Python中xpath解析
文章目录
- 简介
-
- 安装
- 本文示例的html代码
- 使用
-
- 实例化etree
- xpth表达式
-
- 定位
-
- 根据层级定位
- 根据属性进行定位
- 根据id进行定位
- 根据索引号进行定位
- 取值
-
- 获取文本
- 获取属性
- 实例
简介
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
安装
pip install lxml
本文示例的html代码
<div>
<div>
<ul>
<li class="item-0">
<a href="link1.html">first itema>
li>
<li class="item-1">
<a href="link2.html">second itema>
li>
ul>
div>
<div id="111">
<div class="item-1">
<a href="www.qq.com">qq.coma>
<p>this is p labelp>
<ul>
<li class="item-2">
<a href="link1.html">first item1a>
li>
<li class="item-3">
<a href="link2.html">second item2a>
li>
ul>
div>
<a href="www.baidu.com">baidu.coma>
div>
div>
使用
实例化etree
from lxml import etree
# 将本地的html文件加载etree对象中
html = etree.parse("file_path")
# 将互联网上获取的源码数据加载到该对象中
html = etree.HTML(resp.text)
result = etree.tostring(html) # 格式化html代码
xpth表达式
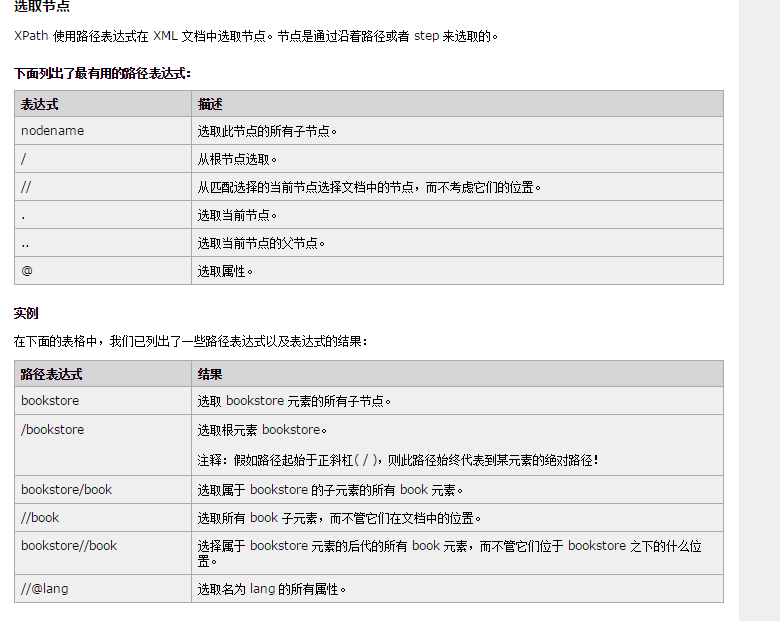
定位
根据层级定位
- / :表示从根节点开始定位
- // :表示多个层级,可以从任意位置开始定位
- ./:从当前位置开始定位
根据属性进行定位
text = html.xpath("/div[1]//li[@class='item-0']")
根据id进行定位
text = html.xpath("//div[@id='111']")
根据索引号进行定位
text = html.xpath("/div/div[1]/ul/li[2]/a/text()") # 注意xpath索引是从1开始的
取值
获取文本
- 该节点下的直系文本:
/text() - 该节点下的所有文本:
//text()
from lxml import etree
wb_data = """
"""
html = etree.HTML(wb_data) # 实例化HTML对象
# 获取/div/div[2]下面的所有文本内容
text = html.xpath("//div[@id='111']//text()")
print([i.strip() for i in text]) # 去除换行符,空格等
# 获取/div/div[1]/ul/li[1]/里面的文本信息
print(html.xpath("//li[@class='item-0']/a/text()")[0])
获取属性
/@属性名称:获取该节点下的直系属性值//@属性名称:获取该节点下的所有属性值
from lxml import etree
wb_data = """
"""
html = etree.HTML(wb_data) # 实例化HTML对象
# 获取/div/div[2]/div/下所有的href值
print(html.xpath("//div[@class='item-1']//@href"))
# 获取/div/div[2]/a下的href值
print(html.xpath("//div[@id='111']/a/@href")[0])
实例
首先自制了一个多线程爬虫模块用于发送请求,模块名称为MyModule
import threading, queue
"""爬虫多线程"""
class SpiderThread(threading.Thread):
def __init__(self) -> "里面包含了请求头和代理IP 代理ip自己设置":
super().__init__(daemon=True) # daemon线程等待,target是运行的函数
# 开启队列对象
self.queue = queue.Queue()
# 线程
self.start() # 实例化的时候自动运行run函数
try:
# 构建ip池,此ip地址仅支持http请求
file = open("./ip.txt", "r") # 得到大量ip地址,与文件同一目录下,存储http类型的ip池
ipList = file.readlines()
file.close()
import random
self.ip = random.choice(ipList).strip()
except Exception as e:
print(f"没有批量ip地址,使用本机ip地址{e}")
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 80))
import random
self.ip = s.getsockname()[0] + f":{random.randint(1, 8080)}" # 获取本电脑的ip地址,同时随机使用端口访问网址
s.close()
# 传入requests所需要的参数
self.headers = {
'User-Agent': "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 96.0.4664 .93 Safari / 537.36"
}
self.proxy = {
"http": f"https://{self.ip}",
# 注意:如果请求的ip是https类型的,但代理的ip是只支持http的,那么还是使用本机的ip,如果请求的ip是http类型的,那么代理的ip一定要是http的,前面不能写成https,否则使用本机IP地址
}
def run(self) -> None: # run方法线程自带的方法,内置方法,在线程运行时会自动调用
while True: # 不断处理任务
func, args, kwargs = self.queue.get()
func(*args, **kwargs) # 调用函数执行任务 元组不定长记得一定要拆包
self.queue.task_done() # 解决一个任务就让计数器减一,避免阻塞
# 生产者模型
def submit_task(self, func, args=(), kwargs={}): # func为要执行的任务,加入不定长参数使用(默认使用默认参数)
self.queue.put((func, args, kwargs)) # 提交任务
# 重写join方法
def join(self):
self.queue.join() # 查看队列计时器是否为0 任务为空 为空关闭队列
def crawl(url, lis, cookies=None, headers=SpiderThread().headers,
proxy=SpiderThread().proxy) -> "lis用来存储返回的resp响应 其是发送get请求": # cookies是一个字典
import requests
if not isinstance(cookies, dict):
resp = requests.get(url=url, headers=headers, proxies=proxy)
else:
resp = requests.get(url=url, headers=headers, cookies=cookies)
if resp.status_code == 200:
print("获取完成,返回的数据在传入的列表里面")
lis.append(resp) # 多线程没有返回值
else:
SpiderThread().submit_task(crawl, args=(i, lis))
# 爬取58同城中全国销售职位的名称
from lxml import etree
import MyModule
from concurrent.futures import ThreadPoolExecutor
spider = MyModule.SpiderThread() # 实例化爬虫对象
"""
通过分析url可得到 url = 'https://nc.58.com/yewu/pu1/?key=%E9%94%80%E5%94%AE';
又第二页的 url = 'https://nc.58.com/yewu/pn2/?key=%E9%94%80%E5%94%AE'
"""
# 得到所有页面的url
def spider1():
resp = [] # 接收返回的页面源代码
url = "https://nc.58.com/yewu/?key=%E9%94%80%E5%94%AE"
spider.submit_task(MyModule.crawl, args=(url, resp))
spider.join() # 等待线程完成
page_source = resp[0].text # 得到页面源码
html = etree.HTML(page_source) # 实例化etree对象
num = int(html.xpath("/html/body/div[3]/div[3]/div/div/div/span[2]/text()")[0]) # 通过分析网页可得该xpath解析
return [f"https://nc.58.com/yewu/pn{i}/?key=%E9%94%80%E5%94%AE" for i in range(1, num)]
def crawl():
respAll = [] # 存储响应
for i in spider1():
spider.submit_task(MyModule.crawl, args=(i, respAll)) # 运行封装的模块
spider.join() # 等待全部线程完成
return [i.text for i in respAll] # 返回响应源代码
def save(resp_text):
html = etree.HTML(resp_text)
torr = html.xpath("//*[@id='list_con']/li")
file = open("./a.txt", "a+", encoding="utf-8") # 写入文件
for i in torr:
temp = i.xpath("./div[1]//a//text()")
name = "".join(temp) # 将名字组装
file.write(f"名称:{name}")
file.close()
def main(respAll):
with ThreadPoolExecutor(50) as pool: # 使用线程池,开启50个线程,对文件进行存储
pool.map(save, respAll)
if __name__ == '__main__':
main(crawl()) # 注意:由于是高性能爬虫,电脑的ip地址很大概率会被58同城封了,尽量使用代理ip