Processed in 0.003025 sec.
核心处理逻辑源码在ExternalDictionariesLoader.cpp中。
去系统表system.dictionaries中查看字典user_sex_dict的详情,如下:
SELECT *
FROM system.dictionaries
WHERE (name = 'user_sex_dict') AND (database = 'clickhouse_tutorial')
FORMAT Vertical
Query id: a2572b20-7573-4806-b9d4-5b32bb70407d
Row 1:
──────
database: clickhouse_tutorial
name: user_sex_dict
uuid: 44abd580-4b73-458c-b3e1-a2087ce934e8
status: NOT_LOADED
origin: 44abd580-4b73-458c-b3e1-a2087ce934e8
type:
key.names: ['code']
key.types: ['UInt64']
attribute.names: ['name']
attribute.types: ['String']
bytes_allocated: 0
query_count: 0
hit_rate: 0
found_rate: 0
element_count: 0
load_factor: 0
source:
lifetime_min: 0
lifetime_max: 0
loading_start_time: 1970-01-01 08:00:00
last_successful_update_time: 1970-01-01 08:00:00
loading_duration: 0
last_exception:
comment: The user sex dictionary
1 rows in set. Elapsed: 0.003 sec.
查询字典数据
执行如下 SQL 查询字典数据:
SELECT
code,
name
FROM clickhouse_tutorial.user_sex_dict
Query id: 814662d1-7a36-4191-9356-9732f7cf2588
┌─code─┬─name─┐
│ 0 │ 未知 │
│ 1 │ 男 │
│ 2 │ 女 │
└──────┴──────┘
3 rows in set. Elapsed: 0.002 sec.
使用获取字典值函数
可以使用内置函数dictGetString() 获取字典值:
SELECT
code,
dictGetString(‘clickhouse_tutorial.user_sex_dict’, ‘name’, code) AS SexName
FROM clickhouse_tutorial.user_sex_dict
Query id: 073f56e6-a912-4e93-943d-3e92e2fa9b73
┌─code─┬─SexName─┐
│ 0 │ 未知 │
│ 1 │ 男 │
│ 2 │ 女 │
└──────┴─────────┘
3 rows in set. Elapsed: 0.002 sec.
在查询中使用字典
SELECT
uniqExact(UserID) AS userCnt,
Sex,
dictGetString(‘clickhouse_tutorial.user_sex_dict’, ‘name’, Sex) AS SexName
FROM clickhouse_tutorial.user_tag
GROUP BY Sex
Query id: 13c61349-0933-4c17-8311-dfba90031c57
┌─userCnt─┬─Sex─┬─SexName─┐
│ 84566 │ 0 │ 未知 │
│ 21796 │ 1 │ 男 │
│ 17816 │ 2 │ 女 │
└─────────┴─────┴─────────┘
3 rows in set. Elapsed: 0.108 sec. Processed 17.75 million rows, 159.73 MB (164.08 million rows/s., 1.48 GB/s.)
删除字典
删除字典使用 drop dictionary 命令:
drop dictionary clickhouse_tutorial.user_sex_dict;
1.1.11.RENAME****操作
语法
RENAME DATABASE|TABLE|DICTIONARY name TO new_name [,…] [ON CLUSTER cluster]
功能说明
重命名数据库
RENAME DATABASE atomic_database1 TO atomic_database2 [,…] [ON CLUSTER cluster]
重命名一个或多个数据库。
重命名表
RENAME TABLE [db1.]name1 TO [db2.]name2 [,…] [ON CLUSTER cluster]
重命名一个或多个表。 重命名表是一项轻量级的操作。
重命名字典
RENAME DICTIONARY [db0.]dict_A TO [db1.]dict_B [,…] [ON CLUSTER cluster]
重命名一个或多个字典。此查询可用于在数据库之间移动字典。
实例讲解
重命名两张表
把table_A重命名为table_A_bak, table_B重命名为table_B_bak, SQL如下:
RENAME TABLE table_A TO table_A_bak, table_B TO table_B_bak
1.1.12.ALTER 操作
ALTER变更表结构 操作
使用ALTERTABLE操作变更表结构。目前,ALTER仅支持 *MergeTree ,Merge以及Distributed等表引擎。语法如下:
ALTER TABLE [db].table_name [ON CLUSTER cluster] ADD|DROP|RENAME|CLEAR|COMMENT|{MODIFY|ALTER}|MATERIALIZE COLUMN …
其中,ALTER变更表结构。支持如下操作:
1.ADD COLUMN:添加列
2.DROP COLUMN:删除列
3.CLEAR COLUMN:重置列的值
4.COMMENT COLUMN:给列增加注释说明
5.MODIFY COLUMN:改变列的值类型,默认表达式以及TTL
增加列
语法
ALTER TABLE [db].table_name [ON CLUSTER cluster]
ADD COLUMN [IF NOT EXISTS] name [type] [default_expr] [codec] [AFTER name_after]
功能说明
使用指定的列名name, 列数据类型type, 编码codec 以及默认值表达式default_expr等,向表中增加新的列。添加列只改变原有表的结构,不会对已有数据产生影响。如果查询表时列的数据为空,那么ClickHouse会使用列的默认值来进行填充。如果有默认值表达式,则使用默认值表达式的值。
实例讲解
例如,给表clickhouse_tutorial.user_tag中新增一个字段 City,类型为 String,字段位置放到 Age 的后面,SQL实例如下:
alter tableclickhouse_tutorial.user_tag add column City String after Age;
删除列
语法
ALTER TABLE [db].table_name [ON CLUSTER cluster]
DROP COLUMN [IF EXISTS] name
功能说明
删除指定 name列。该操作会从文件系统中删除该列数据。如果语句包含 IF EXISTS,执行时遇到不存在的列也不会报错。
实例讲解
例如,删除表clickhouse_tutorial.user_tag中的字段 City,SQL实例如下:
alter tableclickhouse_tutorial.user_tag dropcolumn City
清空列
语法
ALTER TABLE [db].table_name [ON CLUSTER cluster]
CLEAR COLUMN [IF EXISTS] name IN PARTITION partition_name
功能说明
重置对应列和分区的所有值。注意:key 值列不能被清空。例如,EventTime 是user_tag表中的排序键:
CREATE TABLE clickhouse_tutorial.user_tag
(
`UserID` UInt64,
`WatchID` UInt64,
`EventTime` DateTime,
`Sex` UInt8,
`Age` UInt8,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date,
PROJECTION pOS
(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID
(
SELECT
count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SETTINGS index_granularity = 8192
执行如下 SQL清空EventTime 列数据会报如下错误:
ALTER TABLE clickhouse_tutorial.user_tag
CLEAR COLUMN EventTime IN PARTITION ‘2022-03-24’
Received exception from server (version 22.4.1):
Code: 524. DB::Exception: Received from 127.0.0.1:9009. DB::Exception: Trying to ALTER DROP key EventTime column which is a part of key expression. (ALTER_OF_COLUMN_IS_FORBIDDEN)
实例讲解
清空一个不是 key 值列RequestNum 的数据:
alter table clickhouse_tutorial.user_tag
clear column RequestNum IN PARTITION ‘2022-03-24’;
执行完成之后,我们再次查询’2022-03-24’分区的数据,可以发现RequestNum(UInt32类型) 的数据均为UInt32类型的默认值 0。
添加注释
语法
ALTER TABLE [db].table_name [ON CLUSTER cluster]
COMMENT COLUMN [IF EXISTS] name ‘comment’
功能说明
给列增加注释说明。每个列都可以包含注释。如果列的注释已经存在,新的注释会替换旧的。
实例讲解
例如,给UserID字段添加注释’用户 ID’, SQL实例如下:
alter table clickhouse_tutorial.user_tag comment column UserID ‘用户 ID’;
修改列
语法
ALTER TABLE [db].table_name [ON CLUSTER cluster]
MODIFY COLUMN [IF EXISTS] name [type] [default_expr] [codec][TTL]
功能说明
修改 name 列的属性。支持以下列属性的修改:
数据类型:type
默认值表达式:default_expr
数据存活时间:TTL
字段数据压缩算法:codec
实例讲解
改变列的类型
当改变列的类型时,列的值也被转换了。SQL示例:
ALTER TABLE clickhouse_tutorial.user_tag
MODIFY COLUMN `OS` String
改变列的数据类型,也就改变了数据文件的内容,这是一个性能损耗极大的复杂型动作。对于大型表,执行起来要花费较长的时间,会耗费大量 CPU 来进行数据计算。该操作分为如下处理步骤:
1.为修改的数据准备新的临时文件;
2.重命名原来的文件;
3.将新的临时文件改名为原来的数据文件名;
4.删除原来的文件。
第一步会耗时较久。如果该阶段执行失败,那么数据没有变化。如果执行后续的步骤中失败了,数据可以手动恢复。但是存在异常情况,例如已经执行完第 4 步:原来的文件已经从文件系统中被删除。此时,新数据没有写入到临时文件中,那么新数据丢失。
在分布式 ClickHouse 集群中,ALTER列操作的行为是可以被复制的,ALTER指令会保存在ZooKeeper中,然后分发到每个副本节点执行。所有的 ALTER 将按相同的顺序执行。
修改列TTL
修改RequestNum 列TTL 为分区EventDate日期向后一个月。SQL 语句如下:
ALTER TABLE clickhouse_tutorial.user_tag
MODIFY COLUMN
RequestNum UInt32 TTL EventDate + INTERVAL 1 MONTH
执行完上面的 SQL,对应EventDate分区中过期的RequestNum 数据都被清 0。
添加采样
语法
ALTER TABLE [db].name [ON CLUSTER cluster] MODIFY SAMPLE BY new_expression
功能说明
添加采样表达式。
实例讲解
给表user_tag添加采样,以字段 UserID 进行采样:
ALTER TABLE clickhouse_tutorial.user_tag
MODIFY SAMPLE BY UserID
Query id: 950fdcd4-5620-4224-b324-306a9017a74d
Ok.
0 rows in set. Elapsed: 0.011 sec.
查看建表 SQL:
SHOW CREATE TABLE clickhouse_tutorial.user_tag
Query id: 669f450b-e71a-4a8f-b046-d84b62e515f8
CREATE TABLE clickhouse_tutorial.user_tag
(
`UserID` UInt64,
`WatchID` UInt64,
`EventTime` DateTime,
`Sex` UInt8,
`Age` UInt8,
`OS` UInt8,
`RegionID` UInt32,
`RequestNum` UInt32,
`EventDate` Date,
PROJECTION pOS
(
SELECT
groupBitmap(UserID),
count(1)
GROUP BY OS
),
PROJECTION pRegionID
(
SELECT
count(1),
groupBitmap(UserID)
GROUP BY RegionID
)
)
ENGINE = MergeTree
PARTITION BY EventDate
ORDER BY (WatchID, UserID, EventTime)
SAMPLE BY UserID
SETTINGS index_granularity = 8192
1 rows in set. Elapsed: 0.001 sec.
ALTER 操作注意点
使用 ALTER 变更表结构操作,有如下几点需要特别注意:
1.ALTER 操作不支持对primary key或者sampling key中的列(在 ENGINE 表达式中用到的列)进行删除操作。
2.修改包含在primary key中的列的类型时,如果操作不会导致数据的变化(例如,将DateTime 类型改成 UInt32),那么这种操作是可行的。
3.如果 ALTER 操作不能满足需求,可以创建一张新的表,通过 INSERT SELECT语句,将数据拷贝进去,然后通过 RENAME将新的表改成和原有表一样的名称,并删除原有的表。
4.ALTER操作会阻塞对表的所有读写操作。换句话说,当一个大的 SELECT 语句和 ALTER同时执行时,ALTER会等待,直到 SELECT 执行结束。与此同时,当 ALTER 运行时,新的SQL语句将会等待。
ALTER分区数据操作
数据分区
ClickHouse在建表时使用PARTITION BY子句,指定分区表达式对数据进行分区(partition)。例如,通过toYYYYMM()将数据按月进行分区、toMonday()将数据按照周几进行分区、对Enum类型的列直接每种取值作为一个分区等。也可以指定多级分区。
数据分区在ClickHouse中主要有两方面应用:
1、在分区键partition key上进行分区裁剪,只查询必要的数据。灵活的分区设置,使得可以根据SQL Pattern进行分区设置,最大化的贴合业务特点。
2、对分区进行TTL管理,淘汰过期的分区数据。
数据 Part 概念
MergeTree表数据是按part来存储,一次性写入的数据或者数据量达到一定量级时会单独成为一个part。关于数据 part 简单说明如下:
1.part在内部被逻辑上拆分成granule(颗粒)最小逻辑单元,一个granule默认是8192 行,也即稀疏索引粒度,该值可以在建表时设置SETTINGS index_granularity = 8192。
2.part在物理上被划分成三类文件:.idx, .mrk, .bin文件。
3.idx文件存储了每个granule的第一行的primary key以及该pk对应的mrk文件的序号。
4.mrk文件存储了每个granule所有行的每个column的数据存储在bin文件中的起始位置。
5.bin文件中存储了实际的column数据。
可以到系统表system.parts中查看 part 详情信息:
SELECT *
FROM system.parts
LIMIT 1
FORMAT Vertical
Query id: 49fd7a1c-0710-4b66-a283-2ca7cb94f2aa
Row 1:
──────
partition: 2014-03-17
name: 20140317_7_99_5
uuid: 00000000-0000-0000-0000-000000000000
part_type: Compact
active: 1
marks: 2
rows: 617
bytes_on_disk: 619
data_compressed_bytes: 492
data_uncompressed_bytes: 6787
marks_bytes: 112
secondary_indices_compressed_bytes: 0
secondary_indices_uncompressed_bytes: 0
secondary_indices_marks_bytes: 0
modification_time: 2022-03-29 02:53:40
remove_time: 1970-01-01 08:00:00
refcount: 1
min_date: 2014-03-17
max_date: 2014-03-17
min_time: 1970-01-01 08:00:00
max_time: 1970-01-01 08:00:00
partition_id: 20140317
min_block_number: 7
max_block_number: 99
level: 5
data_version: 7
primary_key_bytes_in_memory: 6
primary_key_bytes_in_memory_allocated: 8192
is_frozen: 0
database: clickhouse_tutorial
table: .inner_id.1c93ef11-704f-4515-9596-fbdb4efdf6b8
engine: MergeTree
disk_name: default
path: /Users/data/clickhouse/store/2b4/2b4de01f-12f8-443e-97aa-53ecd1aa49a5/20140317_7_99_5/
hash_of_all_files: 6712fc8502457d2bda140a0d5646408d
hash_of_uncompressed_files: 22917348009482fd4c19d95a67de310d
uncompressed_hash_of_compressed_files: 44085f5d9d357e8068a803ce3134875b
delete_ttl_info_min: 1970-01-01 08:00:00
delete_ttl_info_max: 1970-01-01 08:00:00
move_ttl_info.expression: []
move_ttl_info.min: []
move_ttl_info.max: []
default_compression_codec: LZ4
recompression_ttl_info.expression: []
recompression_ttl_info.min: []
recompression_ttl_info.max: []
group_by_ttl_info.expression: []
group_by_ttl_info.min: []
group_by_ttl_info.max: []
rows_where_ttl_info.expression: []
rows_where_ttl_info.min: []
rows_where_ttl_info.max: []
projections: []
1 rows in set. Elapsed: 0.012 sec.
ALTER 分区操作
ALTER分区操作命令如下表。
分区操作命令
语法
功能说明
实例讲解
DETACH PARTITION
ALTER TABLE table_name DETACH PARTITION|PART partition_expr
将分区移动到分离目录。将指定分区的所有数据移动到分离目录。在进行 ATTACH 查询之前,无法查询此数据。
ALTER TABLE mt DETACH PARTITION ‘2020-11-21’;ALTER TABLE mt DETACH PART ‘all_2_2_0’;
DROP PARTITION
ALTER TABLE table_name DROP PARTITION|PART partition_expr
删除分区。从表中删除指定的分区。此查询将分区标记为非活动并完全删除数据,大约在 10 分钟内。
ALTER TABLE mt DROP PARTITION ‘2020-11-21’;ALTER TABLE mt DROP PART ‘all_4_4_0’;
ATTACH PART|PARTITION
ALTER TABLE table_name ATTACH PARTITION|PART partition_expr
将数据从分离的目录添加到表中。
ALTER TABLE visits ATTACH PARTITION 201901;ALTER TABLE visits ATTACH PART 201901_2_2_0;
ATTACH PARTITION FROM
ALTER TABLE table2 ATTACH PARTITION partition_expr FROM table1
将数据分区从一个表复制到另一个表并添加。将数据分区从 table1 复制到 table2。要使查询成功运行,必须满足以下条件:1、两个表必须具有相同的结构。2、两个表必须具有相同的分区键。
ALTER TABLE table2 ATTACH PARTITION 201901 FROM table1
REPLACE PARTITION
ALTER TABLE table2 REPLACE PARTITION partition_expr FROM table1
将数据分区从一个表复制到另一个表并进行替换。此查询将 table1 中的数据分区复制到 table2 并替换 table2 中的现有分区。数据不会从 table1 中删除。要使查询成功运行,必须满足以下条件:1、两个表必须具有相同的结构。2、两个表必须具有相同的分区键。
ALTER TABLE table2 REPLACE PARTITION 201901 FROM table1
MOVE PARTITION TO TABLE
ALTER TABLE table_source MOVE PARTITION partition_expr TO TABLE table_dest
将数据分区从一个表移动到另一个表。此查询通过从table_source删除数据将数据分区从table_source移动到table_dest。要成功运行查询,必须满足以下条件:1、两个表必须具有相同的结构。2、两个表必须具有相同的分区键。3、两个表必须是相同的引擎族(复制的或非复制的)。4、两个表必须具有相同的存储策略。
ALTER TABLE t1 MOVE PARTITION 201901 TO TABLE t2
CLEAR COLUMN IN PARTITION
ALTER TABLE table_name CLEAR COLUMN column_name IN PARTITION partition_expr
重置分区中指定列中的所有值。如果在创建表时确定了 DEFAULT 子句,则此查询将列值设置为指定的默认值。
ALTER TABLE visits CLEAR COLUMN hour in PARTITION 201902
CLEAR INDEX IN PARTITION
ALTER TABLE table_name CLEAR INDEX index_name IN PARTITION partition_expr
重置分区中指定的索引数据。该查询的工作方式类似于 CLEAR COLUMN,但它重置索引而不是列数据。
ALTER TABLE t1 CLEAR INDEX UserID IN PARTITION 201902
FREEZE PARTITION
ALTER TABLE table_name FREEZE [PARTITION partition_expr] [WITH NAME ‘backup_name’]
创建指定分区的本地备份。如果省略 PARTITION 子句,则查询会立即创建所有分区的备份。整个备份过程在不停止服务器的情况下执行。FREEZE PARTITION 操作只复制数据,不复制表元数据。要备份表元数据,请复制文件 ./clickhouse/metadata/database/table.sql 。要从备份中恢复数据,请执行以下操作:1、如果表不存在,则创建它。使用 table.sql 文件(将其中的 ATTACH 替换为 CREATE)。2、将备份里面的 data/database/table/目录下的数据复制到./clickhouse/data/database/table/detached/目录下。3、运行 ALTER TABLE t ATTACH PARTITION 查询以将数据添加到表中。从备份恢复不需要停止服务器。
ALTER TABLE t FREEZE PARTITION 201902 WITH NAME ‘t_201902_backup’
UNFREEZE PARTITION
ALTER TABLE ‘table_name’ UNFREEZE [PARTITION ‘part_expr’] WITH NAME ‘backup_name’
删除分区的备份。从磁盘中删除具有指定名称的冻结分区。如果省略 PARTITION 子句,则查询会立即删除所有分区的备份。
ALTER TABLE t UNFREEZE PARTITION 201902 WITH NAME ‘t_201902_backup’
FETCH PARTITION|PART
ALTER TABLE table_name FETCH PARTITION|PART partition_expr FROM ‘path-in-zookeeper’
从另一台服务器下载部件或分区。从另一台服务器下载分区。此查询仅适用于复制表。查询执行以下操作:
1、从指定的分片下载分区|part。
2、然后将下载的数据放到 table_name 表的detach分离目录中。
3、使用 ATTACH PARTITION|PART 操作将数据添加到表中。其中,“path-in-zookeeper”是 ZooKeeper 分片的路径。
ALTER TABLE t FETCH PARTITION 201902 FROM ‘/clickhouse/tables/01-08/visits/replicas’
MOVE PARTITION|PART
ALTER TABLE table_name MOVE PARTITION|PART partition_expr TO DISK|VOLUME ‘disk_name’
将分区或数据部分移动到 MergeTree 引擎表的另一个磁盘或卷。当某个表存在“热”和“冷”数据时,它可能很有用。如果有多个磁盘可用,“热”数据可以放到快速磁盘(例如,SSD 或内存中)上,而“冷”数据放到相对较慢的磁盘(例如,HDD)上。数据 Part 是 MergeTree 引擎表的最小可移动单元。
磁盘、卷和存储策略可以在主配置文件 config.xml 或 config.d 目录中的独立文件中的
ALTER TABLE hits MOVE PART ‘20190301_14343_16206_438’ TO VOLUME 'slow’ALTER TABLE hits MOVE PARTITION ‘2019-09-01’ TO DISK ‘fast_ssd’
UPDATE IN PARTITION
ALTER TABLE [db.]table UPDATE column1 = expr1 [, …] [IN PARTITION partition_id] WHERE filter_expr
按条件更新分区内的数据。
ALTER TABLE mt UPDATE x = x + 1 IN PARTITION 2 WHERE p = 2;
DELETE IN PARTITION
ALTER TABLE [db.]table DELETE [IN PARTITION partition_id] WHERE filter_expr
按条件删除分区内的数据。
ALTER TABLE mt DELETE IN PARTITION 2 WHERE p = 2;
ClickHouse多盘存储配置
ClickHouseMergeTree 表引擎可以使用多个块设备进行数据存储,其存储原理就是把存储划分为包含多个设备的卷,并在其之间自动移动数据,也称之为多卷存储(Multi-Volume Storage)。多卷存储原理架构图如下:
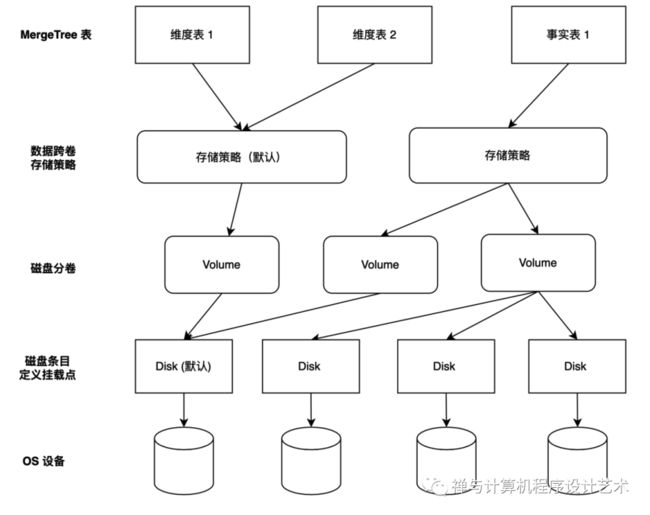
多卷存功能很有用,其中,最重要的用途是将冷热数据分别存储在不同类型的存储上,这种配置叫做分层存储(tiered storage)。正确地使用分层存储可以极大地提高ClickHouse的经济性。关于多卷存储可以参考下面这两篇文章:
https://altinity.com/blog/2019/11/27/amplifying-clickhouse-capacity-with-multi-volume-storage-part-1https://altinity.com/blog/2019/11/29/amplifying-clickhouse-capacity-with-multi-volume-storage-part-2
关于 MergeTree表引擎配置多存储设备参考:
https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree
另外,ClickHouse 服务器存储数据磁盘的信息,存在系统表system.disks中。SQL 如下:
SELECT *
FROM system.disks
FORMAT Vertical
Query id: 321523d6-fcc8-4b4d-9152-05f7ed1b0434
Row 1:
──────
name: default
path: /Users/data/clickhouse/
free_space: 207388188672
total_space: 499963174912
keep_free_space: 0
type: local
1 rows in set. Elapsed: 0.002 sec.
1.1.13.DROP****操作
前面我们讲了创建数据库、表、视图、 函数、用户、角色、行策略、Quota 配额、Profile配置等数据模型的定义。如果想要删除这些定义,使用 DROP 命令操作。
使用 DROP 命令可用删除现有数据模型定义。如果实体不存在,DROP操作报错;如果想要不报错,指定“IF EXISTS”子句。常用 DROP 命令清单如下表。
DROP 命令
语法
功能说明
DROP DATABASE
DROP DATABASE [IF EXISTS] db [ON CLUSTER cluster]
删除 db 数据库中的所有表,然后删除 db 数据库本身。
DROP TABLE
DROP [TEMPORARY] TABLE [IF EXISTS] [db.]name [ON CLUSTER cluster]
删除表。
DROP DICTIONARY
DROP DICTIONARY [IF EXISTS] [db.]name
删除字典。
DROP USER
DROP USER [IF EXISTS] name [,…] [ON CLUSTER cluster_name]
删除用户。
DROP ROLE
DROP ROLE [IF EXISTS] name [,…] [ON CLUSTER cluster_name]
删除角色。已删除角色将从分配给它的所有实体中撤消。
DROP ROW POLICY
DROP [ROW] POLICY [IF EXISTS] name [,…] ON [database.]table [,…] [ON CLUSTER cluster_name]
删除行策略。已从分配它的所有实体中撤销已删除的行策略。
DROP QUOTA
DROP QUOTA [IF EXISTS] name [,…] [ON CLUSTER cluster_name]
删除配额。已删除的配额将从分配它的所有实体中撤消。
DROP PROFILE
DROP [SETTINGS] PROFILE [IF EXISTS] name [,…] [ON CLUSTER cluster_name]
删除配置Profile。已删除的配置Profile将从分配它的所有实体中撤消。
DROP VIEW
DROP VIEW [IF EXISTS] [db.]name [ON CLUSTER cluster]
删除视图。视图也可以通过 DROP TABLE 命令删除,但 DROP VIEW 会检查 [db.]name 是否是视图。
DROP FUNCTION
DROP FUNCTION [IF EXISTS] function_name
删除由 CREATE FUNCTION创建的用户定义函数。不能删除系统内置函数。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦