常用调试golang的bug以及性能问题的实践方法
文章目录
- 如何分析程序运行时间和CPU利用率情况
-
- 1.shell内置time指令
- /usr/bin/time指令
- 如何分析golang程序的内存使用情况?
-
- 1.内存占用情况查看
- 如何分析golang程序的CPU性能情况
-
- 1.性能分析注意事项
- 2.CPU性能分析
-
- A.Web界面查看
- B.使用pprof工具查看
如何分析程序运行时间和CPU利用率情况
1.shell内置time指令
time是Unix/linux内置多命令,使用时一般不用传过多参数,直接跟上需要调试多程序即可。
$ time go run test2.go
&{{0 0} 张三 0}
real 0m0.843s
user 0m0.216s
sys 0m0.389s
上面是使用time对 go run test2.go对执行程序坐了性能分析,得到3个指标。
● real:从程序开始到结束,实际度过的时间;
● user:程序在用户态度过的时间;
● sys:程序在内核态度过的时间。
一般情况下 real >= user + sys,因为系统还有其它进程(切换其他进程中间对于本进程会有空白期)
/usr/bin/time指令
这个指令比内置的time更加详细一些,使用的时候需要用绝对路径,而且要加上参数-v
$ /usr/bin/time -v go run test2.go
Command being timed: "go run test2.go"
User time (seconds): 0.12
System time (seconds): 0.06
Percent of CPU this job got: 115%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.16
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 41172
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 1
Minor (reclaiming a frame) page faults: 15880
Voluntary context switches: 897
Involuntary context switches: 183
Swaps: 0
File system inputs: 256
File system outputs: 2664
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
可以看到这里的功能要强大多了,除了之前的信息外,还包括了:
● CPU占用率;
● 内存使用情况;
● Page Fault 情况;
● 进程切换情况;
● 文件系统IO;
● Socket 使用情况;
● ……
如何分析golang程序的内存使用情况?
1.内存占用情况查看
package main
import (
"log"
"runtime"
"time"
)
func test() {
//slice 会动态扩容,用slice来做堆内存申请
container := make([]int, 8)
log.Println(" ===> loop begin.")
for i := 0; i < 32*1000*1000; i++ {
container = append(container, i)
}
log.Println(" ===> loop end.")
}
func main() {
log.Println("Start.")
test()
log.Println("force gc.")
runtime.GC() //强制调用gc回收
log.Println("Done.")
time.Sleep(3600 * time.Second) //睡眠,保持程序不退出
}
编译
$go build -o snippet && ./snippet
然后在./snippet进程没有执行完,我们再开一个窗口,通过top命令查看进程的内存占用情况
$top -p $(pidof snippet_mem)
结果如下:
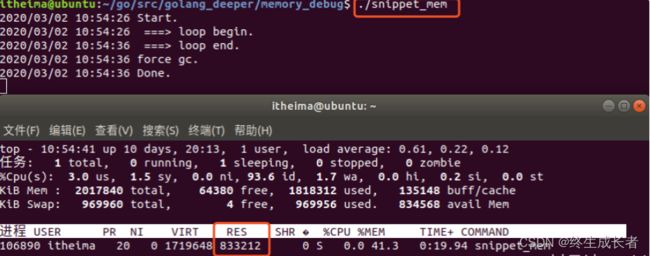
我们看出来,没有退出的snippet_mem进程有约830m的内存被占用。
直观上来说,这个程序在test()函数执行完后,切片contaner的内存应该被释放,不应该占用830M那么大。
结论:
1、在test()函数执行完后,demo程序中的切片容器所申请的堆空间都被垃圾回收器回收了。
2、如果此时在top指令查询内存的时候,如果依然是800+MB,说明垃圾回收器回收了应用层的内存后,(可能)并不会立即将内存归还给系统。
如何分析golang程序的CPU性能情况
1.性能分析注意事项
● 性能分析必须在一个
可重复的、稳定的环境中来进行。
○ 机器必须闲置
■ 不要在共享硬件上进行性能分析;
■ 不要在性能分析期间,在同一个机器上去浏览网页
○ 注意省电模式和过热保护,如果突然进入这些模式,会导致分析数据严重不准确
○ 不要使用虚拟机、共享的云主机,太多干扰因素,分析数据会很不一致;
○ 不要在 macOS 10.11 及以前的版本运行性能分析,有 bug,之后的版本修复了。
如果承受得起,购买专用的性能测试分析的硬件设备,上架。
● 关闭电源管理、过热管理;
● 绝不要升级,以保证测试的一致性,以及具有可比性。
如果没有这样的环境,那就一定要在多个环境中,执行多次,以取得可参考的、具有相对一致性的测试结果
2.CPU性能分析
利用以下代码进行测试:
package main
import (
"bytes"
"math/rand"
"time"
"log"
"net/http"
_ "net/http/pprof"
)
func test() {
log.Println(" ===> loop begin.")
for i := 0; i < 1000; i++ {
log.Println(genSomeBytes())
}
log.Println(" ===> loop end.")
}
//生成一个随机字符串
func genSomeBytes() *bytes.Buffer {
var buff bytes.Buffer
for i := 1; i < 20000; i++ {
buff.Write([]byte{'0' + byte(rand.Intn(10))})
}
return &buff
}
func main() {
go func() {
for {
test()
time.Sleep(time.Second * 1)
}
}()
//启动pprof
http.ListenAndServe("0.0.0.0:10000", nil)
}
这里面还是启动了pprof的监听,有关pprof启动的代码如下:
import (
"net/http"
_ "net/http/pprof"
)
func main() {
//...
//...
//启动pprof
http.ListenAndServe("0.0.0.0:10000", nil)
}
main()里的流程很简单,启动一个goroutine去无限循环调用test()方法,休眠1s.
test()的流程是生成1000个20000个字符的随机字符串.并且打印.
我们将上面的代码编译成可执行的二进制文件 demo4(记住这个名字,稍后我们能用到)
$ go build demo4.go
接下来我们启动程序,程序会无限循环的打印字符串.
接下来我们通过几种方式来查看进程的cpu性能情况.
A.Web界面查看
浏览器访问http://127.0.0.1:10000/debug/pprof/
我们会看到如下画面
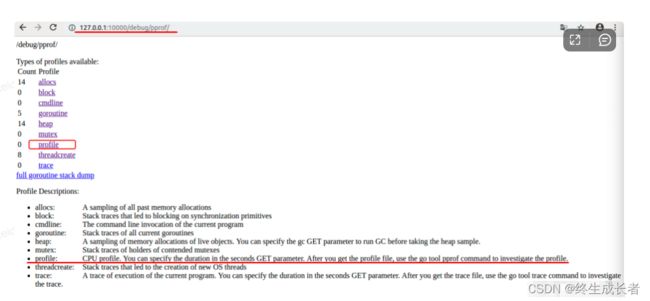
这里面能够通过pprof查看包括(阻塞信息、cpu信息、内存堆信息、锁信息、goroutine信息等等), 我们这里关心的cpu的性能的profile信息.
有关profile下面的英文解释大致如下:
“CPU配置文件。您可以在秒GET参数中指定持续时间。获取概要文件后,请使用go tool pprof命令调查概要文件。”
所以我们要是想得到cpu性能,就是要获取到当前进程的profile文件,这个文件默认是30s生成一个,所以你的程序要至少运行30s以上(这个参数也可以修改,稍后我们介绍)
我们可以直接点击网页的profile,浏览器会给我们下载一个profile文件. 记住这个文件的路径, 可以拷贝到与demo4所在的同一文件夹下.
B.使用pprof工具查看
pprof 的格式如下:
go tool pprof [binary] [profile]
binary: 必须指向生成这个性能分析数据的那个二进制可执行文件;
profile: 必须是该二进制可执行文件所生成的性能分析数据文件。
binary 和 profile 必须严格匹配。
我们来查看一下:
$ go tool pprof ./demo4 profile
File: demo4
Type: cpu
Time: Mar 3, 2020 at 11:18pm (CST)
Duration: 30.13s, Total samples = 6.27s (20.81%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
help可以查看一些指令,我么可以通过top来查看cpu的性能情况.
(pprof) top
Showing nodes accounting for 5090ms, 81.18% of 6270ms total
Dropped 80 nodes (cum <= 31.35ms)
Showing top 10 nodes out of 60
flat flat% sum% cum cum%
1060ms 16.91% 16.91% 2170ms 34.61% math/rand.(*lockedSource).Int63
850ms 13.56% 30.46% 850ms 13.56% sync.(*Mutex).Unlock (inline)
710ms 11.32% 41.79% 2950ms 47.05% math/rand.(*Rand).Int31n
570ms 9.09% 50.88% 990ms 15.79% bytes.(*Buffer).Write
530ms 8.45% 59.33% 540ms 8.61% syscall.Syscall
370ms 5.90% 65.23% 370ms 5.90% runtime.procyield
270ms 4.31% 69.54% 4490ms 71.61% main.genSomeBytes
250ms 3.99% 73.52% 3200ms 51.04% math/rand.(*Rand).Intn
250ms 3.99% 77.51% 250ms 3.99% runtime.memmove
230ms 3.67% 81.18% 690ms 11.00% runtime.suspendG
(pprof)
这里面有几列数据,需要说明一下.
● flat:当前函数占用CPU的耗时
● flat%::当前函数占用CPU的耗时百分比
● sum%:函数占用CPU的耗时累计百分比
● cum:当前函数加上调用当前函数的函数占用CPU的总耗时
● cum%:当前函数加上调用当前函数的函数占用CPU的总耗时百分比
● 最后一列:函数名称
通过结果我们可以看出, 该程序的大部分cpu性能消耗在 main.getSoneBytes()方法中,其中math/rand取随机数消耗比较大.