网络基础2--HTTP协议详解
目录
一、自定制协议
二、TCP粘包问题
2.1. 定长结构体和非定长结构体在发送时的区别
2.2. 那么为什么内存不连续的结构体不能直接使用send发送呢?
2.2. 那我们怎样去接收不定长的数据呢?
2.3. 我们怎样去接收不连续的内存呢?
2.4序列化和反序列化
三、HTTP协议
3.1 http协议概述
3.2 HTTP的URL解释
3.3 HTTP协议的数据流
3.4 HTTP协议的格式
3.4.1、请求格式
3.4.2、响应格式
3.5 HTTP的请求方法:
面试题: GET方法和POST谁更安全
3.6 分析请求体的内容:
3.7 HTTP的响应状态码
3.7.1 为什么需要状态码?
3.8 HTTP常见的header
主要讲的是应用层和传输层

一、自定制协议
就是程序员在应用层约定应用层格式的
我们先来实现一个网络版本的计算器
思路:
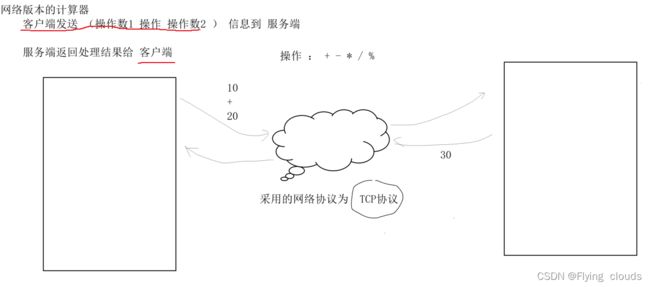
实现:

引出到底什么是自定制协议?

二、TCP粘包问题
tcp的面向字节流的特性,导致了tcp粘包的问题
针对接收方而言,没有办法区分数据是发送了几次,前后发送的数据是没有间隔符的,粘连在一起的

2.1. 定长结构体和非定长结构体在发送时的区别

2.2. 那么为什么内存不连续的结构体不能直接使用send发送呢?
我们先来看看内存连续结构体的发送原理:
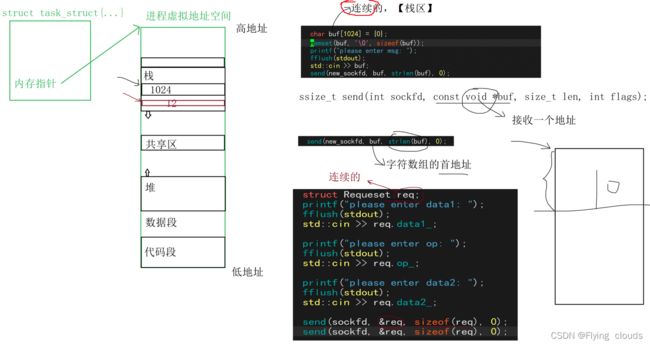
我们再来看看不定长的结构体

2.2. 那我们怎样去接收不定长的数据呢?
比如发送了两次数据,一次10字节,一次100字节,怎么去接收呢?

1.tcp在传输数据的时候可以加上大小
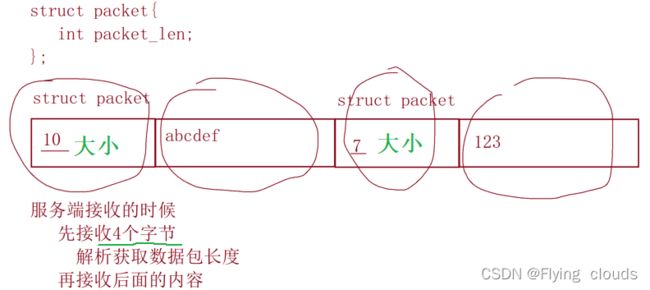
先接收4个字节,解析数据包的长度,再去接收后面的内容
这就解决了粘连的问题
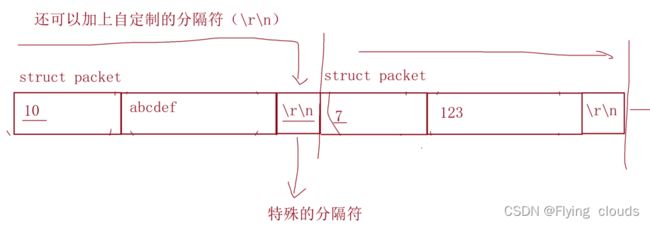
2.还可以加上自定制的分隔符 (\r\n)
2.3. 我们怎样去接收不连续的内存呢?
比如这一种数据,存放的是首字符的地址
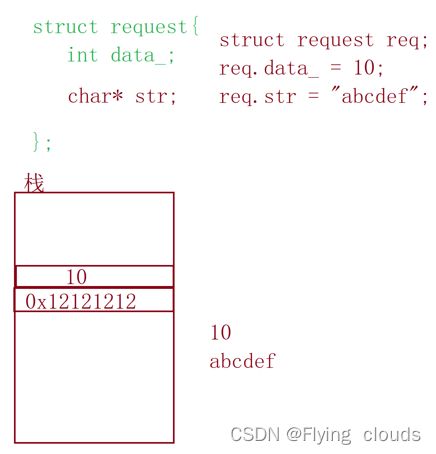
这就需要引出序列化和反序列化
2.4序列化和反序列化
序列化: 将程序当中的数据结构转化成为二进制序列;
数据结构:
内存如果是连续的,直接就可以发送。 例如: 结构体
内存如果是不连续的, 序列化就是将不同的内存组合起来, 放到一块连续的空间当中,发送出去。例如: 链表多个节点

反序列化: 将二进制转化成为数据结构。
三、HTTP协议
3.1 http协议概述
超文本传输协议

3.2 HTTP的URL解释
我们来看下完整的URL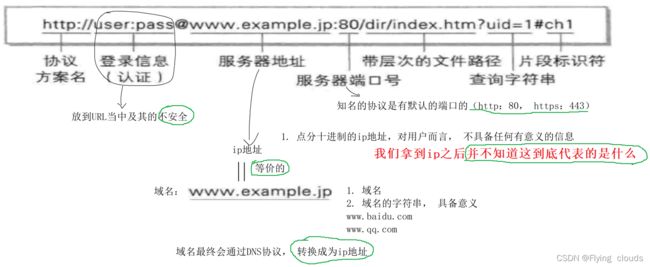
带层次的文件路径:
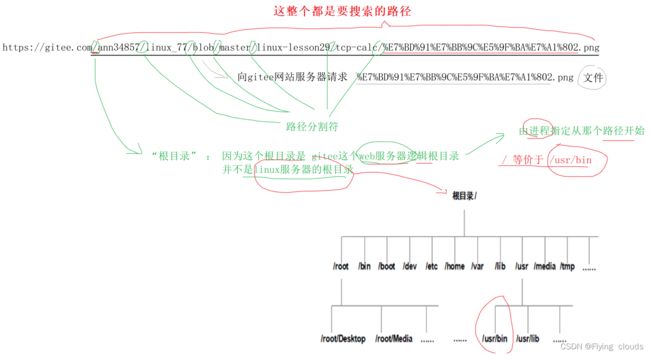
查询字符串:

URL每个部分的总结:

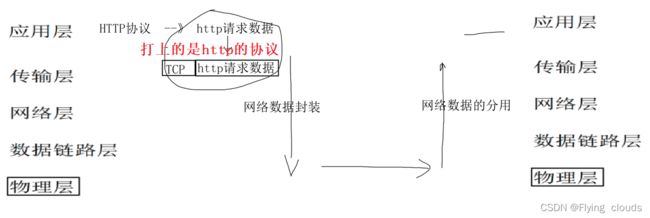
3.3 HTTP协议的数据流
首先要知道:HTTP协议是应用层协议,他在网络协议栈使用到的下层(传输层)协议是TCP协议
直白一点就是:HTTP协议产生的数据,是交给了传输层的TCP协议传输的
3.4 HTTP协议的格式
3.4.1、请求格式
利用tcp模拟HTTP的服务端,去接受浏览器给服务端发送的请求
代码和之前的差不多,我们来看下工作线程的功能:

我们模仿URL在网站上搜索:
这时候显示网页无法正常工作是因为我们并没有给网页发任何消息
但是我们这时候能够发现,我们接收到了网页给我们发送的请求:下面就是请求的内容

我们可以来分析一下这个到底是什么 ,分析一下HTTP的请求格式到底是什么:
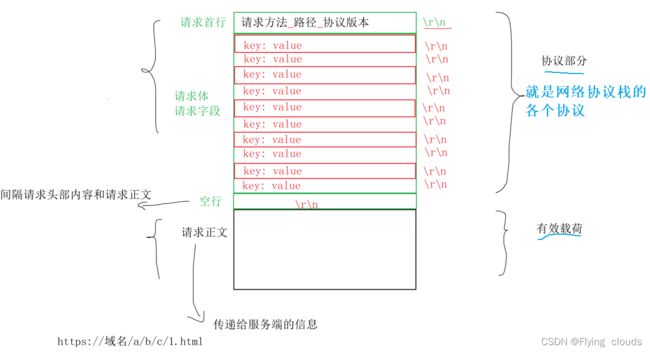
请求首行: 请求方法, 路径, 协议版本
3.4.2、响应格式

我们现在模拟server给浏览器发送一个响应:

我们在浏览器中给server发送一个请求,观察收到的响应是什么样的

3.5 HTTP的请求方法:

请求方法重点的是GET 和 POST
GET:问服务端要抹些资源

PST:给服务端提交数据
POST提交的数据在正文当中:
例如: username=xxx&&passwd=xxx
eg:假设我们要在某个网页进行登录,使用POST请求就会将我们的账号,密码放在请求正文中进行提交
面试题: GET方法和POST谁更安全

路径:
就是我们想要请求资源的路径
协议版本:
HTTP 0.9,HTTP 1.0,HTTP 1.1 ,HTTP 2.0(还在研发)
目前使用最多的就是HTTP1.1
3.6 分析请求体的内容:
请求体可以有很多条 key:value


3.7 HTTP的响应状态码
3.7.1 为什么需要状态码?
浏览器发起了一个HTTP请求,web服务器要告诉浏览器一个状态码(刚刚发起的请求是处理成功了还是失败了)

常见的测试码:

3.8 HTTP常见的header
- Content-Length: 正文的长度
- Content-Type : 正文的类型
- location : 重定向地址,一般搭配3 x x 使用
- Set-Cookie :设置Http Cookie
Cookie 和 Session
Cookie: 浏览器保存的信息,一般是客户端的一些不敏感的信息,Cookie数据的来源自服务端,
在浏览器保存。当下次在请求服务端的某个资源的时候,会携带上
Session:session 数据保存在服务端,一般描述当前会话信息(例如:浏览器的信息,浏览器访问到哪个页面等等)
Cookie:
应用场景:
为什么: 在访问百度的时候,第一次是需要进行登录的,但第二次的时候就不需要再进行登录了
就是因为在第一次登录的时候,登录成功的时候,百度服务器会给浏览器返回一个登录成功的的响应,在响应中就有一些Cookie信息,
下次再来访问的时候就会携带着这些Cookie信息,这些Cookie信息让服务端解析后就能知道是谁登录了。
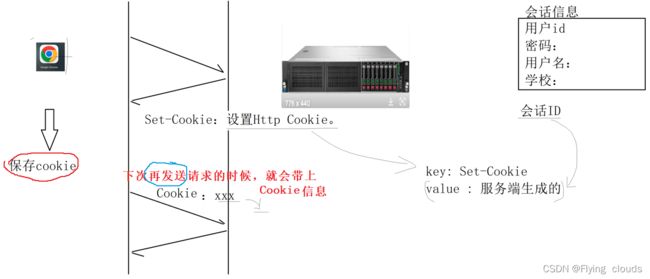
我们也可以利用代码去实验一下Cookie的作用:
我们的服务端给浏览器返回一个Cookie信息

当然:我们这里的Cookie信息设置的是很随意的,平时网站上的Cookie设计的时候是非常复杂的