Quartz分布式任务调度原理
什么是分布式定时任务调度
定时任务调度
在很多应用场景下我们需要定时执行一些任务,比如订单系统的超时状态判断、缓存数据的定时更新等等,最简单粗暴的方式是用while(true)+sleep的组合来空转,直到到达指定时间就执行任务,但这显然非常低效。更好的方法是使用系统提供的Timer定时器或者使用Quartz框架等等。
持久化
如果只是设置一两个固定的简单的定时任务,比如只需要定时把数据从磁盘更新到内存的缓存中,那不需要考虑太多,即使节点宕机了,重启后就会继续按原有频率继续执行定时任务,所以不需要考虑定时任务的持久化问题。
但是如果业务场景比较复杂,需要设置非常多的定时任务,比如订单系统的超时状态判断,每个用户下单后都需要设置一个30分钟的定时任务,30分钟一到就执行任务判断用户是否已经支付,如果尚未支付就自动取消订单。如果机器在此期间宕机丢失内存数据,那么重启之后将会丢失所有定时任务,一大批的超时的未支付订单都不会被取消。因此,我们往往还需要考虑将定时任务写到磁盘中将其持久化,确保任务能够得到执行。
分布式集群
在单个机器节点上做定时任务调度比较简单直白,但弊端是
- 一旦节点宕机,就无法提供定时任务调度的服务。
- 单个节点的算力有限,无法支持大量定时调度任务。
因此往往需要部署分布式集群来提供定时任务调度服务,分布式的定时任务调度系统需要考虑如何统一管理众多的定时任务
- 如何保证每个任务只被一个节点执行(避免时间点到来时同一任务被重复执行)
- 一个节点宕机时如何让其他节点接管其负责的定时任务
- 等等。。。
Quartz单点
Quartz 是一个完全由 Java 编写的开源作业调度框架。
Quartz基础
参考Quartz-任务调度
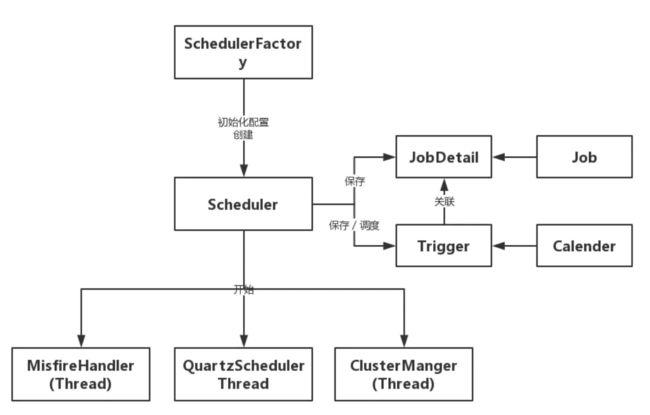
三个基础概念
- 任务:需要执行的任务。
- 触发器:触发器用于配置调度参数,设置触发条件。
- 调度器:调度器将对应的触发器和任务绑定在一起,当触发器被触发时执行对应的任务。
使用实例
创建Job
实现Job接口,并且重写execute方法,就是在这个方法里写我们要执行的任务
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
/** 此类只是用来执行任务代码 */
public class MyJob implements Job
{
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("这里是我们的任务代码");
}
}
创建JobDetail
我们写了MyJob这个类来实现了Job接口,接着我们就要通过创建JobDetail告诉Quartz,MyJob这个类是我们准备要执行的一个任务
//2.2.3版本 注册任务 方式
JobDetail job = JobBuilder.newJob(MyJob.class)//设置要执行的任务是哪个类
.withIdentity("helloJob", "group1")//设置任务信息 参数1任务名 参数2为组名
.build();//创建
创建Trigger
Quartz主要有两种触发器:
- SimpleTrigger触发器:设置一些简单的属性,如开始时间、结束时间、重复次数、重复间隔等。
- CronTrigger触发器:可以使用cron表达式来更灵活的控制时间,例如每年执行一次、每天几点执行、每月几号执行等。
cron格式可以参考crontab格式 & golang时间格式
//Trigger 是触发器接口,要通过TriggerBuilder来实例化一个
TriggerTrigger trigger1 = TriggerBuilder.newTrigger()
//withIdentity(String name, String group) 指定触发器信息 参数1触发器名 参数2触发器组,如果不创建将自动生成
.withIdentity("trigger1", "test")
//withSchedule(ScheduleBuilder schedBuilder) 设置一个实现了ScheduleBuilder接口的触发器
//这里我们演示的是SimpleTrigger触发器,所以要使用SimpleScheduleBuilder.simpleSchedule()方来创建
.withSchedule(SimpleScheduleBuilder.simpleSchedule()
//指定触发间隔,以秒为单位
.withIntervalInSeconds(5)
//设置执行次数
.withRepeatCount(5))
.build();//创建
Trigger trigger2 = TriggerBuilder.newTrigger()
.withIdentity("cron trigger", "test")
.withSchedule(
//这里我们演示的是CronTrigger触发器,所以要使用CronScheduleBuilder.cronSchedule()方来创建
//每5秒执行一次
CronScheduleBuilder.cronSchedule("0/5 * * ? * *")).build();
创建Scheduler
通过SchedulerFactory获取Scheduler调度器,并且将一个任务和一个触发器绑定起来
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
try {
/**
* Scheduler是一个调度器
* 一个Scheduler注册JobDetail和Trigger。一旦注册后,Scheduler 负责执行Job, 前提是Trigger的预定时间到达。
*/
Scheduler scheduler = schedulerFactory.getScheduler();//调用getScheduler()方法来获取一个Scheduler实例
//使用scheduleJob(JobDetail jobDetail, Trigger trigger) 方法使 任务 & 触发器 发生关联
scheduler.scheduleJob(job, trigger2);
//使用start()方法开启调度 scheduler.start();
//关闭调度//scheduler.shutdown();
} catch (SchedulerException e)
{
e.printStackTrace();
}
至此,一个定时任务就配置完成了。
Quartz调度原理
参考Quartz原理解密
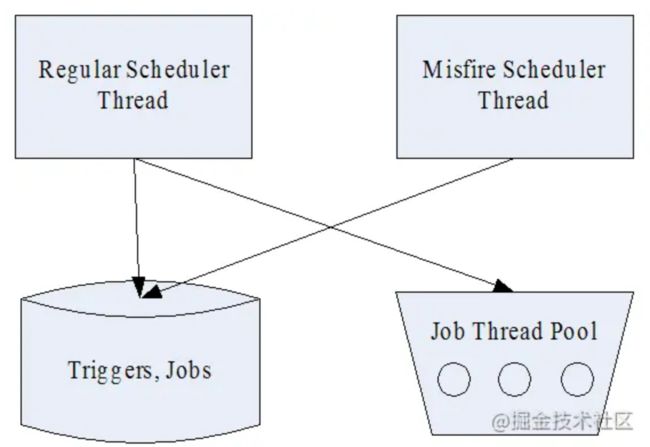
调度线程
Quartz中Scheduler调度线程主要有两类线程:
- Regular Scheduler Thread(执行常规调度):Regular Thread轮询所有Trigger,如果发现有将要触发的Trigger,就从任务线程池中获取一个空闲线程,然后执行与改Trigger关联的Job。
- Misfire Scheduler Thread(执行错失的任务):Misfire Thraed轮询所有Trigger,查找有错失的任务,例如系统重启/线程占用等问题导致的任务错失,根据一定的策略进行处理。
存储
Quartz有两种方式将定时任务存储下来:
- RAMJobStore:将trigger和job存储到内存里
- JobStoreSupport:将trigger和job存储到数据库里
为了防止任务数据丢失,Quartz会将trigger和job存储到数据库里,
Quartz集群
参考分布式任务调度方案调研
定时任务的分布式调度
集群环境下防止并发的一种实现( Spring Quartz 集群思路)
分布式调度策略
除了单机版本外,Quartz也提供了集群方案,它的集群方案是基于数据库实现的。

上图三个节点,每个节点里有许多Scheduler实例(调度器线程),每个Scheduler实例都会去争抢访问数据库中的Trigger,如何保证同一时刻每个Trigger只会被一个Scheduler实例获取并检查?答案是数据库锁(可以理解为用数据库实现了分布式锁)。Quartz集群采用了以数据库作为协调中心的方式,通过表的设计协调不同节点之间的行为:
- QRTZ_SCHEDULER_STATE表:记录Scheduler实例的状态信息
- QRTZ_LOCKS表:记录程序悲观锁的信息
关注QRTZ_LOCKS表,表里只有一个字段
CREATE TABLE QRTZ_LOCKS (
LOCK_NAME VARCHAR2(40) NOT NULL,
PRIMARY KEY (LOCK_NAME)
)
这些数据是根据数据库的业务逻辑操作抽象出的系统所拥有的表的类型,QRTZ_LOCKS主要有两个行级锁
| lock_name | desc |
|---|---|
| STATE_ACCESS | 状态访问锁 |
| TRIGGER_ACCESS | 触发器访问锁 |
下面都以TRIGGER_ACCESS锁为例子讲解,Scheduler实例流程图:

比如一个Scheduler实例想要访问数据库来看是否有Trigger将要触发,那么它就开一个事务,并且首先获取并占用TRIGGER_ACCESS锁,然后再处理业务,比如说如果检查到有Trigger将要触发,就会去分配线程运行对应的任务。在此期间其他实例都无法访问所有与Trigger业务有关的数据表,处理完业务后commit work,结束事务,TRIGGER_ACCESS锁就被释放出来了,
抽象出来的mysql语句(方便理解):
mysql> begin work;
mysql> select * from QRTZ_LOCKS where t.lock_name='TRIGGER_ACCESS' for update
#在这里处理业务
mysql> commit work;
如果一个Scheduler实例获取了一个TRIGGER_ACCESS锁但是还没处理完就挂掉了,会导致与Trigger业务有关的表一直处于加锁状态无法被其他Scheduler实例访问,结果所有实例都没法工作了,因此Quartz又提出了一个接管锁的机制:
- 每个Scheduler实例都在QRTZ_SCHEDULER_STATE表里有自己的唯一ID,例如以hostname+time标识;
- 每个Scheduler实例的ClusterManager线程定期往QRTZ_SCHEDULER_STATE表更新LAST_CHECKIN_TIME作为心跳
- 当某个Scheduler实例超过一定时间没有心跳更新时,其它Scheduler实例得到这个信息,会接管对应的行锁,并恢复过时的任务
总结
总的来说,Quartz的分布式调度策略是以数据库为边界资源的一种异步策略。各个调度器都遵守一个基于数据库锁的操作规则从而保证了操作的唯一性,同时多个节点的异步运行保证了服务的可靠。
但这种Quartz的分布式调度策略有很多局限:
- 集群特性对于高CPU使用率的任务效果很好,但是对于大量的短任务,各个节点都会抢占数据库锁,这样就出现大量的线程等待资源。这种情况随着节点的增加会越来越严重。
- 没有实现比较好的负载均衡机制,仅依靠各个节点中的Scheduler实例随机抢占,可能会导致部分节点负载重,部分节点负载轻的情况。
- 不能满足更复杂的功能,如任务分片、编排、暂停重启、失败重试等。