SwinTrack: A Simple and Strong Baseline for Transformer Tracking(NIPS2022)
SwinTrack
- 摘要
- 介绍
- 相关工作
- 方法
- 实验
摘要
近期,Transformer在视觉跟踪方面进行了深入探索,并展示了显著的潜力。然而,现有的基于Transformer的跟踪器主要将Transformer用于融合和增强由卷积神经网络提取的特征,Transformer在表征学习中的潜力仍未被发掘。在本文中,提出了一个建立在经典孪生框架基础之上的简单而高效的基于全注意力的Transformer跟踪器(SwinTrack),以进一步释放Transformer的潜力。SwinTrack使用Transformer既做了特征提取又做了特征融合,使得模板和搜索区域能够实现充分交互。此外,为了进一步增强鲁棒性,提出了一种新的motion token,该token嵌入了历史目标轨迹,能够通过提供时间上下文来改进跟踪。所提出的motion token是轻量级的,计算量可以忽略不计,但带来了明显的好处。
介绍
Transformer显著推动了视觉跟踪的发展。然而,现有的方法通常利用Transformer来融合和增强由CNN产生的特征。利用Transformer进行特征表示学习的潜力在很大程度上还没有得到充分开发。
将Transformer架构引入计算机视觉领域的工作可以被广泛地分为两类:(1)将Transformer看作是CNN的补充,将Attention机制和卷积神经网络联合起来使用;(2)致力于探索一个全注意力模型,认为Transformer在未来将会打败CNN结构,并将Attention机制作为网络的基本组成块。第二类的工作在开始时的发展并不好,ViT是第一个在视觉领域提出的全注意力模型,但它的许多后续变体在性能上都不如卷积网络,直至Swin Transformer的出现,在目标检测、实例分割等任务上性能远超CNN。
本文将Swin Transformer作为其主干网络,并结合目标跟踪中Siamese经典框架,提出了SwinTrack框架。与基于CNN的框架以及基于混合CNN-Transformer的框架相比,SwinTrack能够在模板和搜索区域的特征学习及其融合中实现更好的交互,从而产生更鲁棒的性能。SwinTrack在LaSOT公开数据集上以0.713的SUC刷新了记录,同时仍能以45帧/秒的速度运行。
Swin Transformer作为一种新的视觉Transformer,采用了基于分层窗口的注意力架构,解决了Transformer结构从语言迁移到视觉的两大挑战性问题:(1)视觉元素变化规模大;(2)图像像素分辨率高,计算复杂度高。Swin Transformer引入了非重叠窗口划分操作,将自注意力计算限制在了局部窗口内,大大减少了计算复杂度。Swin Transformer网络由浅层到深层,下一层的特征图通过逐渐合并上一层的邻域窗口来构建分层特征图,形成特征金子塔,用于密集预测任务(如像素级分割)。
Transformer的两大优势:(1)Transformer是sequence-to-sequence的模型,更容易联合多个模态的数据,在网络架构设计上更加灵活;(2)来自Attention机制的长期建模能力突破了传统基于CNN/RNN的限制。
SwinTrack的主要设计点:
- 将Swin Transformer作为Backbone
- 在跟踪器的不同部分正确选择不同的候选网络;
- 引入untied positional encoding为级联后的特征提供正确的位置编码
- 引入IoU-aware classification score作为分类预测分支,选择更精准的目标边界框
相关工作
Siamese Tracking:孪生跟踪方法将跟踪描述为一个匹配问题,旨在离线学习此任务的通用匹配函数。SiamFC引入了一种全卷积的孪生网络用于跟踪,并在精度和速度之间取得了很好的平衡。为了提升处理尺度变化的能力,SiamRPN将RPN与孪生网络相结合,并提出基于Anchor的跟踪器,表现出了更高的精度和更快的速度。
Transformer in Vision:Transformer起源于NLP,由于其具有良好的性能和更好的并行化能力,快速替代了LSTM模型,并很快在NLP领域占据了绝对地位。DETR首次将Transformer用于目标检测,并取得了良好效果。它将目标检测建模为一个直接的集合预测问题,移除了大部分手动过程并实现了SOTA性能。ViT将Transformer用于主干,是第一个应用在视觉领域的全注意力模型。它将图像划分成多个固定尺寸的patches(token),同时还具有一个线性映射和正确的位置编码。Swin Transformer是视觉领域中目前效果最好的全注意力模型,它可以使用多尺度结构,还能降低计算复杂度,大大提高了效率。
Transformer in Tracking:受其他领域的成功启发,研究人员将Transformer引入跟踪。TransT在孪生框架中引入Transfomer,提出了ECA和CFA模块,实现对特征的增强和融合。TransformerTrack利用Transformer来使用时间特征提高跟踪的鲁棒性。Stark通过将模型更新操作集成到Transformer模块中来探索基于时空的Transformer。
本文提出的SwinTrack与上述基于Transformer的跟踪器有很大不同,上述方法主要应用Transformer来融合卷积特征,属于混合CNN-Transformer结构。与它们不同的是,SwinTrack是一个完全基于注意力机制的跟踪架构,表征学习和特征融合都通过Transformer结构实现,从而能够探索更好的特征来实现更鲁棒的跟踪。

方法
SwinTrack的整体框架如下图所示,主要由三个部分组成,包括用于特征提取的Swin Transformer主干、用于融合视觉和运动线索的编码-解码网络、用于定位目标的头部网络。

深度卷积神经网络显著提高了跟踪器的性能。随着跟踪器的进步,主干网络经历了两次演变:AlexNet和ResNet。与ResNet相比,Swin-Transformer能够给出更紧凑的特征表示和更丰富的语义信息,以帮助后续网络更好地定位目标对象,因此被选用为SwinTrack模型的特征提取器。
基于匹配的视觉跟踪需要将模板信息注入到搜索区域。SwinTrack遵循孪生架构,将模板图像和搜索图像作为输入,并采用编码器来融合模板和搜索区域的特征,同时使用解码器来实现vision-motion的表征学习。
用于融合template tokens和search tokens的编码器: 编码器包含若干个Transformer Block,每个Block由一个多头自注意力(MSA)和一个前馈网络(FFN)组成。FFN中有一个两层的MLP,并在第一个线性层后接了一个GELU激活层。层归一化(Layer Norm)总是在MSA和FFN之前进行,残差连接应用于MSA和FFN模块。
在将特征送入编码器之前,模板和搜索tokens会沿空间维度拼接在一起,以得到一个混合的特征表示。对于每个Block,MSA模块会对混合特征进行自注意力计算,这就相当于分别对template tokens和search tokens进行自注意力计算,同时对它们进行交叉注意力计算,但是对混合特征操作的效率更高。经由MSA得到的特征会送入FFN中进行进一步改善。当tokens离开编码器时,会使用一个de-concatenation操作来耦合template tokens和search tokens。
用于融合vision和motion信息的解码器: 该解码器由一个多头交叉注意力(MCA)模块和一个前馈网络(FFN)组成。解码器将编码器的输出和motion token作为输入,通过计算 f x f_x fx和 C o n c a t ( E m o t i o n , f z , f x ) Concat(E_{motion}, f_z, f_x) Concat(Emotion,fz,fx)的交叉注意力来生成最终的vision-motion特征表示。解码器类似于编码器中的一个层,因为不需要更新最后一层中的模板图像的特征,因此删除了template tokens和search tokens之间的相关性。
这里介绍一下如何生成motion token。motion token是目标物体历史轨迹的embedding,过去的目标轨迹被表示为一组目标框的坐标,每一个目标框都由左上角点和右下角点的坐标建立。为了更加的灵活,需要一个采样过程来确保其能够固定长度、关注最新轨迹、减少冗余。为了将目标轨迹嵌入网络,采用了四个embedding矩阵在目标框的四个坐标值中嵌入元素。embedding矩阵可以表示为 W ∈ R ( g + 1 ) × d W∈R^{(g+1)×d} W∈R(g+1)×d,g控制目标轨迹的嵌入粒度,d为每个embedding向量的大小。将采样的目标框坐标归一化到[1, g]范围,并量化为整数以获得embedding向量的索引。最后,由采样目标轨迹的所有目标框坐标embedding拼接得到motion token。
位置编码: Transformer需要位置编码来标识当前处理token的位置。通过一系列的比较实验,选择TUPE中提出的联合位置编码作为SwinTrack的位置编码方案。此外,将untied positional encoding推广到任意维度,以适应跟踪器中的其他组件。
Why concatenated attention? 为了简化描述,本文将上述方法称为基于concat的融合。为了融合来自不同分支的特征,直观的做法是分别对每个分支的特征进行Self-Attention计算,以完成特征提取步骤,然后进行跨分支特征的Cross-Attention计算,完成特征融合步骤。这种方法可称为基于交叉注意力的融合。
考虑到Transformer是一个序列到序列的模型,它可以自然地接受多模态数据作为输入。与基于交叉注意力的融合相比,基于concat的融合可以通过操作共享来节省计算代价,通过权值共享减少模型参数。从度量学习角度来看,为了确保两个分支之间的度量是对称的,权值共享是一个必不可少的设计。为了确保注意力机制知道当前正在处理的token属于哪个分支以及它在分支中的位置,必须仔细设计模型的位置编码解决方案。
Why not window-based self/cross-attention? 由于选择了Swin-Transformer的第三阶段作为输出,token的数量显著减少,因此基于窗口的注意力并不会节省太多的FLOPs。此外,考虑到窗口划分和窗口反转操作带来的额外延迟,基于窗口的注意力甚至可能是更慢的。
Why not a query-based decoder? 源于vanilla Transformer解码器,视觉任务中许多基于Transformer的模型都利用一个可学习的query从编码器中提取所需要的目标特征。然而,在本文的实验中,基于query的解码器存在收敛速度慢和性能较差的问题。大多数孪生跟踪器将跟踪描述为前景-背景分类问题,这可以更好地利用背景信息。vanilla Transformer解码器是一个生成式模型,生成方式被认为不适合分类任务。另一方面,学习一个能用于任何类型对象的通用目标query可能会导致瓶颈。就vanilla Transformer编码-解码器体系结构而言,SwinTrack是一个仅使用编码器的模型。此外,相当多的领域知识可以很容易地应用到经典的孪生跟踪器上以提高性能,比如通过在响应图上使用Hanning penalty window来引入平滑运动假设。
Head and Loss: head network分为两个分支,分别是分类分支和回归分支。每个分支都是一个三层感知器,其中分类分支负责前景-背景的分类,回归分支负责BBox的回归。两者都从解码器接收特征映射,然后分别预测分类响应映射和边框回归映射。
在分类分支中,采用IoU-aware classification score作为训练目标,以varifocal loss作为训练损失函数。IoU-aware设计近年来非常流行,但大多数工作都将借据预测分支作为辅助分支来辅助分类分支或边界框回归分支。为了消除不同预测分支之间的差距,有研究将分类目标由ground-truth值替换为预测BBox与ground-truth之间的IoU,即IoU-aware classification score(IACS)。IACS可以帮助模型从候选中选择更准确的边界框。与IACS一起,varifocal loss帮助IACS方法优于其他IoU感知设计。varifocal loss有以下形式:
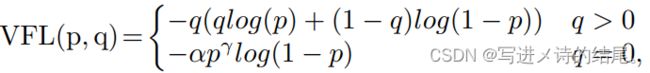
其中p为预测IACS,q为目标分数。对于正样本,即前景点,q为预测的边界框与ground-truth边界框之间的IoU。对于负样本,q = 0。则分类损失可表示为:

其中b为预测边界框,b帽为ground-truth边界框。
在回归分支中,采用generalized IoU loss。回归损失函数可表示为:

用p对GIoU损失进行加权,强调样本的高分类分数。负样本的训练信号被忽略。
实验

对于motion token,采样目标轨迹数量设置为16,固定采样间隔设置为15。如果视频序列的帧率可用,则根据帧率调整采样间隔——帧率×固定采样间隔÷30。

