Hadoop2.X之高可用简介及环境搭建
Hadoop2.0之高可用
Hadoop2.0产生背景
-
Hadoop 1.0中HDFS和MapReduce在高可用、扩展性等方面存在问题
-
HDFS存在的问题(2个)
- NameNode单点故障,难以应用于在线场景 HA(高可用)
- NameNode压力过大,且内存受限,影响扩展性 F(federation,多个NameNode同时工作)
-
MapReduce存在的问题响系统
-
JobTracker访问压力大,影响系统扩展性
-
难以支持除MapReduce之外的计算框架,比如Spark、Storm等
-
Hadoop 1.x与Hadoop 2.x

-
Hadoop 2.x由HDFS、MapReduce和YARN三个分支构成;
- HDFS:NN Federation(联邦)、HA;
- 2.X:只支持2个节点HA,3.0实现了一主多从
- MapReduce:运行在YARN上的MR;
- 离线计算,基于磁盘I/O计算
- YARN:资源管理系统•YARN:资源管理系统
- HDFS:NN Federation(联邦)、HA;
-
HDFS 2.x
- 解决HDFS 1.0中单点故障和内存受限问题。
- 解决单点故障
- HDFS HA:通过主备NameNode解决
- 如果主NameNode发生故障,则切换到备NameNode上
- 解决内存受限问题
- HDFS Federation(联邦)
- 水平扩展,支持多个NameNode;
- (Hadoop2)每个NameNode分管一部分目录;
- (Hadoop1)所有NameNode共享所有DataNode存储资源
- 2.x仅是架构上发生了变化,使用方式不变
- 对HDFS使用者透明
- HDFS 1.x中的命令和API仍可以使用
Hadoop2.0主从架构(HA 高可用机制)
[外链图片转存失败(img-I0nVEOFn-1564134601501)(pic\Hadoop2.0主从架构图.png)]
- 主备NameNode
- 解决单点故障(属性,位置)
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有DataNode同时向两个NameNode汇报数据块信息(位置)
- JNN:集群(属性)
- standby:备,完成了edits.log文件的合并产生新的image,推送回ANN
- 两种切换选择
- 手动切换:通过命令实现主备之间的切换,可以用HDFS升级等场合
- 自动切换:基于Zookeeper实现
- 基于Zookeeper自动切换方案(投票选举)
- ZooKeeper Failover Controller:监控NameNode健康状态,
- 并向Zookeeper注册NameNode
- NameNode挂掉后,ZKFC为NameNode竞争锁,获得ZKFC 锁的NameNode变为active
HDFS 2.x Federation
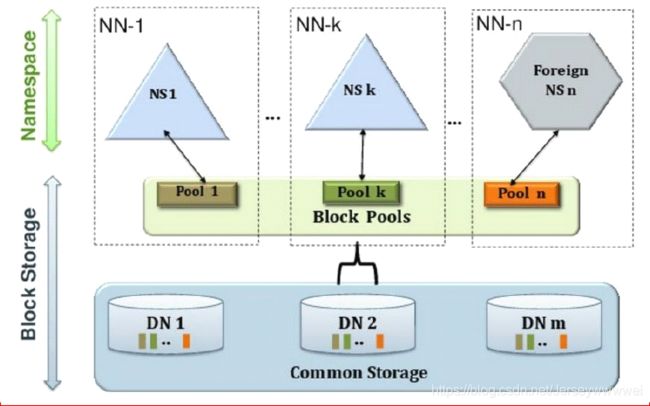
- 通过多个Namenode/Namespace把元数据的存储和管理分散到多个节点中,使到Namenode/Namespace可以通过增加机器来进行水平扩展。
- 能把单个Namenode的负载分散到多个节点中,在HDFS数据规模较大的时候不会也降低HDFS的性能。可以通过多个Namespace来隔离不同类型的应用,把不同类型应用的HDFS元数据的存储和管理分派到不同的Namenode中。
Hadoop高可用搭建
官方文档:http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
节点部署
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| Node01 | * | * | * | |||
| Node02 | * | * | * | * | * | |
| Node03 | * | * | * | |||
| Node04 | * | * |
搭建过程
-
关闭节点,并用jps进行检验
-
实现NN01和NN02之间的免密钥操作
[root@node02 software]# cd /root/.ssh/[root@node02 .ssh]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa[root@node02 .ssh]# cat id_dsa.pub >> authorized_keys[root@node02 .ssh]# ssh localhost[root@node02 ~]# exit[root@node02 .ssh]# scp id_dsa.pub node01:`pwd`/node02.pub[root@node01 ~]# cd /root/.ssh/[root@node01 .ssh]# cat node02.pub >> authorized_keys
-
在NameNode-1中配置nameservice的逻辑名称
[root@node01 hadoop]# vi hdfs-site.xml<configuration> <property> <name>dfs.replicationname> <value>2value> property> <property> <name>dfs.nameservicesname> <value>myclustervalue> property> configuration> -
配置两个NameNode的ID(仅仅是逻辑名称)
<property> <name>dfs.ha.namenodes.myclustername> <value>nn1,nn2value> property> -
配置两个NameNode的物理地址(为了两者之间的RPC(remote procedure call))
dfs.namenode.rpc-address.mycluster.nn1
node01:8020
dfs.namenode.rpc-address.mycluster.nn2
node02:8020
-
配置每个节点的HTTP地址让每个NameNode节点监听相同的RPC地址
<property> <name>dfs.namenode.http-address.mycluster.nn1name> <value>node01:50070value> property> <property> <name>dfs.namenode.http-address.mycluster.nn2name> <value>node02:50070value> property> -
配置JournalNode的节点分享信息
<property> <name>dfs.namenode.shared.edits.dirname> <value>qjournal://node01:8485;node02:8485;node03:8485/myclustervalue> property> -
配置故障转移类,用于在故障转移期间屏蔽Active NameNode
<property> <name>dfs.client.failover.proxy.provider.myclustername> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue> property> -
配置私钥文件,在NameNode01挂掉的情况下,NameNode02立即接管,私钥地址要进行更改
<property> <name>dfs.ha.fencing.methodsname> <value>sshfencevalue> property> <property> <name>dfs.ha.fencing.ssh.private-key-filesname> <value>/root/.ssh/id_dsavalue> property> -
配置全部配置文件
<configuration> <value>myclustervalue> property> property> <value>nn1,nn2value> <name>dfs.namenode.rpc-address.mycluster.nn1name> <value>node01:8020value> <value>node01:50070value> property> <property> <name>dfs.namenode.http-address.mycluster.nn2name> <value>node02:50070value> property> <property> <name>dfs.namenode.shared.edits.dirname> <value>qjournal://node1:8485;node2:8485;node3:8485/myclustervalue> property> <property> <name>dfs.client.failover.proxy.provider.myclustername> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue> property> <property> <name>dfs.ha.fencing.methodsname> <value>sshfencevalue> property> <property> <name>dfs.ha.fencing.ssh.private-key-filesname> <value>/root/.ssh/id_dsavalue> property> configuration> -
[root@node01 hadoop]# vi core-site.xml<configuration> <property> <name>fs.defaultFSname> <value>hdfs://myclustervalue> property> <property> <name>hadoop.tmp.dirname> <value>/var/sxt/hadoop/havalue> property> configuration> -
配置JournalNode
[root@node01 hadoop]# vi hdfs-site.xml<property> <name>dfs.journalnode.edits.dirname> <value>/var/sxt/hadoop/ha/journalnodevalue> property> -
配置自动故障转移
[root@node01 hadoop]# vi hdfs-site.xmldfs.ha.automatic-failover.enabled true -
配置集群以进行自动故障转移
<property> <name>ha.zookeeper.quorumname> <value>node02:2181,node03:2181,node04:2181value> property> -
将修改完的文件分发到别的节点
[root@node01 hadoop]# scp core-site.xml hdfs-site.xml node02:`pwd` [root@node01 hadoop]# scp core-site.xml hdfs-site.xml node03:`pwd` [root@node01 hadoop]# scp core-site.xml hdfs-site.xml node04:`pwd` -
在2,3,4节点安装zookeeper,并配置
-
[root@node02 software]# tar xf zookeeper-3.4.6.tar.gz -C /opt/sxt/ -
[root@node02 sxt]# cd zookeeper-3.4.6/conf -
[root@node02 conf]# mv zoo_sample.cfg zoo.cfg -
[root@node02 conf]# vi zoo.cfg -
dataDir=/var/sxt/zk -
在末尾添加如下文字,2888指主从节点之间的通信端口号,3888指主挂断之后,产生的选举机制
server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888 -
将配置完的zookeeper分发到node03,node04,先要退到zookeeper的安装目录
[root@node02 sxt]# scp -r zookeeper-3.4.6/ node03:`pwd[root@node02 sxt]# scp -r zookeeper-3.4.6/ node04:`pwd -
配置每台服务器的编号
[root@node02 zookeeper-3.4.6]# mkdir -p /var/sxt/zk [root@node02 sxt]# echo 1 > /var/sxt/zk/myid [root@node02 sxt]# cat /var/sxt/zk/myid [root@node03 zookeeper-3.4.6]# mkdir -p /var/sxt/zk [root@node03 zookeeper-3.4.6]# cd /var/sxt/zk [root@node03 zk]# echo 2 > /var/sxt/zk/myid [root@node04 zookeeper-3.4.6]# mkdir -p /var/sxt/zk [root@node04 zookeeper-3.4.6]# echo 3 > /var/sxt/zk/myid [root@node04 zookeeper-3.4.6]# cat /var/sxt/zk/myid -
配置环境变量
[root@node02 zookeeper-3.4.6]# vi + /etc/profileexport ZOOKEEPER_HOME=/opt/sxt/zookeeper-3.4.6 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin将配置好的环境变量分发给node03,node04
[root@node02 zookeeper-3.4.6]# scp /etc/profile node03:/etc/[root@node02 zookeeper-3.4.6]# scp /etc/profile node04:/etc/读取profile
source /etc/profile -
zookeeper操作
在全部会话中输入
zkServer.sh start关闭
zkServer.sh stop查看状态
zkServer.sh status
-
-
启动journalnode节点,在node01,node02,node03分别启动
[root@node01 hadoop]# hadoop-daemon.sh start journalnode -
格式化Namenode01
[root@node01 hadoop]# hdfs namenode -format -
先启动NameNode01
[root@node01 hadoop]# hadoop-daemon.sh start namenode -
在NameNode02中
[root@node02 zookeeper-3.4.6]# hdfs namenode -bootstrapStandby将NameNode01中的数据拷贝到NameNode02中 -
查看zookeeper客户端
[root@node02 zookeeper-3.4.6]# zkCli.sh -
在zookeeper中初始化高可用状态
[root@node01 hadoop]# hdfs zkfc -formatZK -
启动节点
[root@node01 hadoop]# start-dfs.sh成功则显示
Starting namenodes on [node01 node02] node02: starting namenode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-namenode-node02.out node01: namenode running as process 1362. Stop it first. node03: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node03.out node02: datanode running as process 1613. Stop it first. node04: starting datanode, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-datanode-node04.out Starting journal nodes [node01 node02 node03] node01: journalnode running as process 1190. Stop it first. node02: journalnode running as process 1351. Stop it first. node03: journalnode running as process 1313. Stop it first. Starting ZK Failover Controllers on NN hosts [node01 node02] node01: starting zkfc, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-zkfc-node01.out node02: starting zkfc, logging to /opt/sxt/hadoop-2.6.5/logs/hadoop-root-zkfc-node02.out

-
关闭zkfc进程,观察NameNode01,NameNode02的变化
hadoopj-daemon.sh stop zkfc