SSH Chapter 02 Oracle数据库应用
SSH Chapter 02 Oracle数据库应用 笔记
本章目标 :
- 会创建表空间
- 会创建用户并授权
- 掌握序列的使用方法
- 理解同义词的使用方法
- 了解索引,会创建常用索引
- 了解分区表
1. 表空间和用户权限管理
Oracle表空间是一个逻辑的概念,它在物理上是不存在的
1.1 表空间
从逻辑上看,一个数据库(database)下面可以分多个表空间(tablespace),一个表空间下可以分多个段(segment),一个表要占一个段,一个索引也要占一个段。一个段由多个区间(extent)组成,一个区间又有一组连续的数据块(data block)组成。这连续的数据库在逻辑上是连续的,有可能在物理磁盘上是分散的。
从物理上看,一个表空间由多个数据文件组成,数据文件是实实在在的磁盘上的文件,这些文件是由Oracle数据库操作系统的block组成的。
表空间属性:
一个数据库可以包含多个表空间,一个表空间只能属于一个数据库
一个表空间包含多个数据文件,一个数据文件只能属于一个表空间
1、表空间分类:
表空间可以分为三类:
| 类别 | 举例 | 说 明 |
|---|---|---|
| 永久性表空间 | SYSTEM,USERS | 一般保存表、视图、过程和索引等的数据 |
| 临时性表空间 | TEMP | 只用于保存系统中短期活动的数据 |
| 撤销表空间 | UNDO | 用来帮助回退未提交的事务数据 |
经验:
一般不需要建临时和撤销表空间,除非把它们转移其他磁盘中以提高性能
2、表空间的目的:
使用表空间的目的为:
1)对于不同用户分配不同的表空间,对不同的模式对象分配不同的表空间,方便对用户数据的操作,对模式对象的管理
2)可以将不同的数据文件创建到不同的磁盘中.有利用管理磁盘空间,有利于提高I/O性能,有利于备份和恢复数据库等.
一般在完成Oracle系统的安装并创建Oracle实例后,Oracle系统会自动建立多个表空间.
3、创建表空间:
创建表空间,语法如下:
CREATE TABLESPACE 表空间名
DATAFILE ‘数据文件路径’ [SIZE integer 大小]
[AUTOEXTEND [OFF|ON] ] ;
【说明】[]里面内容可选项;数据文件路径中若包含目录需要先创建
tablespacename 是需创建的表空间名称
DATAFILE 指定组成表空间的一个或者多个数据文件,当有多个数据文件时使用逗号分隔
SIZE为初始表空间大小,单位为K或者M
AUTOEXTEND 子句用来启用或禁用数据文件的自动扩展,设置ON则空间使用完毕会自动扩展,设置为OFF则和容易出现表空间剩余容量为0的使用情况,使数据不能存储到数据库中.
示例1:
创建一个自动增长的表空间tp_hr的SQL语句如下:
--推荐创建表空间示例
CREATE TABLESPACE tp_hr
DATAFILE 'd:\Oracle\tp_hr01.dbf'
SIZE 10M AUTOEXTEND ON;
4、查询表空间
-- 查看表空间
SELECT file_name,tablespace_name,bytes,autoextensible
FROM dba_data_files
WHERE tablespace_name='TP_HR';
5、修改表空间
【语法】
ALTER TABLESPACE 表空间名
ADD DATAFILE ‘文件路径’ SIZE 大小
[AUTOEXTEND ON] ;
示例2:
调整表空间大小:
--方法一:更改数据文件的大小
ALTER DATABASE DATAFILE
'd:\Oracle\tp_hr01.dbf'
RESIZE 20M;
--方法二:向表空间内添加数据文件
ALTER TABLESPACE tp_hr
ADD DATAFILE
'd:\Oracle\tp_hr02.dbf' SIZE 10M
AUTOEXTEND ON;
更改表空间状态为只读:
ALTER TABLESPACE tp_hr READ ONLY;
--查看表空间状态:
select tablespace_name,status from dba_tablespaces;
6、删除表空间
【语法】
DROP TABLESPACE 表空间名;
DROP TABLESPACE 表空间名 INCLUDING CONTENTS AND DATAFILES;
【说明】
第一个删除语句只删除表空间;第二个删除语句则删除表空间及数据文件
提示:删除表空间之前先备份
示例3:
删除表空间,代码如下:
-- 只删除表空间
DROP TABLESPACE tp_hr;
-- 删除表空间及数据文件
DROP TABLESPACE tp_hr INCLUDING CONTENTS AND DATAFILES;
返回顶部
1.2 自定义用户管理
当创建一个新的数据库时,Oracle 将创建一些默认数据库用户,如sys,system和scott等(注意Oracle 12c之后不再提供默认的scott用户),可以使用这些用户连接数据库.sys 和 system用户都是Oracle的系统用户,都使用SYSTEM表空间,而SYS拥有更大的权限,区别还有:
| SYS用户 | SYSTEM用户 | |
|---|---|---|
| 地位 | Oracle的一个超级用户 | Oracle默认的系统管理员,拥有DBA权限 |
| 作用 | 主要用来维护系统信息和管理实例 | 通常用来管理Oracle数据库的用户、权限和存储等 |
| 登录身份 | 只能以SYSDBA或SYSOPER角色登录 | 可以Normal方式登录,也可以以SYSDBA的方式登录(注意:仅限于本地服务器的本地用户) |
创建用户
Oracle内部有两个建好的用户:system和sys。用户可直接登录到system用户以创建其他用户,因为system具有创建别 的用户的 权限。 在安装oracle时,用户或系统管理员首先可以为自己建立一个用户。
语法[创建用户]:
create user 用户名 identified by 口令[即密码];
详细语法如下:
CREATE USER user_name
IDENTIFIED BY password
[ DEFAULT TABLESPACE tablespace]
[ TEMPORARY TABLESPACE tablespace]
[ QUOTA UNLIMITED ON tablespace ]
[ QUOTA integer [K|M] ON tablespace]
[ PASSWORD EXPIRE]
参数解释如下:
user_name是用户名password是密码DEFAULT TABLESPACE与TEMPORARY TABLESPACE为用户默认指定表空间和临时表空间PASSWORD EXPIRE- 可选的。 如果设置了此选项,则过期了以后必须重置密码,然后用户才能登录到Oracle数据库QUOTA UNLIMITED用户在表空间所分配的空间没有限制
示例4:
create user test identified by test;
示例5:
创建用户需要注意:1.为用户设置默认表空间 2.为用户分配磁盘限额
若不为用户创建表空间,oracle会使用users作为默认表空间,不易管理;
若不为用户分配磁盘限额,会导致操作数据失败.
CREATE USER A_hr IDENTIFIED BY 1234
DEFAULT TABLESPACE tp_hr
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON tp_hr
QUOTA 10M ON tp_bak ;
此CREATE USER语句将在Oracle数据库中创建一个名为A_hr的新用户,密码为:1234,默认表空间为tp_hr,配额为10MB,临时表空间为temp,在tp_hr的使用没有限制,但是在tp_bak表空间的使用只有10M。
如果想确保用户在登录数据库之前更改密码,可以按如下方式添加密码过期选项:
CREATE USER A_hr IDENTIFIED BY 1234
DEFAULT TABLESPACE tp_hr
TEMPORARY TABLESPACE temp
QUOTA UNLIMITED ON tp_hr
QUOTA 10M ON tp_bak
PASSWORD EXPIRE;
也可以使用第二种方式,代码如下:
/*
===========================================================
|| 第一次登录时需要修改密码
============================================================
*/
--方法二:先创建完用户,再根据要求进行修改
ALTER USER A_hr PASSWORD EXPIRE;
/*
===========================================================
|| 更改表空间中的用户限额
============================================================
*/
ALTER USER A_hr QUOTA 20M ON tp_bak;
查询A_hr用户
SELECT * FROM dba_users WHERE username='A_HR';
查看表空间限额
SELECT * FROM dba_ts_quotas WHERE username='A_HR';
修改用户
示例6
修改用户,语法如下:
alter user 用户名 identified by 口令[改变的口令];
例如:
alter user test identified by 123456;
删除用户
示例7:
删除用户:DROP USER 用户名 CASCADE
==DROP USER 命令可以删除用户,但当用户拥有模式对象时则无法删除用户,而必须使用CASCADE选项删除用户和用户模式对象.==代码如下:
DROP USER A_hr CASCADE;
理解oracle表空间,表,和用户的区别
- 每个项目对应一个表空间,Oracle数据库是通过表空间来存储物理表的,一个数据库实例可以有N个表空间,一个表空 间下可以有N张表。
- 然后创建一个用户对应此表空间即可。
- 所以,在做大型项目的时候,是先创建一个数据库实例,然后创建表空间,再创建用户,然后用户指定这个表空间
用户与表空间关系
- 用户=商家
- 表=商品
- 表空间=仓库
一个商家能有很多商品,1个商品只能属于一个商家。
一个商品可以放到仓库A,也可以放到仓库B,但不能同时放入A和B。
仓库不属于任何商家。
商家都有一个默认的仓库,如果不指定具体仓库,商品则放到默认的仓库中。
1.3 数据库权限管理
权限是用户对一项功能的执行权利。在Oracle中,根据系统管理方式的不同,可将权限分为为系统权限与对象权限两类.
查看当前用户权限:
select * from session_privs;
1、系统权限
系统权限是指被授权用户是否可以直接连接到数据库上以及在数据库中可以进行哪些系统操作.系统权限是在数据库中执行某种系统级别的操作,或者针对某一类的对象执行某种操作的权利.例如,在数据库中创建表空间的权利,或者在数据库中创建表的权利,这些都属于系统权限.
系统权限是对用户而言,常见的系统权限如下:
(1) CREATE SESSION : 连接到数据库.
(2) CREATE TABLE : 创建表.
(3) CREATE VIEW : 创建视图
(4) CREATE SEQUENCE : 创建序列
2、对象权限
允许用户操纵一些特定的对象,如读取视图,可更新某些列、执行存储过程等.如分配表的SELECT,UPDATE权限。
> Oracle 数据库用户有两种途径获取权限
(1) 管理员直接向用户授予权限
(2) 管理员将权限授予角色,然后再将角色授予一个或多个用户.
使用角色能够更加方便和高效的对权限进行管理,所以数据库管理员通常使用角色向用户授予权限,而不是直接向用户授予权限.角色是一组权限的集合,将角色赋给一个用户,这个用户就拥有了这个角色中的所有权限。
在Oracle数据库系统中预定义了很多角色,其中最常用的有CONNECT角色,RESOURCE角色,DBA角色等.
- **CONNECT : 需要连接上数据库的用户,特别是那些不需要创建表的用户,通常授予该角色. **
- RESOURCE : 更为可靠和正式的数据库用户可以授予该角色,可以创建表,触发器,过程等.
- DBA : 数据库管理员角色,拥有管理数据库的最高权限.一个具有DBA角色的用户可以撤销任何其他用户甚至其他DBA权限,这是很危险的,所以不要轻易授予该角色.
除了前面讲到的三种系统角色外,用户可以在Oracle创建自己的角色.
授予权限语法如下:
GRANT 权限|角色 TO 用户名
撤销权限语法如下:
REVOKE 权限|角色 FROM 用户名
示例8:
授予和撤销A_hr用户的CONNECT 和 RESOURCE两个角色
/*
============================================================
|| 给户A_hr用户授权,回收权限 ||
============================================================
*/
GRANT connect, resource TO A_hr; --授予CONNECT和RESOURCE两个角色
REVOKE connect, resource FROM A_hr; --撤销CONNECT和RESOURCE两个角色
GRANT SELECT ON SCOTT.emp TO A_hr; --允许用户查看 EMP 表中的记录
GRANT UPDATE ON SCOTT.emp TO A_hr; --允许用户更新 EMP 表中的记录
select table_name from user_tab_comments; --查看该用户下的所有表名
数据库用户安全设计原则:
(1) 数据库用户权限按照最小分配原则
(2) 数据库用户分为管理,应用,维护,备份四类用户
(3) 不允许使用
sys和system用户建立数据库应用对象(4) 禁止GRANT dba TO user_name(用户名)
返回顶部
2. 序列
做过web开发的人员基本上都知道,数据库表中的主键值有的时候我们会用数字类型的并且自增。这样mysql、sql server中的都可以使用工具创建表的时候很容易实现。但是oracle中没有设置自增的方法,一般情况我们会使用序列和触发器来实现主键自增的功能。
序列: 是oracle提供的用于产生一系列唯一数字的数据库对象。
序列有什么用:
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键值
- 将序列值装入内存可以提高访问效率
2.1 创建序列
创建序列需要CREATE SEQUENCE系统权限。序列的创建语法如下:
CREATE SEQUENCE 序列名
[ START WITH integer ]
[ INCREMENT BY integer ]
[ MAXVALUE integer | NOMAXVALUE ]
[ MINVALUE integer | NOMINVALUE ]
[ CYCLE | NOCYCLE ]
[ CACHE integer | NOCACHE ]
其中:
-
START WITH定义序列的初始值(即产生的第一个值),默认为1。
-
INCREMENT BY用于定义序列的步长,如果省略,则默认为1,如果出现负值,则代表Oracle序列的值是按照此步长递减的。
-
MAXVALUE定义序列生成器能产生的最大值。选项NOMAXVALUE是默认选项,代表没有最大值定义,这时对于递增Oracle序列,系统能够产生的最大值是10的27次方;对于递减序列,最大值是-1。
-
MINVALUE定义序列生成器能产生的最小值。选项NOMINVALUE是默认选项,代表没有最小值定义,这时对于递减序列,系统能够产生的最小值是-10的26次方;对于递增序列,最小值是1。
-
CYCLE和NOCYCLE表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。
如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。如果不循环,达到限制值后,继续产生新值就会发生错误。
-
CACHE(缓冲)定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。
大量创建序列语句发生请求,申请序列时,为了避免序列在运用层实现序列而引起的性能瓶颈。Oracle序列允许将序列提前生成 cache x个先存入内存,在发生大量申请序列语句时,可直接到运行最快的内存中去得到序列。
但cache个数也不能设置太大,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最大的序列号+1 开始存入cache x个。这种情况也能会在数据库关闭时也会导致序号不连续。
-
NEXTVAL返回序列中下一个有效的值,任何用户都可以引用。
-
CURRVAL中存放序列的当前值,NEXTVAL应在CURRVAL之前指定 ,二者应同时有效。
示例9:
需求:创建序列,从序号10开始,每次增加1,最大为2000,不循环,再增加会报错,缓存30个序列号
/*
===========================================================
|创建序列。从序号10开始,每次增加1,最大为2000,不循环,再增加会报错
============================================================
*/
CREATE SEQUENCE seq1
START WITH 10
INCREMENT BY 1
MAXVALUE 2000
NOCYCLE
CACHE 30;
-- 查看当前用户有哪些序列
select * from user_sequences;
2.2 访问序列
创建了序列之后,可以通过 NEXTVAL 和 CURRVAL 来访问该序列的值.可以从伪列中选择值,但是不能操纵它们的值.下面分别说明 NEXTVAL 和 CURRVAL.
- NEXTVAL : 创建序列化第一次使用它NEXTVAL时,将返回该序列的初始值.以后再引用NEXTVAL时,将使用INCREMENT BY 子句来增加序列的值,并返回这个值.任何用户都可以引用.
- CURRVAL : 返回序列当前的值,即最后一次引用NEXTVAL时的值
示例10:
需求 : 在玩具表中需要列
toyid作为标识,不需要有任何含义,可以作为主键
提示 : 该列可以考虑用序列自动插入
创建表的语句如下:
/*
============================================================
| 在玩具表中,需要标识列toyid作为标识,不需要有任何含义,可以作为主键
============================================================
*/
--创建toys表
CREATE TABLE toys(
toyid NUMBER NOT NULL,
toyname VARCHAR2(20),
toyprice NUMBER
);
插入数据,代码如下:
--插入数据
INSERT INTO toys (toyid, toyname, toyprice)
VALUES (seq1.NEXTVAL, 'TWENTY', 25);
INSERT INTO toys (toyid, toyname, toyprice)
VALUES (seq1.NEXTVAL,'MAGIC PENCIL',75);
--查询数据
SELECT * FROM toys;
--查看最后一次引用 NEXTVAL时的返回的值
SELECT seq1.CURRVAL FROM dual;
注意 : 当我们使用序列作为插入数据时,如果使用了“延迟段”技术,则跳过序列的第一个值
Oracle从 11.2.0.1版本开始,提供了一个“延迟段创建”特性:
即:
当我们创建了新的表(table)和序列(sequence),在插入(insert)语句时,序列会跳过第一个值(10)。所以结果是插入的序列值从 序列的第二个值(11) 开始, 而不是 第一个值(10)开始。
想要解决这个问题有两种方法:更改数据库的“延迟段创建”特性为false(需要有相应的权限)
ALTER SYSTEM SET deferred_segment_creation=FALSE;
或者
在创建表时让seqment立即执行,如:
CREATE TABLE toys(
toyid NUMBER NOT NULL,
toyname VARCHAR2(20),
toyprice NUMBER
)
SEGMENT CREATION IMMEDIATE;
以上两种方法都可以解决之前的问题。
2.3 更改序列
ALTER SEQUENCE 命令用于修改序列的定义.如果执行下列操作,则会修改序列
(1) 修改或删除 MAXVALUE 或 MINVALUE
(2) 修改增量值
(3) 修改缓存中序列号的数目.
更改序列的语法如下:
ALTER SEQUENCE 序列名
[ INCREMENT BY integer ]
[ MAXVALUE integer | NOMAXVALUE ]
[ MINVALUE integer | NOMINVALUE ]
[ CYCLE | NOCYCLE ]
[ CACHE integer | NOCACHE ]
注意:
不能修改序列的
START WITH参数. 在修改序列时,应注意升序序列的最小值应小于最大值
示例11
修改序列的最大值为5000,代码如下:
--修改序列
ALTER SEQUENCE seq1
MAXVALUE 5000
CYCLE;
-- 查看当前用户有哪些序列
select * from user_sequences;
2.4 删除序列
DROP SEQUENCE 命令用于删除序列. 还可以使用此语句重新开始一个序列,方法是先删除序列,然后再重新创建该序列.例如:一个序列的当前值为100,现在想用25重新开始此序列.此时可以先删除此序列,然后以相同的名称重新创建它,并将START WITH 参数设置为25.
删除序列的语法如下:
DROP SEQUENCE [schema.]sequence_name
下列命令用于从数据库中删除了seq1序列:
--删除序列
DROP SEQUENCE seq1;
2.5 使用SYS_GUID函数
Oracle还提供了SYS_GUID函数,用来生成32位的唯一编码,也可以作为主键.它源自不需要对数据库进行访问的时间戳和标识符,这会保证创建的标识符在每个数据库里都是唯一的.但管理SYS_GUID生成的值比较困难,所以除非在一个并行的环境里,或者希望避免使用序列的情况下使用函数.
序列与SYS_GUID函数区别,在不需要并行的环境中使用序列作为主键,在并行的环境里或者希望避免使用序列的情况下使用函数
可以多运行几次一下的代码来观察结果的变化:
--使用SYS_GUID函数
SELECT sys_guid() FROM dual;
提示:
使用序列设置关键字时,在数据库迁移时需要特别注意.由于迁移后的表已经存在数据,如果不修改序列的起始值,将会在表中插入重复数据,违背主键约束.所以,在创建序列时要修改序列的起始值.
返回顶部
3. 同义词
同义词顾名思义,是数据库方案对象的一个别名。这里的数据库方案对象指表、视图、序列、存储过程、包等。
同义词的好处:
-
1、不占内存空间,节省大量的数据库空间
-
2、简化了数据库对象的访问
-
3、提高了数据库对象访问的安全性
-
4、扩展的数据库的使用范围,能够在不同的数据库用户之间实现无缝交互;同义词可以创建在不同一个数据库服务器上,通过网络实现连接
3.1 同义词用途
(1) 简化SQL语句
(2) 隐藏对象的名称和所有者
(3) 为分布式数据库的远程对象提供了位置透明性
(4) 提供对对象的公共访问
3.2 同义词分类
同义词可分为两类:私有同义词和公有同义词
1. 私有同义词
私有同义词只能当前用户可以访问,且私有同义词名不可与当前模式的对象名称相同.要在当前模式下创建私有同义词,当前用户必须具有create synonym权限。要在其他用户模式下创建私有同义词,用户必须具有create any synonym的权限.
查看当前用户权限的语句如下:
--查看当前用户权限:
select * from session_privs;
创建私有同义词的语法如下:
CREATE [OR REPLACE] SYNONYM [schema.]synonym_name
FOR [schema.]object_name;
在语法中:
OR REPLACE: 表示在同义词存在的情况下替换该同义词sysnonym_name: 表示要创建的同义词名称object_name: 指定要为之创建同义词的对象的名称
示例12
需求:在A_oe模式下创建私有同义词访问A_hr模式下的employee表.
-- 1 . 创建A_oe用户
CREATE USER A_oe IDENTIFIED BY 1234
DEFAULT TABLESPACE tp_hr
TEMPORARY TABLESPACE temp ;
-- 2 . 创建A_hr模式下的employee表
grant select on scott.emp to a_hr; --授予A_hr用户获得访问scott用户emp表的权限
conn a_hr/1234; -- 登录A_hr用户
create table employee as select * from scott.emp;--创建employee表
-- 3 . 使用SYSTEM用户登录,授予A_oe用户获得访问A_hr模式下的employee表的权限
GRANT SELECT ON A_hr.employee TO A_oe;-- 授予a_oe用户查看a_hr用户employee 表的权限
GRANT CREATE SYNONYM TO A_oe; -- 授予创建私有同义词的权限
-- 4 . 登录 A_oe 用户创建同义词
--创建同义词SY_EMP
CREATE SYNONYM SY_EMP FOR A_hr.employee;
--访问同义词
SELECT * FROM SY_EMP;
2. 公有同义词
公有同义词 可 被所有的数据库用户访问 . 公有同义词可以隐藏数据库对象的所有者和名称,并降低SQL语句的复杂性.要创建公有同义词,用户必须拥有GREATE PUBLIC SYNONYM 系统权限.
创建公有同义词的语法如下:
CREATE [OR REPLACE] PUBLIC SYNONYM [schema.]synonym_name
FOR [schema.]object_name;
示例13
需求说明:
在A_hr模式下,对员工(employee)表创建公有同义词public_sy_emp,目的是使A_oe用户可以直接访问public_sy_emp.
--执行步骤一:切换system用户,赋予权限,语句如下
conn system/123456;
grant create public synonym to A_hr;
--执行步骤二:切换A_hr用户,创建公有同义词
conn A_hr/1234;
create public synonym public_sy_emp for employee;
--执行步骤三:切换A_oe用户,使用公有同义词
conn A_oe/1234;
select * from public_sy_emp;
> 公有同义词和私有同义词的区别:
私有同义词只能在当前模式下访问,且不能与当前模式的对象同名.
公有同义词可被所有的数据库用户访问.
注意:
(1) 使用同义词前,要获得同义词对应对象的访问权限
(2) 对象(如表)与私有同义词不能同名,对象和公有同义词同名时,数据库优先选择对象作为目标,私有同义词和公有同义词同名时,数据库优先选择私有同义词作为目标
3.3 删除同义词
DROP SYNONYM 语句用于从数据库中删除同义词.要删除同义词,用户必须拥有相应的权限.
删除同义词语法如下:
语法:
DROP [PUBLIC] SYNONYM [schema.]synonym_name;
示例14
需求说明:删除私有同义词和公有同义词
--删除私有同义词
DROP SYNONYM A_oe.sy_emp;
--删除公有同义词
DROP PUBLIC SYNONYM public_sy_emp;
注意:
此命令只删除同义词,不删除对应的对象
返回顶部
4. 索引
索引对于Oracle学习来说,非常重要,在数据量巨大的状况下,使用恰到好处的索引,将会使得数据查询时间大大减少.
4.1 什么是索引
索引是关系数据库中用于存放每一条记录的一种对象,主要目的是加快数据的读取速度和完整性检查。建立索引是一项技术性要求高的工作。一般在数据库设计阶段的与数据库结构一道考虑.
索引用于提高查询效率. 索引的内建工作对用户是透明的,由数据库自行维护,我们只需要指定是否添加索引。索引是为表中字段添加的。当一个字段经常出现在
WHERE中作为过滤条件,或ORDER BY或DISTINCT中时可以为其添加索引以提高查询效率。
通俗的来讲,索引在表中的作用,相当于书的目录对书的作用。
4.2 索引的分类
在Oracle中索引的分类如表:
| 物理分类 | 逻辑分类 |
|---|---|
| 分区或非分区索引 | 单列或组合索引 |
| B树索引 | 唯一或非唯一索引 |
| 正常或反向键索引 | 基于函数索引 |
| 位图索引 | 其他索引 |
1. B树索引
B树索引通常也称为标准索引,是一个树结构,树的顶部为根,根节点指向第二级别的多个节点,第二级别的节点又指向第三级别的多个节点,以此类推。最低一级为叶节点,其中包含执行表行的索引项.叶块为双向链接,有助于按照关键字值的升序和降序扫描索引.
一个B树索引只有一个根节点,它实际就是位于树的最顶端的分支节点。
可以用下图一来描述B树索引的结构。其中,B表示分支节点,而L表示叶子节点。

如上图,前三行是索引的内部构造,第三行与最后一行,这是索引指向表里数据的一个指向。索引是建立在列上的。最后一行是索引建立在表中某列上的值。
- 根节点块 :如果索引列的值>0时,指向B1这个分支节点块,如果索引列的值>500时,指向B2这个分支节点块,如果索引列的值>1000时,指向B3这个分支节点块。
- 分支节点块:对于B1来说,再进行细分 如果索引列的值>0且<200时,指向L1这个分支节点块,如果索引列的值>200且<400时,指向L2这个分支节点块,如果索引列的值>400且<500时,指向L3这个分支节点块。
- 叶子节点块: 对于L1来说,如果数据行的值为0,那就放在R1这个数据行中,如果数据行的值为29,那就放在R2这个数据行中,如果数据行的值为190,那就放在R3这个数据行中,等。
创建索引的语法如下:
create or replace [unique|bitmap] index [schema.index_name] on schema.table_name
(column_list…)
[tablespace tablespace_name]
语法中:
- unique|bitmap : unique表示唯一值索引,bitmap表示位图索引,为空则默认为B-tree索引
- index_name : 指所创建索引的名称
- column_list … : 在其上创建索引的列名的列表,可以多列创建索引,列之间用逗号分隔
- **tablespace_name : ** 为索引指定表空间(当表和索引在不同的表空间的时候,效率更高)
2. 唯一索引和非唯一索引
- **唯一索引 : ** 定义索引的列中任何两行都没有重复值 . 唯一索引中的索引关键字只能指向表中的一行.在创建主键约束和创建唯一约束时 都会创建一个与之对应的唯一索引.
- **非唯一索引 : **单个关键字可以有多个与其关联的行
示例15
需求说明:在薪水级别(salgrade)表中,为级别编号(grade)列创建唯一索引
/*
===========================================================
|| 在薪水级别(salgrade)表中,为级别编号(grade)列创建唯一索引
============================================================
*/
CREATE UNIQUE INDEX index_unique_grade ON salgrade(grade);
--查看表中有哪些索引:select * from user_indexes where table_name='表名'
select index_name from user_indexes where table_name='SALGRADE';
-- 完整的查询索引的语法如下:
select user_ind_columns.index_name,user_ind_columns.column_name,
user_ind_columns.column_position,user_indexes.uniqueness
from user_ind_columns,user_indexes
where user_ind_columns.index_name = user_indexes.index_name
and user_ind_columns.table_name = 'SALGRADE';
3. 反向键索引
与常规的B树索引相反,反向键索引在保持列顺序的同时反转索引列的字节, 反向键索引通过反转索引键的数据值来实现.其优点是对于连续增长的索引列,反转索引列可以将索引数据分散在多个索引块间,减少I/O的瓶颈.
这个索引不经常使用到,但是在特定的情况下,是使用该索引可以达到意想不到的效果。如:某一列的值为{10000,10001,10021,10121,11000,…},假如通过b-tree索引,大部分都密集发布在某一个叶子节点上,但是通过反向处理后的值将变成{00001,10001,12001,12101,00011,…},很明显的发现他们的值变得比较随机,可以比较平均的分布在各个叶子节点上,而不是之前全部集中在某一个叶子节点上,这样子就可大大提高检索的效率。
示例15
需求说明:在员工(employee)表中,为员工编号(empno)列创建反向键索引.
/*
===========================================================
|| 在员工(employee)表中,为员工编号(empno)列创建唯一的反向键索引
============================================================
*/
create unique index idx_empno on employee(empno) reverse;
/*
===========================================================
|| 将创建好的反向键索引 作为 employee表的主键
============================================================
*/
alter table employee add constraint pk_empno primary key(empno) using index idx_empno;
-- 使用按照查询 索引就会有效果
select * from employee where empno=7788;
-- 查看表中有哪些索引:select * from user_indexes where table_name='表名'
select index_name from user_indexes where table_name='employee';
4. 位图索引
位图索引的优点在于,它最适于低基数列(即该列的值是有限的,理论上不会是无穷大).例如:员工表的工作(job)列,即便是几百万条员工记录,工种也是可计算的.或者员工的性别,商品表的类别等. 都可以使用位图索引.
位图索引具有以下优点:
(1) 对于大批的即时查询,可以减少响应的时间.
(2) 相比其他索引技术,占用的空间明显减少.
(3) 即使在配置很低的终端硬件上,也能获得显著的性能
位图索引不应当用在频繁发生INSERT,UPDATE,DELETE操作的表上.这些DML操作在性能方面的代价很高. 位图索引最适合于数据仓库和决策支持系统
示例16
在员工(employee)表中,为工种(job)列创建位图索引
/*
===========================================================
| 在员工(employee)表中,为工种(job)列创建位图索引
============================================================
*/
CREATE BITMAP INDEX index_bit_job ON employee(job);
关于B树索引和位图索引的比较:

5. 其他索引
- 组合索引 : 在表内多列上创建.索引中的列不必与表中的列顺序一致,也不必相互邻接.类似SQL Server中的复合索引.如员工表中部门和职务列上的索引.组合索引最多包含32列
- 基于函数的索引 : 若使用函数或表达式涉及正在建立索引的表中的一列或多列,则创建基于函数的索引.可以将基于函数的索引创建为B树索引或者位图索引.
示例17
需求说明:在员工(employee)表中,为员工名称(ename)列创建大写函数索引
/*
===========================================================
| 在员工(employee)表中,为员工名称(ename)列创建大写函数索引
============================================================
*/
CREATE INDEX index_ename ON employee(UPPER(ename));
4.3 索引使用原则
创建索引时需遵循的原则如下:
(1) 频繁搜索的列可以作为索引
(2) 经常排序,分组的列可作为索引.
(3) 经常用作连接的列(主键/外键) 可作为索引
(4) 将索引放在一个单独的表空间中,不要放在有退役,临时段和临时表的表空间中
(5) 对大型索引而言,考虑使用NOLOGGING子句创建大型索引
(6) 根据业务数据发生的频率,定期重新生成或重新组织索引,并进行碎片整理
(7) 仅包含几个不同值的列不可以创建为B树索引,可根据需要创建位图索引
(8) 不要在仅包含几行的表中创建索引
4.4 删除索引
1. DROP INDEX 索引名 语句用于删除索引
示例18
需求说明:删除员工表employee中的index_bit_job位图索引:
--删除索引
DROP INDEX index_bit_job;
注意:
在SQL Server 中创建或删除索引时,必须指明表的名称和索引名称.而Oracle索引名在用户账户中是唯一的,删除时不需要指定表名.
2. 何时应删除索引
(1) 应用程序不再需要索引
(2) 执行批量加载前.大量加载数据前删除索引,加载后在重建索引有以下好处:
①提供加载性能; ②更有效的使用索引空间.
(3) 索引已损坏
4.5 重建索引
1. ALTER INDEX … REBUILD 语句用于创建索引
示例18:
需求说明:将反向键索引更改为正常B树索引,代码如下:
--将反向键索引更改为正常B树索引
ALTER INDEX index_reverse_empno REBUILD NOREVERSE;
2. 何时应重建索引
-
用户表被移动到新的表空间后,表上的索引不是自动转移,此时就需要将索引移到指定的表空间.
语法如下:ALTER INDEX index_name REBUILD TABLESPACE tablespace_name; -
索引中包含很多已删除的项. 对表进行频繁删除,造成索引空间浪费,可以重建索引
-
需将现有的正常索引转换成反向键索引
返回顶部
5. 分区表
在大型的企业应用或企业级的数据库应用中,要处理的数据量通常可以达到几十到几百GB,有的甚至可以到TB级。
虽然存储介质和数据处理技术的发展也很快,但是仍然不能满足用户的需求,为了使用户的大量的数据在读写操作和查询中速度更快,Oracle提供了对表和索引进行分区的技术,以改善大型应用系统的性能。
5.1 什么是分区表:
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。
表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
使用分区的优点:
1、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
2、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
3、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能;
4、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
什么时候使用分区表,官方给的建议是:
-
a. 表的大小超过2GB。
-
b. 表中包含历史数据,历史数据和新添加的数据有着明显的界限划分。
表分区对用户是透明的,即应用程序可以不知道表已被分区,在更新和查询分区表时当做普通表来操作,但Oracle优化程序知道表已被分区.
注意: 要分区的表不能具有LONG 和 LONG RAW 数据类型的列
5.2 分区表的分类
Oracle数据库提供对表或索引的分区方法有几种:范围分区(range),哈希(散列)分区(hash),列表分区(list),复合分区,间隔分区和虚拟列分区等;
1. 范围分区
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。
语法:
PARTITION BY RANGE (column_name)
(
PARTITION part1 VALUES LESS THAN (range1),
PARTITION part2 VALUES LESS THAN (range2),
…
[PARTITION partN VALUES LESS THAN (MAXVALUE)]
);
以列的值的范围来作为分区依据
示例19
需求说明:在某购物中心销售系统中,要求统计某季度的销售信息.
| 列名 | 说明 | 类型 |
|---|---|---|
| SALES_ID | 销售流水编号 | NUMBER |
| PRODUCT_ID | 产品ID | VARCHAR2(5) |
| SALES_DATE | 销售日期 | DATE |
| SALES_COST | 销售金额 | NUMBER(10) |
| AREACODE | 销售区域 | VARCHAR2(5) |
提示:
在按时间分区时,如果某些记录暂时无法预测范围,则可以创建
maxvalue分区,所有不在指定范围内的记录都会被存储在maxvalue所在的分区中.
关键代码如下:
/*
===========================================================
| 范围分区
============================================================
*/
CREATE TABLE SALES1
(
SALES_ID NUMBER,
PRODUCT_ID VARCHAR2(5),
SALES_DATE DATE NOT NULL
-- 省略其他属性
)
PARTITION BY RANGE (SALES_DATE)
(
PARTITION P1 VALUES LESS THAN (to_date('2013-04-1', 'yyyy-mm-dd')),
PARTITION P2 VALUES LESS THAN (to_date('2013-07-1', 'yyyy-mm-dd')),
PARTITION P3 VALUES LESS THAN (to_date('2013-10-1', 'yyyy-mm-dd')),
PARTITION P4 VALUES LESS THAN (to_date('2014-01-1', 'yyyy-mm-dd')),
PARTITION P5 VALUES LESS THAN (maxvalue)
);
--查看分区情况
select table_name,partition_name from user_tab_partitions
where table_name='SALES1';
--插入数据
INSERT INTO SALES1 VALUES(900,'p1',to_date('2012-05-1', 'yyyy-mm-dd'));
INSERT INTO SALES1 VALUES(1000,'p2',to_date('2013-05-1', 'yyyy-mm-dd'));
INSERT INTO SALES1 VALUES(2000,'p2',to_date('2013-07-1', 'yyyy-mm-dd'));
INSERT INTO SALES1 VALUES(3000,'p3',to_date('2013-12-1', 'yyyy-mm-dd'));
INSERT INTO SALES1 VALUES(4000,'p4',to_date('2014-05-1', 'yyyy-mm-dd'));
--要查看在第三季度的数据
SELECT * FROM SALES1 partition(P3);
--要删除第三季度的数据
DELETE FROM SALES1 partition(P3);
经验:
(1) 一般创建范围分区时,都会将最后一个分区设置为
maxvalue,使其它数据落入此分区.一旦需要某一数据时,可以利用拆分分区的技术将需要的数据从最后一个分区分离出来,单独形成一个分区.如果没有创建足够大的分区,插入的数据超出范围就会报错.(2) 如果插入的数据是分区键上的值,则该数据落入下一个分区.例如插入的数据为
2013-10-1,则数据会自动落入P4分区
2. 间隔分区
间隔分区是范围分区的一个拓展,当插入的数据超过了现有的所有分区时,数据库会按照指定的间隔自动创建分区.
它的优点为在不需要创建表时就将所有分区划分清楚 . 间隔分区随着数据的增加会划分更多的分区,并自动创建新的分区.
语法:
PARTITION BY RANGE(column_name)
INTERVAL(NUMTOYMINTERVAL(n, ‘interval_unit’))
(PARTITION P1 VALUES LESS THAN (range1));
-
INTERVAL: 代表“间隔”,按照后面括号中的定义间隔添加分区
-
NUMTOYMINTERVAL(n, ‘interval_unit’) 函数
- 将n转换成interval_unit所指定的值
- interval_unit可以为: YEAR, MONTH
示例20:
需求说明:统计某季度的销售信息
/*
===========================================================
|| 间隔分区
============================================================
*/
--创建间隔分区表
CREATE TABLE SALES2
(
SALES_ID NUMBER,
PRODUCT_ID VARCHAR2(5),
SALES_DATE DATE NOT NULL
)
PARTITION BY RANGE(SALES_DATE)
INTERVAL(NUMTOYMINTERVAL(3,'MONTH'))
(PARTITION P1 VALUES LESS THAN (to_date('2013-04-01','yyyy-MM-dd')));
--插入数据
INSERT INTO sales2 VALUES (1,'a',to_date('2013-03-01','yyyy-MM-dd'));
INSERT INTO sales2 VALUES (1,'a',to_date('2013-05-01','yyyy-MM-dd'));
INSERT INTO sales2 VALUES (1,'a',to_date('2013-08-01','yyyy-MM-dd'));
--获得分区情况
SELECT table_name,partition_name
FROM user_tab_partitions
WHERE table_name=UPPER('sales2');
--查询输出结果,系统自动根据输入数据情况创建新分区“SYS_P82”
TABLE_NAME PARTITION_NAME
----------------------------
SALES2 P1
SALES2 SYS_P346
SALES2 SYS_P347
--查询分区数据
SELECT * FROM sales2 PARTITION(sys_p346);
说明:
- 只需创建第一个开始分区,如示例20中的P1
INTERVAL(NUMTOYMINTERVAL(3,'MONTH'))语句中,INTERVAL代表"间隔",即按照后面括号中的定义间隔添加分区.NUMTOYMINTERVAL(3,'MONTH')表示每3个月为一个分区.
NUMTOYMINTERVAL(n,'interval_unit')函数用于将n转换成interval_unit所指定的值
interval_unit可以为YEAR或者MONTH.- 举例:
NUMTOYMINTERVAL(1,'YEAR'): 每1年为一个分区NUMTOYMINTERVAL(1,'MONTH'): 每1个月为一个分区- 与该类型相关的函数还有
NUMTODSINTERVAL(n,'interval_unit'), 用于将n转换成interval_unit所指定的值.
interval_unit可以为DAY,HOUR,MINUTE,SECOND.- 注意该函数不支持
YEAR和MONTH.- 系统会根据数据自动创建分区
经验:
可以利用间隔分区 将 开始创建时没有分区的表 创建为新的间隔分区表.代码如下:
/*
===========================================================
|| 利用间隔分区将开始创建时没有分区的表创建为新的间隔分区表
============================================================
*/
/*准备工作*/
--1.创建普通SALES表
CREATE TABLE SALES
(
SALES_ID NUMBER,
PRODUCT_ID VARCHAR2(5),
SALES_DATE DATE NOT NULL
);
--2.自行向SALES表插入数据
/*实施步骤*/
--1.创建间隔分区表SALES3
CREATE TABLE SALES3
PARTITION BY RANGE(SALES_DATE)
INTERVAL(NUMTOYMINTERVAL(3,'MONTH'))
(PARTITION P1 VALUES LESS THAN (to_date('2013-04-1','yyyy/mm/dd')))
AS SELECT * FROM SALES; --SALES表为已经创建的表
--2.查询分区情况
SELECT table_name,partition_name
FROM user_tab_partitions
WHERE table_name=UPPER('sales3');
--3.自行向SALES3表插入数据
INSERT INTO sales3 VALUES (1,'a',to_date('2013-03-01','yyyy-MM-dd'));
INSERT INTO sales3 VALUES (1,'a',to_date('2013-05-01','yyyy-MM-dd'));
INSERT INTO sales3 VALUES (1,'a',to_date('2013-08-01','yyyy-MM-dd'));
--4.查询某一分区数据
SELECT * FROM sales3 PARTITION(P1);
返回顶部
6. 创建数据库链:
1. 数据库链的基本概念
数据库链(Database Link) 用来更方便地实现从一个数据库访问另一个数据库,是在本地建立的一个路径 . 简单来说就是通过数据库链 , 能够实现不同数据库之间的通信 , 即在A数据库中可以实现对B数据库中数据的访问
注意:在数据库中数据库链会被看作本地数据库的一个使用对象
2. 数据库链的应用
(1) 数据库链的创建:
-
创建数据库链时 , 要求数据库链的名字与链所指向的数据库的全名相同 , 其语法格式如下:
CREATE [PUBLIC] DATABASE LINK link_name
CONNECT TO username IDENTIFIED BY password
USING ‘SERVERNAME/SERVERURL’;
-
其中:
-
PUBLIC : 使用该关键字表示创建公有的数据库链 .
-
link_name : 表示远程数据库的用户账户和密码
-
username/password : 表示远程数据库的用户账户和密码
-
SERVERNAME/SERVERURL : 表示在连接时使用服务器名或者包含服务完整信息的路径
示例如下:
-- 创建名为link_orcl的数据库链
create database link link_orcl
connect to scott identified by tiger
using '(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.5.150)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
)
)';
-- 查询某个数据库链中的表
select * from emp@link_orcl;
-- 删除名为link_orcl 的数据库链
drop database link link_orcl;
7. 从Oracle数据库中导入导出数据
关键步骤如下:
- 使用imp和exp导入导出数据
- 使用PL/SQL Developer导入导出数据
7.1 使用Oracle工具imp和exp导入导出数据
1. 使用exp导出数据
exp是Oracle提供的导出工具 , 它是操作系统下的一个可执行文件 , 存放目录为D:\app\Administrator\product\11.2.0\dbhome_1\BIN . 在命令提示符窗口输入exp即可启动数据的导出 , 主要步骤如下:
- (1) 按照提示用户名和密码进行登录 . 此处用户名为scott , 密码tiger
- (2) 登录成功后 , 提示输入数组提取缓冲区大小 , 如果采用默认值 , 直接按Enter键即可
- (3) 提示输入导出的文件路径和文件名 , 文件路径默认:
C:\Users\Administrator, 文件名默认为EXPDAT.DMP, 如果采用默认值 , 则直接按Enter键即可 . - (4) 提示导出方式 . 当使用exp导出数据时 , 支持3种导出方式:表达式,导出一个指定表 , 包括表的定义 , 数据和表上建立的索引和约束等 ; 用户方式 , 导出数据一个用户的所有对象 , 包括表,视图,序列,存储过程等 ; 全数据库方式 , 导出数据库中所有的对象 , 只有DBA可以选择这种导出方式 . 此处选择用户方式 , 它是默认项即可.
- (5) 提示是否导出权限,导出表数据 , 是否对导出数据进行压缩 , 采用默认项即可
- (6) 开始导出数据 , 导出完毕后提示成功 , 终止导出.
2. 使用imp导入数据
主要步骤如下:
-
(1) 按照提示输入用户名和密码进行登录 . 此处为scott
-
(2) 登录成功后 , 提示输入导入文件的路径和文件名 , 默认为
EXPDAT.DMP, 直接按Enter键即可 -
(3) 提示输入插入缓冲区大小 , 如果采用默认值 , 直接按Enter键即可
-
(4) 提示是否只列出导入文件的内容 , 如果采用默认值 , 直接按Enter键即可
-
(5) 提示对已经存在 , 是否忽略创建错误 , 默认为no . 此处输入yes , 按Enter键即可
-
(6) 提示是否导入权限 , 是否导入数据 , 根据需求选择,可以采用默认值
-
(7) 提示是否导出整个文件 , 默认项为no . 此处输入yes , 按Enter键继续
-
(8) 开始导入数据 , 导入完毕后给出成功提示终止导入
7.2 使用PL/SQL Developer工具导入导出数据
PL/SQL Developer中提供了更直观方便和更多的导入导出方法
1. 使用PL/SQL Developer导出数据
登录PL/SQL Developer成功后 , 选择Tool → Export Tables , 出现如图:

可以看出有3中导出方式 , 分别是Oracle Export , SQL Inserts,PL/SQL Developer, 他们的区别如下:
Oracle Export: 使用的就是exp命令 , 导出.dmp文件格式 ..dmp文件是二进制的 , 无法查看 , 但可以跨平台 , 效率高且使用最广.SQL Inserts: 导出为.sql文件格式 , 可以使用记事本等文件编辑器查看 , 效率不如第一种 , 适合小数据量导入导出 . 如果表中用blob,clob等字段 , 则不能采用此方式PL/SQL Developer: 导出.pde文件格式 , 它是PL/SQL Developer的自有文件格式 , 只能使用该软件导入导出.
如图所示 : 首先在窗口上测选中要导出的数据库表 , 然后在窗口左下侧勾选要导出的具体内容 , 最后在下侧指定导出文件的路径和文件名 , 单击Export按钮即可完成导出
2. 使用PL/SQL Developer导入数据
登录PL/SQL Developer成功后 , 选择Tool → Improt Tables , 出现如图:

同样可以看到3中导入方式 , 分别与3中导出方式对应 . 在窗口下侧指定导入文件的路径和文件名 , 单击Import按钮即可完成导入
补充:
SYS与SYSTEM、DBA与SYSDBA的区别:
1.SYS与SYSTEM:
- sys 的角色是sysdba system 的角色是sysoper
- sys 具有create database的权限 system没有该权限
- sys可以建数据字典的基表和视图,也能对其进行修改;
system不能建数据字典的基表和视图.也不能对其进行修改 - sys、system都有dba权限
用QQ群作个比喻,sys就相当于群主,system就相当于群管理员。
2.DBA与SYSDBA:
- SYSDBA不是权限,当用户以SYSDBA身份登陆数据库时,登陆用户都会变成SYS。
- SYSDBA身份登陆可以打开,关闭数据,对数据库进行恢复操作等,而这些是DBA角色无法实现的;
- SYSDBA是系统权限,DBA是用户对象权限;
- SYSDBA是管理Oracle实例的,它的存在不依赖于整个数据库完全启动,只要实例启动了,他就已经存在。只有数据库打开了,或者说整个数据库完全启动后,DBA角色才有了存在的基础;
- DBA是一种role对应的是对Oracle实例里对象的操作权限的集合,而SYSDBA是概念上的role是一种登录认证时的身份标识而已。而且,DBA是Oracle里的一种对象,Role 和User一样,是实实在在存在在Oracle里的物理对象,而SYSDBA是指的一种概念上的操作对象,在Oracle数据里并不存在。
补充:
使用 PL/SQL 连接远程Oracle的方法:
由于Oracle的庞大,有时候我们需要在只安装Oracle客户端如plsql、toad等的情况下去连接远程数据库,可是没有安装Oracle就没有一切的配置文件去支持。最后终于发现一个很有效的方法,Oracle的Instant client工具包可以很好地解决这个问题,而且小而方便。
1. 首先到Oracle网站下载Instant Client :
https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html
对应Oracle的版本下载对应的Oracle的客户端,例如:Oracle 11g 可以下载 [instantclient-basic-win-x86-64-11.1.0.7.0.zip]:https://www.oracle.com/database/technologies/instant-client/winx64-64-downloads.html#license-lightbox)
解压之后的文件夹叫:instantclient_11_1.可以放在本地磁盘任意目录下.例如:
D:\app\instantclient_11_1
2. 修改添加文件:
在上一步解压出来的客户端目录下(例如:D:\app\instantclient_11_1)目录下新建文件tnsnames.ora,或者将Oracle安装目录\product\11.2.0\dbhome_1\NETWORK\ADMIN\tnsnames.ora复制到该目录下 ,打开写入如下内容:
ORCL =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.0.100)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = ORCL)
)
)
其中:ORCL是远程数据库在本地的主机名,192.168.0.100是远程服务器的IP地址,ORCL是远程数据库的名称。
3. 配置环境变量:
新建一个环境变量,名为TNS_ADMIN,值为tnsnames.ora文件所在路径。
例如: 变量名 :
TNS_ADMIN变量值 :D:\app\instantclient_11_1
4. 下载并安装PL.SQL.Developer配置应用
配置tools->preferences->connection
# Oracle Home
D:\app\instantclient_11_1
# OCI library
D:\app\instantclient_11_1\oci.dll
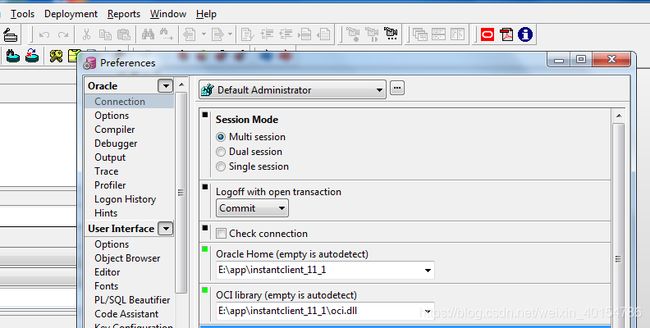
配置完成后关闭PL/SQL ,再重启.
主机名就会出现在PL/SQL Developer的列表里,输入用户名密码,就可以登录远程oracle 数据库。
若发现oci.dll文件报错,则是客户端版本与服务器版本冲突,重新下载对应的客户端版本
5. 查询数据乱码问题解决:
-
当我们连接成功后有时候查询出来的数据会出现乱码的问题,这是因为本地的编码和服务器端编码不一致,这时候我们可以通过SQL语句:
select userenv('language') from dual; -
查询出服务器端的编码,结果如下:
USERENV('LANGUAGE') AMERICAN_AMERICA.ZHS16GBK -
我们就需要添加一个环境变量
NLS_LANG,值为:AMERICAN_AMERICA.ZHS16GBK然后重启PL/SQL就不会再有乱码问题了
6. 无法连接远程Oracle 服务器解决方式
- 找到服务器的
Net Manager工具 , 修改监听器的主机名为本地计算机名 , 如图所示:
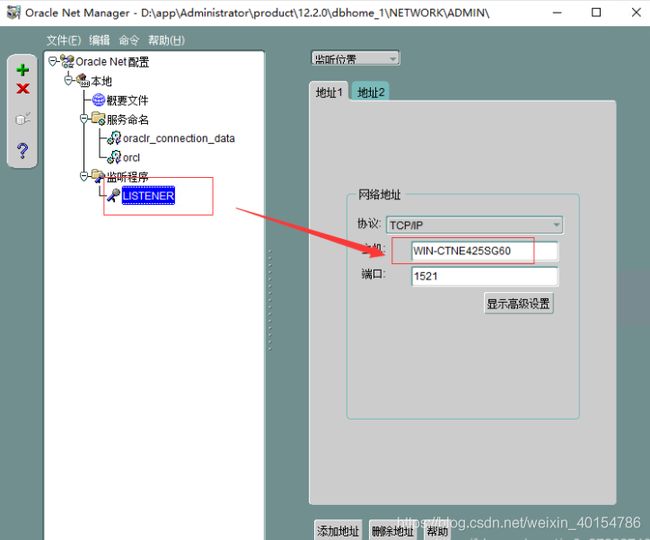
- 设置服务器命名的主机名为本地计算机名 , 如图所示:

- 重启oracle的数据库服务 以及 监听服务
补充:
创建pdb的步骤
1. 创建pdb 可插拔式数据库
-- 查看插接式数据库
show pdbs;
-- 查看参数 FILE_NAME_CONVERT
select name from v$datafile;
-- 创建 插接式数据库
create pluggable database orclpdb
admin user orclpdb identified by orcl
file_name_convert=('D:\APP\ADMINISTRATOR\ORADATA\ORCL\PDBSEED\','D:\APP\ADMINISTRATOR\ORADATA\ORCL\ORCLPDB\');
2. 打开单个pdb数据库
-- 打开单个pdb数据库
alter pluggable database orclpdb open;
-- 关闭pdb数据库
alter pluggable database orclpdb close immediate;
3. 切换到pdb数据库中
-- 切换到pdb数据库中
alter session set container=ORCLPDB;
4. 创建scott用户
-- 创建scott用户
creat user scott identified by tiger;
5. 授予dba权限(可选)
-- 授予dba权限
grant dba to scott;
6. 执行sql脚本文件
-- 执行sql脚本文件 若是安装在D盘 请在对应的盘符下查找sql文件
@D:\app\Administrator\product\12.2.0\dbhome_1\rdbms\admin\scott.sql;
-- 查看某用户下有哪些表名
select table_name from all_tables a where a.OWNER = upper('scott');
7. 保存开启状态
ALTER PLUGGABLE DATABASE orclpdb SAVE STATE;--保存开启状态
8. 删除 pdb 数据库 以及数据文件
drop pluggable database orclpdb including datafiles;