<Java八股文面试>ArrayList源码 | Iterator源码 | LinkedList和ArrayList对比
文章目录
-
- 1. ArrayList
-
- 1.1 ArrayList 扩容规则介绍
- 1.2 ArrayList源码剖析
-
- 1.2.1 ArrayList构造方法和属性分析
- 1.2.2 add()方法
- 1.2.3 addAll()方法
- 2. Iterator
-
- 2.1 Fail-Fast 和 Fail-Safe 基本介绍
- 2.2 fail-fast和fail-safe源码剖析
- 2.3 补充:Vector底层使用的是哪种迭代机制呢?
- 3. LinkedList
-
- 3.1 对比LinkedList 和 ArrayList 的区别
- 3.2 代码对比两者性能
-
- 3.2.1 对比继承和实现关系
- 3.2.2 对比随机访问性能
- 3.2.3 对比插入功能
- 3.2.4 对比占用内存
1. ArrayList
1.1 ArrayList 扩容规则介绍
- ArrayList() 会使用长度为零的数组
- ArrayList(int initialCapacity) 会使用指定容量的数组
- public ArrayList(Collection c) 会使用 c 的大小作为数组容量
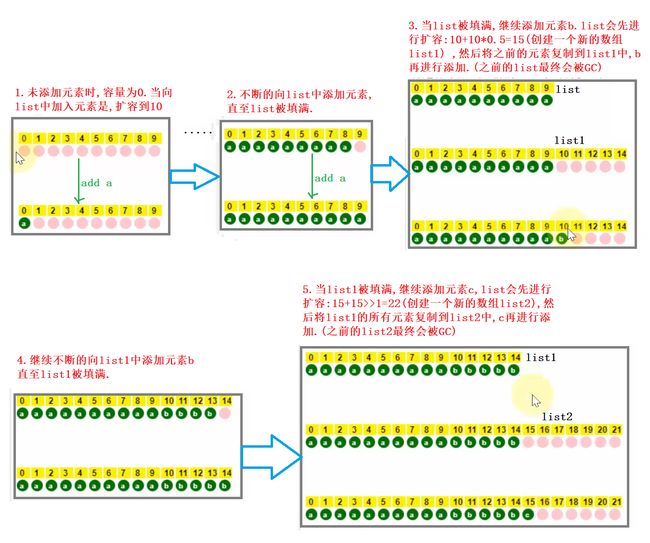
- add(Object o) 首次扩容为 10,再次扩容为上次容量的 1.5 倍
- addAll(Collection c) 没有元素时,扩容为 Math.max(10, 实际元素个数),有元素时为 Math.max(原容量的1.5 倍, 实际元素个数).即:下次扩容容量 和 实际元素个数之间选一个最大值.
备注:对于4和5,默认指的就是无参构造方法,要是有参就是在参数的基础上进行扩容啦.
图解
1.无参构造方法下add()方法扩容机制
代码演示:
/**
*
* 方法功能:测试ArrayList的扩容规则
* 1.ArrayList扩容前20次的结果:
* [0, 10, 15, 22, 33, 49, 73, 109, 163, 244, 366,549, 823, 1234, 1851, 2776, 4164, 6246, 9369, 14053, 21079]
* 2.步骤分析:22 = 15 + (15 >> 2); 49 = 33 + (33 >> 2)
* 3.可以看出,当元素个数为100个时,需要扩容的大小为109.
*/
private static List<Integer> arrayListGrowRule(int n) {
List<Integer> list = new ArrayList<Integer>();
int init = 0;
list.add(init);
if (n >= 1) {
init = 10;
list.add(init);
}
for (int i = 1; i < n; i++) {
init += (init) >> 1;
list.add(init);
}
return list;
}
/**
* 方法功能:当集合为空时,使用addAll()向集合中添加元素
* addAll方法扩容原理:下次扩容容量 和 实际元素个数之间选一个最大值.
*/
private static void testAddAllGrowEmpty() {//
ArrayList<Integer> list = new ArrayList<Integer>();
// list.addAll(List.of(1, 2, 3));//此时输出的length为10,
list.addAll(List.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11));//此时输出的length为11=> max(11,10)_
System.out.println(length(list));
}
/**
* 方法功能:当集合不为为空时,使用addAll()向集合中添加元素
*/
private static void testAddAllGrowNotEmpty() {
ArrayList<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
// list.addAll(List.of(1, 2, 3));//此时输出的length为15=>max(15,13)
list.addAll(List.of(1, 2, 3, 4, 5, 6));//此时输出的length为16=>max(15,16)
System.out.println(length(list));
}
1.2 ArrayList源码剖析
ArrayList是List接口的实现类,它是支持根据需要而动态增长的数组。java中标准数组是定长的,在数组被创建之后,它们不能被加长或缩短。这就意味着在创建数组时需要知道数组的所需长度,但有时我们需要动态程序中获取数组长度。ArrayList就是为此而生的。
1.2.1 ArrayList构造方法和属性分析
源码如下:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
/**
* 默认初始化容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 为空实例赋值的空数组对象.
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 空数组对象,和上面用途稍微不一样.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 存放元素的数组对象
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* 元素个数
*/
private int size;
//无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//初始化为一个空数组
}
//参数为容量的有参构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {//容量值为负数则抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
//参数为集合的有参构造
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {//集合不为空,则创建一个新的数组,并将元素复制到新数组里,elementData指向新数组.
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {// 如果是一个空集合初始化赋值,则直接将其赋值为空数组.
this.elementData = EMPTY_ELEMENTDATA;
}
}
}
结论
-
在无参构造中,我们看到了在用无参构造来创建对象的时候其实就是创建了一个空数组,长度为0
-
在参数为容量的构造中,传入的参数是正整数就按照传入的参数来确定创建数组的大小,否则异常
-
在参数为集合的构造中,传入的集合如果没有元素,则将其赋值为空数组.如果集合有元素,就创建一个新的数组,并将其元素赋值到新数组,更新集合中的数组对象引用.
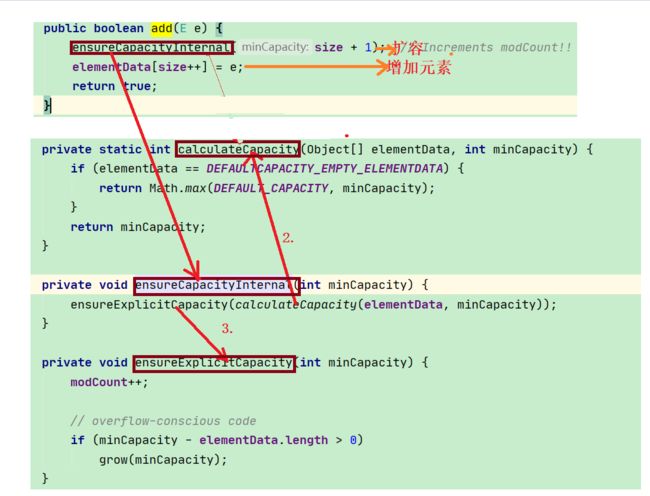
1.2.2 add()方法
总的来说就是分两步:
- 扩容:把原来的数组复制到另一个内存空间更大的数组中
- 复制(添加)元素到新数组:把新元素添加到扩容以后的数组中
源码如下:
//计算需要扩容的容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
//如果在添加的时候远数组是空的,取默认容量与minCapacity之间的最大值.
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 扩容后的为 Max(默认容量 , 加入元素后的容量) ,这样可以保证只扩容一次.
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
//如果ArrayList不为空,就返回加入元素后的容量 (之前的元素容量+1)
return minCapacity;
}
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果所需容量 比 elementData实际的容量 要小,则需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);//扩容
}
//注意:minCapacity代表加入 元素后需要的容量
//elementData:实际存放元素的数组, 和 minCapacity大小关系不确定.
接下来重点来了,ArrayList扩容的关键方法grow():
//扩容方法
private void grow(int minCapacity) {
//获取到ArrayList中elementData数组的内存空间长度
int oldCapacity = elementData.length;
//计算扩容后的大小:扩容至原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 再判断一下新数组的容量够不够,够了就直接使用这个长度创建新数组. 如果不够,则直接使用minCapacity 的值,这样可以避免重复扩容.
if (newCapacity - minCapacity < 0)
// 不够就将数组长度设置为需要的长度
newCapacity = minCapacity;
//若预设值大于默认的最大值检查是否溢出
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 调用Arrays.copyOf方法将elementData数组指向新的内存空间时newCapacity的连续空间
// 并将elementData的数据复制到新的内存空间
elementData = Arrays.copyOf(elementData, newCapacity);
}
结论: 从方法中我们可以清晰的看出其实ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。
1.2.3 addAll()方法
通过观察addAll()方法源码,可以看到其原理和add()方法类似,都是先扩容,再将数组内容复制到新数组.
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
2. Iterator
2.1 Fail-Fast 和 Fail-Safe 基本介绍
-
ArrayList 是 fail-fast 的典型代表,遍历的同时不能修改,尽快失败
-
CopyOnWriteArrayList 是 fail-safe 的典型代表,遍历的同时可以修改,原理是读写分离
代码演示
public class FailFastVsFailSafe {
// fail-fast 一旦发现遍历的同时其它人来修改,则立刻抛异常
// fail-safe 发现遍历的同时其它人来修改,应当能有应对策略,例如牺牲一致性来让整个遍历运行完成
//ArrayList属于fail-fast类型
private static void failFast() {
ArrayList<Student> list = new ArrayList<>();
list.add(new Student("A"));
list.add(new Student("B"));
list.add(new Student("C"));
list.add(new Student("D"));
for (Student student : list) {
System.out.println(student);
}
System.out.println(list);
}
//CopyOnWriteArrayList属于fail-safe类型
private static void failSafe() {
CopyOnWriteArrayList<Student> list = new CopyOnWriteArrayList<>();
list.add(new Student("A"));
list.add(new Student("B"));
list.add(new Student("C"));
list.add(new Student("D"));
for (Student student : list) {
System.out.println(student);
}
System.out.println(list);
}
static class Student {
String name;
public Student(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
public static void main(String[] args) {
failFast();
// failSafe();
}
}
运行结果
1.测试fail-fast
- 添加断点
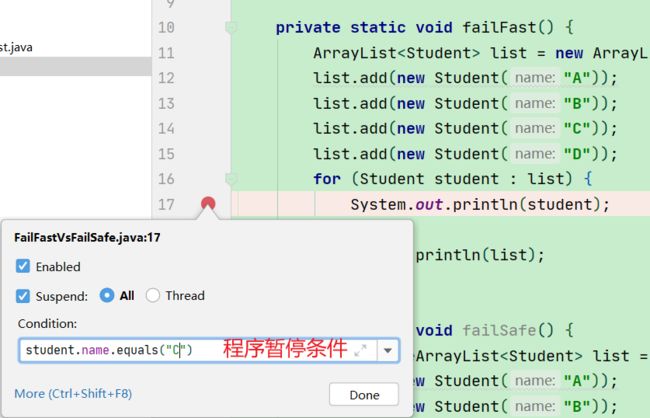
- 在迭代过程中未list增加一个新项
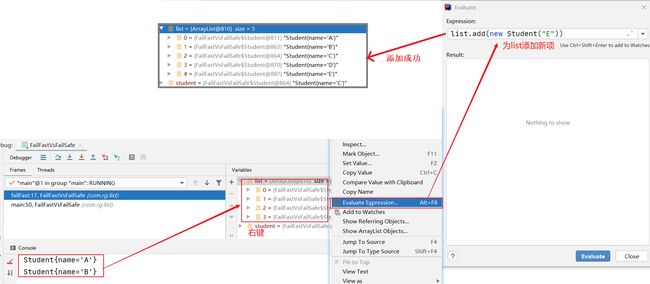
- 程序报错

2.测试fail-safe
添加断点和添加新项和上面一致. 贴一下最终的运行结果:

根据结果可以得出结论:copyonwrite是把原集合复制出来,在新集合上进行修改,修改好后指向新集合。现在遍历的是旧集合不影响
2.2 fail-fast和fail-safe源码剖析
fail-fast源码分析
-
当使用增强for迭代list集合时,会先创建一个Itr对象(属于Iterator类),为属性expectedModCount初始化.
-
expectedModCount的初始值为list中的modCount (modCount 是list的成员变量,记录list被修改的次数)
-
之后每次迭代list就是用Itr对象.先判断hasNext()是否有值,如果则调用NEXT()方法进行获取.
-
NEXT()方法执行时,会先判断是否存在并发修改.如果存在则抛出异常,不存在则返回需要的元素.
分析演示场景: 迭代过程中为list增加了一个元素,导致modCount变成了5,但是expectedModCount还为4.所以Next()中验证是否存在修改时就会报异常.
private class Itr implements Iterator<E> {
int cursor; // 返回下一个元素的下标
int lastRet = -1; // 返回最后一个元素的下标,如果没有则返回-1
int expectedModCount = modCount;//迭代器对象刚进行迭代时修改的初始次数(也就是循环开始时的修改次数)
Itr() {}//构造方法
public boolean hasNext() {//判断是否还有下一个元素
return cursor != size;//如果5个元素 size:5 当遍历完最后一个元素后再次迭代时,cursor=5,返回false.
}
public E next() {//获取下一个元素,通知迭代器的指针后移一位.
checkForComodification();//检查是否存在并发修改
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;//指向后移
return (E) elementData[lastRet = i];//返回需要的元素
}
//检查是否在迭代过程中进行了修改
final void checkForComodification() {
if (modCount != expectedModCount)//如果进行了修改modCount就会增加,导致这俩属性值不相等,抛出并发修改异常
throw new ConcurrentModificationException();
}
}
fail-safe源码分析
-
当使用增强for迭代list集合时,会先创建一个COWIterator对象,将需要迭代的集合赋值给 snapshot,cursor初始化为0.
-
之后每次迭代list就是使用COWIterator对象,先hasNext()判断是否有值.然后调用Next()获取值.
**分析演示场景:**当进行for遍历时,会把需要遍历的集合在COWIterator中存一份.之后每次遍历都是使用COWIterator中的数组对象. 当在遍历过程中进行add操作时,会创建一个新的数组,将老的元素和新的元素放入,再赋值给list集合中的数组对象.这个过程也被称为 写时复制(读写分离)
所以最后输出结果是:遍历出的没有新元素E,list直接输出有新元素E
//COWIterator
static final class COWIterator<E> implements ListIterator<E> {
/** 数组的快照 */
private final Object[] snapshot;
/** 返回元素的下一个坐标. */
private int cursor;
//构造器
COWIterator(Object[] es, int initialCursor) {
cursor = initialCursor;
snapshot = es;
}
//判断是否有下一个袁旭
public boolean hasNext() {
return cursor < snapshot.length;
}
//获取下一个元素的值.
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];//cursor指针后移
}
}
//CopyOnWriteArrayList类
public class CopyOnWriteArrayList<E> implements List<E>{
final transient Object lock = new Object();
//数组对象用于存放元素
private transient volatile Object[] array;
/**
* Gets the array. Non-private so as to also be accessible
* from CopyOnWriteArraySet class.
*/
final Object[] getArray() {
return array;
}
//添加元素
public boolean add(E e) {
synchronized (lock) {
Object[] es = getArray();//获取之前的数组对象
int len = es.length;//获取长度
es = Arrays.copyOf(es, len + 1);//创建一个 len + 1 的新数组
es[len] = e;//将新的值放在最后一个位置上.
setArray(es);//将新数组对象赋值给list中的array
return true;
}
}
}
2.3 补充:Vector底层使用的是哪种迭代机制呢?
Vector其实就比ArrayList多了个同步机制,也就是每个方法加上了synchronized.
经过Debug发现,Vector使用的也是Itr作为迭代器,其迭代类型属于:Fail-Fast.
代码演示
private static void testVector(){
Vector <Student> vector = new Vector <>();
vector.add(new Student("A"));
vector.add(new Student("B"));
vector.add(new Student("C"));
vector.add(new Student("D"));
for (Student student : vector) {
System.out.println(student);
}
System.out.println(vector);
}
3. LinkedList
3.1 对比LinkedList 和 ArrayList 的区别
LinkedList
- 基于双向链表,无需连续内存
- 随机访问慢(要沿着链表遍历)
- 头尾插入删除性能高
- 无法很好的利用CPU缓存,无法很好的配合局部性原理,占用内存多,
ArrayList
- 基于数组,需要连续内存
- 随机访问快(指根据下标访问)
- 尾部插入、删除性能可以,其它部分插入、删除都会移动数据,因此性能会低 (但是性能也可以秒杀LinkedList)
- 可以很好的利用CPU缓存,配合局部性原理,占用内存少,
3.2 代码对比两者性能
3.2.1 对比继承和实现关系
根据继承和实现关系,可以看出 ArrayList比LinkedList多实现一个RandomAccess接口.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{}
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{}
RandomAccess是个标记接口, 主要用于标记该类使用下标进行访问的,还是利用指针进行访问的.
/*
*
* for (int i=0, n=list.size(); i < n; i++)
* list.get(i);
*
* 上面这种循环比下面这种循环效率更高:
*
* for (Iterator i=list.iterator(); i.hasNext(); )
* i.next();
*
*
* @since 1.4
*/
public interface RandomAccess {//标记接口,不做任何实现.
}
3.2.2 对比随机访问性能
public static void main(String[] args) {
int n = 1000;
int insertIndex = n;
//产生1000个随机数,测试对比ArrayList和LinkedList的随机访问性能
for (int i = 0; i < 5; i++) {//测试五次(JVM要预热一下,次数越多越准确O!)
int[] array = randomArray(n);
List<Integer> list1 = Arrays.stream(array).boxed().collect(Collectors.toList());
LinkedList<Integer> list2 = new LinkedList<>(list1);
randomAccess(list1, list2, n / 2);//访问中间的数
}
}
//随机访问方法
static void randomAccess(List<Integer> list1, LinkedList<Integer> list2, int mid) {
StopWatch sw = new StopWatch();
sw.start("ArrayList");
list1.get(mid);
sw.stop();
sw.start("LinkedList");
list2.get(mid);
sw.stop();
System.out.println(sw.prettyPrint());
}
测试结果:
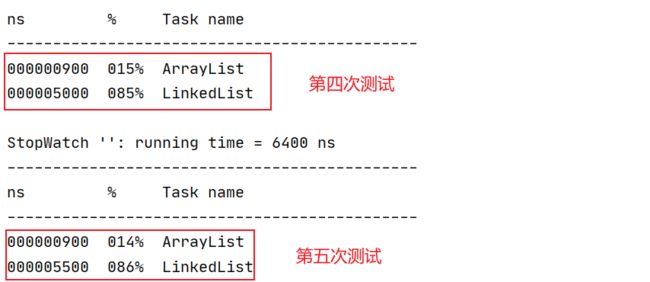
3.2.3 对比插入功能
- 头部插入对比
private static void addFirst(List<Integer> list1, LinkedList<Integer> list2) {
StopWatch sw = new StopWatch();
sw.start("ArrayList");
list1.add(0, 100);
sw.stop();
sw.start("LinkedList");
list2.addFirst(100);
sw.stop();
System.out.println(sw.prettyPrint());
}
结果:LinkedList远超于ArrayList.

- 尾部插入对比
private static void addLast(List<Integer> list1, LinkedList<Integer> list2) {
StopWatch sw = new StopWatch();
sw.start("ArrayList");
list1.add(100);
sw.stop();
sw.start("LinkedList");
list2.add(100);
sw.stop();
System.out.println(sw.prettyPrint());
}
结果:ArrayList更快一些
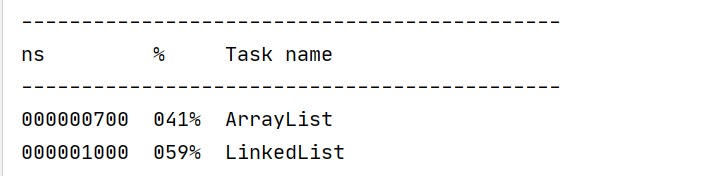
- 中间插入
private static void addMiddle(List<Integer> list1, LinkedList<Integer> list2, int mid) {
StopWatch sw = new StopWatch();
sw.start("ArrayList");
list1.add(mid, 100);
sw.stop();
sw.start("LinkedList");
list2.add(mid, 100);
sw.stop();
System.out.println(sw.prettyPrint());
}
结果:ArrayList远超于LinkedList (因为LinkedList的迭代过程非常缓慢)
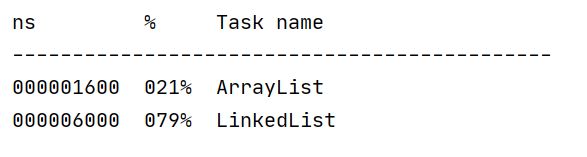
总结:
-
传统的
ArrayList:增删慢,查询快 LinkedList:增删快,查询慢说法是完全错误的. -
ArrayList除了头部插入比LinkedList效率低,其他方面都是超于LinkedList. 所以实际项目开发中,建议使用ArrayList.
3.2.4 对比占用内存
没有CPU缓存前:数据的运算,先将数据从硬盘读到CPU,然后CPU执行计算,计算完写到硬盘.但是CPU的计算速度是很快的(1s执行亿次级),例如CPU执行指令<1nm,但是读数据到CPU和写数据到硬盘却需要几百nm,CPU利用率极低.
有了CPU缓存:数据的运算,先将数据从硬盘加载到缓存中,然后CPU从缓存中读数据(可以提高到10nm),接着CPU进行运算,运算完将结果写到缓存,由缓存将数据写入硬盘.CPU的效率可以大大提高.
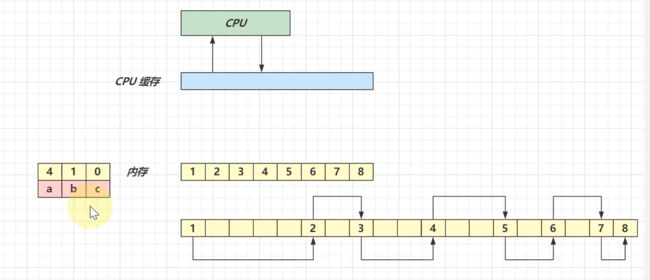
局部性原理: 读取元素时,其相邻元素也有很大概率被访问到.
-
对于ArrayList,会将其相邻元素也加载进入缓存,由于其元素在内存是是连续的.下次使用就不用再重新加载了,直接从缓存中取.
-
而对于LinkedList,由于其数据存储并不是连续的.虽然也将即将使用的数据及其相邻内存的数据加入缓存,但是后面需要的数据可能并不在当前的缓存中.而且一般缓存也是很小的,后面加入的数据可能覆盖前面的.所以需要经常将数据加入缓存. 从而无法很好的配合局部性原理.
如果有收获!!! 希望老铁们来个三连,点赞、收藏、转发。
创作不易,别忘点个赞,可以让更多的人看到这篇文章,顺便鼓励我写出更好的博客