NeurIPS 2019:计算机视觉论文回顾
作者:Maria Dobko
编译:ronghuaiyang
导读
这是2019年12月9日至14日在温哥华举行的NeurIPS 2019的概述(笔记)。这篇文章中提到的所有论文都是在计算机视觉领域。

NIPS 2019上的一些论文回顾
会议网站:https://neurips.cc/
论文全集:https://papers.nips.cc/book/advances-in-neural-information-processing-systems-32-2019
这是2019年12月9日至14日在温哥华举行的NeurIPS 2019的概述(笔记)。超过13000名参与者。两天的研讨会,一天的辅导课和三天的主要会议。在这篇文章中,我会简要地描述了一些论文,它们引起了我的注意。这篇文章中提到的所有论文都是在计算机视觉领域,这是我的研究领域。
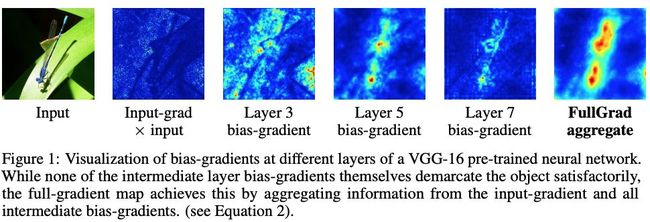
神经网络可视化的全梯度表示
Suraj Srinivas, François Fleuret
论文链接:https://papers.nips.cc/paper/8666-full-gradient-presentation-for-neural-networkvisualiz.pdf
探索输入部分的重要性如何被显著性映射捕获。研究表明,任何神经网络的输出都可以分解为输入梯度项和神经元梯度项。他们证明了在卷积网络中聚合这些梯度映射可以改善显著性映射。论文提出了FullGrad显著性,它结合了输入梯度和特征级偏差梯度,因此,满足两个重要概念:局部(模型对输入的敏感性)和全局(显著性图的完整性)。
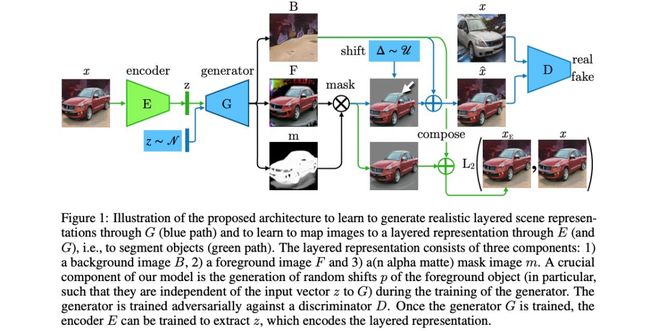
扰动生成模型中目标分割的出现 Emergence of Object Segmentation in Perturbed Generative Models
Adam Bielski, Paolo Favaro
论文链接:https://arxiv.org/pdf/1905.12663.pdf
提出了一种不需要人工标注就能从一组图像中学习目标分割的框架。其主要思想是建立在这样的观察之上:相对于给定的背景,物体的位置可以被局部扰动,而不影响场景的真实感。训练生成模型,生成分层图像表示:背景,掩模,前景。作者使用小的随机移位来暴露无效的分割。他们用两个生成器训练StyleGAN,用蒙版分别作为背景和前景。它经过训练,使具有移位前景的合成图像呈现出有效的场景。在生成的掩码上还有两个损失项,以促进二值化并且帮助最小掩码的收敛,这两个项都添加到WGAN-GP生成器损失中。他们还训练了编码器与固定的生成器,以获得分割的真实图像。该方法在LSUN物体数据集的4个类别上进行了测试:汽车、马、椅子、鸟。
GPipe:利用管道并行性有效地训练巨型神经网络
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, Zhifeng Chen
为了解决高效和任务无关的模型并行性需求,引入了GPipe,这是一个可扩展的模型并行性库,用于训练可以表示为层序列的巨型神经网络。该算法采用同步梯度更新的方法,使模型并行化,具有较高的硬件利用率和训练稳定性。主要贡献包括模型可扩展性(在吞吐量和大小上几乎线性加速,支持超过1k层和90B参数的非常深的transformer),灵活性(任何网络的扩展),简单的编程接口。GPipes提供了一种提高质量的方法,甚至可以使用迁移学习或多任务学习来提高较小数据集的质量。实验表明,越深的网络迁移效果越好,而越宽的模型记忆效果越好。
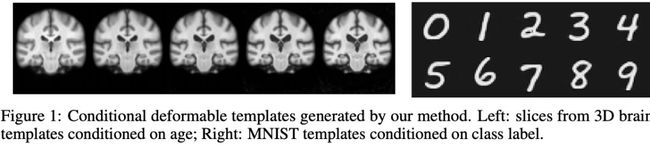
使用神经网络来学习条件可变形模板
Adrian Dalca, Marianne Rakic, John Guttag, Mert Sabuncu
论文链接:https://papers.nips.cc/paper/8368-learning-conditional-deformable-templates-with-convolutional-networks.pdf
代码:https://github.com/voxelmorph/voxelmorph
学习框架估计可变形模板(atlases)连同校准网络。启用基于所需属性的条件模板生成函数。该方法联合学习注册网络和图集。我们开发了一个学习框架来建立可变形模板,它在许多图像分析和计算解剖任务中起着基础作用。在模板创建和图像对齐的传统方法中,模板是使用模板估计和对齐的迭代过程中构建的,这通常在计算上非常昂贵。介绍的方法包括一个概率模型和有效的学习策略,生成通用模板或条件模板,以及一个神经网络,提供有效的对齐这些模板的图像。这对临床应用特别有用。
学习预测用于语义图像生成的布图到图像的条件卷积
论文链接:https://arxiv.org/pdf/1910.06809.pdf
代码:https://github.com/xh-liu/CC-FPSE
该方法根据语义标签映射对卷积核进行预测,从噪声映射中生成中间特征映射,最终生成图像。作者认为,对于generator:卷积核应该知道不同位置上不同的语义标签,而对于discriminator,应该加强生成图像和输入语义布局之间的细节和语义对齐。因此,使用图像生成器来预测条件卷积(有效地预测深度可分卷积,只预测深度卷积的权值,是一个全局上下文感知的权值预测网络)。引入的特征金字塔语义-嵌入鉴别器用于纹理和边缘等细节,也用于与布局图的语义对齐。

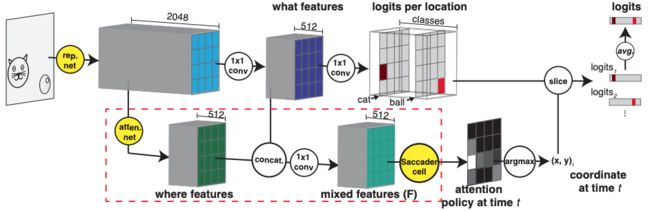
Saccader:提高视觉的注意力模型的准确性
Gamaleldin F. Elsayed, Simon Kornblith, Quoc V. Le
论文链接:https://arxiv.org/pdf/1908.07644.pdf
代码:https://github.com/google-research/google-research/tree/master/saccader
在这项工作中,硬注意模型的改进(他们选择图像中的显著区域,并只使用它们进行预测)被提出。这篇文章介绍的模型 — Saccader有一个训练前的步骤,只需要类标签和提供初始注意位置的策略梯度优化。 Saccader的结构:1、表示网络(BagNet),2、注意力网络,3、Saccader单元(无RNN,每次预测视觉的注意力位置)。最好的Saccader模型缩小了与普通ImageNet基线的差距,达到75%的top-1和91%的top-5,而只关注不到三分之一的图像。
使用重画的非监督物体分割
Mickaël Chen, Thierry Artières, Ludovic Denoyer
论文链接:https://arxiv.org/pdf/1905.13539.pdf
ReDO(重绘物体)是一种非监督数据驱动的物体分割方法。作者假设自然图像的生成是一个复合过程,其中每个物体都是独立生成的。他们把物体分割任务看作是发现可以重绘而不需要看到图像其余部分的区域。如本文所述,该方法基于一种对抗性架构,其中生成器由输入样本引导:给定一个图像,它提取物体掩码,然后在相同位置重新绘制一个新对象。该生成器由一个鉴别器控制,以确保生成的图像的分布与原始图像对齐。加入学习函数,尝试从一般图像中重建噪声向量,然后通过每次只重建一个区域,保持图像的其余部分不变,将输出与输入绑定在一起。
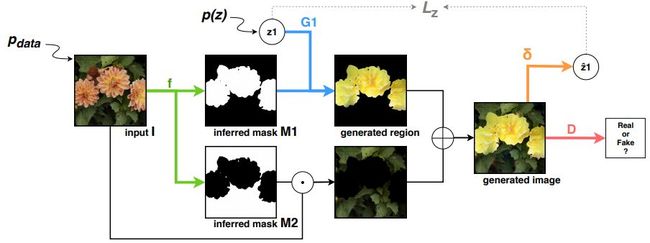
神经网络中的近似特征冲突
Ke Li, Tianhao Zhang, Jitendra Malik
论文链接:https://papers.nips.cc/paper/9713-approximate-feature-collisions-in-neural-nets.pdf
特征冲突 — 两个不同的样本共享相同的特征激活,因此具有相同的分类决策。本文提出了一种特征冲突检测的方法。在这篇论文中,作者们证明了神经网络可以令人惊讶地对巨大的逆向选择的变化不敏感。在这个实验中,他们观察到这种现象可能是由ReLU激活函数的固有特性引起的,从而导致两个非常不同的样本共享相同的特征激活,从而做出相同的分类决策。可能的应用包括有代表性的数据收集、正则化器的设计、易受攻击的训练样本的识别。

网格对语义分割上下文解释的重要性
Lukas Hoyer, Mauricio Munoz, Prateek Katiyar, Anna Khoreva, Volker Fischer
论文链接:https://arxiv.org/pdf/1907.13054.pdf
结果表明,网格显著性可以成功地提供易于解释的上下文解释,而且可以用于检测和定位数据中出现的上下文偏差。主要目标是开发一种显著性方法,通过扩展现有的方法来生成网格显著性,从而为网络预测提供可视化的解释。这为(像素级)稠密预测网络提供了空间相干的视觉解释,并为语义分割网络提供了上下文解释。

通过对抗性模型操作来欺骗神经网络解释
Juyeon Heo , Sunghwan Joo , Taesup Moon
论文链接:https://arxiv.org/pdf/1902.02041.pdf
假设:基于映射的显著性解释器很容易被欺骗,而不会显著降低准确性。本文证明了目前最先进的基于显著性映射的解释器,如LRP、Grad-CAM和SimpleGrad等,很容易被对抗性模型操作所欺骗。文章中提出了两种类型的欺骗,被动的和主动的,以及定量的度量 — 欺骗成功率(FSR)。它给出了为什么对抗性模型操作会有效,以及一些限制。

深度神经网络中解释方法的基准
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, Been Kim
论文链接:https://papers.nips.cc/paper/9167-a-benchmark-for-interpretability-methods-in-deep-neural-networks.pdf
对模型预测重要内容的错误估计可能导致对敏感领域(医疗、自动驾驶等)产生不利影响的决策。作者比较了特征重要性估计器,并探讨了集成它们是否能提高准确性。为了比较这些方法,他们从每幅图像中去除一小部分所有像素,这些像素被认为是对模型预测贡献最大的,并且在没有这些像素的情况下对模型进行再训练。假设最佳解释方法应提供去除模型性能最弱的像素点。这种评估方法称为ROAR:RemOve And Retrain。测试方法包括基础估计(梯度的热图,梯度积分,导向后向传播),基础预测器的集成(SmoothGrad梯度积分,VarGrad梯度积分等等),以及控制变量(随机,sobel边缘滤波器)。最有效的方法是SmoothGrad-Squared和VarGrad。
人眼感知评估:生成模型的基准
Sharon Zhou, Mitchell L. Gordon et al.
HYPE是一个标准化的、有效的生成模型评估,它测试生成模型在人眼中的逼真程度。正如作者所提到的,它是一致的,灵感来自于知觉心理学中的心理物理学方法,可以可靠的通过从一个模型中随机取样的不同集合输出,得到可分离的模型性能,并且在成本和时间上很高效。
用于语义分割的区域互信息损失
Shuai Zhao, Yang Wang , Zheng Yang, Deng Cai
论文链接:https://arxiv.org/pdf/1910.12037.pdf
代码:https://github.com/ZJULearning/RMI
语义分割通常采用像素分类的方法来解决,而像素损失忽略了图像中像素之间的依赖关系。作者使用一个像素和它的相邻像素来表示这个像素,并将一个图像转换成一个多维分布。因此,通过最大化预测和目标分布之间的相互信息,可以使预测和目标更加一致。RMI的思想是直观的,它也很容易使用,因为它只需要在训练阶段的一些额外的内存,甚至不需要改变基本分割模型。RMI也可以在性能上实现实质性的、一致的改进。这个方法在PASCAL VOC 2012上进行了测试。

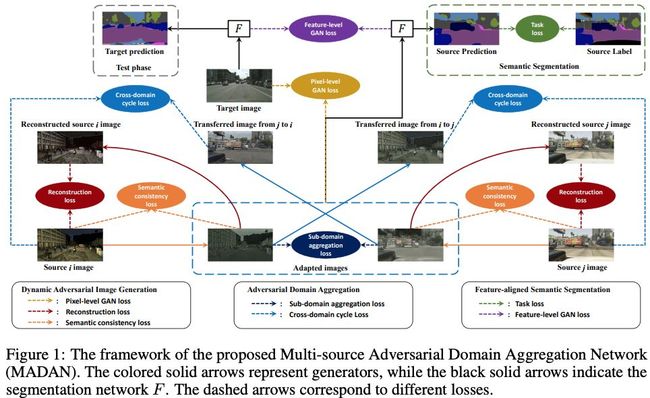
多源领域自适应语义分割
Sicheng Zhao, Bo Li, Xiangyu Yue, Yang Gu, Pengfei Xu, Runbo Hu, Hua Chai, Kurt Keutzer
论文链接:https://arxiv.org/pdf/1910.12181.pdf
在这个工作领域中,对语义分割的适应是从多个来源进行的,并提出了一个新的框架,称为MADAN。正如作者所述,除了特征级对齐外,像素级对齐还通过为每个源循环生成一个自适应的域来进一步考虑,这与一种新的动态语义一致性损失是一致的。为了提高不同自适应域的一致性,提出了两种判别器:跨域循环判别器和子域聚合判别器。该模型在合成数据集 —— GTA和SYNTHIA,以及真实的城市景观和BDDS上进行了测试。

—END—
英文原文:https://medium.com/@dobko_m/neurips-2019-computer-vision-recap-ddd26b13337c
公众号近期荐读:
GAN整整6年了!是时候要来捋捋了!
数百篇GAN论文已下载好!搭配一份生成对抗网络最新综述!
有点夸张、有点扭曲!速览这些GAN如何夸张漫画化人脸!
天降斯雨,于我却无!GAN用于去雨如何?
脸部转正!GAN能否让侧颜杀手、小猪佩奇真容无处遁形?
容颜渐失!GAN来预测?
强数据所难!SSL(半监督学习)结合GAN如何?
弱水三千,只取你标!AL(主动学习)结合GAN如何?
异常检测,GAN如何gan ?
虚拟换衣!速览这几篇最新论文咋做的!
脸部妆容迁移!速览几篇用GAN来做的论文
【1】GAN在医学图像上的生成,今如何?
01-GAN公式简明原理之铁甲小宝篇
GAN&CV交流群,无论小白还是大佬,诚挚邀您加入!
一起讨论交流!长按备注【进群】加入:

更多分享、长按关注本公众号:
