从零开始设计键值数据库(KEY-VALUE STORE)
本文主要参考 System Design Interview: An Insider’s Guide(CHAPTER 6)
键值存储(key-value store),也被称为键值数据库(key-value database),是一个非关系型数据库。每一个独特的标识符都被存储为一个带有相关值的键。这种数据配对被称为 "键-值 "对。 在一个键值对中,键必须是唯一的,与键相关的值可以通过键来访问。键可以是纯文本或散列值。出于性能方面的考虑,短键的效果更好。键是什么样子的?这里有几个例子:
• Plain text key: “last_logged_in_at”
• Hashed key: 253DDEC4
键值对中的值可以是字符串、列表、对象等。在键值存储中,值通常被视为不透明的对象,如Amazon dynamo , Memcached , Redis , 等等。
下面是一个键值存储的数据片段:

你需要设计一个支持以下操作的键值存储。
-
put(key, value) // insert “value” associated with “key”
-
get(key) // get “value” associated with “key”
了解问题并确定设计范围
没有完美的设计。每种设计都会在读、写和内存使用的权衡方面达到特定的平衡。另一个必须做出的权衡是在一致性和可用性之间。我们希望设计了一个包括以下特点的键值存储:
-
一个键值对的大小很小:小于10KB。
-
有能力存储大数据。
-
高可用性。系统响应迅速,即使在故障期间也是如此。
-
高可扩展性。系统可以被扩展以支持大型数据集。
-
自动扩展。服务器的增加/删除应该是基于流量的自动。
-
可调整的一致性。
-
低延迟。
单服务器kv存储
开发一个部署在单个服务器中的键值存储很容易。一个直观的方法是将键值对存储在一个哈希表中,这样可以将所有东西都保存在内存中。尽管内存访问速度很快,但由于空间的限制,把所有东西都放在内存中可能是不可能的。有两种优化方法可以用来在单个服务器中容纳更多的数据:
-
数据压缩
-
只在内存中存储经常使用的数据,其余的存储在磁盘上
即使有这些优化,单个服务器也会很快达到其容量。需要一个分布式键值存储来支持海量数据。
分布式kv存储
分布式键值存储也被称为分布式哈希表,它将键值对分布在许多服务器上。在设计分布式系统时,理解CAP(Consistency一致性、Availability可用性、Partition Tolerance分区容忍度)理论很重要。
CAP 理论
CAP理论指出,一个分布式系统不可能同时提供这三种保证中的两种以上:一致性、可用性和分区容忍度。让我们建立几个定义。
一致性:一致性意味着所有客户在同一时间看到相同的数据,无论他们连接到哪个节点。
可用性:可用性意味着任何请求数据的客户端都能得到响应,即使有些节点发生了故障。
分区容忍度:分区表示两个节点之间的通信中断。 分区容忍度意味着尽管网络分区,系统仍能继续运行。
CAP理论指出,必须牺牲三个属性中的一个来支持三个属性中的两个,如图6-1所示。
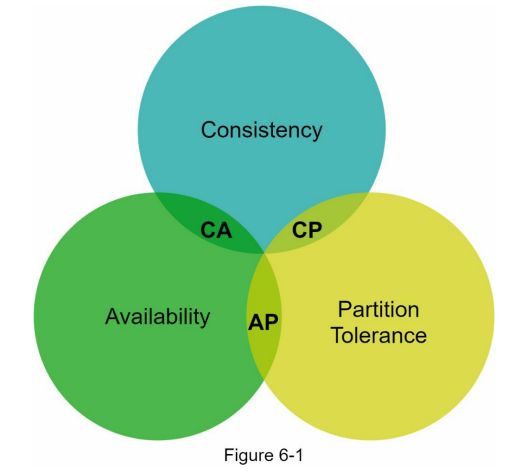
现在,键值存储是根据它们支持的两个CAP特性来分类的。
CP(一致性和分区容忍)系统:CP键值存储支持一致性和分区容忍,同时牺牲了可用性。
AP(可用性和分区容忍度)系统:一个AP键值存储支持可用性和分区容忍度,同时牺牲了一致性。
CA(一致性和可用性)系统:CA键值存储支持一致性和可用性,同时牺牲了分区容忍度。由于网络故障是不可避免的,一个分布式系统必须容忍网络分区。因此,CA系统不能存在于现实世界的应用中。
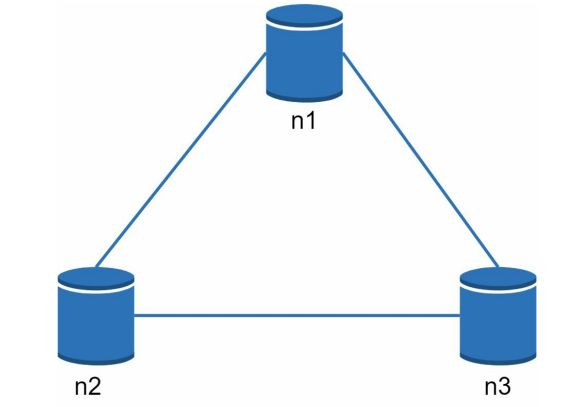
你在上面读到的主要是定义部分。为了使它更容易理解,让我们看一下一些具体的例子。在分布式系统中,数据通常被多次复制。假设数据被复制在三个复制节点上,如图6-2所示,n1、n2和n3。
理想情况
在理想的世界里,网络分区永远不会发生。写入n1的数据会自动复制到n2和n3。这就实现了一致性和可用性。
真实的分布式系统
在一个分布式系统中,分区是无法避免的,当分区发生时,我们必须在一致性和可用性之间做出选择。在图6-3中,n3发生故障,无法与n1和n2通信。如果客户端向n1或n2写数据,数据就不能传播到n3。如果数据被写入n3,但还没有传播到n1和n2,n1和n2就会有陈旧的数据。
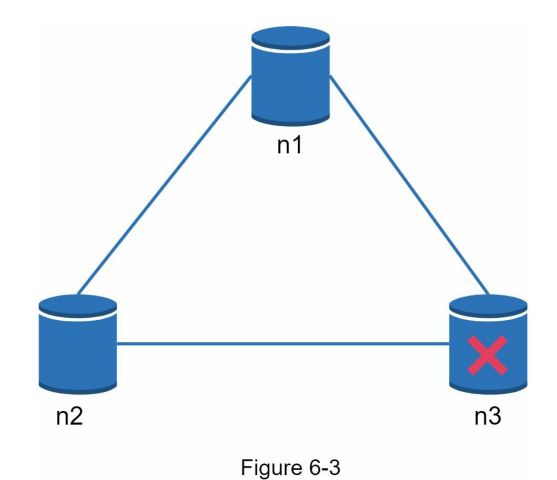
如果我们选择一致性大于可用性(CP系统),我们必须阻止对n1和n2的所有写操作,以避免这三个服务器之间的数据不一致,这使得系统不可用。银行系统通常有极高的一致性要求。例如,对银行系统来说,显示最新的余额信息是至关重要的。如果由于网络分区而发生不一致,在不一致问题解决之前,银行系统会返回一个错误。
然而,如果我们选择可用性大于一致性(AP系统),系统就会一直接受读取,即使它可能返回陈旧的数据。对于写,n1和n2将继续接受写,当网络分区解决后,数据将被同步到n3。 选择适合你使用情况的正确CAP保证是建立分布式键值存储的一个重要步骤。
系统组件
我们将讨论以下用于构建键值存储的核心组件和技术。
- 数据分区
- 数据复制
- 一致性
- 不一致的解决
- 故障处理
- 系统架构图
- 写入流程
- 读取流程
下面的内容主要是基于三个流行的键值存储系统。Dynamo、Cassandra和BigTable。
数据分区
对于大型应用来说,将完整的数据集装入一台服务器是不可行的。实现这一目标的最简单方法是将数据分成较小的分区,并将其存储在多个服务器中。在对数据进行分区时,有两个挑战。
- 将数据均匀地分布在多个服务器上。
- 当节点被添加或移除时,最大限度地减少数据移动
一致性hash是解决这些问题的一个很好的技术。
-
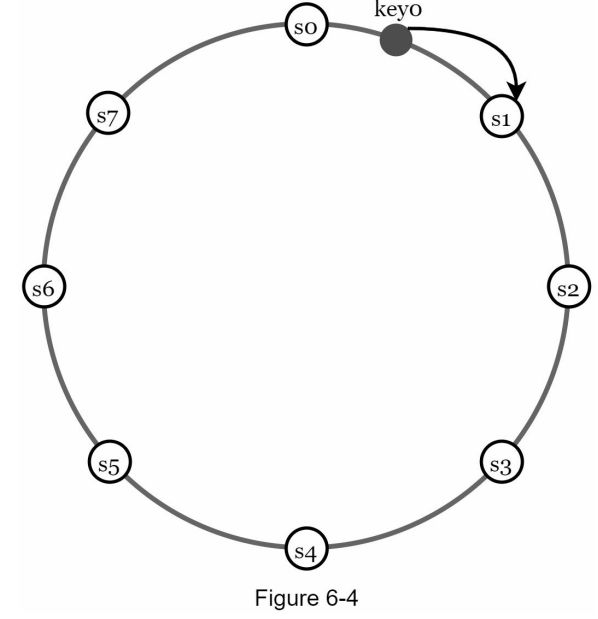
首先,服务器被放置在一个哈希环上。在图 6-4 中,由 s0、s1、…、s7 表示的八个服务器被放置在哈希环上。
-
接下来,将key散列到同一个环上,并存储在顺时针方向移动时遇到的第一个服务器上。例如,key0 使用此逻辑存储在 s1 中。
使用一致性哈希对数据进行分区具有以下优点:
- 自动扩展:可以根据负载自动添加和删除服务器。
- 异构性:服务器的虚拟节点数量与服务器容量成正比。例如,容量更高的服务器分配有更多的虚拟节点。
数据复制
为了实现高可用性和可靠性,数据必须在N个服务器上进行异步复制,其中N是一个可配置参数。这N个服务器的选择采用以下逻辑:在一个key被映射到哈希环上的某个位置后,从该位置顺时针走,选择环上的前N个服务器来存储数据副本。在图6-5(N=3)中,key0被复制在s1、s2和s3。
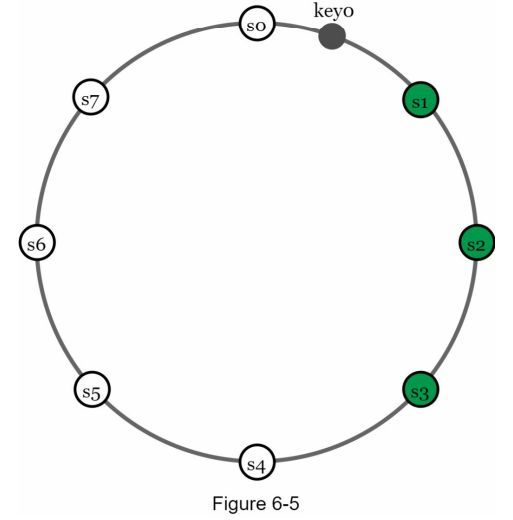
对于虚拟节点,环上的前N个节点可能由少于N个物理服务器拥有。为了避免这个问题,我们在执行顺时针行走逻辑时只选择唯一的服务器。 由于停电、网络问题、自然灾害等原因,同一数据中心的节点经常在同一时间发生故障。为了提高可靠性,副本被放置在不同的数据中心,并且数据中心通过高速网络连接。
一致性
由于数据在多个节点上复制,因此必须跨副本同步。 Quorum 共识可以保证读写操作的一致性。让我们首先建立一些定义。
N = 副本数
W = 大小为 W 的写入仲裁。要使写入操作被视为成功,必须从 W 个副本确认写入操作。
R = 大小为 R 的读取仲裁。要使读取操作被视为成功,读取操作必须等待至少 R 个副本的响应。
考虑下图 6-6 中 N = 3 的示例。
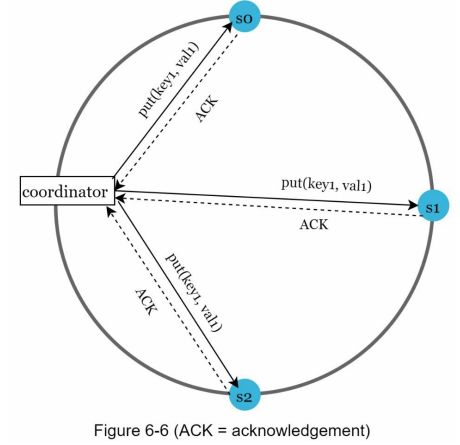
W = 1并不意味着数据被写入了一台服务器。例如,在图6-6的配置中,数据是在s0、s1和s2复制的。W = 1意味着协调器必须在写操作被认为是成功之前收到至少一个确认。例如,如果我们从s1得到一个确认,我们就不再需要等待s0和s2的确认了。协调器在客户端和节点之间充当代理角色
W、R和N的配置是一个典型的延迟和一致性之间的权衡。如果W = 1或R = 1,一个操作就会快速返回,因为协调者只需要等待任何一个副本的响应。如果W或R > 1,系统提供更好的一致性;然而,查询会更慢,因为协调者必须等待最慢的副本的响应。
如果W + R > N,强一致性得到保证,因为必须至少有一个重叠节点拥有最新的数据以保证一致性。
如何配置N、W和R以适应我们的使用情况?下面是一些可能的设置。
如果R = 1,W = N,系统被优化为快速读取。
如果W = 1,R = N,系统被优化为快速写入。
如果W + R > N,强一致性得到保证(通常N = 3,W = R = 2)。
如果W + R <= N,强一致性就得不到保证。
根据需求,可以调整W、R、N的值,以达到所需的一致性水平
一致性模型
一致性模型是设计键值存储时需要考虑的其他重要因素。一致性模型定义了数据的一致性程度,存在着广泛的可能的一致性模型。
- 强一致性:任何读操作都会返回一个与最新的写数据项的结果相对应的值。客户端永远不会看到过期的数据。
- 弱一致性:后续的读操作可能看不到最新的值。
- 最终一致性:这是弱一致性的一种特殊形式。只要有足够的时间,所有的更新都会被传播,所有的副本都是一致的。
强一致性通常是通过强迫一个副本不接受新的读/写,直到每个副本都同意当前的写来实现。这种方法对于高可用系统来说并不理想,因为它可能会阻止新的操作。Dynamo和Cassandra采用最终一致性,这是我们推荐的键值存储的一致性模型。从并发写入来看,最终一致性允许不一致的值进入系统,并迫使客户端读取这些值来进行调节。下一节将解释调和如何与版本管理一起工作。
不一致的解决:版本化
复制提供了高可用性,但会导致副本之间的不一致。版本化和向量锁用于解决不一致问题。版本化意味着将每个数据修改视为新的不可变数据版本。在讨论版本化之前,让我们通过一个例子来解释不一致是如何发生的: 如图 6-7 所示,副本节点 n1 和 n2 具有相同的值。让我们将此值称为原始值。服务器 1 和服务器 2 获取相同的 get(“name”) 操作值

接下来,服务器 1 将名称更改为“johnSanFrancisco”,服务器 2 将名称更改为“johnNewYork”,如图 6-8 所示。这两个变化是同时进行的。现在,我们有冲突的值,称为版本 v1 和 v2。

在这个例子中,原始值可以被忽略,因为修改是基于它的。然而,没有明确的方法来解决最后两个版本的冲突。为了解决这个问题,我们需要一个可以检测冲突和调和冲突的版本系统。矢量时钟是解决这个问题的一个常用技术。让我们研究一下矢量时钟是如何工作的。
矢量时钟是一个与数据项相关的[server, version]对。它可以用来检查一个版本是否先于、成功或与其他版本冲突。
假设一个矢量钟用D([S1, v1], [S2, v2], …, [Sn, vn])表示,其中D是一个数据项,v1是一个版本计数器,s1是一个服务器号码,等等。如果数据项D被写入服务器Si,系统必须执行以下任务之一。
- 如果[Si, vi]存在,则递增vi。
- 否则,创建一个新条目[Si, 1]。
如图6-9所示,用一个具体的例子来解释上述的抽象逻辑。
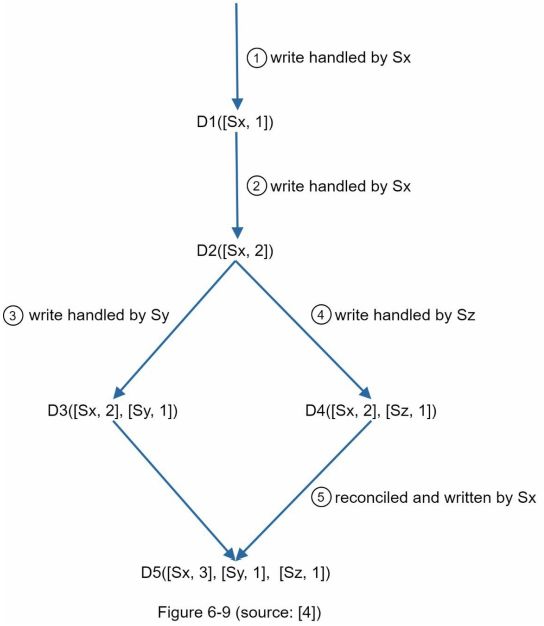
- 一个客户向系统写入一个数据项D1,该写入由服务器Sx处理,它现在拥有向量时钟D1[(Sx, 1)]。
- 另一个客户端读取最新的D1,将其更新为D2,并将其写回。D2是从D1更新得到的,所以它覆盖了D1。假设这个写是由同一个服务器Sx处理的,它现在有矢量时钟D2([Sx, 2])。
- 另一个客户端读取最新的D2,将其更新为D3,并将其写回。假设这个写是由服务器Sy处理的,它现在有向量时钟D3([Sx, 2], [Sy, 1])。
- 另一个客户端读取最新的D2,将其更新为D4,并将其写回。假设这个写是由服务器Sz处理的,它现在有D4([Sx, 2], [Sz, 1]))。
- 当另一个客户端读取D3和D4时,它发现了一个冲突,这是由于数据项D2被Sy和Sz修改所引起的。该冲突由客户端解决,更新的数据被发送到服务器。假设写入是由Sx处理的,它现在有D5([Sx, 3], [Sy, 1], [Sz, 1])。
使用矢量时钟,如果Y的矢量时钟中每个参与者的版本计数器大于或等于版本X中的计数器,就很容易知道版本X是版本Y的祖先(即没有冲突)。例如,矢量时钟D([s0, 1], [s1, 1])是D([s0, 1], [s1, 2])的祖先。因此,没有冲突被记录下来。
同样地,如果在Y的向量钟中有任何参与者的计数器小于X中的相应计数器,你就可以知道一个版本X是Y的兄弟姐妹(即存在冲突)。D([s0, 1], [s1, 2]) 和 D([s0, 2], [s1, 1])。
尽管矢量时钟可以解决冲突,但有两个明显的缺点。首先,矢量时钟增加了客户端的复杂性,因为它需要实现冲突解决逻辑。
第二,向量钟中的 [server:version] 对可能会迅速增长。为了解决这个问题,我们为长度设置了一个阈值,如果超过了这个阈值,最古老的对就会被删除。这可能会导致和解的效率低下,因为不能准确地确定子孙关系。然而,根据Dynamo论文[4],亚马逊还没有在生产中遇到这个问题;因此,对于大多数公司来说,这可能是一个可以接受的解决方案。
故障处理
与任何大规模的系统一样,故障不仅是不可避免的,而且是常见的。处理故障情况是非常重要的。本节首先介绍检测故障的技术。然后,介绍常见的故障解决策略。
故障检测
在一个分布式系统中,仅仅因为另一台服务器这么说,就认为一台服务器停机是不够的。通常情况下,至少需要两个独立的信息源来标记一个服务器停机。 如图6-10所示,全联通组播是一个直接的解决方案。然而,当系统中存在许多服务器时,这是不高效的。

更好的解决方案是使用分散式故障检测方法,如 gossip 协议。 Gossip 协议的工作原理如下:
-
每个节点维护一个节点成员列表,其中包含成员 ID 和心跳计数器。
-
每个节点定期增加其心跳计数器。
-
每个节点定期向一组随机节点发送心跳,这些节点依次传播到另一组节点。
-
一旦节点收到心跳,成员列表将更新为最新信息。
-
如果心跳没有增加超过预定义的时间,则该成员被视为离线。

如图6-11所示。
-
节点s0维护着左侧所示的节点成员列表。
-
节点s0注意到节点s2(成员ID=2)的心跳计数器已经很长时间没有增加了。
-
节点s0向一组随机节点发送包括s2的信息的心跳。一旦其他节点确认s2的心跳计数器长时间没有更新,节点s2就会被标记下来,并将这个信息传播给其他节点。
处理暂时性地故障
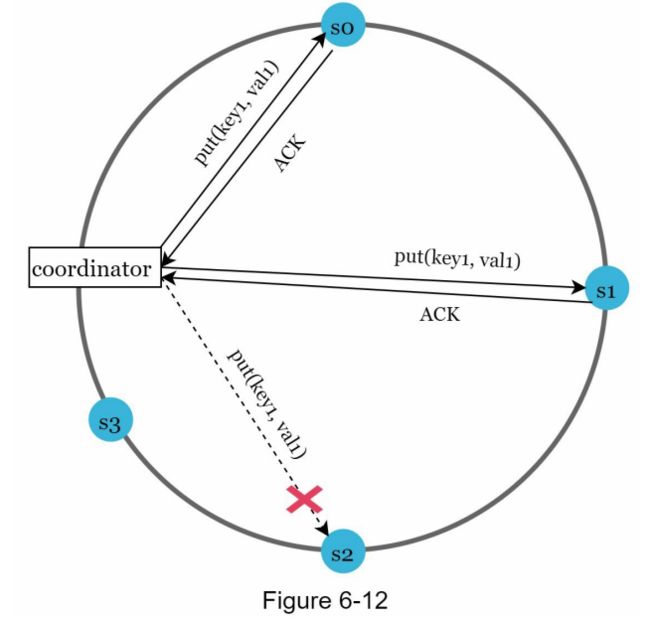
通过 gossip 协议检测到故障后,系统需要部署一定的机制来保证可用性。在严格的仲裁方法中,可以阻止读取和写入操作,如仲裁共识部分所示。一种称为“sloppy quorum”的技术用于提高可用性。系统没有强制执行法定人数要求,而是选择前 W 个健康的服务器进行写入,并选择前 R 个健康的服务器进行哈希环上的读取。离线服务器被忽略。如果由于网络或服务器故障导致服务器不可用,另一台服务器将临时处理请求。当宕机的服务器启动时,更改将被推回以实现数据一致性。这个过程称为提示切换(Hinted handoff)。由于图 6-12 中 s2 不可用,读写操作将暂时由 s3 处理。当 s2 重新上线时,s3 会将数据交还给 s2。
处理永久性故障
提示切换用于处理临时故障。如果副本永久不可用怎么办?为了处理这种情况,我们实现了一个反熵协议来保持副本同步。反熵涉及比较副本上的每条数据并将每个副本更新到最新版本。 Merkle 树用于不一致检测和最小化传输的数据量。
“哈希树或 Merkle 树是一种树,其中每个非叶节点都用其子节点的标签或值(如果是叶)的哈希值进行标记。哈希树允许对大型数据结构的内容进行有效和安全的验证”。
假设key空间从 1 到 12,以下步骤展示了如何构建 Merkle 树。突出显示的框表示不一致。
第 1 步:将key空间划分为桶(在我们的示例中为 4 个),如图 6-13 所示。桶用作根级节点以保持树的有限深度。
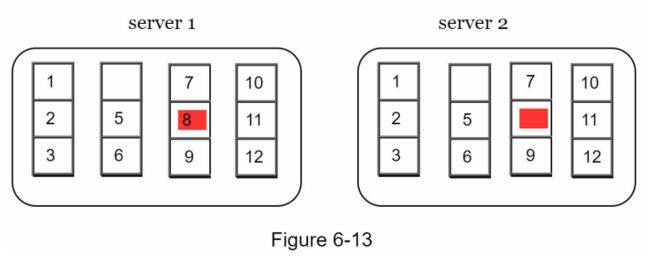
第 2 步:创建桶后,使用统一的散列方法对桶中的每个键进行散列(图 6-14)。

第 3 步:为每个桶创建一个哈希节点(图 6-15)。

第 4 步:通过计算子节点的哈希值向上构建树直到根节点(图 6-16)。

要比较两个Merkle树,首先要比较根哈希值。如果根哈希值匹配,则两个服务器有相同的数据。如果根哈希值不一致,那么就比较左边的子哈希值,然后是右边的子哈希值。你可以遍历树,找到哪些桶没有被同步,只同步这些桶。 使用Merkle树,需要同步的数据量与两个副本之间的差异成正比,而不是它们包含的数据量。在现实世界的系统中,桶的大小是相当大的。例如,一个可能的配置是每十亿个键有一百万个桶,所以每个桶只包含1000个键。
处理数据中心故障
数据中心中断可能由于停电、网络中断、自然灾害等原因发生。要构建能够处理数据中心中断的系统,跨多个数据中心复制数据非常重要。即使一个数据中心完全离线,用户仍然可以通过其他数据中心访问数据。
系统架构图
现在我们已经讨论了设计键值存储的不同技术考虑,我们可以将注意力转移到架构图上,如图 6-17 所示。

该架构的主要特点如下:
- 客户端通过简单的 API 与键值存储进行通信:get(key) 和 put(key, value)。
- 协调器是充当客户端和键值存储之间的代理的节点。
- 节点使用一致的散列分布在一个环上。
- 系统完全分散,因此可以自动添加和移动节点。
- 数据在多个节点上复制。
- 没有单点故障,因为每个节点都有相同的职责集。
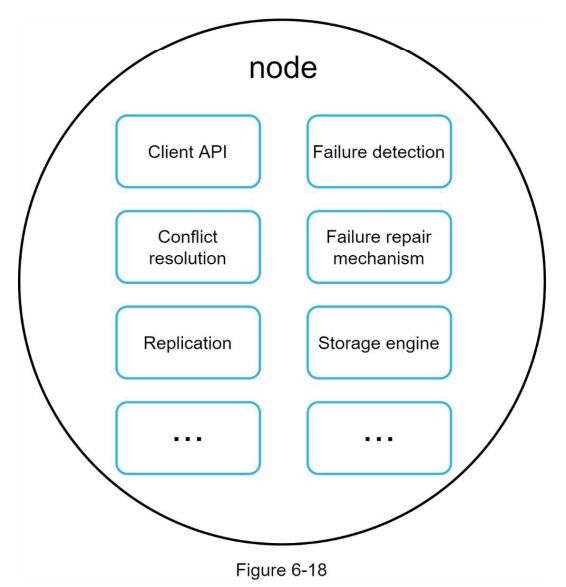
由于设计是去中心化的,每个节点执行许多任务,如图6-18所示。
写入流程
图6-19解释了在一个写请求被引导到一个特定的节点后会发生什么。请注意,建议的写/读路径的设计主要是基于Cassandra的架构。

- 写请求被持久化在一个提交日志文件中。
- 数据保存在内存缓存中。
- 当内存缓存已满或达到预定义的阈值时,数据被刷新到磁盘上的 SSTable。注意:排序字符串表 (SSTable) 是
读取流程
读取请求被引导到一个特定的节点后,它首先检查数据是否在内存缓存中。如果是,数据就会被返回给客户端,如图6-20所示。
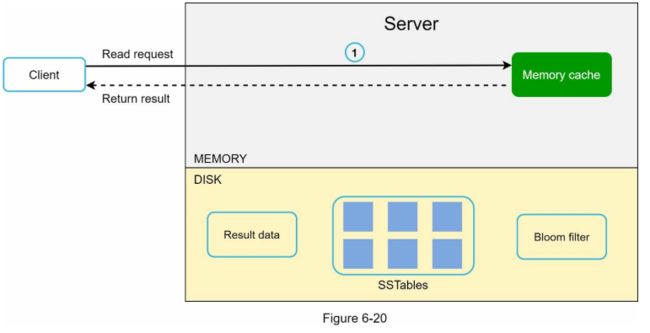
如果数据不在内存中,就会从磁盘中检索出来。我们需要一个有效的方法来找出哪个SSTable中包含key。布隆过滤器通常被用来解决这个问题。 当数据不在内存中时,其读取路径如图6-21所示。

- 系统首先检查数据是否在内存中。如果没有,则执行步骤 2。
- 如果数据不在内存中,则系统检查布隆过滤器。
- 布隆过滤器用于找出哪些 SSTables 可能包含key。
- SSTables 返回数据集的结果。
- 将数据集的结果返回给客户端。
总结
下表总结了分布式键值存储的特点和相应的技术。
| 目标/问题 | 技术 |
|---|---|
| 存储海量数据的能力 | 使用一致性哈希将数据分发给不同的服务器 |
| 高可靠读取 | 数据复制;多数据中心 |
| 高可靠写入 | 版本化和使用向量时钟解决冲突 |
| 数据分区 | 一致性哈希 |
| 增量可扩展性 | 一致性哈希 |
| 异构性 | 一致性哈希 |
| 可调节的一致性 | Quorun共识 |
| 处理暂时性故障 | Sloppy quorum和提示切换(hinted handoff) |
| 处理永久性故障 | Merkle树 |
| 处理数据中心故障 | 跨数据中心复制 |
如果大家对文章内容有疑问或建议,欢迎评论区留言,我们可以一起讨论,共同提高
转载请标明原作者:https://blog.csdn.net/qq_36622751